
- HTTP의 변천사를 공부하고 작성한 글입니다.
- "변천사"라고만 이야기 하기엔 각 버전에 대한 비교적 상세한 설명을 담았습니다.
- 각 버전에 대한 상세한 설명이 필요없으시면 건너뛰시길 바랍니다💃🏾- 그렇지만 꼼꼼히 읽으시면 분명 HTTP에 대한 이해도가 올라갈 것입니다.
- ✨는 새로운 버전의 시작을 알립니다.
- ⛔️는 기존 버전의 문제점을 말합니다.
- 변천사의 흐름을 파악하기 원하시는 분들은 ⛔️에 주목해주시면 될 것 같습니다. 모든 새로운 기술은 기존의 문제점으로부터 출발합니다. - 정독예상시간 : 20-25분
내가 변천사에 관한 글을 쓴 이유 :
모든 기술은 특정한 문제를 해결하기 위해서 탄생합니다. 그리고 그 기술의 핵심을 이해하는 가장 본질적인 방법 또한 이 기술이 어떤 문제를 해결하기 위해 탄생했는지 이해하는 것입니다. HTTP는 계속해서 새로워지고 있습니다. 1,2,3 버전까지 계속 새롭게 탄생하면서, 기존에 겪고 있는 문제들을 해결해냈습니다. 제가 변천사 혹은 역사에 관해 글을 쓰고자 하는 것은 버전이 업데이트가 되어가면서, 어떤 문제를 해결하고자 했는지 이해하고자 하는 것이며, 그것을 통해서 해당 버전의 본질을 이해하게되길 기대하는 것입니다. 그럼 시작해보겠습니다.
HTTP의 정의
http의 변천사를 알아보기 전에, http가 무엇인지를 먼저 알아보겠습니다.
HTTP(HyperText Transfer Protocol)는 World Wide Web 상에서 정보를 주고받을 수 있는 프로토콜이다. 주로 HTML 문서를 주고받는 데에 쓰인다. [위키피디아]
위 문장을 풀어서 해석해보면, 다음과 같이 이해해볼 수 있습니다. 하이퍼텍스트(HyperText)를 전송하는(Transfer) 프로토콜인데(Protocol), 그것이 이루어지는 장소는 World Wide Web이다.
그렇다면 저희가 이 정의를 제대로 이해하기 위해서 알아보아야 할 단어들이 있습니다.
- HyperText
- Protocol
- World Wide Web
HyperText
하이퍼텍스트란 다른 문서에 대한 참조를 통해 독자가 한 문서에서 다른 문서로 즉시 접근할 수 있는 텍스트를 말합니다. HTML 상에서 < a > 라는 요소를 사용할 때, 저희는 다른 문서로 이동할 수 있는데, 이렇게 이동할 수 있는 텍스트를 하이퍼텍스트라고 말합니다.
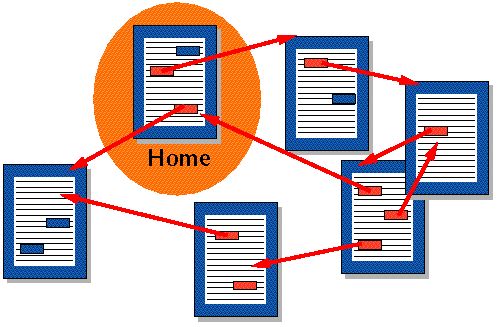
사진과 같이, 하이퍼텍스트를 통해서 다양한 문서사이를 왔다갔다 할 수 있습니다. 기존의 문서는 위에서 아래로 순차적이면서 서열적인 구조를 갖추고 있었지만, 하이퍼텍스트는 문서 내에 삽입된 링크에 의해서 그 차례가 바뀌면서 임의적이고 나열적인 구조를 가지게 됩니다.
보통 이런 하이퍼텍스트를 사용하고 있는 대표적인 기술이 HTML입니다. HTTP 초창기에는 HTML만 지원가능했지만, 최근에는 거의 모든 파일 형식을 HTTP를 통해서 지원할 수 있게 되었습니다.
HyperText의 정의를 알아봄으로써 저희가 알 수 있었던 것은 HTTP가 전송하는 대상이 무엇인지 입니다. HTTP가 전송하는 대상은 HyperText였었으나, 최근에는 거의 모든 파일을 HTTP를 통해서 전송할 수 있게 되었습니다.
Protocol
프로토콜은 컴퓨터 내부에서, 또는 컴퓨터 사이에서 데이터의 교환 방식을 정의하는 규칙 체계입니다. [MDN]
프로토콜은 규칙체계를 말합니다. 무엇을 위한 규칙체계입니까? 데이터 교환 방식을 정의하기 위한 규칙체계입니다.
프로토콜은 저희가 사용하는 언어와 비슷합니다. 한국인은 한국인끼리 그들이 가지고 있는 생각(데이터)를 전달하기 위해서 한국어라는 프로토콜을 사용합니다. 만약 서로가 사용하는 언어, 그러니까 프로토콜이 다르면 저희는 정보를 공유하기 어려워집니다.
이처럼 컴퓨터 사이에서 정보를 공유하기 위해서도 규칙을 맞출 필요가 있습니다. 바로 프로토콜이라는 규칙 체계입니다. 이 프로토콜을 통해서 컴퓨터는 다른 컴퓨터와 의사소통을 할 수 있게 됩니다.
World Wide Web
월드 와이드 웹은 인터넷에 연결된 컴퓨터를 통해 사람들이 정보를 공유할 수 있는 전세계적인 정보 공간을 말한다. 간단히 웹이라고 부르는 경우가 많다. [위키피디아]
WWW는 간단히 말하면, 컴퓨터를 통해 정보를 공유하는 정보공간 입니다. 당연히 이것의 탄생 또한 정보 공유와 얽혀있습니다.
1989년 스위스와 프랑스 사이에는 CERN(유럽 입자 물리 연구소)라는 곳이 있었습니다.

이 연구소에서는 팀 버너스 리 라는 컴퓨터 과학자가 있었는데요, 이 사람이 어느 날 고민한 것이죠. 어떻게 하면 효율적으로 세계의 여러 대학과 연구기관에서 일하는 물리학자들 사이에서 신속하게 정보를 교환하고, 공동연구를 진행할 수 있을까? 그래서 탄생하게 된 것이 바로 World Wide Web입니다. 불과 그의 나이 25살이었습니다.

HTTP의 정의를 알아보기 위한 시간을 가져보았습니다. 위의 내용을 모아서 다시한번 정의를 내려보면 다음과 같습니다.
HTTP는 HyperText라는 데이터를(오늘날엔 거의 모든 종류의 데이터) 컴퓨터 간에 전송하고 교환하기 위한 규칙체계다. 그리고 그것이 이루어지는 장소는 World Wide Web이다.
어렵지 않죠?
WWW(World Wide Web)의 발명
위에서 저희는 WWW이 어떻게 발명되었는지를 살펴보았습니다. 이번 섹션에서는 WWW에 대해서 조금만 더 상세하게 알아보겠습니다.
사실 WWW는 원래 이런 이름이 아니었을 수도 있었습니다. 팀 버너스 리는 2014년에 래딧에서 열렸던 "Ask Me Anything"이라는 세션에서, WWW의 이름이 될 뻔했던 후보를 소개한 적이 있습니다. Mesh, Mine of Infomation, The Information Mine. 이 세가지입니다. 결국 심사숙고 후에 WWW라는 이름을 가지게 되었습니다.
이 WWW는 기존의 TCP와 IP 프로토콜 상에서 만들어지면서, 4개의 구성요소를 가지게 되었습니다.
- HTML : 하이퍼텍스트 문서를 표현하기 위한 텍스트 형식
- HTTP : 문서 같은 것을 교환하기 위한 간단한 프로토콜
- 브라우저 : 문서를 화면에 보여주기 위한 클라이언트
- httpd : 문서에 접근하도록 해주는 httpd의 초기버전 (아파치 하이퍼텍스트 전송 프로토콜 서버)
이 4가지 구성요소들은 1990년 말에 완료되었습니다. 이제 HTTP의 변천사를 파고들어가기 위한 기반을 이해했습니다. 본격적으로 HTTP의 변천사를 알아보도록 하겠습니다. 먼저 가장 초창기버전인 HTTP/0.9입니다.
✨HTTP/0.9 - 원 라인 프로토콜
사실 HTTP/0.9 버전은 출시될 때부터 0.9 버전이라는 이름을 가진 것은 아니었습니다. 그저 이후에 버전이 생기면서, 이전과 구분하기 위해서 버전이름이 붙여진 것입니다. 때문에 이 버전을 초창기 HTTP의 버전이라고 봐도 좋습니다. 0.9버전은 지극히 단순합니다. 요청은 단 한줄로 구성됩니다. 이용가능한 메서드는 오직 GET 하나밖에 없었습니다.
다음은 요청 메시지의 예시입니다. 메서드(오직 GET) + 경로 형식으로 이루어져 있었습니다.
GET /mypage.html응답 또한 지극히 단순합니다. 오직 HyperText만 지원했습니다.
<HTML>
A very simple HTML page
<HTML>연결 또한 응답을 주고나면, 곧바로 제거되었었습니다. 헤더도 존재하지 않았고, 상태코드, 버저닝 같은것들 또한 존재하지 않았습니다. 헤더가 존재하지 않았다는 것은 오직 HTML 파일만 전송할 수 있었다는 것을 의미합니다. 헤더가 탄생했기 때문에 다양한 종류의 파일을 지원할 수 있었던 것입니다. HTTP/0.9까지는 매우 단순한 프로토콜이었습니다.
✨HTTP/1.0 - 확장성 만들기
HTTP/1.0에선 몇가지 추가적인 변화가 생겼습니다.
1. 버저닝
2. 상태코드
3. 헤더
4. 메서드 확장
1.버저닝 :
HTTP가 진화해서 1.0 버전이 되었습니다. 드디어 이때부터 버저닝이 되기 시작했습니다. 요청을 보낼 때마다 버전 정보가 붙었습니다. 이렇게 말입니다.
GET /mypage.html HTTP/1.0 2.상태코드 :
또한 상태코드도 붙었습니다. 이 상태코드는 응답의 시작 부분에 붙어서 전송되었습니다. 이 덕분에 브라우저는 요청에 대한 성공 실패여부를 알 수 있었습니다.
200 OK
Date : Tue, 15 nov 1994 08:12:31 GMT
...3.헤더 :
그리고 헤더가 도입되었습니다. 이는 메타데이터를 전송할 수 있게 해주었습니다.(메타데이터란 데이터에 대한 설명이라고 볼 수 있습니다.) 메타 데이터는 요청과 응답에 대한 것이었습니다. 또한 프로토콜을 극도로 유연하고 확장 가능하게 만들어주었습니다.
이런 헤더의 도입으로 인해서 HTML만 지원 가능하던 제한이 풀렸습니다. 여타 스타일시트, 스크립트, 미디어 파일등을 지원할 수 있게 되었습니다. (헤더 안에서도 Content-Type 덕분입니다.)
4.메서드 확장 :
또한 메서드도 확장되었습니다. 0.9에서는 GET만 지원했습니다. 1.0에서는 GET, HEAD, POST를 지원합니다.
⛔️ HTTP/1.0의 한계
0.9에서 1.0로 넘어가면서 장족의 발전이 있었습니다. 그러나 아직 아쉬운 점이 있습니다. 바로 연결입니다. 0.9버전과 마찬가지로 response가 보내지고 나면, 연결은 제거되었습니다. 아래의 HTTP 요청과 응답 로그를 확인해보겠습니다. 연결 생성과, 연결 닫힘 부분을 주목해주세요.
(연결 1 생성 - TCP Three-Way Handshake)
Connected to xxx.xxx.xxx.xxx
(Request)
GET /my-page.html HTTP/1.0
User-Agent: NCSA_Mosaic/2.0 (Windows 3.1)
(Response)
HTTP/1.0 200 OK
Content-Type: text/html
Content-Length: 137582
Expires: Thu, 01 Dec 1997 16:00:00 GMT
Last-Modified: Wed, 1 May 1996 12:45:26 GMT
Server: Apache 0.84
<HTML>
A page with an image
<IMG SRC="/myimage.gif">
</HTML>
(연결 1 닫힘 - TCP Teardown)
------------------------------------------
(연결 2 생성 - TCP Three-Way Handshake)
Connected to xxx.xxx.xxx.xxx
(Request)
GET /myimage.gif HTTP/1.0
User-Agent: NCSA_Mosaic/2.0 (Windows 3.1)
(Response)
HTTP/1.0 200 OK
Content-Type: text/gif
Content-Length: 137582
Expires: Thu, 01 Dec 1997 16:00:00 GMT
Last-Modified: Wed, 1 May 1996 12:45:26 GMT
Server: Apache 0.84
[image content]
(연결 2 닫힘 - TCP Teardown)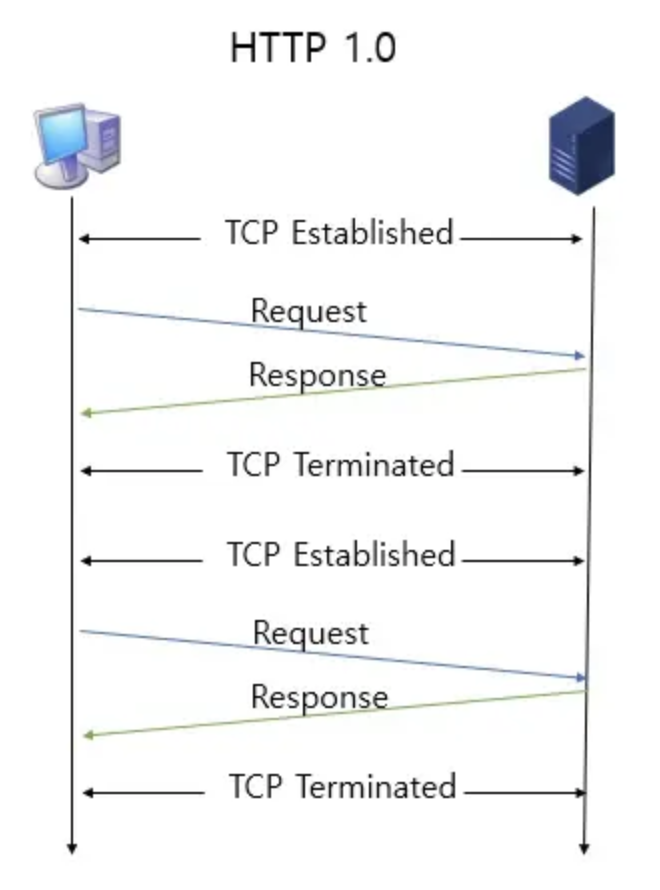
보시다시피 매번 요청와 응답 사이에 단 하나의 연결만이 존재했습니다. 응답이 끝나면 연결이 사라지고, 다음번 요청을 하기 위해서는 다시 3-way-handshake를 통해서 TCP 커넥션을 생성해주어야 했습니다. 아직은 꽤나 불편합니다.
1.0버전은 뭔가 합의를 해서 만들어진 버전이 아닙니다. 일단 생겨나는 문제들을 뭐든지 해결해보자. 일단해보자. 라는 방식으로 접근하며 발전되었습니다. 1996년 11월에 1.0에 대한 실제적인 정보들이 공개되었습니다. RFC 1945입니다. 하지만 이것은 공식적인 표준은 아닙니다.
이제 1.1버전에 대한 설명을 시작할 것입니다. 본격적인 표준에 대한 이야기죠. 그 전에 1.0버전의 변경사항들을 한번 더 정리해보겠습니다.
- 요청에 버전 정보가 붙어서 전송되기 시작했다.
- 상태코드가 붙은 응답이 도착한다.
- 헤더가 생겨서 다양한 종류의 파일을 지원할 수 있게 되었다.
- 메서드의 종류가 확장되었다. GET에서 HEAD와 POST도 사용할 수 있게 되었다.
- ⛔️ 아쉽지만 연결은 매 요청-응답마다 새롭게 해줘야 한다.
✨HTTP/1.1 - 표준 프로토콜
드디어 표준이 된 프로토콜 버전이 등장합니다. HTTP/1.1 버전은 표준이 된 이후로 현재까지도 이용되고 있습니다. HTTP/1.1은 HTTP/1.0이 발표된 지 몇 달이 채 지나지 않아 발표되었습니다. 이 말인즉, HTTP/1.0이 정의되어가는 와중에도 HTTP의 표준화를 위한 다양한 작업들이 동시다발적으로 진행중이었다는 것입니다. 그렇게 HTTP/1.1은 1997년에 발표되었고, 표준이되었습니다.
다음의 사항들이 1.1버전에서 생긴 중대한 변화들입니다.
- 커넥션의 재사용 : 이전에 사용된 커넥션을 다시 열어 시간을 절약하게 되었습니다.
- 파이프라이닝 : 덕분에 첫번째 요청의 응답이 완전히 전송되기 전에 두번째 요청 전송을 가능하게 했습니다. 이 덕분에 커뮤니테이션 latency 낮출 수 있었습니다. (latency : 일반적으로 요청과 응답 사이의 시간을 말한다.)
- 청크 가능한 응답 : 뭉텅이진 응답을 나누어 보낼 수 있게 되었습니다.
- 캐시 제어 메커니즘 : 캐시 제어에 대한 세심한 컨트롤이 가능해졌습니다.
- 언어, 인코딩 혹은 타입을 포함한 컨텐츠 협상 : 클라이언트와 서버로 하여금 교환하기에 가장 적합한 컨텐츠를 보여줄 수 있게 되었습니다.
- Host 헤더를 지원 : 덕분에 동일 IP주소에서 다른 도메인을 호스트하는 기능이 서버 코로케이션을 가능하게 했습니다.
- 다양한 메서드들을 지원 :
- GET, HEAD, POST, PUT, DELETE, TRACE, OPTIONS
각각의 내용들에 대해서 조금 상세히 알아보도록 하겠습니다.
1.커넥션의 재사용 :
Connection 헤더는 HTTP/1.0버전에도 존재했습니다. 그러나 HTTP/1.0 버전과 HTTP/1.1버전에는 중대한 차이가 존재합니다. 1.0버전까지만해도 커넥션은 요청과 응답의 사이클이 끝나면 close되어야 했습니다. 그러나 1.1버전이 되어서는 Keep-alive 기능이 default가 되었습니다. 이것을 통해 요청과 응답의 사이클이 끝나도 커넥션을 재사용할 수 있게 되었습니다. 이를 통해 저희가 알 수 있는 것은 Connection 헤더는 2가지 옵션을 가지고 있다는 것입니다. 바로 Close와 Keep-alive입니다.
Connection: Closed: The default for HTTP/1.0
Connection: Keep-Alive: The default for HTTP/1.1여기서 close헤더는 요청이 완수되고 나면 TCP 커넥션을 닫아야 한다는 것을 서버에게 지시하는 역할을 합니다. Keep-alive는 요청이 완수되고 나더라도 서버가 TCP 커넥션을 유지하고 있어야 한다는 것을 지시합니다. 이렇게 함으로써 엄청난 성능 최적화를 가져올 수 있었습니다. TCP커넥션을 열고 닫을 필요가 없어졌으니까요.
예시로, 1.1 버전에서의 요청과 응답 메시지를 살펴보겠습니다.
(커넥션 1 생성 - TCP Three-Way Handshake)
Connected to xxx.xxx.xxx.xxx
(요청 1)
GET /en-US/docs/Glossary/Simple_header HTTP/1.1
Host: developer.mozilla.org
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.9; rv:50.0) Gecko/20100101 Firefox/50.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate, br
Referer: https://developer.mozilla.org/en-US/docs/Glossary/Simple_header
(응답 1)
HTTP/1.1 200 OK
Connection: Keep-Alive
Content-Encoding: gzip
Content-Type: text/html; charset=utf-8
Date: Wed, 20 Jul 2016 10:55:30 GMT
Etag: "547fa7e369ef56031dd3bff2ace9fc0832eb251a"
Keep-Alive: timeout=5, max=1000
Last-Modified: Tue, 19 Jul 2016 00:59:33 GMT
Server: Apache
Transfer-Encoding: chunked
Vary: Cookie, Accept-Encoding
[content]
(요청 2)
GET /static/img/header-background.png HTTP/1.1
Host: developer.cdn.mozilla.net
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.9; rv:50.0) Gecko/20100101 Firefox/50.0
Accept: */*
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate, br
Referer: https://developer.mozilla.org/en-US/docs/Glossary/Simple_header
(응답 2)
HTTP/1.1 200 OK
Age: 9578461
Cache-Control: public, max-age=315360000
Connection: keep-alive
Content-Length: 3077
Content-Type: image/png
Date: Thu, 31 Mar 2016 13:34:46 GMT
Last-Modified: Wed, 21 Oct 2015 18:27:50 GMT
Server: Apache
[image content of 3077 bytes]
(커넥션 1 닫힘 - TCP Teardown)위에서부터 차근히 읽어보시면, 먼저 어떤 커넥션이 생성되기 전에 3-way-hand-shake를 통해 TCP 커넥션이 생성된다는 것을 알 수 있습니다. 그리고 요청과 응답을 주고 받기 시작합니다. HTTP/1.0버전과의 차이점이 있다면, HTTP/1.1은 요청을 하고 응답이 왔다고 해서 바로 커넥션이 닫히지 않는다는 점입니다. 이전에 사용되었던 커넥션을 재사용해서 다수의 요청과 응답을 주고받을 수 있습니다. 이렇게 함으로써 커넥션에 필요한 비용을 아낄 수 있었고 1.0에 비해 성능을 최적화할 수 있었습니다. 이 모든것이 keep-alive 덕분입니다👏🏻
2.파이프라이닝 :
하지만 아직 아쉬운 점이 있습니다. Keep-alive를 통해서 커넥션을 재사용할 수 있게 되었다 할지라도, 요청을 보내고 응답이 도착해야만 다음 요청을 보낼 수 있다면 이 또한 latency를 증가시키는 요소가 됩니다. 그래서 도입된 것이 바로 파이프라이닝입니다. 이 파이프라이닝은 다수의 요청을 연속적으로 보낼 수 있게 해줍니다. (동시가 아닙니다.) 앞번의 요청에 대한 응답을 받지 않더라도 연속적으로 요청을 보낼 수 있게 함으로써 성능을 조금 더 최적화할 수 있었습니다. 아래 그림을 보시면 이해에 도움이 될 것 같습니다.
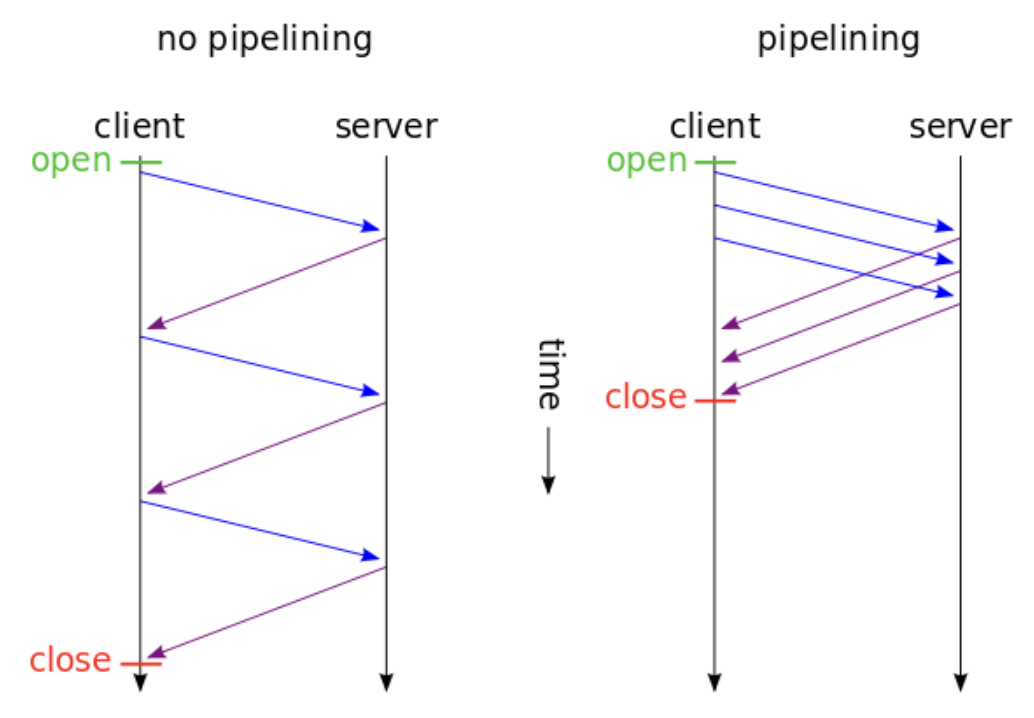
왼쪽은 파이프라이닝을 사용하지 않은 그림인데, 여기선 응답이 도착하고 난 이후에서야 요청을 보냅니다. 오른쪽은 파이프라이닝을 적용한 그림인데, 요청을 보내고나서 응답을 받지 않더라도 요청을 다시 보낼 수 있습니다.
사실 이 파이프라이닝에도 한계는 분명히 존재합니다. 이 한계에 대한 내용은 곧 HTTP/2.0으로 발전하는 계기가 되기도 합니다. 때문에 뒤에서 조금 더 상세히 살펴보도록 하겠습니다.
여기 keep-alive에 대해 더 공부해보고 싶은 분들을 위한 자료가 있습니다.
WHAT IS KEEP-ALIVE?
3.청크가능한 응답 :
chunk란 어떤 하나의 뭉텅이를 의미합니다. 그렇다면 이 의미 또한 뭉텅이진 응답으로 이해할 수 있을 것 같습니다. 아직 와닿지는 않겠지요. 조금 더 풀어서 설명을 해보겠습니다.
"청크된 응답"이란 무엇일까요? 클라이언트가 서버에게 화면을 요청합니다. 이 때 서버는 한 번에 데이터를 보내지 않습니다. html 파일을 여러 개의 뭉텅이(chunk)로 나눕니다. 그리고 그 뭉텅이 조각 조각들을 나누어 클라이언트로 보냅니다.
이것은 어떤 경우에 도움이 되는 것일까요? 사용자 경험을 개선하는데에 도움이 됩니다. 예시 코드를 통해 조금 더 자세하게 알아보겠습니다.
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>청크 예시</title>
<link rel="stylesheet" href="./style.css"></head>
<script src="./app.js"></script>
</head>
<body>
<header>헤더바</header>
<main>
....
</main>
</body>
</html>보시면 head의 영역이 있습니다. 여기에는 각종 scripts와 stylesheets가 포함되어있습니다. 그러면 서버 쪽에서는 head 영역만 하나의 chunk로 만들어서 클라이언트로 보냅니다. 그리고 그 chunk를 받은 클라이언트는 해당 chunk와 관련된 작업을 진행합니다. 그 와중에 서버는 나머지 남은 영역들을 다시 chunk합니다. 클라이언트로 보낼 준비를 하고 있을 것입니다.
조금 더 와닿는 예시라면 그 밑에 있는 헤더바 부분이 있을 수 있겠습니다. 헤더바에 해당하는 부분을 chunk하고 클라이언트에 보내면, 클라이언트는 헤더바에 해당하는 부분만 먼저 화면에 보여줄 수 있습니다. 그러면 화면의 다른 영역은 아직 로드 되지 않았다 할지라도, 사용자가 아예 빈 화면을 보는 시간이 줄어듭니다. 뭔가가 화면에 나타남으로써 "아 화면이 나타나는구나"를 인지할 수 있게 되는 것입니다. 이것을 perceived performance라고 부르기도 합니다. 사실 속도가 좀 느리다 할지라도, 유저가 느리다고 느끼지 않도록 만드는 것도 사용자 경험에 있어서 중요한 부분에 해당합니다.
그렇다면 이 chunked response는 어떻게 동작하는 것일까요? response가 chunk되면 더 이상 content-length 헤더는 필요없어집니다. 대신에 chunk를 이용하기 위해서 'Transfer-Encoding: chunked' 헤더를 추가합니다. 이렇게 하면 response가 chunk되어 보내질 것입니다. response를 살펴보면, 각각의 chunk의 시작부분에, hexadecimal형식으로 현재 chunk의 길이가 표시될 것입니다. 다음은 chunk된 response의 예시입니다.

요런 기능이 HTTP/1.1버전부터 가능해졌습니다. ✨
참고자료 : All About HTTP Chunked Responses
4.캐시제어 메커니즘
추가적인 캐시제어 메커니즘이 HTTP/1.1버전에서 추가되었습니다. 이 캐시라는 기능은 특정 api를 일컫는 이름은 아니며, 다양한 api를 조합하여 사용하는 전략이라고 할 수 있습니다.
캐시는 특정 리소스에 대해서 반복적인 요청이 발생할 때, 해당 리소스를 미리 저장해둠으로써 연산 혹은 로드의 시간을 줄이는 개념 혹은 전략입니다. http 상에서 캐싱 전략을 사용하려고 할 때, 데이터가 가진 특성이 무엇이냐에 따라서 2가지로 전략이 달라질 수 있습니다. mutalbe 데이터와 immutable한 데이터라는 특성에 따라서 전략이 달라집니다. 각각의 전략에 대해서 알아보면서, http에서 사용할 수 있는 캐싱 api에 대해서 알아보겠습니다.
먼저 mutable 데이터에 대한 캐싱 전략입니다.
1) mutable 데이터에 대한 캐싱 전략 :
mutable한 데이터란, index.html 파일 처럼, 그 내부의 내용이 달라질 가능성이 있는 데이터를 말합니다. 때문에 해당 데이터를 캐싱하려고 할 때는 데이터의 내용물이 변경된 것을 확인하고, 최신화 된 데이터를 캐싱할 수 있도록 해야합니다. 데이터의 내용에 변경이 없다면 캐싱되어있는 데이터를 그대로 사용하도록 하는 전략입니다. 여기서 중요한 것은 데이터의 내용이 변경된 것을 어떻게 알 수 있느냐 하는 것입니다.
데이터의 내용이 변경된 것을 확인하기 위해서 여러가지 api들이 함께 사용되어야 합니다. no-cache 헤더, ETag directives, If-None-Match 헤더 등등이 사용되어야 합니다. 각각의 api들을 사용해서 어떻게 mutable한 데이터의 캐싱이 이루어지는지 살펴보겠습니다.
먼저 Cache-Control 헤더에, no-cache 값을 설정해줍니다. 이 속성은 오해하기 쉽지만, 캐시를 하지 않겠다는 의미가 아닙니다. 도리어, 서버에 새로운 컨텐츠가 있는지 묻는 속성입니다. 만약 서버에 새로운 컨텐츠가 있다면, 그 컨텐츠를 다운받도록 합니다. 이 속성은 캐싱되어있는 데이터를 사용하면서도 데이터에 변경이 있는지를 계속 확인하려고 할 때 사용합니다. 만약 캐싱을 하지 않기를 원한다면, no-store 속성을 사용합니다.
이렇게 no-cache를 설정해주었습니다. 그 다음으로 필요한 것은 ETag라는 속성입니다. no-cache를 통해서 지속적으로 서버에 새로운 데이터가 있는지 묻습니다. 그와 동시에 무조건 함께 사용해줘야하는 속성이 ETag입니다. 이 ETag는 특정한 리소스에 대한 토큰을 발급합니다. 그래서 해당 토큰값을 가지고 있다가, 컨텐츠가 변경되는 것을 감지하면 새로운 토큰을 발급합니다. 그런 다음 토큰 값을 비교하면서, 서로 다른 토큰값이라는 것이 확인되면, 컨텐츠에 변경이 생겼다는 것을 알아차리는 방식입니다.
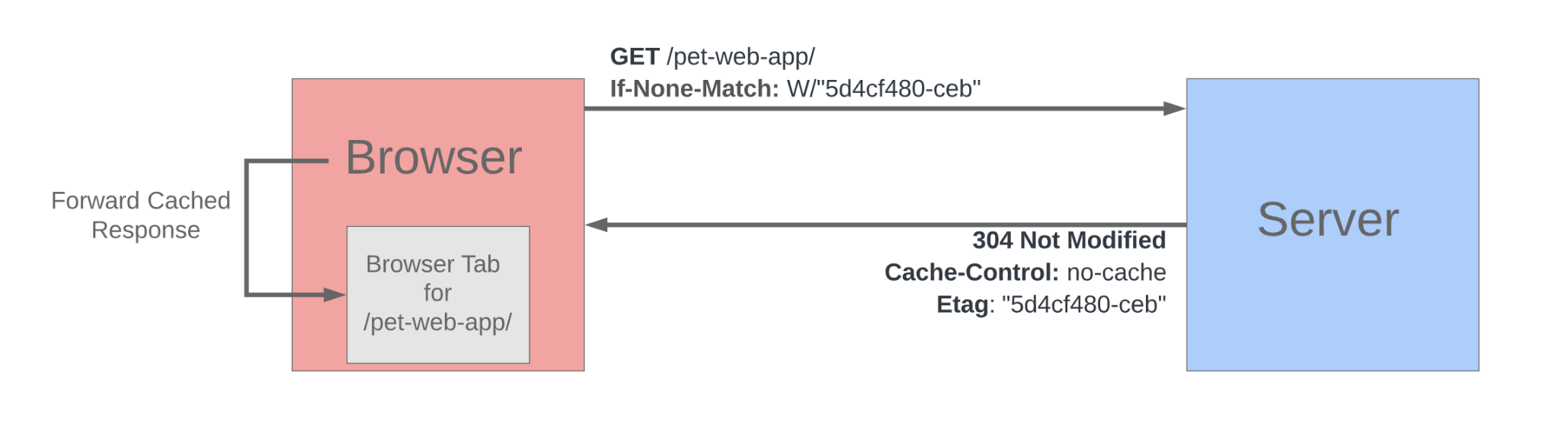
위 그림을 보시면 If-None-Match 헤더에 특정 토큰값이 명시된 것을 확인할 수 있습니다. 해당 필드에 명시된 토큰값과 내가 요청하는 리소스에 대한 토큰값이 같은지를 묻고 있는 것입니다. 그리고 확인해본 결과, 서버측에서는 해당 토큰값이 같다고 판단했습니다. 그리하여 304 상태코드와 함께 응답을 보내줍니다. 그러면 브라우저입장에서는 안심하고 캐싱되어있던 리소스를 그대로 사용하면 되는 것입니다.
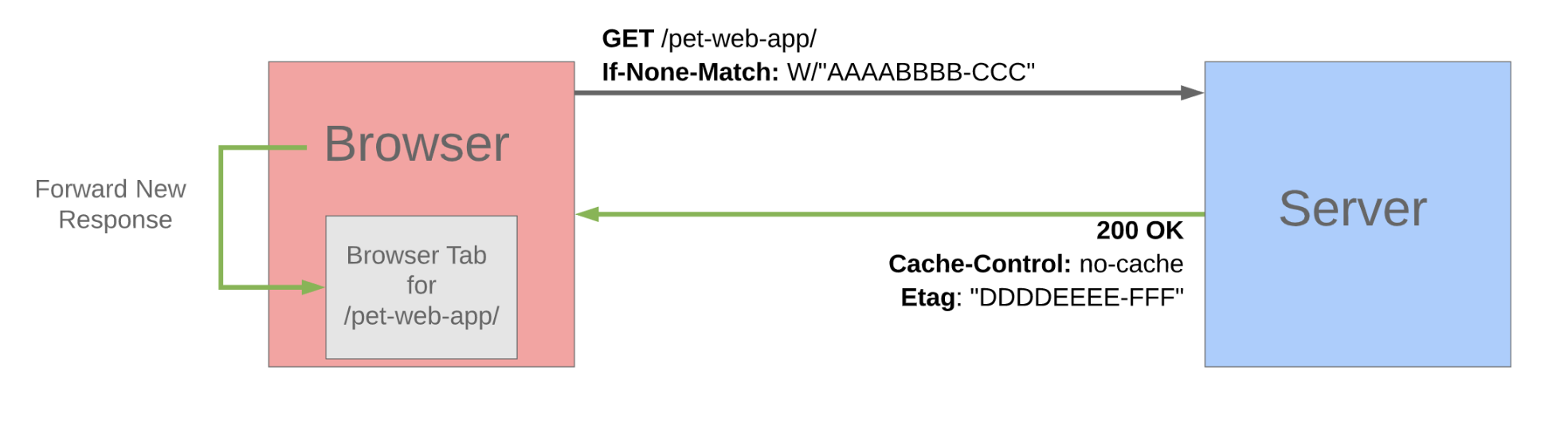
다음은 토큰이 일치하지 않는 경우입니다. 마찬가지로 If-None-Match 헤더에 특정 토큰 값을 담아서 확인을 요청합니다. 그런데 서버에서 확인을 해보니, 토큰 값이 다른 것입니다. 그래서 200상태 코드, 변경된 리소스, 새로운 ETag를 함께 응답으로 보내줍니다.
이것이 바로 mutable한 데이터에 대한 캐싱 전략입니다. 다음으로는 immutable한 데이터에 대한 캐싱 전략을 알아보겠습니다.
2) immutable 데이터에 대한 캐싱 전략 :
immutable한 데이터는 어떤 것들이 있을까요? 대표적인 예시에는 이미지가 있습니다. 이미지 같은 경우에는 그 내부적인 내용을 변경시킬 가능성이 매우 적습니다. 또한 버전 관리를 하고 있는 js 파일같은 경우에도 immutable한 데이터라고 할 수 있습니다. 1.0버전의 js 파일 내부를 변경시켰다는 것 자체가 이미 1.0버전이 아닌 1.1버전으로 가고 있는 것이니까요. 두 파일은 아예 다른 파일로 구분됩니다. 그리고 파일에 붙는 이름도 app_v1.js에서 app_v2.js로 변경될 것입니다. 이런 식으로 내부내용에 변경사항이 없는 리소스를 향해서 우리는 immutable한 리소스라고 부릅니다. 그리고 우리는 이런 리소스를 관리할 때, 리소스에 특정 URL을 붙이고, 그 URL에 따라서 캐싱을 관리하게 됩니다. 이런 전략을 cache-busting 패턴이라고 부릅니다. 그럼 이 immutable한 데이터의 캐싱 전략을 자세히 알아보겠습니다.
먼저 cache-control헤더에 max-age 를 설정해줍니다. max-age에 명시된 초수 만큼 캐싱을 유지하겠다는 의미가 됩니다. 저희는 유저가 이미지를 다운받은 후에 이후로는 반복해서 다운로드하도록 만들고 싶지 않습니다. 때문에 max-age의 길이를 31536000으로 설정해줍니다. 이는 1년을 나타내는 숫자입니다. 1년 동안 해당 데이터에 대해서 캐싱을 실행하겠다는 의미가 됩니다. 만약 우리가 요청하는 리소스에 변경이 생긴다면, 해당 리소스는 아예 새로운 리소스로 판단합니다. 그래서 해당 리소스를 요청할 수 있는 URL로 다시 불러오는 것입니다.
참고자료 : frontend caching quick start
참고자료 : http cache
5.컨텐츠 협상(Content-nagotiation)
컨텐츠 협상. 협상이 무엇입니까? 상호간에 협의를 통해서 어떤 일을 결정하는 것을 말합니다. HTTP는 컨텐츠에 대해서 어떤 협상을 진행하려고 하네요. 이 컨텐츠에 대한 협상은 왜 필요한 것일까요?
request가 들어오고, response를 보냅니다. 이 response안에 포함되어 있는 내용들은 결국 사람에게 해석되는 정보입니다. 따라서 자연적으로 그것을 해석하는 사람에게 가장 적합한 형태로 제공하려는 욕구가 생겨납니다. 아쉽지만 모든 사람들에게 '최고'인 형태가 같을 수가 없습니다. 또한 브라우저가 지원가능한 컨텐츠의 형태에도 제한이 있을 수 있었습니다.(그 당시에는 그랬을 것 같습니다.) 그런 이유로 HTTP는 Content-nagotiation이라는 기능을 제공하게 되었습니다.
Content-nagotiation은 다양한 표현방식이 가능한 가운데 최고로 적합한 방식을 선택하는 과정을 이야기합니다. 어떤 종류의 응답도 협상의 대상이 될 수 있습니다. 에러도 포함합니다.
이런 컨텐츠 협상에는 2가지 종류가 있습니다. 서버주도 협상(server driven nagotiation)과 클라이언트 주도 협상(client driven nagotiation)입니다. 이것들은 분리되어 사용할 수도 있고, 두개 모두를 결합해서 사용할 수도 있습니다.
만약 적합한 컨텐츠를 제공하는 알고리즘이 서버쪽에 속해있다면, 서버주도 협상이라고 할 수 있습니다. 클라이언트 쪽에 속해있다면? 클라이언트 주도 협상이라고 할 수 있겠죠?
헤더는 응답-요청에 포함된 아스키코드를 읽을 수 있는 덕분에, 컨텐츠 전환에 굉장히 용이합니다. 이것에 사용되는 헤더가 바로 Accept입니다. 클라이언트는 "Accept" 헤더를 사용합니다. 이를 통해 서버에게 어떤 컨텐츠와 미디어 타입을 수용할 수 있는지 알릴 수 있습니다. 예를 들어 Accept 헤더는 다음과 같이 사용됩니다.
Accept: */* - 모든 것이 수용가능합니다.
Accept: text/plain; text/html - plain text와 html 파일이 수용가능합니다.
Accept: text/html; image/jpeg; image/bmp - html,image,bitmap 이미지가 수용가능합니다. HTTP/1.1버전으로 넘어오면서 확실히 다양한 부분에서 스마트하고, 최적화가 되어져가고 있다는 것이 느껴지는 군요! 컨텐츠 협상 자체를 더 깊이 알고 싶으시다면 아래의 자료들을 참고해보시면 좋을 것 같습니다.
RFC2068 - two kind of nagotiation
MDN - Content_negotiation
RFC-2068 Content negotiation
Understanding Application Layer Protocols
6.Host 헤더
Host 헤더는 웹서버에게 어떤 가상 호스트를 사용하는지를 알려줍니다. Host 헤더는 아래와 같이 작성됩니다.
GET /static/img/header-background.png HTTP/1.1
Host: developer.mozilla.org그러면 Host헤더에 등록된 주소로 GET 이후에 나열된 path를 활용해 리소스를 요청하게 됩니다. (developer.mozilla.org/static/img/header-background.png 이곳으로 요청을 보내게 됩니다.)
이런 Host 헤더는 왜 필요해진 것일까요? 기존 HTTP/1.0버전에서의 문제점이 있다면, GET 요청을 서버에 보낼 때 host 를 포함하지 않는다는 것이었습니다. 이것은 서버팜에서 사용되는 가상 호스팅에서 문제가 되었습니다. 이것이 정상적으로 유저가 요청한 경로와 페이지를 찾기 위해서는 위해서는 host 정보가 있어야했습니다. HTTP/1.0 이후 버전부터는 요청할 때, 무조건 이 host가 포함되어 있어야 합니다. 만약 host헤더 필드가 포함되어 있지 않다면, 400에러를 받게 될 것입니다.
*서버팜 : 서버로써 동작하는 수 없이 많은 컴퓨터들의 그룹을 의미한다. 보통 서버기능을 제공하는 단체에 의해서 운영된다.
*가상호스팅 : 하나의 서버에 여러개의 서버를 host하는 방식을 말한다.
7.다양한 메서드 지원
HTTP/1.0버전 까지만 해도 GET POST HEADER 이 3가지 메서드밖에 지원하지 않았습니다. 드디어 HTTP/1.1이 표준이 되면서 다양한 형태의 메서드를 지원하게 되었습니다.
- GET : 리소스 조회한다.
- POST : 요청된 데이터를 처리한다. 주로 데이터 등록에 사용된다.
- PUT : 리소스를 대체할 때 사용한다. 해당 리소스가 없으면 직접 생성한다.
- PATCH : 리소스를 일부만 변경시킨다.
- DELETE : 리소스 삭제한다.
- HEAD: GET과 동일하지만 메시지 부분을 제외하고, 상태 줄과 헤더만 반환한다.
- OPTIONS: 대상 리소스에 대한 통신 가능 옵션을 설명한다.(주로 CORS에서 사용)
- CONNECT: 대상 자원으로 식별되는 서버에 대한 터널을 설정한다.
- TRACE: 대상 리소스에 대한 경로를 따라 메시지 루프백 테스트를 수행한다.
⛔️ HTTP/1.1이 가진 한계
분명 HTTP/1.1은 1.0에 비해 많은 성능 최적화를 이루었습니다. 그럼에도 불구하고 한계는 존재했습니다. HTTP/1.1 섹션을 마무리하기 전에 그 한계를 알아보겠습니다. HTTP/1.1의 한계는 곧 HTTP/2.0 탄생의 배경이 되기도 합니다.
1. HOL Blocking (Head Of Line Blocking)
HTTP/1.1에서 keep-alive기능이 도입되고, 파이프라이닝을 통해 다수의 요청을 연속적으로 보낼 수 있게 했습니다. 성능이 크게 향상되었습니다. 그러나 이 파이프라이닝에도 한계가 존재했습니다. 앞 번에 보냈던 요청에서 병목이 생기면, 이후에 들어왔던 요청에 대한 작업이 마무리가 되었어도 응답으로 보내지 못하는 현상이 생긴 것입니다. 이렇게 이전에 있었던 요청에 대해서 이슈가 생김으로 이후의 응답들에 병목이 생기는 현상을 Head Of Line Blocking이라고 부릅니다. 때문에 이런 문제를 해결하고자 사람들이 사용했던 방법이 있습니다. Multiple Connection입니다.
Multiple connection이란 여러 개의 TCP 커넥션을 생성하는 것입니다. 이렇게 여러 커넥션을 생성하게 되면 특정 커넥션에서 이슈가 생긴다할지라도 다른 커넥션에선 병목현상이 생기지 않습니다. 그러면 이를 통해 모든 문제가 해결된 것일까요? 그렇지 않습니다. 이 Multiple Connection도 한계가 있었으니, 그 수가 늘어날 수록 서버와 클라이언트 사이에 많은 오버헤드가 생겨나게 되고, 대역폭에 대한 경쟁이 심해진다는 단점이 있었습니다. 특히나 오늘날처럼 많은 데이터가 요청되는 웹에서 분명 한계점이 존재했습니다. 여기 Multiple Connection에 대한 자료가 있습니다.
using multi connection
2. 무거워진 헤더
웹이 발전하면서 웹을 통해서 전달할 수 있는 수 없이 많은 데이터가 생겨나게 되었습니다. 또한 필요로 하는 데이터도 많아지게 되었고, 그에 따라 요구되는 기능과 옵션들이 추가되었습니다. 이 말인즉 헤더에 많은 정보가 들어가게 되었다는 것입니다. 이 헤더의 무게가 무거워짐으로 인해서 네트워크의 성능을 저하시키는 측면이 있었습니다. 이런 문제를 해결할 필요가 있었습니다.
HTTP/1.1은 약 15년간 표준의 자리를 유지해왔습니다. 굉장히 긴 시간이었습니다. 그러나 2015년에는 후세대에게 자리를 내어주게 됩니다.
✨HTTP/2 - 더 나은 성능을 위한 프로토콜
HTTP/2.0의 등장배경 :
앞서 살펴보았듯, HTTP/1.1에서는 많은 기능이 추가되고 이전에 비해 성능도 훨씬 좋아졌습니다. 그러나 발전이 거듭될 수록, 브라우저에서 사용되는 요청의 수나 컨텐츠의 무게도 달라지게 되었습니다. 이런 HTTP/1.1에서의 한계를 느끼고 구글은 먼저 SPDY라는 실험적인 프로젝트를 진행했고 그것을 2009년에 발표했습니다. 이는 HTTP의 속도를 매우 향상시키는 기술입니다.
이런 기술에 관심을 가진 대형 IT회사들 곧, 페이스북, 클라우드페어, 워드프레스 같은 사이트에서도 SPDY를 사용하게 되었습니다. 그러다보니 SPDY는 점점 업계의 암묵적 표준이 되어가고 있었습니다. 이내 SPDY는 IETF의 관심을 끌게 되었고, IETF는 2012년에 이 SPDY를 HTTP/2.0의 기초로 사용하겠다고 결심했습니다. 그렇게 HTTP/2.0이 시작되었습니다. 3년간의 개정 후에 2015년에 표준으로 발표되었습니다. 그리고 몇달이 지나 구글에서는 SPDY라는 실험적 프로토콜을 deprecated시켰습니다. 표준화를 위해 기여한 것에 그저 감사할 다름이라는 소감을 밝히면서요.
아마 이 SPDY가 어떤 프로토콜인지를 설명하는 것은 곧 HTTP/2.0을 설명하는 것과 겹치는 것이 같을 것입니다. 때문에 SPDY에 대한 내용을 링크로만 남기고 곧바로 HTTP/2.0을 설명하도록 하겠습니다.
https://www.chromium.org/spdy/spdy-whitepaper/
SPDY는 무엇인가?
HTTP에서는 몇가지 중대한 변화들이 있었습니다.
- Binary Framing layer
- MultiPlexing
- Stream prioritization
- Compress Header
- Server Push
외에도 몇 가지 추가사항들이 있었지만, 본 글에서는 다음의 5가지에 대해서만 다뤄보도록 하겠습니다.
1.Binary Framing Layer :
Binary Framing Layer는 어쩌면 HTTP/2.0에서 가장 중대한 변화입니다. 이것은 거의 모든 성능 최적화의 기반이 됩니다. 아래 사진을 보시면 알 수 있듯이 이 Binary Framing Layer는 전송계층(TCP)과 어플리케이션 계층(HTTP) 사이에 놓여있습니다. 또한 이 Layer라는 단어, 즉 계층이라는 단어가 우리에게 알려주는 것은 이것이 새롭게 최적화된 인코딩 메커니즘이라는 것입니다.

기억해야할 사실이 있다면, HTTP/2.0에서는 이렇게 새롭게 인코딩된 메커니즘을 사용하기 때문에 이전 버전과는 호환이 되지 않습니다. 마찬가지로 서버에서 H2를 사용하는데 클라이언트에서 H1을 사용한다면 이용할 수 없고, 그 반대도 똑같습니다. 반드시 양 측은 같은 버전을 사용해야 합니다.
아무쪼록 이 Binary Framing Layer는 데이터를 교환하는 방식을 매우 많이 바꿔놓았습니다. 어떻게 바꿔놓았는지를 설명하기 위해서는 여기에 사용되는 핵심 용어들을 이해할 필요가 있습니다. 바로 스트림, 메시지, 프레임입니다. 이 단어들에 주목해주세요.
- 스트림 : 스트림은 하나의 커넥션 안에서 생성된 양방향의 바이트 흐름입니다. 이 스트림은 한 커넥션 안에서 여러 개가 생성될 수 있습니다. 또한 하나 혹은 여러 개의 메시지를 가질 수 있습니다. (스트림이 양방향이라는 말은 뒤에서 차차 설명하겠습니다.)
- 메시지 : 프레임들의 시퀀스를 말하며, 논리상의 요청과 응답 메시지들에 매핑되어있습니다.
- 프레임 : H2통신에서 가장 작은 단위입니다. 이 프레임들은 각각 식별자를 가지고 있는데, 이 식별자는 해당 프레임이 어디 스트림에 속해있는지를 나타냅니다.
사실 이렇게 단어의 정의만 보면 잘 이해가 안될 수도 있습니다. 걱정마세요. 아래에서 차근차근 설명해나갈 것이고, 읽다보면 이해한 여러분을 보게될 것입니다.

그림을 먼저살펴보겠습니다. (여기선 조금 호흡을 천천히 가져주세요.) 보시면 데이터를 주고받는 스트림 1이 존재합니다. 그리고 각각의 요청와 응답 메시지들이 왔다갔다 합니다. 이 메시지들에는 프레임이 바인딩 되어 있습니다. 그 프레임은 하나일 수도 있고 2개일 수도 있습니다. 이 프레임에는 헤더 데이터도 들어가고, payload의 값도 들어갑니다. 잘 보시면 각 프레임의 헤더마다 이 프레임이 어느 스트림에 속해있는 것인지 식별자가 붙어있습니다. 현재 사진에 stream1이라고 붙어있는게 보이시나요? 추후에 이 스트림 식별자를 통해서 쪼개어진 데이터들을 다시 조합합니다. 곧 소개하겠지만, 이것이 MultiPlexing의 근간이 됩니다. 아직도 이해가 안되셨다면, Multiplexing을 읽으시면서 더 이해가 될 것입니다.
binary protocol : (깨알설명)
이렇게 만들어진 H2는 binary로 이루어진 프로토콜입니다. 기존의 HTTP는 아스키코드 기반의 textual 프로토콜이었습니다. 그런데 H2에서 binary 프로토콜로 바뀌었습니다. 왜 이런 변경사항이 생긴 것일까요? 사실 아스키코드 기반의 프로토콜은 사람이 이해하기엔 좋았습니다. 하지만 컴퓨터가 이해하기에는 어려움이 있었죠. 경우에 따라서 빈 공간이 들어가기도 하고, 몇몇 종료 시퀀스나, 기타 특이사항들은 프로토콜을 페이로드와 구분하기 어렵게 만들기도 했고, 보안상의 문제도 있었습니다. 이런 문제점들을 커버하면서도, 훨씬 강력한 성능을 가져다주는 binary 프로토콜을 이용하게 되었습니다.
2.Multiplexing
이제 MultiPlexing을 설명해보겠습니다. 이것을 설명하기 전에, Multiplexing의 의미를 이해할 필요가 있을 것 같습니다. Multiplexing은 동시에 요청을 보내고, 순서에 상관없이 응답을 받을 수 있는 기술입니다. 그럼 MultiConnection과는 어떤 차이가 있을까요? MultiConnection은 다수의 TCP 커넥션을 생성합니다. 하지만 Multiplexing은 하나의 TCP 커넥션 안에서 다수의 요청을 보내고, 다수의 응답을 순서에 상관없이 받을 수 있게 합니다.
도대체 이런 기술이 어떻게 가능하게 된 것일까요? 앞서 저는 Binary Frame Layer가 Multiplexing의 근간이 된다고 말씀 드렸습니다. 맞습니다 Binary Frame Layer가 이 일을 가능하게 합니다. H2에서는 하나의 커넥션 안에서, 데이터를 주고받을 때(요청과 응답) 각각 다른 스트림을 사용합니다. 그리고 프레임에는 각각 스트림에 대한 식별자를 가지고 있습니다. 때문에 다수의 요청과 응답을 아무렇게나 보내더라도, 어떤 스트림에 속해 있는지 식별자를 가지고 있기 때문에 스트림의 작업이 끝났을 때, 각각 알맞는 스트림 식별자를 확인하고 재구성할 수 있습니다.
이 프레임들이 다수의 메시지를 동시에 보낼 수 있게 하는 핵심입니다. 정확히 말하면 프레임의 식별자라고 할 수 있겠죠? 이 프레임에 메시지가 어떤 스트림에 속해있는지에 대한 정보가 들어가 있기 때문에 순서를 신경쓰지않고 아무렇게나 보내도 괜찮습니다.
아래의 애니메이션을 보시면 실제로 어떻게 '동시에' 메시지가 왔다갔다하는지를 이해할 수 있을 것입니다.

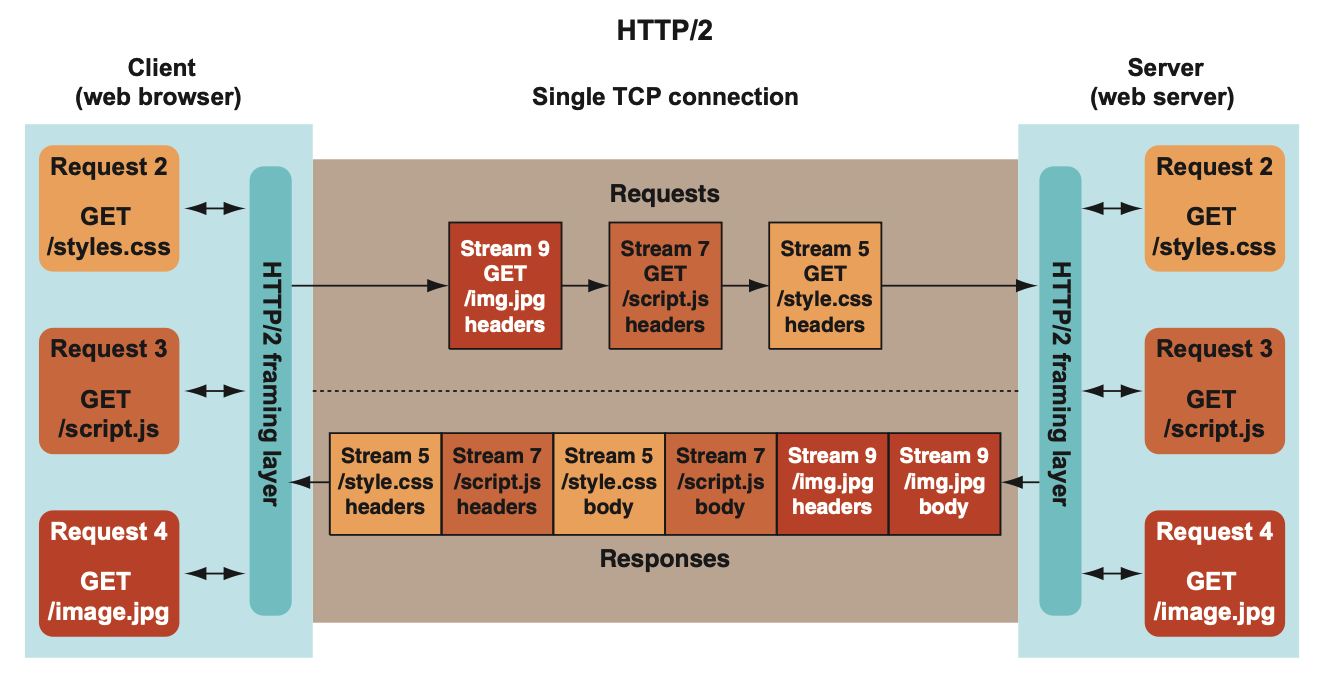
보시면 하나의 커넥션 안에서 다수의 요청 연속적으로 날아갑니다. 그리고 응답으로 돌아올 때는, 요청보냈던 순서와 상관없이 뒤죽박죽으로 날아옵니다. 위 사진을 보시면 Stream5와 Stream7이 막 섞여 있습니다. 사실 Stream9가 더 앞에 위치해 있어도 상관없습니다. 이렇게 뒤죽박죽으로 날아와도 괜찮은 이유가 뭐라고 했죠? 이 메시지들이 어떤 스트림에 속해있는지에 대한 식별자를 가지고 있기 때문입니다. 마지막에 이 메시지들이 바이너리 프레임 계층에 도착해서 그 식별자를 확인하고, 재구성해 줄 수 있기 때문에 순서를 아무렇게나 보내도 상관없는 것입니다.
사실 조금 당황하셨을 수도 있을 것 같습니다. 분명히 '동시에'라고 했는데, 지금 보이는 그림은 '동시에'가 아니기 때문입니다. 맞습니다. 엄밀히 말하면 '동시에'가 아닙니다. 하지만, HTTP/1.1과 비교했을 땐 '거의' 동시에 라고 봐도 괜찮습니다.
HTTP/2.0도 마찬가지로 TCP 위에서 동작합니다. 그리고 각각의 메시지들이 왔다갔다 하기 위해서는 그 커넥션을 탈 수 밖에 없습니다. 때문에 줄줄이(queue) 메시지들이 왔다갔다해야만 하는 것입니다. 하지만 HTTP/2.0의 가장 핵심되는 포인트는 요청을 보내고나서 응답을 받을 때까지 기다리지 않아도 된다는 것입니다. 요청을 보내고 받는 것은 순서에 상관없이 받을 수 있다는 점이 바로 HTTP/2.0의 핵심입니다.
그림이 나온 겸 스트림에 대한 부분도 조금 더 설명해보겠습니다. 보시면 요청을 보낼때의 스트림의 ID에는 5,7,9가 포함되어 있었습니다. 그리고 응답을 받을 때도 스트림의 ID는 5,7,9로 라벨링 되어있습니다. 이것이 바로 스트림이 양방향적이라는 것의 의미입니다.
각각의 스트림은 응답까지 보내고나면 close됩니다. 스트림은 재사용되는 것이 아닙니다. 또한 이 스트림이 어떤 실제 커넥션이 아니라, 하나의 가상의 개념(logical concept)이라는 것도 기억해두시면 이해하는데에 도움이 될 것 같습니다. 스트림의 실질적인 의미는 프레임에 붙어있는 스트림 식별자에서 그 역할을 발휘합니다.
혹시 multiplexing이 어떻게 가능해지는지 이해하셨을까요? 만약 해당 내용을 이해하셨다면 H2의 핵심을 거의 이해하셨다고 보셔도 좋습니다. 하지만 아직도 잘 이해가 안되셨다면, 심호흡한번 하고 마음을 차분하게 가진 다음, 다시 한번 읽어보세요. 다시 읽을 땐 여러분의 뇌가 지식을 받아들일 준비가 되어 있을 것입니다🤓
3.Stream prioritization
H2 이전에는 무조건 요청-응답 순서로 이루어지는 프로토콜이었기 때문에, 프로토콜 내에서 우선순위를 매길 필요가 없었습니다. 만약 우선순위를 매기고 싶은 요청이 있으면 그냥 '먼저' 보내면 됩니다. 프로토콜 내부에서 우선순위를 정하는 것이 아니라, 외부에서 순서를 정하고 보내면서 우선순위를 정하는 방식이었습니다.
H2에서는 한 번에 보낼 수 있는 요청의 수가 매우 많아졌습니다.(대부분의 경우 100개 정도의 스트림을 활성화할 수 있습니다.) 때문에 프로토콜 외부에서 순서를 굳이 지정해 줄 필요가 없어졌습니다. 하지만 이렇게 되는 경우 우선순위가 낮은 리소스에서는 대역폭의 낭비가 생길 수도 있고, 경우에 따라서는 화면에 리소스가 나타나는 것이 느릴 수도 있습니다. 이런 문제를 해결하기 위해서 Stream Prioritization도입되었습니다.
Stream Proritization은 weight를 통해서 지정할 수 있습니다. A 스트림과 B스트림이 존재한다고 가정해보겠습니다. A 스트림이 더 중요한 우선순위를 가지므로 12의 weight를 부여했습니다. 그리고 B에는 4의 weight를 부여합니다. 이제 H2에서 각 스트림의 우선순위를 매기기 하기 위해서 A + B의 weight를 계산합니다. 16입니다. 그리고 전체 weight에서 각각의 스트림의 weight를 나눕니다.
- A : 12 / 16 => 3/4
- B : 4 / 16 => 1/4
결국 A가 승리했습니다. 고로 A의 작업을 처리하기 위해서 서버 쪽에서 사용되는 CPU, memory 등등 대부분의 자원들이 3/4만큼 투자될 것입니다. 나머지 리소스는 B를 위해서 사용되겠지요. 이런 방식으로 스트림의 우선순위가 정해집니다.
당연한 말이겠지만, 스트림의 우선순위가 높을 수록, 더 일찍 응답이 도착하게 될 확률이 높아집니다. 그리고 이런 전략은 때때로 성능의 향상을 위해서 매우 유용합니다.
4.Compress Header
H1 에서 설명드렸듯이, 헤더는 요청과 응답에 대한 메타 데이터를 담고 있습니다. 하지만, 이 헤더에는 꽤나 반복적이 내용들이 많이 들어가 있습니다. Cookie, User-Agent, Host, Accept, Accept-Encoding 과 같은 헤더들이 예시가 될 것 같습니다. 이런 헤더들은 반복될 수 있고, 또한 낭비적이기도 합니다.
HTTP/1에서는 바디 부분을 압축할 수 있는 기능(Accept-Encoding)을 지원하긴 하지만, 헤더를 압축하는 기능은 없었습니다. HTTP/2에 들어서선 이런 압축 기능을 제공합니다. 헤더에는 중요한 정보도 많이 담겨있고, 보안적인 안정성도 필요하기에 HPACK이라는 기술을 적용해 압축을 진행합니다.
5.Server Push
H2의 또 다른 중대한 변경은 server push가 추가되었다는 점입니다. 이 기능은 클라이언트에서 특정 리소스에 대한 요청이 없어도, 여러 개의 리소스를 같이 보낼 수 있게 합니다.
예를 들어서, HTTP1의 경우 브라우저가 화면에 나타나면, HTML을 요청합니다. 그리고 Head영역에 담겨있는 css와 js파일을 읽고 각각에 대한 파일을 다시 서버에 요청합니다. 그러나 H2의 경우에는 첫번째 HTML파일을 요청할 때, css와 js 파일을 같이 응답으로 보내줄 수 있습니다. 그러니까 클라이언트가 서버에게 "이 페이지좀 받을 수 있을까?" 라고 물어보면, 서버는 "그럼! 여기 너가 필요할 것 같은것도 같이 보내줄께"라고 보내주는 것입니다.

H2에 이런 서버 푸시 기능이 도입됨으로써, H1에서 화면을 보여주기 위해 들었던 RTT가 확연히 줄어들게 되었습니다.
⛔️ HTTP/2.0 의 한계 :
HTTP/2.0은 정말 많은 성능의 향상을 이루어냈습니다. 그러나 이런 HTTP/2.0에도 한계가 존재했습니다. 바로 이 프로토콜 또한 TCP 위에서 동작한다는 점입니다. HTTP/2.0이 아무리 많은 발전을 이루어내도, 결국 TCP 위에서 동작하기 때문에 TCP가 가진 한계를 벗어날 수가 없었습니다. 그래서 결국 TCP를 버리고 UDP를 선택하는 움직임이 생겼습니다. 그렇게 UDP 위에 만들어진 프로토콜이 QUIC입니다.
해당 내용을 알아보기 전에 H2의 한계를 알아볼 것입니다. 어쩌면 H2의 한계를 알아보는 것은 곧 TCP의 한계를 알아보는 것일지도 모르겠습니다. 여러가지 한계점이 있겠지만, 이 시간 다뤄볼 내용은 크게 2가지 입니다.
1)TCP의 느린 연결 수립 :
2)TCP레벨에서의 HOLB(Head Of Line Blocking) :
1) TCP의 느린 연결수립 :
TCP는 데이터 전송의 신중함을 위해서 연결 수립에 긴 시간이 소요됩니다. 이것을 위해서 진행되는 것이 3-way-handshake입니다. 여기에 더해 보안까지 신경을 쓰게되면 연결수립 과정이 더 길어집니다. 이런 과정들이 왜 필요하게 된 것인지에 대해서 이해해보고, 그 한계점을 알아보겠습니다.
3-way-handshake는 왜 느릴까요? 이것은 왜 필요한 것일까요? 이를 이해하기 위해선 먼저 TCP를 간략히 이해할 필요가 있겠습니다. TCP는 신뢰성, 안정성을 중요하게 생각하는 프로토콜입니다. 내가 데이터를 보냈을 때, 이것이 중간에 손실되지 않고 확실하게 받고, 보내겠다. "확실하고, 안전하게." 여기에 힘을 쏟은 프로토콜이 TCP입니다.
TCP는 어떻게 신뢰성을 보장하는가?
TCP가 확실하게 데이터를 주고 받기 위해서 사용하는 것이 일련번호(sequence number)입니다. TCP에서는 데이터를 보낼 때, 여러 개의 패킷으로 나누어보냅니다. 한번에 많은 데이터를 보내는 경우 대역폭을 많이 차지할 수 있기 때문에 그렇습니다. 이때, 패킷에 sequence number가 새겨짐으로써 중간에 손실된 데이터가 없도록 만듭니다.
예를 들어서 A 패킷을 a와 b로 나누었다고 해보겠습니다. a에 새겨져있는 일련번호는 1번이고, b에 새겨진 번호는 2번입니다. 클라이언트 쪽에서 처음에는 1번이 새겨진 데이터를 받았습니다. 그럼 그 다음에는 2번이 새겨진 데이터를 받을 것을 기대할 수 있습니다. 그런데 7번이 새겨진 데이터가 온 것입니다. "어 이거 이상해! 다시 데이터 제대로 보내줘." 라고 말할 수 있는 근거가 sequence number로 부터 제공되는 것입니다. 이 sequence number 덕분에 데이터를 신뢰하고 받을 수 있게 된 것입니다.
TCP에 3-way-handshake는 왜 필요한가?
이렇게 sequence number를 사전에 확립하기 위해서 진행하는 과정이 3-way-handshake입니다. 조금 더 설명해보겠습니다. TCP는 양방향 통신입니다. 때문에 클라이언트도, 서버도 데이터를 보낼 수 있습니다. 그렇다면 양측 모두가 이용가능한 일련번호가 필요할 것입니다. 이때 맨처음에 생성하는 일련번호를 ISN(Initial Sequence Number)라고 합니다. 그리고 둘 다 서로의 초기 일련번호를 알 필요가 있습니다. 이것을 위해서 3-way-handshake가 필요한 것입니다. 예를 들어보면 다음과 같습니다.
영희 -> 철수 : 철수야 내 ISN은 256란다.(SYN)
영희 <- 철수 : 너의 ISN을 받았어. 256구나 알겠어(ACKnowledge)!나는 257(256+1)을 받을 준비가 되었어(ACK)
영희 <- 철수 : 영희야 그리고 내 ISN은 567이야 (SYN)
영희 -> 철수 : 너의 ISN을 받았어. 567이구나 알겠어(ACKnowledge)!나는 568(567+1)을 받을 준비가 되었어(ACK)이런 방식으로 3-way-handshake과정이 진행되고, 이 과정을 통해서 양측은 서로의 일련번호를 수립하게 됩니다. 실제로는 철수가 영희에게 ISN을 알았다고 말하는 부분과, 자신의 ISN을 영희에게 전달하는 부분은 동시에 진행됩니다. 이제부터 양측은 데이터가 손실될 걱정 없이 마음 놓고 데이터를 보낼 수 있게 되었습니다. 일련번호가 있으니까요! 문제가 생기면 데이터를 다시 요청하면됩니다. 이런 이유로 3-way-handshake가 필요합니다.
위의 내용을 통해서 알게 되셨겠지만, TCP에서 연결수립을 위해서 3-way-handshake는 필요한 과정입니다. 하지만 여기에 더해 보안을 신경 쓴 TLS handshake가 더해지면 어떻게될까요?

Why do we need a 3-way handshake? Why not just 2-way?
Why does TCP even need a 3-way handshake?
TLS handshake :
TLS는 보안 통신을 위해서 설계된 프로토콜입니다. 그리고 TLS handshake란 이 TLS를 이용해서 안전한 통신을 하기 위한 과정입니다. 이 과정을 통해서 클라이언트와 서버 간에 필요한 암호화 및 인증 정보를 교환하고, 서로간의 통신을 위한 암호화 키를 교환합니다. 이런 과정을 통해서 안전한 통신을 시작할 수 있습니다.
구체적인 TLS 핸드쉐이크의 과정을 설명하는 것은 링크로 대체하도록 하겠습니다. 결국 이 과정을 소개함으로써 제가 말하고 싶은 것은 TLS 핸드쉐이크는 3-way-Handshake가 진행된 다음에 추가적으로 실행된다. 고로 전체적인 RTT가 증가한다.는 것입니다. 아래 사진을 보겠습니다.
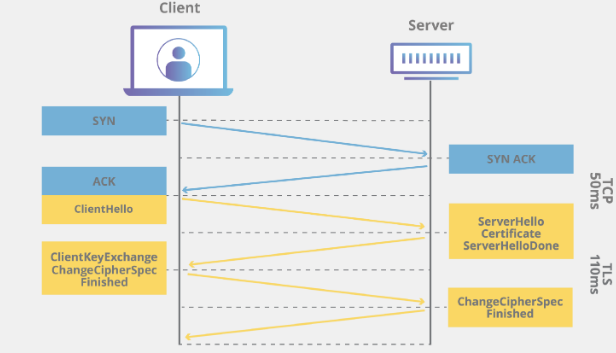
보시면 맨 위에서 3-way-handshake가 진행된 다음, 그 연결에 이어 또 보안을 위한 핸드쉐이크가 진행됩니다. TLS핸드쉐이크가 마무리 된 이후에야 본격적으로 클라이언트가 서버에게 원하는 요청을 시작할 수 있습니다. TLS 1.2버전에 비해서 TLS 1.3버전의 RTT가 줄어들기는 했지만, 마찬가지로 3-way-handshake 이후에 추가적인 handshake 과정이 필요합니다. 결론적으로 production에서는 https를 사용하지 않는 경우가 거의 없고, 그렇다면 TCP에서의 연결 수립은 TLS 1.2버전까지는 3RTT, TLS 1.3 버전이 되어 좋아봐야 2RTT가 걸립니다. 이것보다 더 개선될 수는 없을까요? HTTP3는 가능합니다.
참고 : Key differences Between TLS 1.2 and TLS 1.3
2) TCP레벨에서의 HOLB(Head Of Line Blocking) :
이번엔 TCP가 가지고 있는 HOLB의 문제점을 알아보겠습니다. H2는 H1에 비해 엄청난 속도 향상을 이루었습니다. 하지만, H2도 H1보다 속도가 느린 순간이 있었습니다. 바로 패킷이 손상되었을 때 입니다.
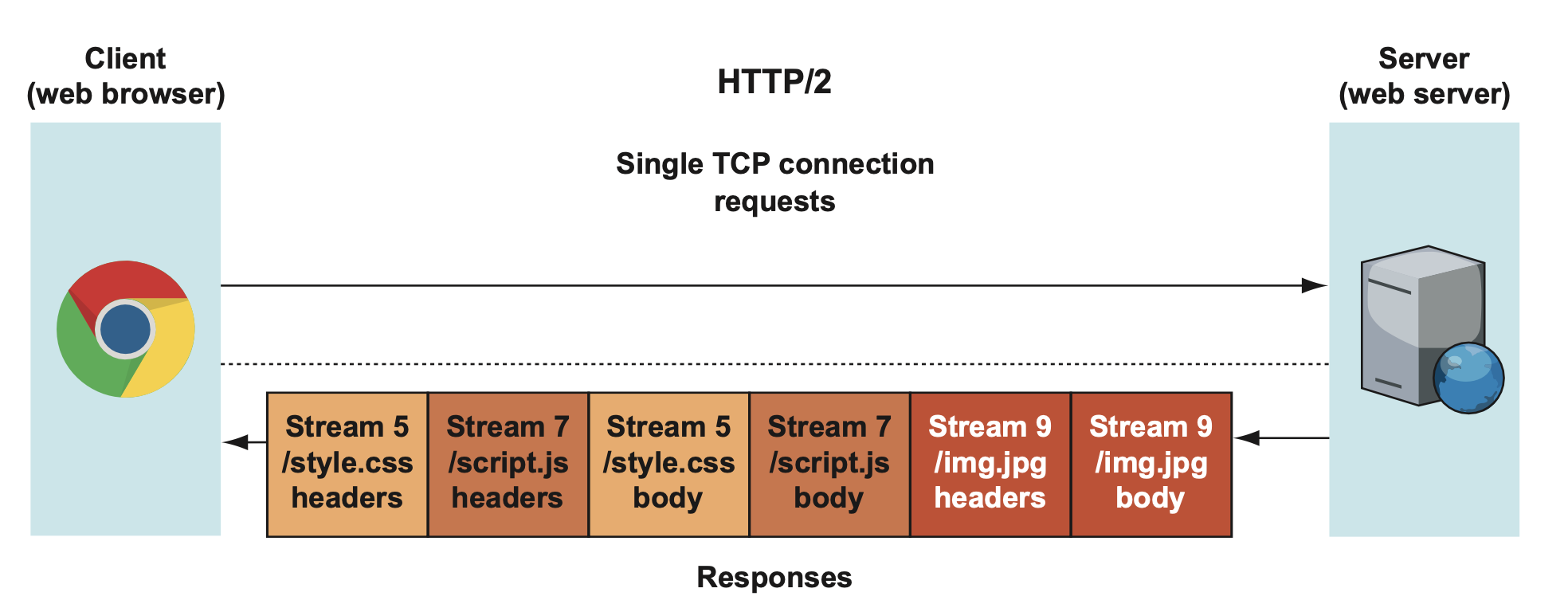
위 그림에는 3가지 스트림이 전송되고 있습니다. stream5, stream7,stream9. 그런데 이 중 맨 앞에 있던 stream5/style.css - headers가 손상되었다고 해보겠습니다. 그럼 제대로 된 패킷을 전달받지 못한 것을 알게된 클라이언트는 이를 서버에게 알립니다. 그리고 서버는 해당 stream5 - headers를 재전송하게 될 것입니다.
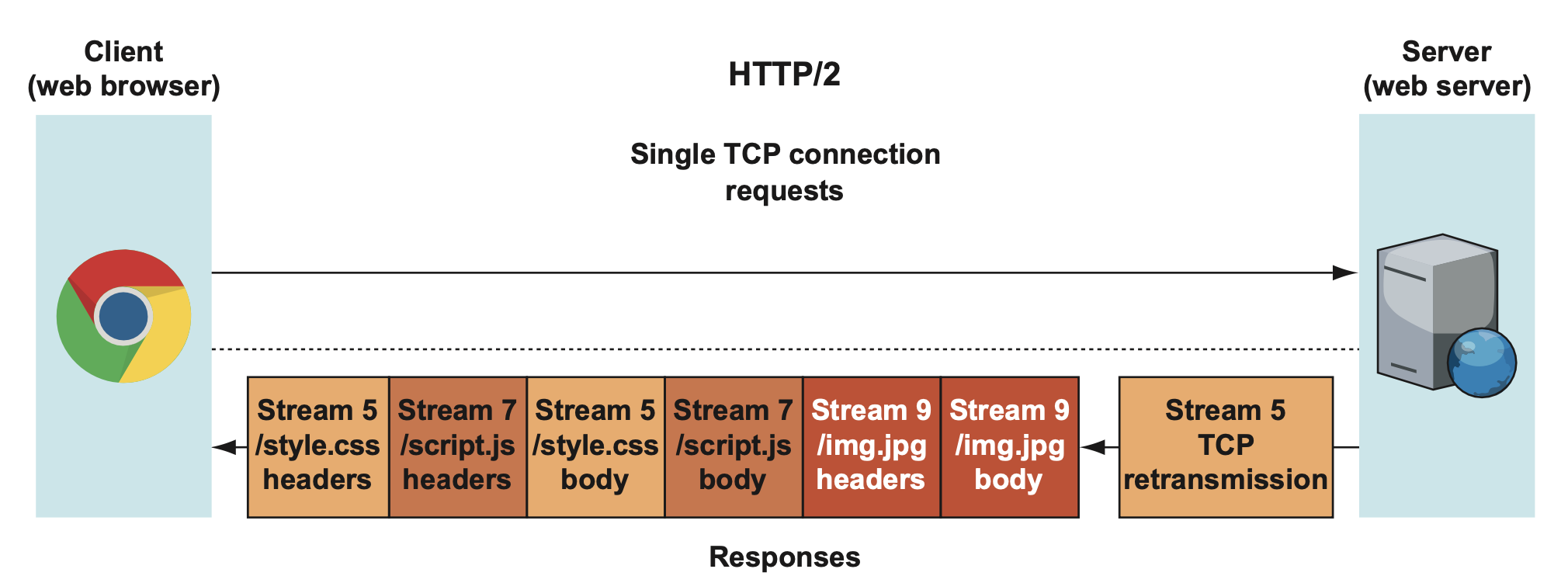
stream5가 제일 마지막 순번으로 전송되는 모습을 볼 수 있습니다. 만약 또 다른 패킷 손상이 일어나지 않았다면 stream7과 stream9는 클라이언트에 도착해서 흩어져있던 프레임들이 재구성되어 있을 것입니다. 하지만, 문제는 TCP는 순서를 보장하는 프로토콜이라는 것입니다. 응답 데이터들은 queue 되어야 하기 때문에 당장에 사용할 수가 없는 한계가 있습니다. 만약 똑같은 상황이 MultiConnection을 사용하는 H/1.1에서 일어났다면, 상황은 달랐을 것입니다.
H/1.1에서는 style.css 파일을 요청한 부분에서 문제가 생겼으면 해당 TCP 요청만 재전송하면 됩니다. 그리고 다른 script, img 파일의 TCP요청은 먼저 도착해서 클라이언트에서 사용되고 있었을 것입니다. 딜레이되는 것은 딱 style.css파일밖에 없는 것입니다.
H2는 Multiplexing을 통해서 HTTP 레벨에서의 Blocking을 해결했습니다. 한가지 리소스에서 발생한 지연이, 다른 리소스에 영향이 미치지 않도록 만들어주었지요. 하지만, TCP 레벨에서의 Blocking은 여전히 남아있었습니다. 하나의 스트림에서 발생한 패킷 손상이 다른 스트림에도 영향을 미치는 한계점이 있었던 것입니다.
이렇게 HTTP2의 한계점까지 알아보았습니다. HTTP1.1버전은 약 15년간 표준의 자리를 유지해왔습니다. 하지만 H2는 약 6-7년의 시간만에 표준의 자리를 내어주게 됩니다.
✨HTTP/3 - HTTP over QUIC
HTTP3는 2020년에 발표되었고, 2022년 6월에 표준화가 완성되었습니다. 위에서 언급했다시피 HTTP/3는 TCP를 선택하지 않았습니다. 아무리 발전을 꿰하려해도 TCP위에서는 한계가 있기 때문입니다. TCP는 신뢰성은 보장되지만 속도가 느리다는 단점이 있으며, HOLB의 문제가 있었고, 해당 문제를 TCP위에서 해결한다 할지라도 전세계적으로 사용되고 있는 네트워크 기기와의 호환성 문제도 있었습니다. 결국 HTTP/3는 UDP를 선택하게 되었습니다.
우선 UDP는 무엇일까요? 간략하게 설명드리자면, 데이터 전송의 안정성을 보장하지는 않지만 빠르게 전송할 수 있는 프로토콜입니다. 예를 들면, UDP는 '던진다~! 오케이 나는 던졌어. 받는건 니 책임~'와 같이 데이터를 전송하기 전과 후에 재차 확인하는 과정이 없습니다. 빠르게 데이터를 전송하지만 신뢰성을 보장하지 않는 프로토콜입니다. 반면, TCP는 '야! 받을 준비됐어? 된 거 맞지? 그럼 보낼께!'와 같이 재차 확인하는 과정을 통해 데이터의 안정성을 보장하면서도 속도가 상대적으로 느린 프로토콜입니다.
UDP는 빠르다고 할 수 있지만, 데이터의 안정성은 보장 못합니다. TCP에 비해 데이터가 손실될 확률이 높습니다. 하지만 이를 보완할 방법이 있기 때문에 HTTP/3에선 UDP를 선택했습니다. UDP의 단점은 QUIC이라는 프로토콜이 보완해줍니다. QUIC은 UDP와 TCP의 장점을 쏙 챙긴 그런 프로토콜이라고 할 수 있는데, 이에 대한 설명과 함께 UDP의 단점은 어떻게 보완되었는지도 설명해보겠습니다.
✨QUIC
HTTP/3은 UDP위에 설계되었다고 말씀드렸지만, 조금 더 엄밀히 말하면 QUIC이라는 프로토콜 위에 설계되었습니다. 그리고 그 QUIC이 UDP위에 설계된 것입니다. 이 QUIC이라는 프로토콜은 구글에서 실험적으로 만든 프로토콜인데, 이후에 IETF의 관심을 끌고, 표준으로 채택되게 되었습니다. HTTP3를 이루고 있는 기술이 QUIC이고 이 QUIC을 이해하는 것이 곧 HTTP3를 이해하는 것과 다를 바가 없다고 할 수 있습니다.
그렇다면 QUIC에서는 어떤 개선점이 있었을까요? 여러가지가 존재하겠지만, 이전 버전의 한계점을 어떻게 개선했는지, 주목할 만한 개선점에는 무엇이 있었는지를 중점으로 놓고 몇 가지 살펴보도록 하겠습니다.
다음은 제가 설명드릴 내용의 목차입니다.
1.빠른 연결 수립 (built-in security)
2.HOLB 문제가 해결된 멀티플렉싱
3.Connection ID
4.UDP의 단점을 보완한 QUIC
1.빠른 연결 수립 (built-in security) :
HTTP2의 한계점을 살펴보면서, TCP의 느린 연결수립에 대해서 알아봤었습니다. TCP에서는 기본적으로 연결수립을 진행한 다음, 보안에 대한 연결을 진행합니다. 때문에 최소 2회 이상의 RTT가 발생합니다. 그런데 QUIC는 1RTT 만에 연결수립와 보안을 동시에 진행합니다. 대단하지 않나요? 한번만에, 연결과 보안 둘 다 챙겨버립니다. 이것이 어떻게 가능할까요?
아래 사진을 보시겠습니다.
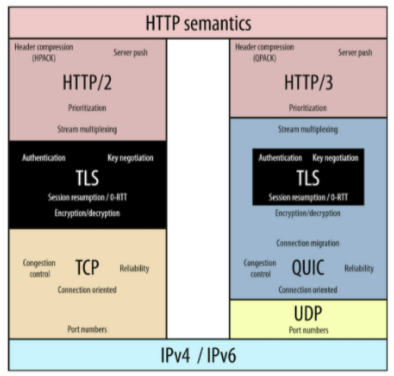
왼쪽 그림을 보면 기존에는 TCP위에 TLS가 독립적으로 존재합니다. 그러나 오른쪽 그림의 QUIC에서는 TLS를 내장하고 있습니다. 이 말인즉, 기존에는 보안 설정을 하기 위해서는 TCP 연결을 수립하고 난 다음, 보안을 위한 추가적인 작업이 필요했지만, QUIC에서부터는 보안을 위해 추가적인 작업을 따로해 줄 필요 없이 기본적으로 내장하고 있게 되었다는 것입니다. 이 때문에 더욱 빠른 연결수립을 하는 것이 가능해졌습니다. 아래의 그림을 보시면 더욱 명확하게 이해될 것입니다.
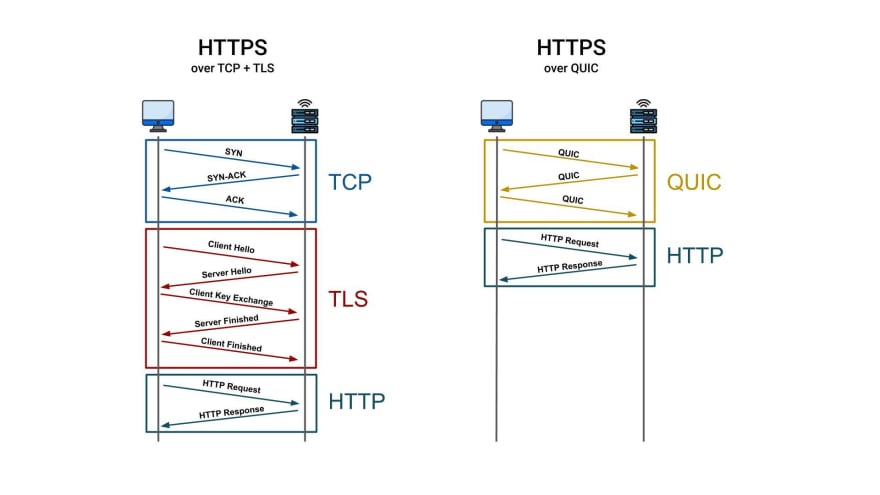
그림과 같이 QUIC에서는 연결 수립을 위해 처음 보내는 요청에서부터, 보안이 필요한 정보까지 함께 보내고 있습니다. 때문에 연결수립과 보안설정까지 1RTT만에 끝낼 수 있습니다. 심지어 사전에 연결했던 적이 있었다면, 이전의 정보를 캐싱해둠으로써 0RTT도 가능해집니다. 참고
이렇듯 QUIC은 TLS1.3 보안 프로토콜의 기능들을 통합함으로써, 암호화의 작업을 어플리케이션 계층에서 전송계층으로 내렸고, 이를 통해서 연결수립의 속도를 높일 수 있었습니다. 추가적으로 보안이 가능해진 영역도 넓어졌는데, 해당 내용은 여기선 다루지 않겠습니다.
2. HOLB가 해결된 멀티플렉싱 :
위에서 살펴봤다시피, HOLB문제는 TCP를 기반으로한 프로토콜의 고질적인 문제점이었습니다. 패킷이 손실되면, 손실된 패킷이 재전송되기 전까지는 전체 데이터 전송의 흐름에 병목이 생길 수 밖에 없었습니다.
그렇다면 이런 문제를 해결하기 위해 각각의 패킷들도 stream별로 구분해주어야 합니다. 이런 일이 어떻게 가능할까요? HTTP2에서 멀티플렉싱이 이루어진 원리와 비슷합니다. HTTP2에서 어떻게 멀티플렉싱이 가능했나요? 바로 프레임에 stream id를 부여했기 때문에 가능했었습니다. 도착한 프레임의 순서가 막무가내여도, 해당 프레임에 부여된 stream id를 확인해서 각각의 stream에 맞게 프레임을 재조립 해주었기 때문에 요청을 보낸 순서대로, 응답이 도착할 필요가 없었던 것입니다. 그러니까 HTTP2 멀티플랙싱의 핵심은 stream id입니다.
그리고 QUIC에서의 멀티플렉싱의 핵심도 stream id에 있습니다. 어떻게 QUIC에서는 HOLB가 해결되면서, 멀티플렉싱도 가능해졌는지 차차 알아보겠습니다.
먼저, QUIC으로 들어오면서 멀티플렉싱의 기능이 전송계층으로 내려갔습니다. 기존의 HTTP2에서는 멀티플렉싱의 기능이 어떤 계층에서 이루어졌었죠? Binary Framing Layer라는 계층이었습니다. 이 계층은 TCP라는 전송 계층위에, 그리고 application 계층 아래에 있었습니다. 전송계층에서 받아온 패킷 안의 프레임을 가지고 위의 계층으로 보내면, 그 위의 binary framing 계층에서 프레임 안의 stream id를 가지고 조립을 하는 방식이었습니다. 그러니까, Binary Framing Layer에서 멀티플렉싱이 이루어지고 있었습니다.
그런데, 그 멀티플렉싱이 QUIC에서는 전송계층으로 내려오면서, 각각의 패킷에 대하여, 아니 더 엄밀히 말하면, 패킷이 가지고 있는 byte stream에 대하여 stream id를 부여합니다. 그 stream id 덕분에 패킷들은 독립적인 패킷이 될 수 있습니다. 이 덕분에 멀티플렉싱이 가능해집니다. 무슨 말인지 모르겠죠? 그림과 함께 살펴보면 더욱 잘 이해될 것입니다.
TCP에서의 패킷 전송 흐름 :
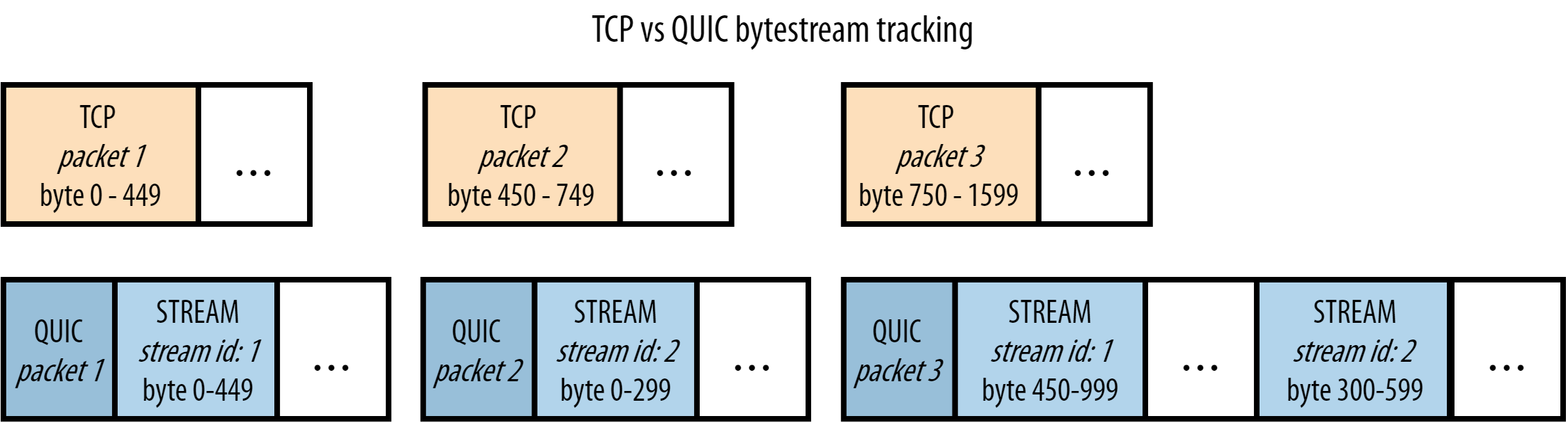
위쪽의 주황색은 TCP에서의 패킷 전송흐름입니다. 위에서 설명드렸다시피, TCP는 신뢰성을 중요하게 생각하는 프로토콜이기 때문에 각각의 패킷들이 순서에 맞게 도착하도록 해야합니다. 그것을 위해서 byte range가 주어져있습니다. 주황색 그림을 예로 들어 설명해보겠습니다.
- packet1이 도착했습니다. byte range가 0-499이네요. 이 사실을 기억합니다.
- packet3이 도착했습니다. byte range가 750-1599이네요. 어, 중간에 450-749가 비었습니다. 문제가 있는 것 같아요. packet2를 재전송 요청합니다.
- packet2가 도착할 때까지 이후의 다른 패킷들은 대시 상태에 들어가게 됩니다.
만약 위의 예시에서 packet1과 packet3 담고 있는 데이터의 종류가 stream1과 관련된 데이터였고, packet2가 담고 있는 데이터의 종류가 stream2와 관련된 데이터였다고 해보겠습니다. 그렇다면 사실 packet2가 손실된 것은 packet1과 packet3의 데이터와는 큰 상관이 없습니다. 애궂게 그냥 기다리는 겁니다.
QUIC에서의 패킷 전송 흐름 :
그런데 QUIC은 이런 문제를 각각의 패킷에 stream id를 부여함으로써 해결합니다.
아래쪽의 파란색 그림을 보겠습니다. 아래쪽 그림은 HTTP3를 이루고 있는 QUIC이라는 전송 프로토콜입니다. 여기에선 각각의 패킷마다 그 안에 stream id를 가지고 있습니다. 이게 핵심입니다.
차근 차근 생각해봅시다. {packet : 1, streamId : 1, byte : 0-449} 이 데이터가 먼저 도착했고, 그 다음에 {packet : 3, streamId: 1, byte : 450-999}가 도착했습니다. 그러니까 packet 2에 손실이 생긴 것입니다.
만약 TCP였다면 그대로 다시 packet2를 재전송 요청했을 것입니다. 하지만, QUIC에서는 패킷이 도착한다? 그러면 stream id를 먼저 확인합니다. 그런 다음, 이전 stream id에서 가지고 있던 byte range를 확인합니다. 제가 예를 든 패킷을 통해서 순서대로 살펴보겠습니다. 아래의 내용을 차근차근 읽다보면 원리를 이해하게 될 것입니다.
- packet 1이 도착했다.
- stream id를 확인하니 1번이다. 해당 스트림에 대한 byte range를 기억한다.
- packet 3이 도착했다.
- stream id를 확인해보니 1번 stream이다. 그러면 이전에 stream id의 byte range를 확인한다. 확인해보니 0-449다. 지금 받아온 byte range는 450-999다. byte range 사이의 어떤 gap도 존재하지 않는다. 정상이라고 처리한다.
- packet 4를 받았다.stream id를 확인해보니 2번 stream이다. 그러면 이전에 stream id 2번의 byte range를 확인한다. 어, 그런데 해당 데이터가 존재하지 않는다. 지금 받아온 byte range는 300-599인데, 0-299라는 gap이 존재한다. stream id 2 번에 대한 이전 패킷을 다시 요청해야겠다.
- stream 2번에 해당하는 이전 패킷을 요청한다. 다시 손실된 패킷을 받아오는 동안, packet 4번의 데이터는 보관된다. 그리고 나머지 상관없는 stream의 패킷에는 지연이 발생하지 않는다. 오로지 Stream 2번과 관련된 패킷에만 지연이 생긴다.
이런 원리를 통해서 http3에서는 TCP 차원에서 발생하던 HOLB의 문제를 해결했습니다. 결국 핵심은 stream id입니다. 이런 고유 번호를 통해서 독립적으로 전송될 수 있도록 하는 멀티플렉싱이라는 기술이 가능해진 것입니다.
여기서 깨알같이 저희가 알 수 있는 사실은 HTTP3가 udp를 사용함에도 불구하고 순서를 보장한다는 사실입니다. 모든 패킷들에 대해서 순서를 지키도록 하는 것은 아니고, 각 스트림에 대해서는 순서를 지키도록 하면서 QUIC은 신뢰성을 보장하고 있습니다.
아래는 제가 http3에서의 멀티플렉싱을 이해하기 위해 참고한 자료들입니다.
- Head-of-Line Blocking in QUIC and HTTP/3: The Details <- HOLB 관련해선 이 자료가 최고인 것 같습니다.. 👍
- TCP Head of Line Blocking
- QUIC and HTTP/3 Features - Head of Line Blocking Removal
3.Connection ID :
HTTP3가 되면서 향상된 기능 중 또 주목할 만한 부분은 connection id라는 기능입니다. 해당 기능은 ip주소나 여타 다른 이유에 의해서 네트워크 인터페이스가 변경되더라도 생성했었던 연결을 유지할 수 있게 해주는 기능입니다. 사실 연결이 생성되었는데, ip 주소가 변경되는 일은 저희 일상 속에서 빈번하게 일어나는 일입니다. 언제 이런일이 일어날까요?
일상 속 관찰 가능한 ip 주소의 변경 :
집에서 wifi를 이용해 유튜브를 보면서 집을 나섭니다. 집과 멀어지는 순간부터는 wifi를 잡을 수 없기 때문에, 개인의 셀룰러 데이터를 이용하게 됩니다. 이 순간 ip주소는 변경됩니다. 그러는 동안 유튜브도 잠시 끊기죠. 만약 기존의 TCP기반의 네트워크를 이용하고 있었다면, 무조건 다시 새로운 연결을 맺어주어야 합니다. 하지만, HTTP3를 사용하면 ip주소가 변경된 이런 상황 속에서도 연결을 새로 맺어줄 필요가 없습니다. 바로 connection id 때문입니다.
connection id(CID) 가 뭐야? :
connection id(CID)는 연결에 대한 랜덤하고 고유한 식별자입니다. 해당 정보는 QUIC의 패킷 헤더에 붙어있습니다. 이 CID의 주된 기능은 전송계층 이하의 단계(TCP, IP Etc.)에서 변경사항이 생긴다고 할지라도, 전송되는 패킷들이 잘못된 end point로 전달되지 않도록 보장합니다. 덕분에 네트워크 인터페이스가 변경되어도 항상 연결이 유지될 수 있으며, 심지어는 이전에 다운받았던 데이터를 새롭게 다운 받을 필요가 없어집니다. 이런 점은 용량이 큰 데이터나, 비디오 스트리밍 같은 경우에는 상당한 이점이 될 수 있습니다.
참고 :
4.UDP의 단점을 보완한 QUIC
UDP에는 크게 2가지의 문제점이 있었습니다. 바로 신뢰성과 보안의 문제였죠. 패킷이 손실되어도 그것에 대해 책임을 지지 않는다는 점, 그리고 암호화 기능이 없어 중간에 데이터를 탈취하거나 변조하는 공격에 취약하다는 점이 UDP의 주요 문제점입니다.
그런데 제가 설명드린 내용을 통해 유추할 수 있듯이, QUIC은 이런 단점들을 보완했습니다.
신뢰성의 문제 :
지금까지 이 글을 찬찬히 읽어오셨다면, 이미 이 신뢰성의 문제가 어떻게 해결되었는지 알고 계실 것입니다. QUIC이 멀티플랙싱을 어떻게 가능하게 하는지에 대해서 설명하는 부분에서 해당 내용을 살펴보았기 때문입니다. QUIC에서는 각각의 패킷의 byte stream 대하여 stream id를 부여합니다. 그리고 그 stream id와 byte range가 일치하는지를 확인하고, 일치하지 않는다면 패킷을 재전송하기를 요청합니다. 기존의 UDP에서는 전송된 패킷이 손실되었을 때, 재전송을 요청하지 못했던 이유는 각 패킷에 대한 식별 정보가 없었기 때문입니다. UDP는 연결이 없는 프로토콜로, 각 패킷이 독립적으로 전송되며, 전송 순서나 패킷 손실에 대한 확인 및 복구 기능이 존재하지 않습니다. 그러나, QUIC은 이런 문제를 각 패킷에 stream id를 부여하고, 문제가 있을 시 재전송하는 알고리즘을 도입함으로써 해결했습니다.
보안의 문제 :
보안의 문제도 이미 설명 드린바가 있습니다. UDP에서 암호화 기능이 없었지만, QUIC에서는 전송계층 자체에서 암호화기능을 통합함으로써 이 문제를 해결했고, 더 이상 보안이 옵션이 아닌 기본적으로 내장된 기능이 되었습니다.
👋🏻 결론
오늘은 이렇게 HTTP의 변천사를 알아보았습니다. 해당 내용을 공부하면서 느끼게 된 지점이 몇 가지 있었습니다. 그 내용을 공유하며 글을 마무리하려 합니다.
기술은 문제해결로부터 나온다 :
역시나 기술은 쌩뚱 맞은데에서 나오지 않습니다. 언제나 기존의 상황에 불편함이나, 어려움이 존재했고 그것에 대한 더 적절하고 더 나은 해결책을 마련하다보니 새로운 기술이 탄생하게 됩니다. 당연하게 들리는 이런 패턴을, 스스로 찾아가며 공부하면서 다시 한 번 발견하게 되었습니다. 마찬가지로 모든 기술들의 탄생의 근원이 문제해결에 있다고 했을 때, 내가 새로운 기술을 공부할 때에도 유사한 패턴으로 접근한다면, 훨씬 더 빨리 기술의 본질에 다가갈 수 있겠다는 생각을 한번 더 해보게 되었습니다.
더 빠르게, 더 안전하게 :
그리고 기술의 방향성도 알게 되었습니다. 이름은 다양한 기술로 소개되어있지만, 결국 그 본질은 이전 버전 보다 더 빠르게, 더 안전하게 사용할 수 있게 만들어주는 것이었습니다. 이는 어쩌면 기술 직군에 속해있는 저의 방향성과도 맞지 않을까 생각합니다. 어떻게 하면 더 빠르게, 더 안전하게 개발할 수 있을까. 이런 고민의 방향성을 가지면서 성장하다보면, 기술이 발전하는 것과 비슷한 맥을 같이하겠구나 싶은 생각이 들었습니다. HTTP2에서 HTTP3의 버전업이 빠르게 이루어졌던 것과 같이, 저의 버전업도 더 빠르게 이루어질 수 있기를 기대해봅니다.
이렇게 긴 글을 읽어주셔서 감사합니다. 부디 도움이 되셨기를 바라며, 제가 학습할 때 도움이 되었던 자료들 또한 아래에 첨부하겠습니다. 🙋🏻♂️
참고자료 :
RFC9110
Understanding Application Layer Protocols
HTTP의 진화
구글의 야심작
Evolution of HTTP
Brief History of HTTP
Why the Internet will be faster with HTTP/2
ideal HTTP Performance
The Performance Of HTTP Requests Over HTTP/1.1
HTTP/2
The Evolution of HTTP – HTTP/2 Deep Dive
Key differences Between TLS 1.2 and TLS 1.3
Why do we need a 3-way handshake? Why not just 2-way?
Why does TCP even need a 3-way handshake?
http3 quic protocol guide
HTTP3는 왜 UDP를 선택한 것일까?
HTTP/3: the past, the present, and the future
http3 is fast
HTTP3 : QUIC protocol guide
Head-of-Line Blocking in QUIC and HTTP/3: The Details
TCP Head of Line Blocking
QUIC and HTTP/3 Features - Head of Line Blocking Removal

5개의 댓글

You delivered such an impressive piece to read, giving every subject enlightenment for us to gain information.
Thanks for sharing such information with us due to which my several concepts have been cleare
https://uprivareptiles.com



글 너무 잘 읽었습니다 !! 👍🏼👍🏼