3-9 크롤링
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
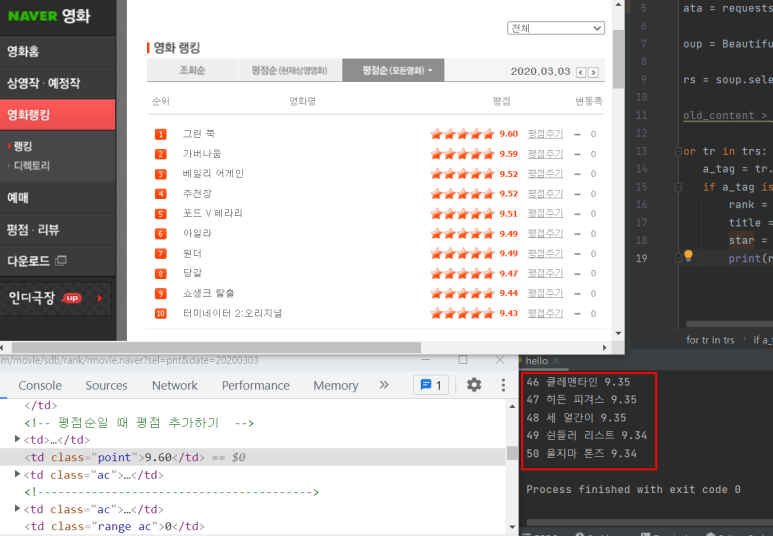
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.nhn?sel=pnt&date=20200303',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
trs = soup.select('#old_content > table > tbody > tr')
#old_content > table > tbody > tr:nth-child(2) >
for tr in trs:
a_tag = tr.select_one('td.title > div > a')
if a_tag is not None:
rank = tr.select_one('td:nth-child(1) > img')['alt']
title = a_tag.text
star = tr.select_one('td.point').text
print(rank, title, star)검사 - elemental - copy - copy selector 에서 'td.title > div > a' 발췌
for tr in trs:
a_tag = tr.select_one('td.title > div > a')
if a_tag is not None:
rank = tr.select_one('td:nth-child(1) > img')['alt']
title = a_tag.text
star = tr.select_one('td.point').text
print(rank, title, star)
굵은 부분은 print(rank['alt'], title.text, star.text) 로 사용해도 됨3-8 Memo
크롤링 : 인터넷 창을 열어 받아온 정보들을 솎아내는 것
중요기술 2가지
1 : (코드를 따내서 브라우저를 키지 않고) 요청하는 것(requests) / 파이참에서 bs4 설치(BeautifulSoup)
2 : 요청해서 가지고 온 정보인 html들 중에 내가 원하는 정보를 잘 솎아내는 것
soup = BeautifulSoup(data.text, 'html.parser')
trs = soup.select('#old_content > table > tbody > tr')
#old_content > table > tbody > tr:nth-child(2) >
for tr in trs:
a_tag = tr.select_one('td.title > div > a')
if a_tag is not None:
title = a_tag.text
print(title)
블로그 이전했습니다. https://yerimi11.tistory.com/