TLTR
- 트랜잭션들의 길이가 짧거나 데이터베이스를 이루는 항목들의 수가 비교적 적은 트랜잭션 데이터 베이스에서
- 해쉬 기법을 사용하여 스캔하면서 트랜잭션에서 발생 가능한 부분집합을 해쉬 테이블에 저장해서
- 최소 지지도에 영향을 받지 않고 기존 알고리즘보다 빈발항목 집합을 효율적으로 발견할 수 있는 연관 규칙 탐사 알고리즘 제안
기존의 연관 규칙 탐사
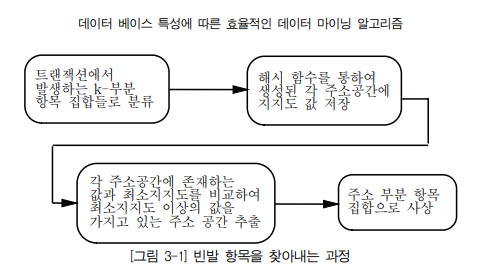
트랜잭션에 나타나는 항목의 발생 빈보수가 최소 지지도(Minumum Support) 보다 큰 빈발 항목 집합(Large frequent item sets)을 찾는 방법
기존 연관 규칙 탐사 알고리즘은 빈발 항목 집합의 후보 항목집합을 만들고 찾아냄. 기존 알고리즘 개선 연구는 후보 항목 집합 줄이기와 데이터베이스 크기 줄이는 방향으로 진행되옴.
기존 방식이 시간을 줄이기는 하지만, 후보 집합 줄이기와 데이터베이스 크기를 줄이는데에 시간을 들여야하는 단점 존재.
기존 알고리즘은 트랜잭션의 길이가 길고 후보 항복의 수가 많은 대용량 데이터 베이스에서 수행되는 경우를 가정.
본 연구의 핵심 아이디어 및 차별점
하지만 트랜잭션은 다양한 형태로 이뤄짐
트랜잭션이 짧은 데이터에 대해서 더 효율적인 연관 규칙 탐색 알고리즘이 가능
데이터베이스 특성에 맞춰 효율적인 알고리즘이 가능하다.
몰랐던 것
- 퍼지이론과 확률론의 차이 : 확률은 결과가 명확하게 떨어지는 것들을 다루고 퍼지이론은 결과가 불명확한것을 다룸, 예를 들어 주사위를 던져서 나오는 눈의 수와 같은 결과가 확실한건 확률론의 영역이고, 예쁜 사람의 집합은 퍼지 이론의 영역임.
불확실성 추론(Reasoning with Uncertainty)
출처
데이터 베이스 특성에 따른 효율적인 데이터 마이닝 알고리즘, (박지현, 고찬)

선한 의도가 선한 결과를 만드는 시스템을 만드는게 꿈입니다.