TCP 완전 정복 ...ing
본 내용은 김효곤 교수님의 [인터넷 프로토콜] 서적 및 강의를 기반으로 정리한 글입니다! 🙇🏻♀️
+ 아직 완성이 안된 글입니다...! 공부 하는대로 계속 내용 추가 할 예정입니다 🔥🔥
13.1 TCP 서비스 모델
인터넷 트래픽의 90% 이상을 TCP가 실어나름 ex. 웹, 이메일, 비디오 스트리밍 …
→ 잘 설계된 서비스 모델과 그를 위한 정교한 메커니즘 구현
TCP의 복잡한 메커니즘들은 모두 외부적으로 사용자에게 제공하는 서비스 모델을 구현하기 위한 장치
13.1.1 TCP의 특징
1. 🚚 reliable delivery 배달의 안전성 보장!
- 재전송 retransmission 메커니즘을 통한 신뢰성있는 배달
- 바로 아래 계층인 IP가 제공하는 서비스에 전혀 신뢰성 X → TCP가 극복해야함
- 여러 차례 재전송을 해서라도 꼭 배달
→ TCP에 배달을 맡긴 응용 계층은 신뢰성 있는 통신 채널을 가정하고 나머지 작업 수행
⇒ 응용 계층 스스로가 성공적인 배달여부를 체크하면서 재전송할 필요 ❌ TCP에 믿고 맡김
2. 👯 in-order delivery 데이터를 보내는 순서대로!
- TCP를 트랜스포트로 사용하는 응용 프로토콜들은 TCP 연결을 일종의 파이프로 생각
- 파이프의 입구 = 전송 소켓, 파이프의 반대편 끝 = 수신 소켓
→ 양방향으로 하나씩 존재 = 데이터채널
- socket에 데이터를 write = 파이프에 데이터를 밀어 넣는 것
- IP는 데이터의 순서 보장 X → TCP가 보장해줌으로서 응용 계층의 부담을 줄임
3. 🎛️ flow control 응용이 데이터를 처리할 수 있는 만큼만! 흐름제어
- 송신자측에서 지나치게 빠른 속도로 데이터를 보내면 수신자가 소화할 수 없음
- 수신자가 소화하지 못하는 이유?
→ 수신 host가 처리능력이 떨어지는 느린 컴퓨터
→ TCP로 통신 중인 응용 말고도 많은 다른 응용들이 수신 측의 컴퓨터에서 수행
- 수신자가 소화하지 못하는 이유?
- 다른 응용이 CPU를 점유하는 동안에는 TCP를 사용하는 응용이 도착하는 데이터를 처리 X
4. 🍔 Byte Stream 데이터를 바이트가 길게 줄 서있는 것처럼 생각!
- 응용 계층에서 내려오는 데이터를 바이트의 연속으로 생각
→ 이것을 일정 길이로 잘라 TCP 패킷을 만듦 = segment
- 대부분의 TCP 연결은 적절한 segment 크기를 알아서 결정할 수 있음 by 경로 MTU 발견
- 데이터는 바이트 단위로 번호가 매겨지고, 배달 여부도 바이트 단위로 체크 (퍼즐 한 조각)
segment 단위로 묶어서 전송하긴 하지만, TCP에는 segment를 세는 기능 X
⇒ 모든 체크는 바이트 단위로!
- 응용에서는 1바이트부터 시작해서 데이터 크기에 제한 없이 TCP에 전송 요구 가능
5. 🔗 Connection-Oriented 데이터가 흐르면 연결이 필수! 연결지향
- 연결지향이냐 아니냐는 프로토콜 스택의 계층과 상관 X 각 프로토콜별 개별적 선택
(같은 계층의 UDP나 아래 계층의 IP는 connectionless)
- 데이터 전송 상태에 대한 정보를 추적해야 하기 때문에 연결지향
데이터 분실, 순서 뒤바뀜, 수신측의 TCP 버퍼의 여유공간 등
→ 데이터 전송의 정확한 상태를 알고 있는 것으로 1, 2, 3 특징이 가능하게 만듦
13.2 TCP 헤더 형식
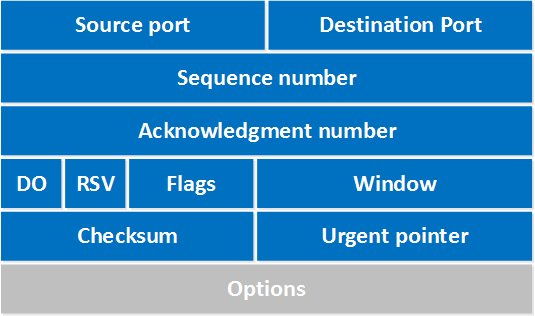
40B의 option 제외 고정헤더의 길이 20B
13.2.1 고정 헤더 구성값
-
Source Port & Destination Port → 2B * 2 = 4B
포트번호 16bit(2B) → 수신해야 할 응용 프로세스를 찾는데 사용
= transport 계층 주소
두 개의 포트번호 + IP 헤더에 있는 IP 주소 → 총 4개의 주소 값으로 응용 프로세스를 찾아냄<IP 주소, 포트번호> 쌍 = 소켓 ⭐️
TCP 연결은 두 개의 소켓을 연결하는 것+) 포트번호의 분류
- well known port: 우리가 잘 알고있는 서비스들이 이 범위를 사용 (0 ~ 1023)
ex. HTTP 80번 포트
아무나 이 포트번호를 사용할 수 없음, IANA에 등록하는 절차 필요
이 포트번호를 아예 사용하지 못하게 하는 운영체제도 있음
- registered port: 각종 응용들이 IANA에 등록해서 사용하고 있는 범위 (1024 ~ 49151)
well-known과 달리 규제가 빡세지 않음
서버가 아닌 클라이언트 응용이 아무 포트나 잠깐 쓰려고 할 때 이 범위에서 사용하기도 함
서버에 접속해서 원하는 데이터를 받고 연결을 끊을 때까지 잠깐 사용 → ephemeral port
- private/dynamic port: 이 범위를 쓰는 응용은 거의 없음 (19152 ~ 65535)
최근 p2p응용이나 트로이 목마 같은 해킹 툴들이 사용
https://ko.wikipedia.org/wiki/TCP/UDP%EC%9D%98_%ED%8F%AC%ED%8A%B8_%EB%AA%A9%EB%A1%9D
- well known port: 우리가 잘 알고있는 서비스들이 이 범위를 사용 (0 ~ 1023)
-
Sequence Number → 4B
Byte Stream이라는 TCP의 특성에 의해 각 바이트는 일련번호를 하나씩 받음
이 번호를 통해 유실, 순서 뒤바뀜 등을 대처
TCP segment의 헤더에 적힌 시퀀스 번호
= 세그먼트에 의해 옮겨지고 있는 바이트 중 가장 앞의 시퀀스 번호 → 대표 번호
-
Acknowledgement Number ACK → 4B ⭐️ ⭐️
마지막으로 받은 연속적인 바이트의 시퀀스 번호 + 1
ex. 시퀀스 번호 2번까지 잘 받았다면 ACK = 3
잘 받았다 = 무사히 수신 소켓 버퍼에 들어감!
→ 언제든지 응용이 소켓 read 함수를 통해 퍼갈 수 있음ACK x를 받으면 전송 소켓 버퍼에서 번호가 x-1인 바이트까지는 삭제 가능
→ 재전송이 필요 없어졌기 때문!
-
HDL → 0.5B
최대 40B option 때문에 헤더 길이가 가변 → 헤더길이 명시 필요
HDL 4 = 실제 TCP 헤더 길이
4bit → 0 ~ 15까지 표현 가능 4 15 = 60B (최대)
만약 헤더가 4의 배수가 아니라면 padding 필요
-
Flags → 1B
각 flag당 1 bit씩 총 8개의 flag 존재


-
Window Size → 1B
window = 수신 측 소켓 버퍼의 빈 공간
처음에 공간을 잡아놓고 활용률을 봐가면서 소켓 크기 자체를 연결 도중 재조정 하기도 함
→ autosizing전송 측이 수신 측 버퍼를 넘치게 하지 않는 하에서 몇 바이트나 더 전송할 수 있는지를 파악하게 함
→ 흐름 제어 flow control -
Checksum → 1B
전송 중 오류가 생겼는지 확인하는 전형적인 인터넷 체크섬으로 1의 보수 덧셈 결과를 1의 보수 취함
UDP처럼 TCP도 pseudo header 사용 (IP주소와 IP프로토콜 필드값이 체크섬에 포함)다만 UDP와 달리 TCP 체크섬은 의무
TCP segment 전체에 대해 계산되고, NIC에서 해줄 수 있으면 위임도 가능
→ OS는 체크섬 필드를 0으로 하고 보낸 후 NIC가 하드웨어적으로 계산해서 채워줌 -
Urgent Pointer → 1B
flags 필드에서 URG flag = 1일때 긴급한 데이터의 끝 위치를 명시
현재 segment 시퀀스 번호로부터 얼마나 떨어져 있는지 바이트 단위로 알려줌
13.2.2 TCP Options
TCP option도 TLV = Type(1B) + Length(1B) + Value 형식을 따름
종류에 따라 Value 필드의 길이 달라짐
Length는 Type와 Length 필드의 길이까지 포함한 해당 옵션의 전체 길이
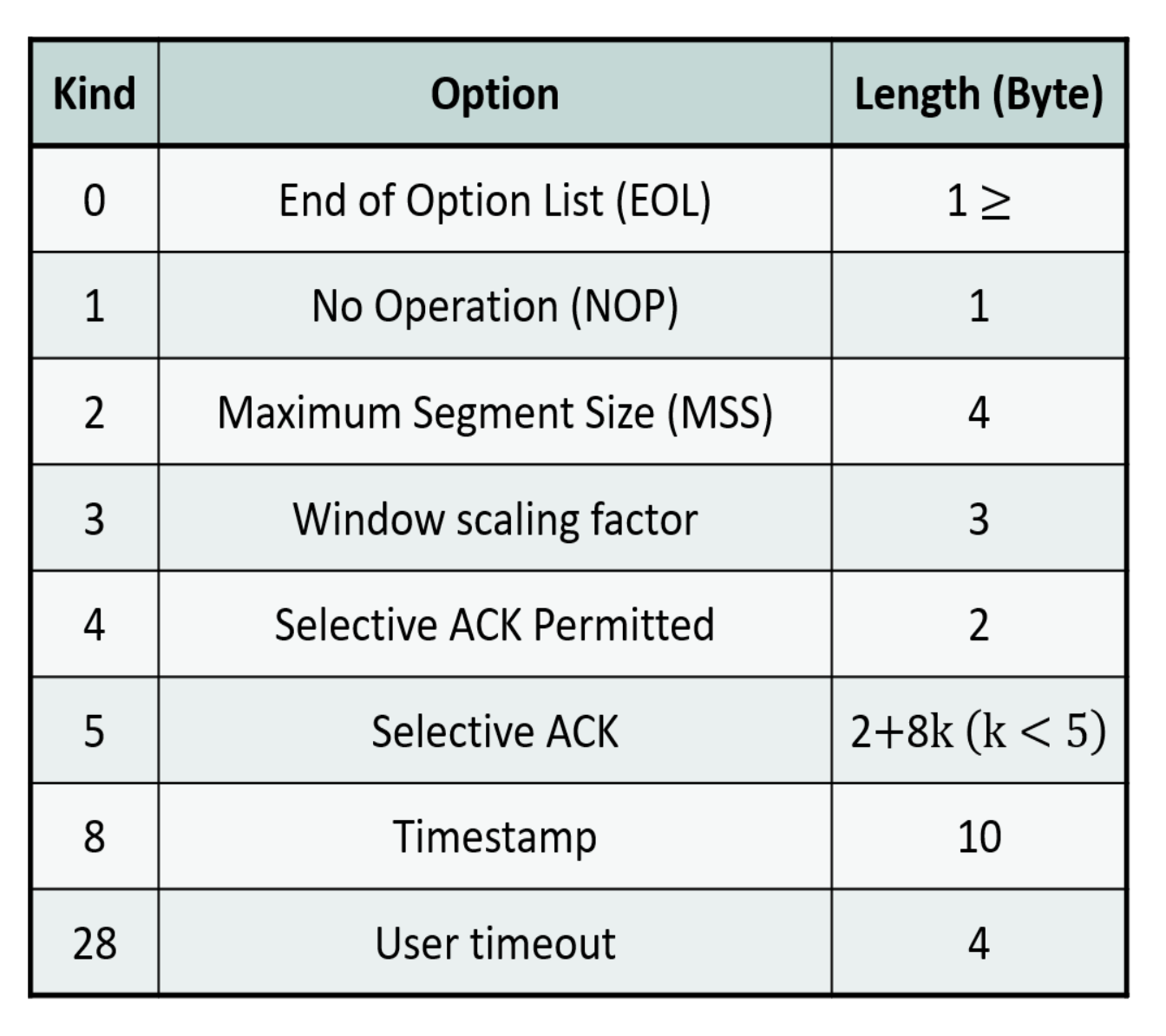
-
End of Option List (EOL) → 1B
이 뒤로는 더 이상 옵션이 없다는 뜻
필수 사용 X → 헤더 길이 알기 때문에 option의 길이도 앎
4배수가 아닌 경우 NOP으로 메꾸면 되기 때문에 꼭 EOL을 사용할 필요는 없음BUT 만약 EOL을 넣었다면, 4배수를 맞춰야 하는 경우 뒤에 0(NOP X)으로 패딩
→ NOP도 결국 option의 일종이기에 EOL의 정의와 모순됨

MSS(4) + NOP(1) + WS(3) + SACK(2) = 10B → 4배수가 되려면 2B필요
따라서 뒤에 EOL(1) + 0으로 padding(1) 필요한 것 -
No Operation (NOP) → 1B
헤더 길이가 4배수가 되도록 끼워넣는 값으로 option 앞이나 뒤에 어디든 붙여도 상관 없음
4배수만 맞추면 되므로 3개를 초과하지 않음
-
Maximum Segment Size (MSS) → 4B
TCP 연결이 만들어질 때 어떤 세그먼트 크기를 쓸 것인지 peer에게 알려줄 때만 사용
일반적인 TCP segment = TCP 헤더 + 응용 계층 데이터
BUT MSS는 TCP 헤더 부분을 제외한 응용 계층 데이터 부분의 길이만을 얘기함TCP 연결이 사용하는 호스트의 인터페이스 MTU 크기에 의해 결정 (링크계층의 MTU)
링크계층 MTU의 payload에 TCP segment를 실은 IP 데이터그램이 들어가는 경우,
TCP 헤더와 IP 헤더가 최소크기를 가져야 데이터 부분의 길이가 최대가 됨→ MTU - (20B + 20B) = MSS가 됨
BUT 경로 상의 어떤 MTU가 작아질 수 있으므로 최종 MSS는 아님
MTU가 MSS+40B보다 작은 경우 peer들이 MSS를 더 작은 값으로 조정하지 않으면 IP fragment
→ IP 헤더 DF = 1로 설정해서 MTU를 탐색하는 PMTU discovery 사용 -
Window Scaling Factor → 3B
윈도우 확장 옵션으로 수신 소켓 버퍼의 크기가 64KB보다 큰 경우 peer에게 알려줌
TCP 고정헤더에서 Window Size는 16bit → 2 ^ 16 - 1 = 65535B까지만 표현 가능수신 소켓 버퍼 (TCP Buffer)
= 네트워크에서 들어오는 데이터의 속도 & 응용의 속도차를 완충해주는 공간고속의 연결에서는 속도차가 커질 수 있어 버퍼가 더 커야할 필요가 있음
이 옵션에 들어있는 값의 명칭: scale factor
고정헤더의 window size를 몇 번 왼쪽 shift해서 해석해야 하는지를 의미window size *= 2 ^ (scale facor)
-
Selective ACK (SACK) Permitted → 2B
TCP 연결 단계에서 peer TCP에게 자신은 Selective ACK를 사용할 수 있다고 알림
peer TCP도 SACK을 사용할 수 있다고 하면 데이터 전송 단계가 시작되었을 때 SACK 사용 가능
-
Selective ACK → 2 + 8*k (k < 5)
SACK option은 송신자 TCP가 여러 segments를 보낼 때 일부가 유실되었더라도 어떤 것을 못받았는지 알려줌
→ 잃어버린 segment만을 보내는 효율적인 재전송을 하게 함비교적 나중에 추가된 option으로 TCP 성능 향상에 지대한 영향을 줌
데이터 전송이 시작된 후에 쓰이는 옵션이므로 TCP 연결 시점에서는 나타나지 않음
value 필드에 불연속 바이트 블록 → left edge, right edge → 길이 4B짜리 바이트 시퀀스 번호
left edge: 불연속 블록의 시작 시퀀스 번호
right edge: 불연속 블록의 마지막 시퀀스 번호 + 1(5841 ~ 8761) & (11681 ~ 12991) 이고 ACK = 4800인 경우
→ (4801 ~ 5840) & (8761 ~ 16680) 이 블록에 해당하는 바이트가 유실되었다!SACK는 못받은 것이 아닌 받은 것을 확인
수신자는 송신자에게 SACK option을 통해 이미 수신한 두 불연속 블록을 빼고 재전송 할 것을 요구
→ 불필요한 재전송을 피함으로써 TCP 전송 속도 UP!하나의 불연속 블록의 표현 = left edge(4B) + right edge(4B) = 8B
TCP option의 최대는 40B지만 5개 블록을 표현할 수 없음 Why?
→ TLV에 따라 Type과 Length를 표현하는 2B가 포함되어야 하기 때문 → 따라서 최대 4개블록 4개 = 4 * 8 + 2(TL) = 34 → 2B Padding 필요 (NOP 2개 or EOL 1개 + 0 1B)
8. Timestamp → 10B
전송되는 segment에 달아서 보내고 수신측 TCP는 이 값을 그대로 복사해서 보냄
→ 송신자 측은 수신측 TCP까지의 왕복시간 = RTT (Round-Trip Time)을 알게됨
측정 목적: TCP가 전송한 segment가 ACK되어 돌아올 만한 시간을 추정해야하기 때문
정밀하고 빠른 RTT 측정을 목표로 함
어떤 segment를 전송했을 때, 평균 RTT 시간이 훨씬 지났는데도 ACK가 안돌아오는 경우
→ 네트워크에서 해당 segment가 유실되었다고 판단 + 재전송
기존 RTT를 측정하던 방법:
시스템에 한 flag(T)를 두고 패킷이 전송될 때 T = 0이면 그 패킷이 출발한 시간 t1 저장
→ T = 1로 바꾸어 RTT가 측정중임을 표시
(이 시기에 전송되는 다른 패킷에 대해서는 측정 X → 기존 방식의 대표적인 한계)
→ t1에 출발했던 패킷이 ACK가 되어 돌아올 때의 시간 t2
→ t2 - t1 = RTT의 sample
→ T = 0으로 다시 바꿔서 RTT 측정과정 반복
⇒ 한계점: 한 RTT당 한 RTT sample만 얻을 수 있기 때문에 RTT가 매우 큰 경우는 측정 빈도, 샘플 down
RTT가 빠르게 변화하는 상황에서는 RTT의 평균과 분산 추정의 정확성이 매우 떨어짐
반면 timestamp는 한 RTT당 한 smaple이 아니라 매 패킷마다 RTT sample을 얻을 수 있음
→ 측정 sample수가 많아지면서 정확한 RTT 추정 가능
28. User Timeout → 4B
전송된 데이터가 ACK로 돌아오기를 기다리는 최대 시간 조절
peer TCP에게 얼마 이상의 시간 동안 ACK가 없으면 연결을 끊어라!는 것을 미리 알려줌
많은 클라이언트를 상대하는 서버라면 ACK와 같은 정상적인 반응을 하지 않는 TCP 연결 유지 BAD
→ UTO 값을 아주 작게 설정해서 클라이언트 TCP에게 통보
→ 살아있는 TCP 클라이언트는 어떻게든 UTO가 넘기 전에 패킷 전송 등의 행동 취함
→ 연결 종료 예방
반대로 반응이 없어 보여도 연결을 끊지 말아달라고 요구하려면 매우 큰 UTO를 통보하면 됨
⇒ ⭐️ 모든 TCP 옵션은 반드시 TCP 연결 시에 양쪽 TCP peer가 모두 동의해야 사용 가능 ⭐️
만약 버전이 안맞아서 자신이 인식할 수 없는 옵션이면 무시 + length 값만큼 건너뛰어 다음 옵션 처리
커널이 업데이트 되면서 TCP가 새로운 버전으로 교체될 때 해결됨
→ 하위 호환성 backward compatibility를 보장 + 자유로운 옵션추가 가능으로 feature scalability
13.3 TCP 연결 제어
TCP는 연결 지향 Connection Oriented 프로토콜!
→ 연결이 이루어진 후에야 데이터가 흐를 수 있음
TCP는 전이중 full-duplex 방식으로 작동 = 두 TCP peer 사이에 양방향 데이터 채널이 열려있음
두 TCP가 각 데이터 채널을 통한 데이터 전송 상태에 대해 일치하는 이해를 가짐 = 동기화 Synchronize
동기화를 위해 필요한 정보:
-
Initial Sequence Number (ISN)
바이트 스트림의 맨 첫 번째 바이트에 할당되는 SN은 0이나 1이 아님
TCP 연결의 납치(hijack)를 막기 위해 무작위 같은 수 채택
→ 자신이 고른 ISN을 peer TCP 끝점에 알려주어야 함 (어디서부터 byte sequence가 시작되는지)
-
Window Size
수신 소켓 버퍼 안의 빈 공간 크키
연결 시작 지점에서는 소켓 버퍼가 비어있으므로 윈도우 크기 = 소켓 버퍼 자체의 크기
소켓 버퍼를 얼마로 할당할 것인지는 사용자가 결정하므로 전송 시작 전에 알려줘야함!flow control 흐름 제어를 위해 peer TCP가 window size를 알고 있어야 함
-
Maximum Segment Size (MSS)
이 채널이 사용하기를 희망하는 TCP segment의 크기 (헤더 제외)
ISN, Window Size → 각 채널에서 독립적인 별도의 값 사용
MSS → 양 채널이 고른 값의 최소값으로 통일 → IP fragment를 방지각자의 첫 MSS = 호스트 인터페이스 MTU - 40B
MSS = min(MSS a→b, MSS b→a)
MSS는 option에 해당하므로 생략할 수도 있는데 이 경우는 최악의 MTU = 576B, MSS = 536B
두 TCP peer가 동일한 서브넷에 있는 경우 MSS 정보가 필요 없음
BUT 통상적으로는 SYN segment에 MSS 옵션 포함!MSS는 TCP, IP 헤더 크기가 최소임을 가정하고 구한 값
→ 옵션이 들어간 경우 IP fragment가 발생할 수도 있지 않은가?
→ 이 경우 TCP 송신자는 MSS에서 option 크기를 제외한 숫자의 데이터 바이트만을 전송
→ IP fragment를 피함!- MTU = 1500B
- MSS = 1460B (20B IP + 20B TCP 기준)
- 실제 TCP 옵션이 12B 있다면 → TCP는 payload를 1448B까지만 실어서 보냄
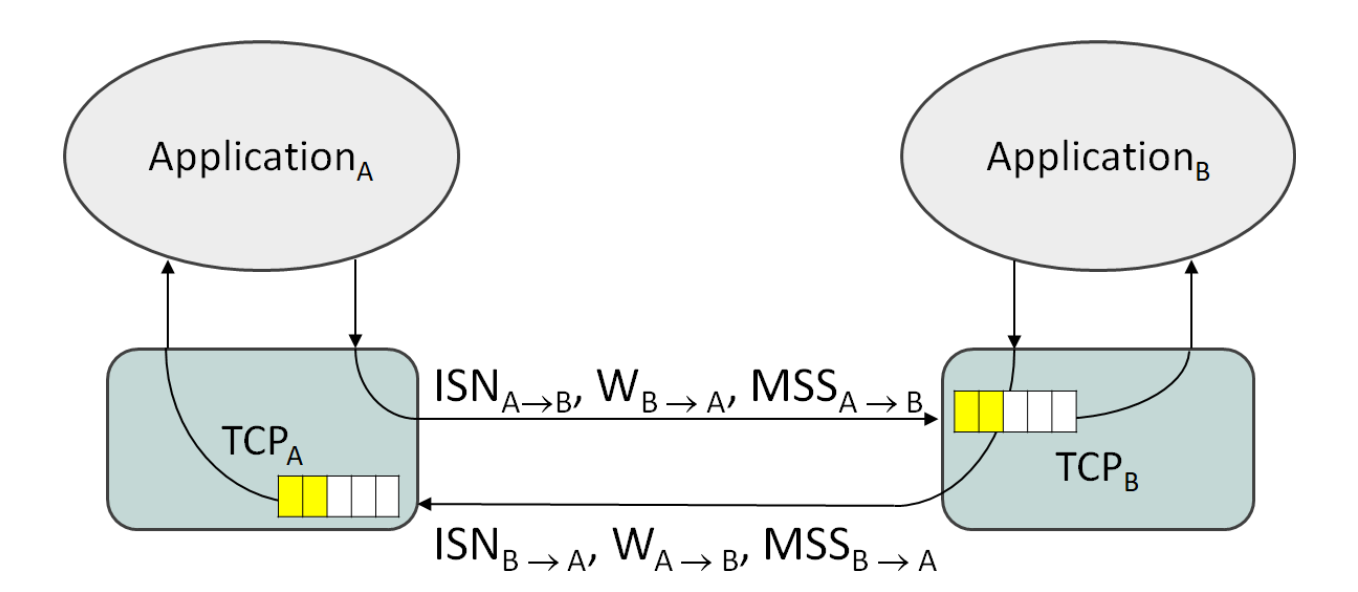
ISN, MSS: 정방향, W: 역방향에 쓰임 (A의 window size는 B → A 일 때 고려히기 때문)
TCP는 ISN, W, MSS 이외에도 끊임 없이 추적, 관리해야 할 값들이 많음
→ 매 연결마나 커널 안에 연결을 관리하기 위한 TCB 제어 블록(TCB)을 만듦연결 중에는 TCB로 값들을 추적할 수 있고 연결이 종료되면 해당 TCB도 사라짐
TCB: 연결을 식별하는 두 개의 소켓 번호 (IP, Port), RTT 추정치, RTT 편차,
전송 및 수신 소켓 버퍼에 대한 포인터, 다음에 전송할 시퀀스 번호, 윈도우 크기 등등 많은 값 포함
⇒ 데이터 전송과 수신을 위한 모든 제어에 관련된 값들의 집약
13.3.1 연결 맺기
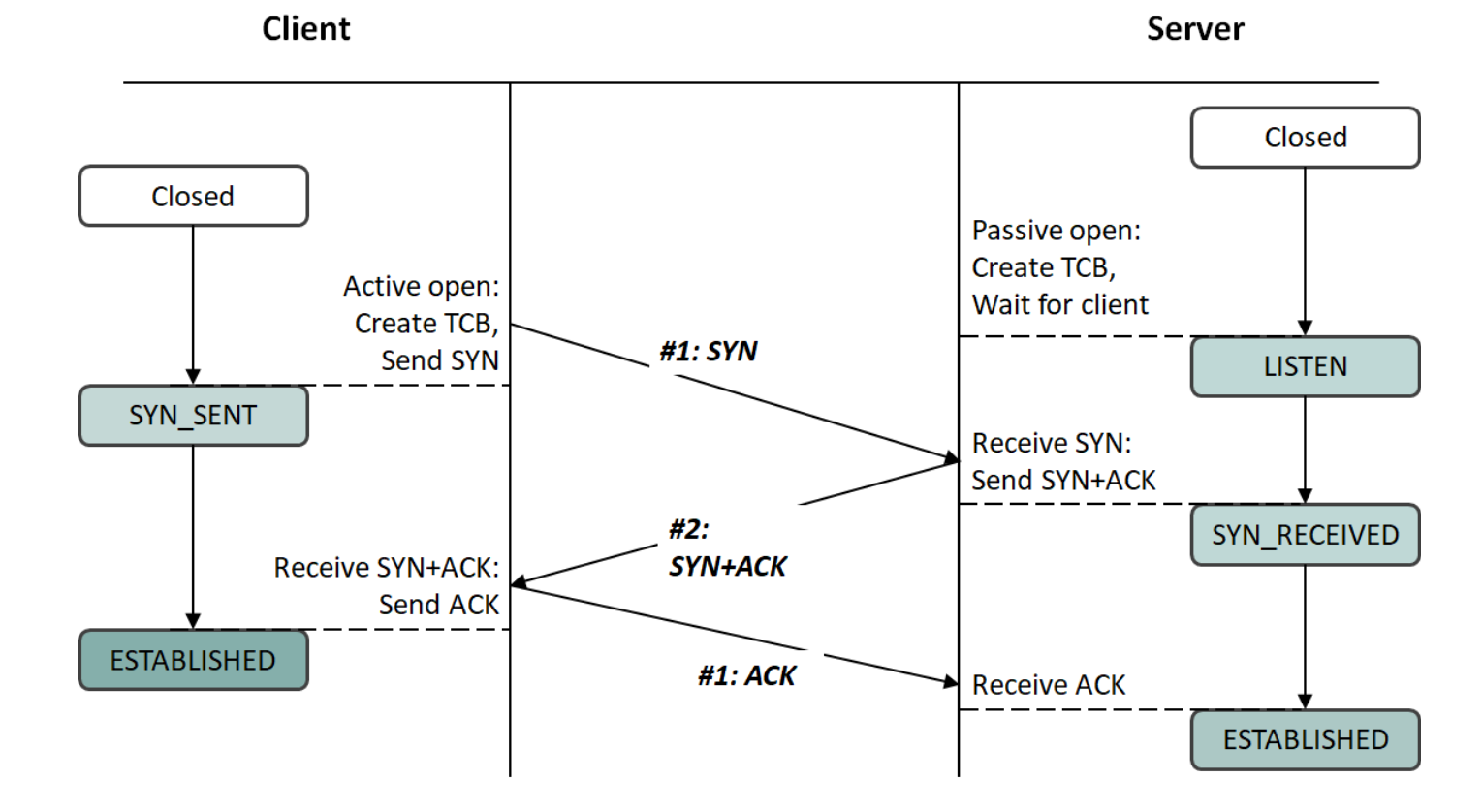
3-way handshake
클라이언트 🙋🏻♀️: 연결 맺자~
서버 🙆🏻: 그래~
🔗 연결: 3개의 패킷 사용
- C → S: SYN | SYN segment: 데이터 채널을 위한 연결 파라미터 값 3개를 실어 나름 아직 연결 전이므로 데이터는 없고 헤더만 존재
- S → C: SYN + ACK | TCP는 reliable delivery를 해야하므로 받았으면 받았다는 확인을 해줘야 함 서버 측에서 클라이언트에게 연결에 필요한 새로운 파라미터 값 정보인 SYN + 앞선 클라이언트로부터 온 SYN을 잘 받았다는 ACK 정보도 함께 보냄
→ 두 데이터 채널이 함께 묶여 만들어질 수 밖에 없음 (BUT 나중에 끊을 떄는 각각 끊을 수 있음)
- C → S: ACK | S → C 채널을 위한 세 값을 헤더에 싣고 온 SYN에 대한 ACK 별도의 ACK를 전송하지 않고 ACK 내용을 헤더에 표현한 뒤 ACK = 1로 설정해도 됨
13.3.2 연결 끊기
연결을 맺을 때는 두 개의 데이터 채널이 동시에 만들어져야함
BUT 연결을 끊을 때는 데이터 채널을 따로따로 끊을 수 있음
→ 한 개의 데이터 채널을 끊은 뒤에도 남은 반대 채널은 계속 쓸 수도 있음 (이론적으론 가능, 그치만 굳이?)
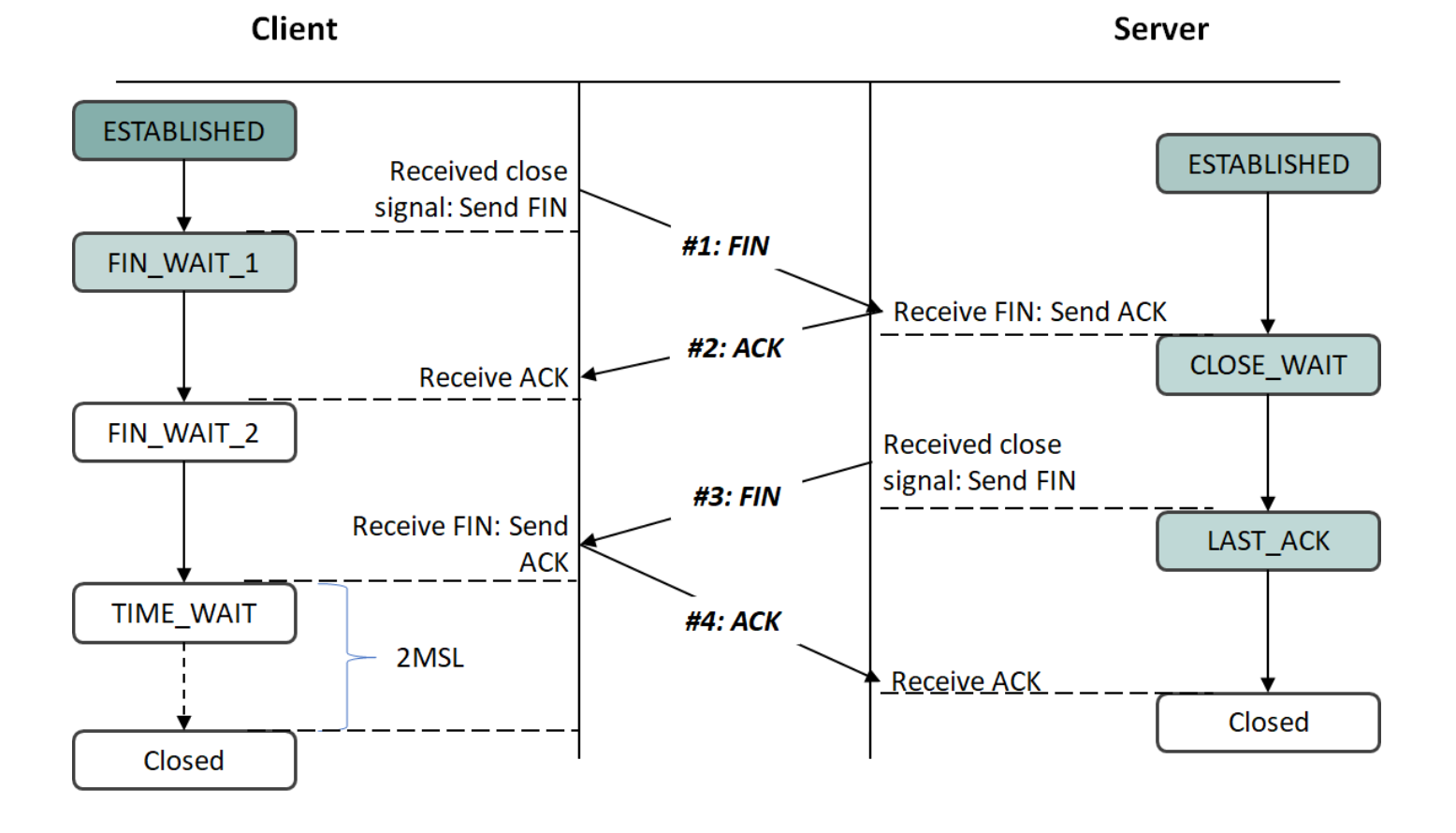
⌛️ 종료: 4개의 패킷 사용
-
C → S: FIN
FIN 패킷이 가는 방향의 데이터 채널의 연결을 끊음
어느쪽이든 먼저 FIN 패킷을 보낼 수 있음
BUT 먼저 FIN segment를 보낸 쪽이 더 큰 부담을 가짐
-
S → C: ACK
끊자고 하는 FIN segment가 수신자 측에 정상적으로 도달이 완료되었음을 알림
-
S → C: FIN
FIN 패킷이 가는 방향의 데이터 채널의 연결을 끊음
-
C → S: ACK
먼저 끊자고 한 쪽이 TCP 연결에서 보내는 마지막 패킷 = ACK 을 보내게 되어있음
TCP에는 데이터의 재전송은 있어도 ACK의 재전송은 없음
만약 #4: ACK가 가다가 유실되면 peer는 ACK를 기다리다 timeout
→ FIN segment 재전송
⇒ 마지막 ACK를 전송하는 측은 ACK 보내고 바로 끝내버릴 수 없음 (ex. 자료구조 정리, TCB 정리)재전송 될지 모르는 FIN segment를 기다려야 함 = TIME_WAIT
TIME_WAIT 시간 = Maximum Segment Life (MSL) * 2
MSL: 원칙적으로 segment가 배달이 되지 않은 상태로 네트워크 안을 떠돌 수 있는 시간
MSL의 표준을 2분으로 생각했을 때 TIME_WAIT는 무려 4분으로 꽤 긴 시간!
반면 끊음을 당하는 쪽은 마지막 ACK를 받자마자 끝
TCB 등 연결마다 만들어진 메모리 자원, 다수의 타이머 이벤트 처리 등을 데이터 전송이 끝난 후에도 유지해야 함
→ TIME_WAIT는 한 순간에도 수 많은 클라이언트들을 상대해야 하는 대형 서버에게는 큰 부담
⇒ 데이터를 모두 보내고 먼저 연결을 끊어야 할 때 RST를 이용하기도 함
(RST: TCP 헤더의 flags 중 하나로 kill 여부 결정)
13.4 TCP 흐름 제어
TCP는 응용으로부터 내려오는 바이트 스트림을 잘라서 segment를 만듦
→ IP에 내려보내 데이터그램의 형태로 목적지에 배달
BUT 목적지까지의 파이프가 계속 용량이 변하고, 목적지에서도 수신 응용이 데이터를 소화하는 속도가 계속 변함
경로 상의 네트워크 용량이 계속 변하는 것을 추적 & 전송 속도 조절 → 혼잡제어 conjestion control
목적지에서 수신 응용의 처리 속도 추적 & 전송 속도 조절 → 흐름제어 flow control
소켓 자료구조: 두 쌍의 소켓 식별자 (나와 peer까지해서 2개) + 소켓의 현재 상태 + 소켓 버퍼
소켓 버퍼는 각 TCP의 두 데이터 채널에 연결
응용 → 전송 소켓 버퍼 → 네트워크 → 수신 소켓 버퍼 → 응용
흐름제어의 목적
- 수신자쪽에서 데이터가 넘치치 않도록 조절
- 파이프가 비지 않도록 충분히 데이터를 전송
⇒ 데이터 유실이 일어나지 않는 선에서 충분히 빠르게 데이터를 전송해야함
TCP 수신자가 수신 상태에 대한 연락을 잘 해줘야 함 = ACK
고정헤더의 흐름제어 관련 필드: ACK, Window Size
→ 방향 데이터 채널의 ACK 정보는 ← 방향으로 옴
ACK 정보는 TCP 고정 헤더의 두 필드를 사용
← 방향으로 올 데이터가 있으면 그것의 헤더에 담아 보냄
← 방향으로 올 정보가 없으면 헤더만 있는 ACK segment를 만듦
13.4.1 ACK 번호
ACK 번호의 본질은 sequence 번호
TCP 연결시에 전송되는 SYN segment도 ISN을 할당받음
ISN은 SYN segment 자체가 할당 받는 것이기 때문에 데이터 바이트는 하나도 싣고 있지 않아도 주어짐
SYN segment 자체도 네트워크 안에서 유실되면 재전송 되어야 하기 때문

#6 패킷이 SN을 1 소모 → #8 패킷 Seq = 1
TCP 연결 종료시에 전송되는 FIN segment도 ISN 하나 소모함

#665 FIN 패킷이 SN 1 소모 Seq = 320 → 같은 방향으로 가는 #674 SN Seq = 321
SYN과 FIN을 제외하면 오직 데이터 바이트만이 Sequence Number를 소모할 수 있음
→ 데이터를 하나도 싣지 않은 ACK segment들은 SN을 증가시키지 않음
Sequence Number는 이전까지 전송한 바이트수라고 해석하면 됨!

전체 K바이트를 나르는 경우 FIN의 Seq = ISN + k + 1
reliable delivery를 위한 ACK
ACK = x → x-1 번째 데이터 바이트까지의 모든 데이터가 수신 소켓 버퍼에 무사히 도착!
만약 데이터가 유실되어 순서가 아닌 SN을 가진 데이터가 왔다면 이전에 보냈던 ACK번호를 그대로 보냄
→ ACK 번호 = 수신 소켓 버퍼에 들어간 마지막 바이트의 SN + 1
→ 데이터를 보냈음에도 전과 동일한 ACK가 도착했다
= 새로 보낸 데이터는 순서가 잘못되어 수신 버퍼에 넣지 않음
→ 대신 reordering buffer라는 별도의 커널공간에 저장
이후 재전송된 segment들이 들어와 벌어졌던 gap이 메꿔지면 한 번에 ACK 증가시킴
재전송된 segment들도 우선 reordering buffer에 들어가고 한 번에 수신 소켓 버퍼로 이동!
Cumulative ACK 누적ACK
마지막 연속 바이트의 시퀀스 번호 + 1을 송신자에게 ACK 하는 방식
어떤 ACK segment가 네트워크 안에서 유실되어도 그 다음 ACK가 전달된다면 문제가 없어짐 = 견고성
ACK segment도 IP에 실려가므로 유실될 수 있음
만약 각 segment별로 ACK를 보낸다면 유실된 ACK에 대해 모두 재전송이 필요
BUT 누적 ACK의 경우 마지막 segment의 ACK만 잘 간다면 문제 없음!
13.4.2 윈도우 크기
Window Size = 수신자가 ACK 하는 시점에 수신 소켓 버퍼에 존재하는 빈공간의 크기
→ 그 당시의 ACK 번호와 윈도우 크기를 캡처해서 보내는 것이라고 생각
윈도우 크기시 주의할 점: 윈도우 크기를 절댓값으로 해석하지 말 것 ⭐️
ex. 윈도우 크기가 2KB라고 알려줬을 때 그대로 2KB를 더 보내면 소켓 버퍼가 넘칠 수 있음
→ 전송을 하려는 시전에 수신자의 상황이 달라질 수 있기 때문!
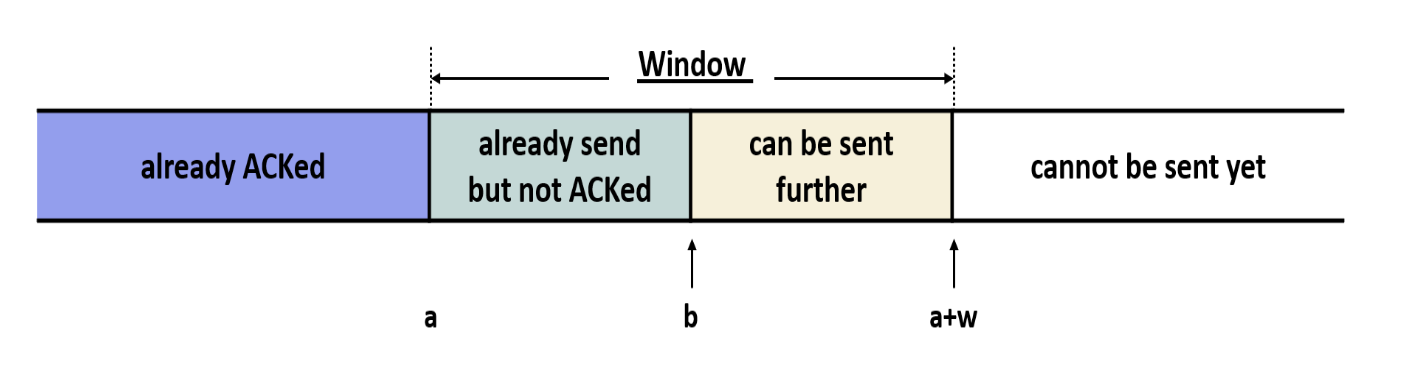
수신자가 보낸 ACK = a, window size = b → ACK를 보낼 당시의 값
송신자가 ACK를 받았을 때는 이미 SN = b 까지 추가적으로 데이터를 보냄
만약 b+w > a+w-1 이면 수신 소켓 버퍼 넘침!
⇒ 송신자가 더 보낼 수 있는 총량 = w-(b-a)-1B
(위 그림에서 노란색 부분에 속하는 양)
Byte Stream에 있는 데이터 바이트의 구분
- already ACKed: 전송되었고 이미 ACK를 받은 바이트
- already send but not ACKed: 전송되었지만 아직 ACK를 받지 못한 바이트
= 미확인 outstanding - cannot be sent yet: 아직 전송되지 않은 바이트
ACK가 도착하면 window를 오른쪽으로 움직임
ACK→ window의 왼쪽 엣지 LE를 오른쪽으로
window size → 오른쪽 엣지 RE = 새로 업데이트된 LE + window size
⇒ sliding window내에서만 전송
TCP 흐름제어를 수행하여 수신 소켓 버퍼가 넘쳐 데이터가 유실되는 일이 없게 함
13.4.2 윈도우 업데이트
window update: window size를 전달하기 위한 수단으로 사용되는 ACK
TCP의 ACK 정보에는 ACK 번호 뿐만 아니라 window 크기도 포함됨
TCP의 윈도우 업데이트 규칙: 강제 ACK 전송 규칙
윈도우 업데이트 시점에서 ACK를 보낼 수 없는 상태
(어짜피 ACK를 할 수 있는 시점에서는 윈도우 업데이트 필요 X)
- ACK를 할 계기를 줄 새로운 데이터의 도착이 없음
- Delayed ACK에 의해 ACK가 억제당하고 있음
응용이 열심히 퍼내서 소켓 버퍼에 빈공간이 생겼는데도 송신 측이 모르는 경우
파이프에서 데이터가 빠져 나갔는데 채워넣지 못함
→ 이러한 상황이라도 데이터 흐름에 손해를 보게될 정도가 되면 강제로 ACK시켜 이를 해결
1. 송신자 → 수신자: 데이터 보냄 (예: 3000 bytes)
2. 수신자: 다 받음 → 버퍼 거의 다 참 (윈도우 = 0)
3. 수신자: ACK 보냄 + “윈도우 0” (더 보내지 마!)
4. 수신자 내부에서 처리됨 → 버퍼가 비어감 (윈도우 증가)
5. BUT 새로운 데이터는 안 옴 → delayed ACK 상태
6. 시간이 지나도 송신자는 ‘윈도우 0’으로 착각 → 데이터 안 보냄
7. 수신자: “이거 안 되겠는데?” → **강제로 윈도우 update ACK 전송!**
8. 송신자: “오! 윈도우 생겼네?” → 데이터 전송 재개송신 측이 알고 있는 윈도우의 RE가 2MSS 이상 오른쪽으로 이동할 수 있다면 즉시 ACK를 보냄
13.4.3 발신 버퍼와 수신 버퍼가 TCP의 성능에 끼치는 영향
흐름제어 성능에 영향을 끼치는 중요한 값 = 수신 측 소켓 버퍼의 크기
그에는 못미치지만 발신 측 소켓 버퍼의 크기도 영향을 미침!
데이터 채널의 용량 = 대역폭 * 지연 Bandwidth-delay product BDP
대역폭 [bits/s]: 초당 파이프에 넣을 수 있는 데이터 양 (B)
지연 [s]: 데이터가 파이프를 끝까지 통과하는데 걸리는 시간 (L)
⇒ BDP = 파이프 안에 동시에 들어있을 수 있는 데이터의 총량
만약 수신자가 데이터를 받을 수 없는 상황이되면?
수신 소켓 버퍼에서 데이터를 퍼내던 응용 프로세스가 CPU 할당을 받지 못하는 경우
→ 파이프에서 움직이던 BDP에 해당하는 양 만큼의 데이터 유실!
⇒ 수신자는 항상 수신 소켓 버퍼의 크기를 2*BDP를 감당할 수 있을 정도의 크기로 마련
BDP만큼을 더 받더라도 더 이상 받을 수 없다는 연락을 보내는 동안 또 BDP만큼이 올 수 있기 때문
→ 2 * BDP
BUT TCP 연결에서 B, L은 제각각이고 연결 도중 바뀔 수도 있음
현재의 TCP는 계속 P의 크기를 모니터링하며 수신 소켓 버퍼의 크기를 조절할 수 있음
2P = 2 L B
B = 2P / 2L → B_bottleneck = 병목의 속도, 분모: RTT, 분자: 바람직한 수신 소켓 크기
만약 2P를 바람직한 크기보다 훨씬 작게 설정해놓았다면? B_bottleneck보다 값이 작아짐
→ 실제 병목이 제공할 수 있는 용량보다 더 낮은 속도
⇒ 이런 문제를 해결하기 위해 상당히 큰 수신 소켓의 크기를 사용해야함
BUT 수신 소켓 버퍼가 너무 커지면 여기에 쌓인 데이터는 응용이 퍼내가기 전까지 또 다른 큐잉 지연의 원인!
→ 단대단 end-to-end 지연이 커져 사용자 경험에 좋지 않
⇒ 수신 소켓이 무조건 크다고 좋은 것은 아님
그럼 어느정도의 크기로 소켓 버퍼를 설정해야하는가?
TCP 연결마다 BDP를 수용할 수 있는 크기로 버퍼 설정
Dynamic Right Sizing (DRS)
수신자가 TCP 패킷 헤더와 타임스탬프 옵션을 기반으로 BDP 추정 → window size에 반영
Auto-tuning
DRS와 달리 BDP 추정과는 상관 X
소켓 버퍼에 할당할 수 있는 시스템 메모리 크기의 여유를 봐가며 버퍼 크기 조절
버퍼가 가득 차면 더 크게 만들어서 계속 데이터가 흐를 수 있게 해줌
간접적으로 TCP 성능을 높임
발신 소켓 버퍼가 너무 작으면 응용 프로세스가 소켓에 데이터를 쓸 때 버퍼가 가득 차있을 수 있음
→ 커널 block
네트워크나 수신측 peer 때문에 데이터가 나가지 못하는 경우
→ 발신 소켓 버퍼의 데이터가 다시 실려 나감
BUT 버퍼가 너무 작으면 비어있던 파이프를 채울 정도로 데이터가 충분 X
⇒ 수신자가 막혀있어도 그 동안 송신자가 버퍼에 계속 쓸 수 있어야 함!
⇒ 발신 소켓 버퍼도 충분히 크게 잡아야함
13.5 에러 제어
TCP segment는 IP 데이터그램에 실려 전송되므로 유실 위험성 존재
13.5.1 ACK 규칙
segment 헤더에 적힌 SN = s, 정상적인 SN = a, segment의 크기 = L
-
기대했던 SN = a
정상적으로 받은 데이터를 수신 소켓 버퍼에 넣음
→ ACK = a + L 전송 계획 (delayed ACK로 일단 계획)
-
기대보다 큰 SN > a → 통상적인 의미에서의 에러 제어가 필요한 경우
- 어떤 segment가 네트워크 안에서 유실된 후, 그 뒤의 segment는 정상 도착한 경우
순서가 맞지 않는 segment → reordering buffer에 넣음
- SN = a+1인 짧은 segment가 오는 경우
Persist Probe에 해당하는 데이터
0-window ACK가 있었던 경우 송신자가 수신 소켓 버퍼에 여유가 생겼는지 주기적으로 질문하기 위함
0-window ACK = window size가 0이라고 적어서 ACK 한 것
→ 송신측 window의 LE = RE, RE를 넘어서 데이터를 전송했다!
→ 두 경우 모두 ACK = a 즉시 전송 (긴급한 상황이므로 delayed ACK 적용 X)
- 어떤 segment가 네트워크 안에서 유실된 후, 그 뒤의 segment는 정상 도착한 경우
-
기대보다 작은 SN < a
자주 일어나지 않는 특별한 경우 Keepalive Probe
이미 받아서 수신 소켓 버퍼로 들어간 데이터에 해당하는 SN을 달고 새로운 segment가 온 것
일부러 비정상적인 SN을 설정해보냄으로서 수신자가 살아있는지 체크
보낼 데이터가 없으므로 헤더만 전송→ ACK = a 즉시 전송
13.5.2 segment 유실의 발견
TCP 송신자가 segment 유실을 알게되는 경우
-
재전송 타이머 Retransmission Timer
TCP segment가 전송됐는데 RTT가 지나도록 ACK가 도착하지 않는 것을 알 수 있도록 타이머 존재
타이머의 초기값: RTO Retransmission Time Out = avg(RTT) + 4 * dev(RTT)
전송된 segment는 재전송 큐에 복사 + 전송된 시간 기록커널이 주기적으로 큐를 체크하면서 현재 시각과 전송된 시간 차이가 RTO가 넘는 segment 체크
ACK가 도착한 경우 ACK된 모든 segment는 큐에서 삭제P[RTO < RTT] ≤ 1/16 by Chebyshev
-
중복 ACK duplicate ACK (Fast Retransmit)
수신측에서 비정상적인 SN을 받은 경우 앞서 정상적으로 받았을 때의 ACK와 동일한 값 전송
→ 중복 ACK 발생중복 ACK가 3개 발생하면 ACK되고 있는 SN를 가진 segment가 유실되었다고 판단
segment가 3(경험적으로 판단)개나 도착할 동안에도 아직 도착하지 않음
→ 라우팅의 문제로 순서가 뒤집어진게 아니라 아예 유실된 것이라고 생각재전송 타이버로 유실 사실을 발견하고 재전송 하는 것보다 빠름 → Fast Retransmit
FR: RTT + 3d
RT: avg(RTT) + 4 * dev(RTT) (수십, 수백ms 가능)→ 3d << 4 * dev(RTT) 해상도가 낮은 타이머를 쓸 수록 더 차이가 커짐
Fast Retransmit을 사용할 수 있는 조건
- window size가 커서 여러 segment가 한 번에 전송될 정도여야 함
유실된 segment 이후로도 3개의 segment가 더 들어와야 하기 떄문
- 혼잡이 발생하여 유실이 일어난 라우터의 혼잡 정도가 극심해서는 안됨
한 segemnt가 유실된 직후의 다음 segment는 정상적으로 도착해야함!
⇒ Fast Retransmit이 아예 재전송 타이머를 완전히 대체할 수 있는 것 X
- window size가 커서 여러 segment가 한 번에 전송될 정도여야 함
13.6 TCP 타이머
13.6.1 Delayed ACK 타이머
TCP 수신자는 즉각적으로 ACK를 하지 않음
→ ACK 패킷을 보내기 싫기 때문
ACK 패킷은 TCP 헤더 + IP 헤더로만 구성되어도 최소 40B
⇒ 단독으로 ACK 패킷을 보내지 말고 해당 방향으로 가는 데이터가 있을 때 같이 전송!
사실 대역폭이 증가한 오늘날에는 딱히 필요는 없지만 여전히 기본 구성으로 존재
TCP segment가 도착하면 타이머가 시작
만약 타이머가 돌고 있다면 새로 시작하지는 않음
⇒ 지연 값이 도착하는 모든 패킷에 정확히 적용되는 것은 아님!
delayed ACK가 타임아웃 될 때까지는 지연된 segement들이 증가
결국 타임아웃이 되면 N:1의 비율로 ACK 발생 (N ≥ 1)
사람들이 ACK가 두 segment당 하나로 온다고 오해할까?
Delayed ACK 알고리즘과 window update 규칙의 상호작용으로 인한 것!
윈도우 업데이트 규칙: 응용이 수신 소켓 버퍼에서 데이터를 퍼가서,
2MSS 이상의 추가 공간 발생시 무조건 송신자에게 ACK 보냄
= 송신 측 window의 RE가 오른쪽으로 2MSS 이상 움직일 수 있는 경우
⇒ 수신 측 응용이 열심히 퍼가고 있다면 윈도우 업데이트 규칙에 의해 ACK 발생
(Delayed ACK가 오버라이드 됨)
서버에서 커다란 파일을 다운로드 받을 때, 응용이 프로세서를 대부분 점유할 수 있다면 발생하는 일!
Delayed ACK로 ACK를 억누를 수 있는 최대시간은 시스템 마다 다름
표준으로는 500ms까지 가능 BUT 최근에는 시간을 대폭 축소하는 경향이 있음
13.6.2 Persist 타이머
ACK의 window size 값이 0으로 왔을 때 TCP 송신자가 시작하는 타이머
window size = 0 → ACK를 할 당시 수신 측 소켓 버퍼가 꽉 찼다는 뜻 = 0-윈도우 ACK
0-윈도우 ACK를 받으면 송신자는 더 이상 데이터를 보낼 수 없음 (흐름제어)
TCP 수신자로부터의 윈도우 업데이트를 기다려야함
BUT 윈도우 업데이트 = ACK 패킷
→ IP 데이터그램에 실려 운반되므로 유실 될 수 있음!
만약 윈도우 업데이트 내용을 담은 ACK 패킷이 유실된다면 서로 데이터를 보내지 못하는 상황
→ Persist 타이머를 설정하여 이 값이 타임아웃되면 혹시 ACK가 유실된 것인지 의심
→ 수신자에게 작은 데이터 조각을 보내봄 1B
(흐름제어상 1바이트도 더 보내면 안되지만 이 경우 유일한 에외)
window의 RE 너머 1바이트를 보냄 = persist probe
Persist Probe를 보냈을 때 수신 측의 반응
- 다시 0-window ACK 보냄 + 1B도 수신할 수 없었음을 ACK 번호로 표현
persist 하는 동안 전혀 상황의 변화가 없었던 것
수신 소켓의 버퍼가 여전히 가득 차있음!
- 다시 0-window ACK 보냄 + 1B는 수신
수신자의 상황 변화가 있었지만 윈도우 업데이트를 보낼 정도의 공간 확보는 X
1B정도는 받을 수 있어서 받고 ACK 번호 1증가
수신자는 약간의 공간이 있더라도 1MSS 보다 작으면 거짓말을 함
= Silly Window Syndrom (SWS) 회피
상황 변화가 있긴 했으므로 타이머의 값을 2배로 올리진 않음
- 0이 아닌 window 값을 보내며 1B 수신
윈도우 업데이트 ACK가 실제로 유실됐었던 경우
13.6.3 Keepalive 타이머
KeepAlive 타이머는 표준에는 없음
BUT 실제 시스템에서 서버들에서 불필요한 자원 낭비를 막기 위해 많이 사용
TCP의 half-open 상태: 클라이언트가 혼자 조용히 down된 경우 서버는 그것을 알 수 없음
연결이 정상적으로 종료되었으면 서버는 연결에 할당되었던 모든 자원 수거
BUT half-open시 수거하지 못하고 자원을 낭비하고 있게 됨!
클라이언트에서는 큰 문제가 되지 않지만, TCP 연결의 수가 아주 많은 서버의 경우 문제가 됨
⇒ 서버는 오랫동안 활동이 없는 클라이언트가 half-open 상태가 아닌지 체크
마지막으로 패킷 교환이 있었던 시점에 시작 → 2시간 후에 타임아웃 (OS마다 다름)
이 때 서버는 Keepalive probe 패킷을 보내봄
이미 2시간이나 서로 데이터를 주고 받지 않았기에 보낼 데이터가 없음, 헤더만 보냄
비활동 상태의 클라이언트라면 놀라서 반응해야함
→ 그러려면 이미 ACK를 받은 옛날 것을 보냄
→ 살아있는 client는 즉시 바른 ACK 번호를 제시하는 ACK 패킷을 보냄
→ 만약 죽었다면 응답이 없음
⇒ 1분 내외의 시간 간격을 두고 Keepalive Probe를 3~5번 정도 보내보고 응답이 안오면 연결 정리!
13.7 혼잡 제어
인터넷 프로토콜 스위트 중 가장 복잡한 TCP 중 가장 복잡한 부분!
13.7.1 혼잡 제어 알고리즘의 시작
13.7.2 Van Jacobson 알고리즘
목적: 현재 TCP 경로가 받아들일 수 있는 전송 속도를 알아내는 것!
너무 작게 설정하면 사용자에게 낮은 throughput
너무 크게 설정하면 병목 라우터(TCP 경로 상에서 가장 용량이 작은 곳)에사 패킷이 대량으로 유실
도착하는 ACK = 다음 전송할 데이터 세그먼트 출발 신호를 주는 TCP 동작
데이터 세그먼트 하나가 수신자에게 배달이 되어 파이프를 빠져나감
→ ACK 돌아옴 = 수신 측에서 잘 빠져나갔다는 뜻
→ 빠져나간 데이터 세그먼트만큼을 채워넣음
⇒ 평형 유지 equilibrium
TCP 채널애 할당할 수 있는 대역폭 * 송신자에서 수신다까지 지연 = 파이프에서 이동 중인 데이터양
혼잡 윈도우 conjestion window: 네트워크의 최대 용량을 추정하는 송신자의 추정치
네트워크가 소화할 수 있는 RTT당 전송률을 파악하기 위해 사용하는 윈도우
TCP 수신자가 보내주는 수신 소켓 버퍼 여유 공간인 window size와 다름!
W: 세그먼트 단위
- ACK가 오는 경우 → W = W + 1
한 RTT동안 전송한 W 세그먼트가 모두 ACK되어 돌아오는 겅우 1 RTT가 지난 후 1 세그먼트만큼 커짐
= additive increas AI
- ACK가 오지 않고 재전송 타임아웃 발생
→ w = 1
13.7.3 Slow Start 알고리즘
13.7.4 Fast Retransmit 알고리즘
13.7.5 Fast Recovery 알고리즘
13.8 작은 세그먼트 방지와 강건성 원칙
TCP는 일부러 세그먼트를 MSS보다 작게 만들어 보낼 이유가 없음
→ TCP/IP 헤더 오버헤드가 상대적으로 커지기 때문
데이터만 전송 소켓 버퍼에 충분히 있다면 언제나 TCP는 MSS 크기를 가진 segment를 보냄
Silly Window Syndrom SWS 회피
TCP가 작은 데이터 segment를 양산하지 않기 위해 하는 행동
수신측: 1MSS가 되지 않는 소켓 버퍼 공간은 아예 없는 척!
→ 그렇지 않으면 송신자가 1MSS 이하의 segment를 전송할 수 있기 때문
송신측: Nagle 알고리즘을 통한 작은 segment 전송 방지
Nagle 알고리즘
이미 1MSS 보다 작은 segment를 전송하여 그에 대한 ACK를 받지 못한 상황이면
또 다른 작은 segment를 내보내지 않도록 하는 것!
→ 해당 ACK가 돌아올 때까지 작은 데이터들이 버퍼에 쌓이고 나중에 한 번에 가게 됨
혼자 비싸게 택시타고 가기 vs 다같이 버스타고 가기
작은 segment에 대해 ACK가 도착하지 않아도 1MSS 이상의 바이트가 모였다면 상관없이 전송!
ex. ‘a’글자를 꾹 누르고 있는 상황
컴퓨터 입장에서는 응용으로부터 매우 천천히 ‘a’ 파이트들이 발신 소켓 버퍼에 떨어지는 중
이 때는 뒤의 입력을 기다렸다가 여러 바이트씩 묶어서 한 번에 segment로 전송!
⇒ TCP/IP 헤더 오버헤드 비율이 대폭 개선
RTT가 작은 연결에서는 ACK가 금방 돌아오므로 크게 효과 X
RTT가 작다 = 일반적으로 연결 경로가 짧고 인터넷의 가장 복잡한 부분을 거치치 않음
ex. 두 컴퓨터가 LAN을 통해 통신 → 대역폭이 커서 헤더 오버헤드로 인한 낮은 효율이 크게 문제X
반대로 RTT가 큰 연결 → 인터넷의 혼잡한 지점을 지나면서 주어진 TCP 연결에 할당된 대역폭 작음
→ 더 많은 라우터를 거칠 수록 이 가능성은 UP
온라인 게임 같은 실시간 응용은 Nagle 알고리즘이 방해가 되기도 함
⇒ 응용에 따라서는 Nagle 알고리즘을 비활성화하는 경우도 있음
왜 송신 측에서 Nagle 알고리즘이 잘 수행되고 있는데 굳이 수신 측에서 SYS 회피를 해야되냐?
TCP 설계에서 Postel의 강건성 원칙 robustness principle
“Be conservative in what you do, be liberal in what you accept from others.”
패킷 전송에 있어서 남이 규칙을 지킬 것이라고 믿지 말되 너는 규칙을 지켜라
SWS는 peer 중 어느 한 쪽이라도 규칙을 지키면 작은 segment의 남발 문제를 해결 할 수 있음
Nagle 알고리즘 ↔ Delayed ACK 알고리즘
TCP는 full-duplex 프로토콜이므로 두 개의 데이터 채널 존재
만약 Nagle이 작은 segment의 전송을 막고 있었음
그런데 Delayed ACK 타이머가 눌려 그동안 억눌렸던 ACK 전송
작은 segment를 만들만큼의 데이터 밖에는 발신 소켓 버퍼에 없는 상황
→ 그럼 ACK는 데이터 없이 헤더만 보낼까? Nagle을 따라야 하니까? → NO ❌
이왕 ACK를 보내는 김에 데이터도 같이 보내버림
어차피 Nagle 알고리즘은 헤더로 인한 오버헤드를 줄이기 위한 알고리즘인데
거꾸로 헤더 오버헤드를 늘리는 결정을 하는 것은 말이 안됨!
윈도우 업데이트 규칙 ↔ SWS
윈도우 업데이트 규칙이 되는 2MSS와 수신측 SWS에서 조건이 되는 1MSS
윈도우 업데이트 규칙 → 1) 새롭게 발생한 공간에 대해 2) ACK를 보낼까 말까
SWS → 1) 소켓 버퍼에 이미 존재하지만 너무 작은 공간을 2) 제대로 알려줄까 말까
⇒ 데이터 도착에 의해 ACK를 하게 되었다면 이미 윈도우 업데이트 규칙은 해당 X
이 경우 소켓 버퍼에 있는 공간의 크기가 1MSS보다 크냐 작냐의 문제만 남음
→ 작으면 0으로 보냄
