
SEC 0. Database 1 - DATABASE 소개 및 본질 알아보기 ref.1 ref.2
DATABASE 1 수업소개
- 데이터가 중요한 이유: 데이터를 가공해서 다양한 일을 할 수 있음
- 인터넷에 연결된 웹과 앱을 통해 소식과 지식을 전파할 수 있고, 빅데이터나 인공지능 같은 기술을 이용해서 대규모의 데이터로부터 통찰력있는 분석 결과를 뽑아낼 수 있음
- 이를 위해 데이터를 저장하고 꺼내는 일을 해야 함
- file: 운영체제마다 파일 기능을 제공하기 때문에 어디에서나 사용할 수 있음
- 성능이나 보안의 한계성 존재
- database: 파일의 한계를 극복, 소중한 데이터를 안전하고 편리하게 보관
- MySQL, Oracle, SQL Server, PostgreSQL, MongoDB 등
- 데이터베이스는 거대하고 복잡하고 위험한 데이터를 다루기 위해 고안된 도구
데이터베이스의 본질
- 데이터베이스는 매우 방대한 기능을 가지고 있는 정보 도구
- CRUD:
- input: Create, Update, Delete
- output: Read
file vs database
- 전문적인 database들이 가지고 있는 장점:
프로그래밍적으로, 컴퓨터 언어를 이용해서 데이터를 추가하고, 수정하고, 삭제하고, 읽고, + 자동화 할 수 있음
Database 1을 마치며
- 어떤 데이터베이스를 선택할지
- 데이터베이스가 정해져 있지 않다면, 무엇을 공부할 것인지 선택할 때 통계를 기반으로 선택하면 좋음
- ex) database ranking(검색어), db-engines.com(사이트) 등
- 데이터베이스 시장의 절대 강자는 관계형 데이터베이스
- 관계형 데이터베이스와 아닌 것 비교해보며 공부해보기 - 공통적인 점은 아마 본질적인 것일 것
- Oracle: 관계형 데이터베이스, 정부/관공서, 대기업, 비쌈 등
- MySQL: 관계형 데이터베이스, 무료, 오픈소스, 대규모 데이터 but 별로 중요하지 않은 데이터를 사용하는 작은 기업 등
- MongoDB: Document store
SEC 2. MySQL 기본
MySQL의 구조
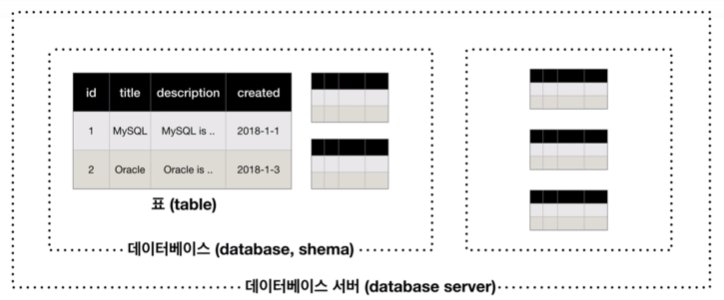
- 데이터를 기록하는 최종적인 곳은 표(table)
- MySQL(관계형 데이터베이스)은 엑셀/스프레드시트와 비슷한 구조를 갖고 있음
- 데이터는 표에 저장이 됨, 이 표가 무수히 많아짐
- 서로 연관된 표들을 그룹핑해서 연관되어 있지 않은 표들과 분리하는 파일의 폴더같은 게 있는데, 이것이 바로 데이터베이스
- 데이터베이스/스키마: 표들을 그룹핑할 때 쓰는 일종의 폴더, 서로 연관된 데이터를 그룹핑해줌
- 데이터베이스 서버: 스키마들을 모아둔 것
- 데이터베이스 서버라는 프로그램을 설치하고, 그 프로그램이 갖고 있는 기능성을 이용해서 데이터와 같은 여러가지 작업을 함
MySQL 서버 접속
- 보안: 데이터베이스의 자체적인 보안체계가 있어 데이터를 안전하게 보관할 수 있음
- 권한: MySQL에 여러 사람의 접근 권한을 차등적으로 설정할 수 있음
./mysql -uroot -p(혹은 pw 바로 입력)
# -uroot : root라는 사용자로 접속, root는 관리자로 모든 권한이 있으니 주의
# window(실습시)
mysql -u root -pMySQL 스키마의 사용
- create database
CREATE DATABASE (db_name);
CREATE DATABASE dbdb;- delete database
DROP DATABASE (db_name);
DROP DATABASE dbdb;- how to show database list in mysql
SHOW DATABASES;- use - 지금부터 이 데이터베이스를 사용하여 작업하겠음을 의미
USE (db_name);
USE dbdb;SQL과 테이블 구조
- SQL: Structured Query Language
- Structured: 관계형 데이터베이스가 기본적으로 표의 형식으로 정리정돈 할 수 있음, 표를 작성하는 것, 즉, 구조화 되었다-
- Query: 데이터베이스에게 무언가를 요청하는 것
- Language: 데이터베이스도 이해할 수 있고 사용자도 이해할 수 있는 언어(SQL)
- SQL의 특징
- 쉬움
- 중요함: SQL라는 컴퓨터 언어는 관계형 데이터베이스라는 카테고리에 속하는 제품들이 공통적으로 데이터베이스 서버를 제어할 때 쓰이는 표준화된 언어
- 가성비가 아주 뛰어난 언어!

- table, 표: x축(row, record, 행, 데이터 하나하나, 데이터 자체)과 y축(column, 열, 데이터의 구조, 데이터의 타입)
- 위의 그림은 행 2개/데이터 2건, 컬럼 4개
SEC 3. MySQL 테이블의 생성
MySQL 테이블의 생성 1

- create table in mysql (by searching cheat sheet)
- 컬럼의 데이터 타입을 강제할 수 있음
CREATE TABLE table_name(
col1_name datatype(length)
# length: 값을 얼마나/어디까지 노출시킬 건지
);
CREATE TABLE topic(
id INT(11) NOT NULL AUTO_INCREMENT,
...MySQL 테이블의 생성 2
- create table in mysql (by searching cheat sheet)
- 컬럼의 데이터 타입을 강제할 수 있음
CREATE TABLE table_name(
col1_name datatype(length)
# length: 값을 얼마나/어디까지 노출시킬 건지
);
CREATE TABLE topic(
id INT(11) NOT NULL AUTO_INCREMENT,
# NOT NULL: 값이 없는 것을 허용하지 않음
# AUTO_INCREMENT: id 컬럼은 자동으로 n씩 증가함
title VARCHAR(100) NOT NULL,
# 100: 100글자 까지, 1000글자가 들어오면 100글자까지 자름
description TEXT NULL,
# NULL: 값이 없는 것을 허용함
created DATETIME NOT NULL,
author VARCHAR(30) NULL,
profile VARCHAR(100) NULL,
PRIMARY KEY(id)
# PRIMARY KEY: 성능, 중복 방지-
);
- mysql 8.0 에서 datetime 은 1000-01-01 00:00:00 ~ 9999-12-31 23:59:59 만 허용
이전 mysql 5.x 버전에서
datetime NOT NULL default '0000-00-00 00:00:00'
허용되지 않는 0000-00-00 00:00:00 값이 들어가서 에러가 발생
이때는 SQL MODE 를 변경해 주어야 함 ref.
set sql_mode='ALLOW_INVALID_DATES';
- password 관련 에러: 기본 비밀번호를 쓰는 경우 비밀번호 설정 권고
SET PASSWORD = PASSWORD('123123') # 123123: 사용할 비밀번호


- 데이터베이스가 여러가지 규제/정책을 가지고 있고, 그 규제/정책 덕분에 데이터를 깔끔하게, 원하는 형식으로 유지하는 데 큰 도움을 줄 수 있음
SEC 4. MySQL CRUD
MySQL CRUD
- Create Read Update Delete : 데이터베이스의 기본적인 작업 요소, 데이터베이스의 본질
- Create/Read : 데이터베이스의 필수적인 작업 요소
SQL의 INSERT 구문
- create row
INSERT INTO table_name (col1_name, col2_name, ...)
VALUES (val1, val2, ...)
SHOW TABLES; # 테이블 리스트 확인
DESC table_name; # 테이블의 구조 확인
INSERT INTO topic (title, description, created, author, profile) VALUES('MySQL', 'MySQL is ...', NOW(), 'egoing', 'developer');
# NOW(): 현재 시간을 나타내는 함수- read row
SELECT * FROM topic; # 테이블 전체 읽기SQL의 SELECT 구문
- 모든 데이터 출력
SELECT * FROM table_name;- 원하는 컬럼만 출력
SELECT col1_name, col3_name... FROM table_name;- 특정 컬럼의 특정 값만 출력
SELECT col1_name, col3_name... FROM table_name WHERE col3_name='sth';- 정렬하여 출력
SELECT col1_name, col3_name... FROM table_name WHERE col3_name='sth' ORDER BY id DESC;
# DESC: 내림차순- 원하는 개수만큼 데이터 출력
SELECT col1_name, col3_name... FROM table_name WHERE col3_name='sth' ORDER BY id DESC LIMIT 2;SQL의 UPDATE 구문

- update - WHERE문 넣어주는 것 중요
# example)
UPDATE topic SET author='duru', profile='data administrator' WHERE id=3;
SQL의 DELETE 구문
- delete - WHERE문 넣어주는 것 중요
# example)
DELETE FROM topic WHERE id=5;
SEC 5. 더 배워보기
수업의 정상
- 혁신(innovation)-Relational(관계형)과 본질(essence)-Database-CRUD
- 왜 관계형 데이터베이스들은 왜 다른 것들과 구분되는지
관계형 데이터베이스의 필요성
- 왜 관계형 데이터베이스가 필요한지
- 중복되고 있는 데이터가 존재하는 경우
- 개선할 점이 있다는 강력한 증거가 될 수 있음
- 용량, 기술적, 경제적 문제가 있을 수 있음
- 중복을 제거하여 별도의 새로운 테이블을 만들면 여러 장점이 생김
- 별도의 표를 열어서 비교해봐야 하는 등의 번거로움/단점이 생김
- 데이터베이스에 데이터가 저장될 때는 분산되게 보여줄 때는 합쳐서
테이블 분리하기
- 테이블 이름 변경
RENAME TABLE topic TO topic_backup;- topic 테이블 생성
CREATE TABLE `topic` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`title` varchar(30) NOT NULL,
`description` text,
`created` datetime NOT NULL,
`author_id` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
);- 데이터 INSERT
INSERT INTO `topic` VALUES (1,'MySQL','MySQL is...','2018-01-01 12:10:11',1);
INSERT INTO `topic` VALUES (2,'Oracle','Oracle is ...','2018-01-03 13:01:10',1);
INSERT INTO `topic` VALUES (3,'SQL Server','SQL Server is ...','2018-01-20 11:01:10',2);
INSERT INTO `topic` VALUES (4,'PostgreSQL','PostgreSQL is ...','2018-01-23 01:03:03',3);
INSERT INTO `topic` VALUES (5,'MongoDB','MongoDB is ...','2018-01-30 12:31:03',1);- author 테이블 생성
CREATE TABLE `author` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(20) NOT NULL,
`profile` varchar(200) DEFAULT NULL,
PRIMARY KEY (`id`)
);- 데이터 INSERT
INSERT INTO `author` VALUES (1,'egoing','developer');
INSERT INTO `author` VALUES (2,'duru','database administrator');
INSERT INTOuthor` VALUES (3,'taeho','data scientist, developer');JOIN - 관계형 데이터베이스의 꽃
- topic 테이블의 'author_id'와 author 테이블의 'id'의 값은 같다고 여기고 JOIN
SELECT * FROM topic LEFT JOIN author ON topic.author_id=author.id;- topic.author_id, author.id를 지우고예쁘게 정리
SELECT topic.id, title, description, created, name, profile FROM topic LEFT JOIN author ON topic.author_id=author.id;- 컬럼 이름 변경해서 출력
SELECT topic.id AS topic_id, title, description, created, name, profile FROM topic LEFT JOIN author ON topic.author_id=author.id;-
JOIN을 이용하여 분리된 테이블을 읽을 때 식별자(example: author_id/id)를 통해 통합해서 읽을 수 있음
-
테이블을 분리함으로써 데이터 하나를 바꿀 때, 관련된 모든 테이블들의 정보를 바꿀 수 있음
-
comment 테이블 생성 및 데이터 INSERT, JOIN
create table comment (
id int(11) not null auto_increment,
description varchar(130) null,
author_id int(11) null,
primary key (id)
);
insert into comment (id, description, author_id)
VALUES (1, 'mysql is awesome', 1);
insert into comment (id, description, author_id)
VALUES (2, 'postgres is awesome', 1);
insert into comment (id, description, author_id)
VALUES (3, 'I wanna be skilled-full back end developer', 2);
insert into comment (id, description, author_id)
VALUES (4, 'I wanna study more', 1);
select comment.id as comment_id, description, name, profile from comment left join author on comment.author_id = author.id;
select * from comment left join author on comment.author_id=author.id;
select comment.id, description, name, profile from comment left join author on comment.author_id=author.id;인터넷과 데이터베이스
- 정보의 바다라고 할 수 있는 인터넷 위에서 데이터베이스가 동작하게 되면 굉장히 파워풀한 효과를 낼 수 있음
- MySQL은 내부적으로 인터넷을 활용할 수 있도록 고안된 시스템
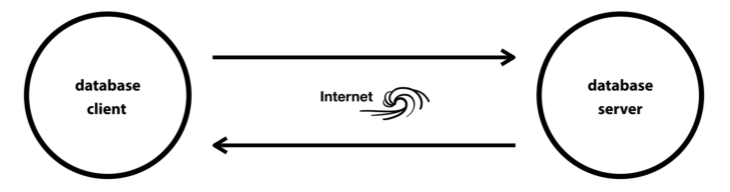
- internet:
- 인터넷을 사용하기 위하여, 인터넷이 동작하기 위하여 필요한 컴퓨터의 최소 수량, 2대
- 각자 흩어져 있는 컴퓨터들이 인터넷으로 연결되면서, 말하자면 컴퓨터들 간의 사회가 만들어지는 것, 한 대의 컴퓨터가 가지고 있는 한계를 초월해버림
- client(서비스 요청), server(서비스 제공) - 서로 정보를 요청하고 응답하면서 동작
- database client를 통해서만 database server를 사용/접근할 수 있음
- example) database client-mysql(명령어를 통해 database server를 제어) monitor, workbench...
MySQL 클라이언트
- monitor 장점: MySQL 서버를 설치하면 함께 설치되기 때문에 MySQL 서버가 있는 곳에 MySQL 모니터가 있어 어디에서나 사용할 수 있음, GUI가 아니고 명령어 기반의 프로그램, 많은 서버 컴퓨터들이 컴퓨터의 자원을 그 일 자체에 투여하기 위해 GUI 기능을 제공하지 않는 경우가 있음, 이 경우 workbench는 실행할 수 없으나 monitor는 가능
- monitor 단점: 명령어를 기억하고 있어야 함
- 하는 일에 따라 맥락적으로 선택하여 사용해야 함
- 종류가 다양하므로 선호도나 주머니 사정에 따라 적절하게 선택
MySQL Workbench
- GUI 기반 MySQL 클라이언트
- mysql monitor
mysql -u root -p -h localhost
# -h: host의 약자, host는 인터넷에 연결되어 있는 각각의 컴퓨터
# 실행하려고 하는 MySQL monitor라는 클라이언트로 인터넷을 통해서 다른 컴퓨터에 있는 MySQL 서버에 접속하려고 하면
# 옆에 그 서버에 해당되는 컴퓨터의 주소를 적으면 됨
# monitor와 Workbench가 같은 컴퓨터에 설치되어 있기 때문에 localhost 또는 127.0.0.1 입력
# local host면 생략해도 됨: mysql -u root -p- Workbench 기본 사용 방법 ref. 참고
SEC 6. DATABASE 2 - MySQL 마무리
DATABASE 2 MySQL 수업을 마치며
- 두가지 길
- 지금까지 배운 것을 사용해서 어떤 현실의 문제를 해결하는 것
- 배운 것만으로는 극복할 수 없는 한계를 극복할 수 있도록 앞서간 엔지니어들이 잘 정립해 놓은 이론 내지는 기술과 같이 혁신적인 것들을 배우는 것
- TIPs(?) of keyword(?)
- sql(CRUD...)
- index
- modeling
- backup(mysqldump, binary log...)
- cloud(AWS RDS, Google Cloud SQL for MySQL, AZURE Database for MySQL...)
- programming(Python/PHP/Java... mysql api...)
