
컴파일러의 일반적 구조
컴파일러는 고급 언어로 쓰여진 프로그램을 어떤 특정한 컴퓨터에서 직접 실행 가능한 형태의 프로그램으로 번역해 주는 컴퓨터 프로그램이다.
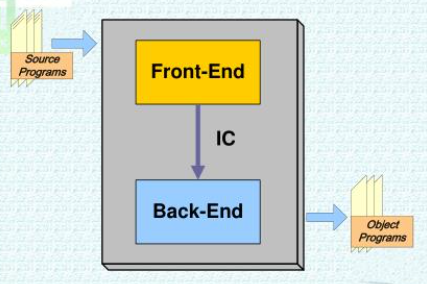
컴파일러의 구조는 크게 전단부(front-end)와 후단부(back-end)로 나눌 수 있다.
- 전단부 : 소스 언어에 관계되는 부분으로 소스 프로그램을 분석하고 중간 코드를 생성하는 부분
- 각 언어마다 하나씩 필요
- 문법 이론에 의해 잘 정립됨
- 소스 프로그램을 읽어 들이는 어휘 분석 단계로부터 중간 코드를 생산하는 중간 코드 생성 단계까지로, 출력은 중간 코드
- 후단부 : 소스 언어보다는 목적 기계에 의존적이며 전단부에서 생성한 중간 코드를 특정 기계를 위한 목적 코드로 번역하는 부분
- 목적 기계 당 하나씩 필요
- 경험적인 방법을 통하여 구현하며 계속적인 연구가 진행되고 있는 부분
- 전단부 이후의 프로세스, 중간 코드에 대한 목적 프로그램이 생성됨
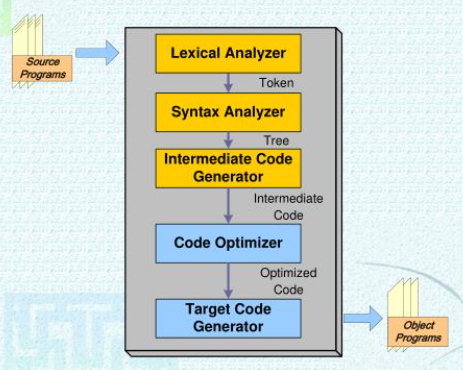
전단부
-
어휘 분석(lexical analysis)은 어휘 분석기(또는 스캐너)에 의해 이루어지며 이는 소스 프로그램을 읽어 들여 일련의 토큰을 생성하는 일을 한다.
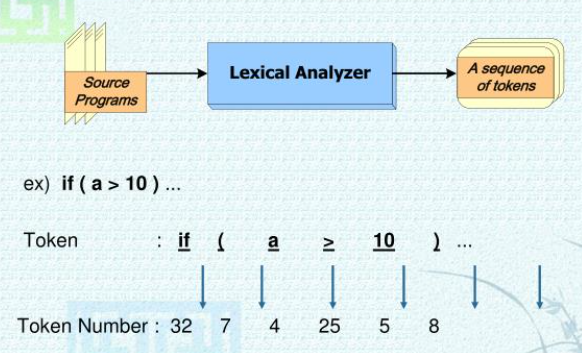
- 토큰 : 문법적으로 의미를 갖는 최소의 단위, 프로그램은 토큰의 열로서 구성되어 있음
- 토큰의 종류 :
1) 특수 형태 : 언어를 정의할 때 언어 설계자가 결정하는 지정어(keyword), 연산자 기호, 구분자(delimiter) 등 // (, >=, )...
2) 일반 형태 : 프로그래머가 프로그래밍할 때 사용한 명칭과 상수들 // if, a, 10... - 토큰 번호 : 각 토큰들은 효율적인 처리를 위해서 고유의 내부번호를 정수 형태로 갖음
- 생성된 토큰들은 다음 과정인 구문 분석 단계의 입력이 됨
-
구문 분석기(syntax analyzer)는 파서(parser)라고도 하는데, 어휘 분석 단계의 출력인 토큰들을 받아 소스 프로그램에 대한 에러를 체크하고 올바른 문장에 대해서 구문 구조를 만든다.

- 소스 프로그램에 에러가 있으면 그에 해당하는 에러 메시지를 출력하고 그렇지 않으면 프로그램에 대한 구문 구조를 트리 형태로 만들어 출력한다.
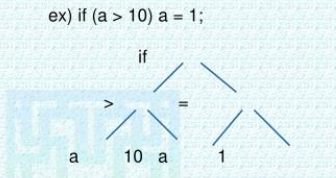
- 프로그램의 구문 구조를 트리형태로 표현하는 방법에는 파스 트리(parse tree)와 추상 구문 트리(abstract syntax tree)가 있는데 대부분의 컴파일러에서는 추상 구문 트리를 사용한다.
- 다음은 if(a>10) a=1; 배정문의 추상 구문 트리이다.
-
중간 코드 생성(intermediate code generation) 과정에서는 파서의 출력인 추상 구문 트리를 입력으로 받아 의미 검사(semantic checking)를 행하고 그에 해당하는 중간 코드를 생성한다.
[그림1.11]
컴파일러는 언어의 특성과 목적 기계, 그리고 컴퍼일러를 구현하는 사람에 따라 다른 구조를 가질 수 있기 때문에, 컴파일러에 따라 독립된 의미 분석 단계를 가질 수 있다.- 형 검사(type checking) : 의미 분석 단계에서 하는 중요한 일 중 하나로, 각 연산자(operator)가 소스 언어의 정의에 맞는 피연산자(operand)를 가지는가를 검사하는 것
- 형 변환(type conversion), 의미 분석 단계에서 처리
- ex1) 대부분의 프로그래밍 언어에서는 실수가 배열의 첨자로 사용되었을 때 에러로 간주
- ex2) 어떤 언어에서는 실수와 정수의 혼합 연산을 허용하는데 이때는 연산을 수행하기 전에 정수를 실수로 바꾸어 주는 작업이 필요
- 중간 코드 생성 :구문 분석 단계에서 만들어진 구문 구조를 이용하여 코드를 생성
- 구문 트리를 운행하면서 각 구문에 해당하는 중간 코드를 생성
# 배정문 a=b+10 lod 1 2 // load b ldc 10 // load constant 10 add // addition str 1 1 // store a- b의 값과 상수 10을 스택에 적재한 다음 덧셈을 해서 a에 저장, 여기서 사용한 중간 언어는 U-코드
- 형 검사(type checking) : 의미 분석 단계에서 하는 중요한 일 중 하나로, 각 연산자(operator)가 소스 언어의 정의에 맞는 피연산자(operand)를 가지는가를 검사하는 것
후단부
-
코드 최적화(code optimization)는 같은 의미를 유지하면서 코드를 보다 더 효율적으로 만들어 코드 실행시 기억 공간이나 실행 시간을 절약하는 데 도움을 주는데, 이는 선택적인 단계로 생략되는 경우도 있다. 중간 코드 생성 단계에서 생성된 중간 코드들은 코드 최적화 단계의 입력으로 사용될 수 있다.
[그림1.12]
- 최적화되는 관점에 따라 지역 최적화와 전역 최적화로 구분할 수 있다.
- 지역 최적화(local optimization or peephole optimization) :
- 기본 블록 내에서 행해지며 부분적인 관점에서 일련의 비효율적인 코드들을 구분해 내고 좀 더 효율적인 코드로 개선하는 방법으로 실제로 상당한 수준의 코드 효율화를 취할 수 있음
1) 컴파일 시간 상수 연산(constant folding)
2) 중복된 load, store 명령문 제거
3) 식(expression)의 대수학적 간소화
4) 연산 강도 경감
5) 불필요한 일련의 코드 블록(null sequence) 삭제 등
- 기본 블록 내에서 행해지며 부분적인 관점에서 일련의 비효율적인 코드들을 구분해 내고 좀 더 효율적인 코드로 개선하는 방법으로 실제로 상당한 수준의 코드 효율화를 취할 수 있음
- 전역 최적화(global optimization) :
- 흐름 분석 기술을 이용하여 기본 블록들 사이에 최적화를 행하는 것
1) 공통 부분식 축약
2) 루프 내에서 값이 변하지 않는 코드를 루프 밖으로 이동
3) 도달될 수 없는 코드의 제거 등
- 흐름 분석 기술을 이용하여 기본 블록들 사이에 최적화를 행하는 것
- 지역 최적화(local optimization or peephole optimization) :
[그림1.13]
- 최적화는 그 위치에 따라 precode optimization과 postcode optimization으로 나눌 수 있다.
- precode optimization : 중간 코드를 이용하여 최적화를 수행하며 그 위치는 목적 코드 생성 전에 행해짐
- postcode optimization : 목적 코드 생성 후에 목적 코드를 최적화하는 방법으로 기계 의존적인 최적화 방법
- 최적화되는 관점에 따라 지역 최적화와 전역 최적화로 구분할 수 있다.
-
목적 코드 생성기(target code generator)는 중간 코드를 입력으로 받아 그와 의미적으로 동등한 목적 기계에 대한 코드를 생성하는 일을 한다.
- 목적 코드 생성기가 목적 코드를 생성하기 위해 행하는 일
1) 목적 코드 선택 및 생성
2) 레지스터의 운영
3) 기억 장소 할당
4) 기계 의존적인 코드 최적화 - 각 변수들에 대한 기억 장소를 할당해야 하며 중간 코드의 의미와 일치하는 기계 명령어들을 효과적으로 선택하는 코드 생성 알고리즘을 사용해야 한다.
- 대부분의 컴퓨터들이 빠른 시간 내에 계산을 할 수 있는 소수의 고속 레지스터들을 가지고 있어, 우수한 목적 코드 생성기는 이러한 레지스터들을 가능한 한 효율적으로 사용할 수 있어야 한다. 효율적인 레지스터의 사용은 임시 변수(temporary variable)의 사용을 줄일 수 있을 뿐만 아니라 전체적인 실행 속도를 빠르게 할 수 있다. 레지스터 할당(register allocation) 문제는 효율적인 코드 생성을 위해서 매우 중요한 문제이며 많은 알고리즘이 개발되어 있다.
- 목적 코드 생성기에서 행하는 기계 의존적인 최적화는 연속적인 명령어들을 의미적으로 동등한 명령어 또는 처리 속도가 빠른 명령어로 대체하여 기계어 코드의 성능을 향상시키는 방법이다. 일반적으로 코드 생성기에 의해 생성된 코드들은 잘 훈련된 어셈블리 프로그래머들이 손으로 작성한 코드들보다 훨씬 효율적이어야 한다.
- 목적 코드 생성기가 목적 코드를 생성하기 위해 행하는 일
-
컴파일러는 소스 프로그램에 나타는 모든 자료에 대한 정보(어떤 변수가 정수 혹은 실수를 나타내는지, 배열의 크기, 함수의 인수가 몇 개 필요한지 등)들을 가지고 있어야 한다. 이런 자료에 대한 정보는 컴파일러의 앞부분, 즉 어휘 분석 단계와 구문 분석 단계에서 수집되어 심벌 테이블(symbol table)이라는 곳에 저장된다. 테이블 관리는 이러한 정보들을 관리하는 부분이며 여기에서 사용되는 자료 구조를 심벌 테이블이라 한다.
-
컴파일러의 중요한 기능 중에 하나는 소스 프로그램의 에러(어휘 분석 단계에서 소스 프로그램의 토큰의 철자가 틀리는 경우, 구문 분석 단계에서 괄호가 빠지는 것과 같은 문법 규칙에 대한 에러 등)를 발견하여 사용자에게 알려주는 것이다. 이와 같은 에러에 대한 처리 기술은 컴파일러를 실제로 구현하는데 있어 매우 중요하다. 컴파일러는 이런 에러들을 처리하여 주는 루틴(error handling routine)을 갖고 있다.
이상 컴파일러의 전반적인 과정에서, 컴파일러가 행하는 크고 복잡한 일을 기능적으로 독립적인 여러 단계들로 나누어 쉽게 구현할 수 있다는 걸 알게 되었다. 컴파일러의 구현에 있어서 하나 이상의 단계들을 모아 패스(pass)라고 하는 하나의 모듈로 묶을 수 있는데, 하나의 패스는 소스 프로그램이나 그 전 패스의 출력을 읽어들여 그 패스를 이루고 있는 단계들의 기능에 따라 입력을 변환하여 중간 파일에 출력한다. 이 출력은 다음 패스의 입력이 된다.
여러 단계가 모여 하나의 패스를 이룬다면, 서로간의 제어에 따라 각 단계들은 상호간의 수행을 할 수 있다. 어휘 분석 단계와 구문 분석 단계를 대표적인 예로 들 수 있는데, 어휘 분석기에서 무조건 토큰들을 생산하는 것이 아니라 구문 분석 단계에서 토큰이 필요할 때마다 어휘 분석 단계에게 토큰을 요구하게 하여 마치 부프로그램과 같은 역할을 할 수 있게 한다.
컴파일러의 컴파일 과정을 전단부와 후단부로 분리하여 작성하는데 초창기의 컴파일러는 이러한 구분 없이 전 과정을 하나의 패스로 구성한 단일 패스 컴파일러였다. 컴파일러에서 패스의 개수는 사용하는 목적 기계나 프로그래밍 언어에 따라 결정된다. 여러 개의 패스로 구성된 컴파일러를 다중 패스 컴파일러라 한다.
다중 패스 컴파일러는 기능에 따라 여러 패스로 구성되어 있기 때문에 컴파일러의 부분적인 기능을 개선하고 다른 기종으로 이전하기에도 편하다. 또한, 다중 패스 컴파일러는 하나의 패스가 사용했던 공간을 다음 패스가 다시 사용할 수 있기 때문에 단일 패스 컴파일러보다 작은 기억 공간을 요구한다. 그러므로, 작은 기억 공간을 가진 컴퓨터에서는 다중 패스 컴파일러가 유리하다. 그러나, 단일 패스 컴파일러보다 컴파일 속도가 느리다는 것이 단점이다.
