
앞서서 S3에 저장된 도면 파일을 다운로드 받아 텍스트 데이터를 추출한 후 DB에 저장하는 서비스를 만들었다.
하지만 상용 서비스에 비해 터무니 없이 느린 속도에 충격을 받고 코드를 수정해 보려고 한다. 다운로드 부분을 살펴보기에 앞서 속도 측정을 위해 Spring AOP(Aspect-Oriented Programming)을 사용하자
AOP 사용법
pom.xml 파일에 아래의 종속성을 추가하자
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-aop</artifactId>
</dependency>
<dependency>
<groupId>org.aspectj</groupId>
<artifactId>aspectjweaver</artifactId>
</dependency>ExecutionTimeAspect class를 만들어 아래의 코드를 입력하자
package com.cad.cad_service.util;
import org.aspectj.lang.ProceedingJoinPoint;
import org.aspectj.lang.annotation.Around;
import org.aspectj.lang.annotation.Aspect;
import org.springframework.stereotype.Component;
@Component
@Aspect
public class ExecutionTimeAspect {
@Around("@annotation(measureExecutionTime)")
public Object logExecutionTime(ProceedingJoinPoint joinPoint, MeasureExecutionTime measureExecutionTime) throws Throwable {
long startTime = System.currentTimeMillis();
Object proceed = joinPoint.proceed();
long endTime = System.currentTimeMillis();
System.out.println("{" + joinPoint.getSignature() + "}" + "executed in {" + (endTime - startTime) + "} ms");
return proceed;
}
}AOP에 대한 자세한 설명보단 사용법 위주로 간단히 살펴보면
- @Aspect 어노테이션을 사용해 이 클래스가 Aspect를 나타내는 클래스라는 것을 명시하고 @Component를 붙여 스프링 빈으로 등록한다.
- @MeasureExecutionTime 어노테이션이 붙은 모든 메서드의 실행 시간을 측정하기 위해 @Around 어노테이션으로 타겟 메서드(logExecutionTime)를 감싼다.
- 실행 시간을 터미널에 출력한다.
이제 커스텀 어노테이션인 @MeasureExecutionTime 어노테이션을 정의하자.
package com.cad.cad_service.util;
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.METHOD)
public @interface MeasureExecutionTime {
}- 런타임에 적용하기 위해 @Retention 어노테이션을 사용한다.
- Aspect를 적용하는 곳에 메서드를 추가하기 위해 @Target 어노테이션을 사용한다.
이제 측정하고자 하는 메서드에 @MeasureExecutionTime 어노테이션을 붙여주자
@MeasureExecutionTime
public void downloadFolder(String project) {
...
}다운로드 속도 높이기
리펙토링 전
@Component
@RequiredArgsConstructor
public class S3Util {
private final TransferManager transferManager;
private final AmazonS3Client s3Client;
@Value("${cloud.aws.s3.bucket}")
public String bucket;
@MeasureExecutionTime
public void downloadFolder(String project) {
try {
File s3Dir = new File("s3-download");
project = URLDecoder.decode(project, StandardCharsets.UTF_8);
MultipleFileDownload download = transferManager.downloadDirectory(bucket, project, s3Dir);
download.waitForCompletion();
} catch (AmazonServiceException e) {
log.error("Amazon service exception: ", e);
}
catch (InterruptedException e) {
log.error("Thread sleep exception: ", e);
}
}
}
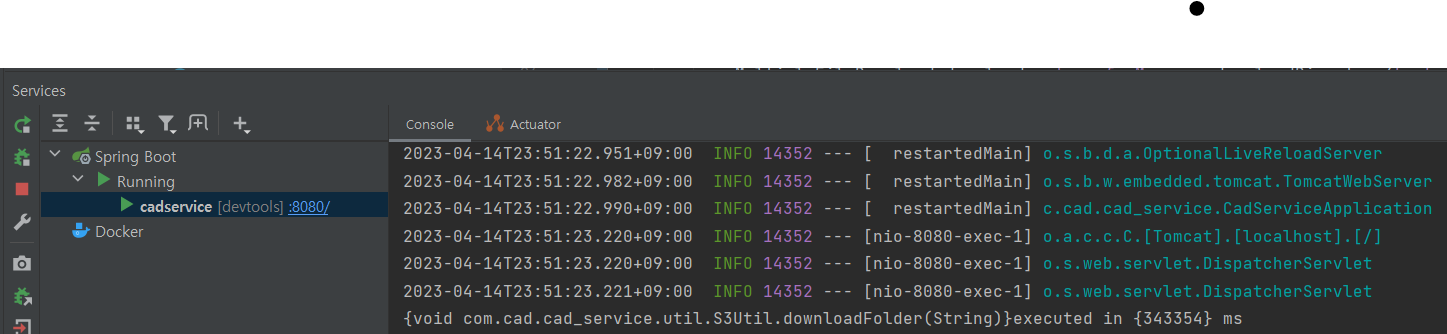
소요 시간: 343.354초
리펙토링
파일을 압축해서 업로드하고 압축 파일을 다운로드 한다면 시간을 훨씬 줄일 수 있겠지만 선택할 수 없었다. 그래서 선택한 방법이 멀티 스레딩이다.
멀티 스레딩을 사용한 다운로드를 생각했을 때 가장 먼저 Multipart가 생각이 났다. S3에서 다수의 파일을 다운로드하기 위해서는 TransferManager를 사용하는데 ] transferManager가 싱글 스레드를 사용한 다운로드 메서드를 제공한다. 스레드를 20개로 늘릴 수 있는지 기대하면서 코드를 아래처럼 바꿔보았다.
try {
AmazonS3 s3 = AmazonS3ClientBuilder.standard().withRegion(Regions.AP_NORTHEAST_2).build();
TransferManager tm = TransferManagerBuilder.standard()
.withS3Client(s3)
.withExecutorFactory(() ->
Executors.newFixedThreadPool(20, new ThreadFactoryBuilder().build())).build();
MultipleFileDownload download = tm.downloadDirectory(bucket, project, new File("s3-download"));
download.waitForCompletion();
} catch (InterruptedException e) {
System.out.println(e);
}분명 동작은 하는데 파일 형식이 깨지고 다운로드가 끝나질 않는 오류가 계속 발생했다. 때문에 이방법은 패스..
java system class의 setProperty 메서드를 사용해서 스레드 사이즈를 늘려보았다.
@MeasureExecutionTime
public void downloadFolder(String project) {
try {
File s3Dir = new File("s3-download");
project = URLDecoder.decode(project, StandardCharsets.UTF_8);
System.setProperty("s3manager.threads.max", "10");
MultipleFileDownload download = transferManager.downloadDirectory(bucket, project, s3Dir);
download.waitForCompletion();
} catch (AmazonServiceException e) {
log.error("Amazon service exception: ", e);
} catch (InterruptedException e) {
log.error("Thread sleep exception: ", e);
}
소요 시간: 333.949초 ?!
약 10초 단축되긴 했지만 유의미한 차이는 없는 것 같다. 다음 방법으로 넘어가보자.
이 링크에서 s3Client.getObject()가 transferManager.downloadDirectory() 보다 빠르다고 해서 코드를 바꿔보았다. 코드가 옛날 코드라 deprecate된 메서들이 좀 있어서 링크는 참고만 하고 본 포스팅의 코드를 보면 되겠다.
@MeasureExecutionTime
public void downloadFolder(String project) {
try {
project = URLDecoder.decode(project, StandardCharsets.UTF_8);
ListObjectsV2Result result = s3Client.listObjectsV2(bucket, project);
for (S3ObjectSummary summary: result.getObjectSummaries()) {
GetObjectRequest getObjectRequest = new GetObjectRequest(bucket, summary.getKey());
s3Client.getObject(getObjectRequest, new File(summary.getKey()));
}
} catch (AmazonServiceException e) {
log.error("Amazon service exception: ", e);
}
}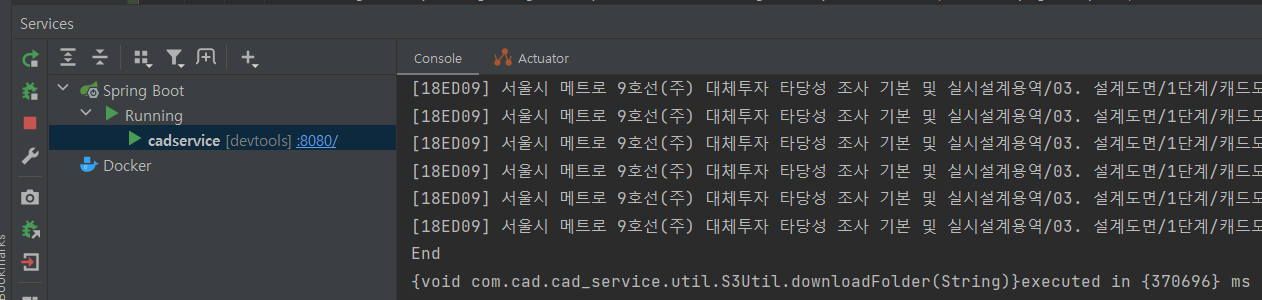
소요 시간: 379.696초
오히려 더 느려졌길래 ExecutorService 로 getObject 메서드를 감싸보았다.
@MeasureExecutionTime
public void downloadFolder(String project) {
try {
project = URLDecoder.decode(project, StandardCharsets.UTF_8);
ExecutorService executor = Executors.newFixedThreadPool(8);
ListObjectsV2Result result = s3Client.listObjectsV2(bucket, project);
for (S3ObjectSummary summary: result.getObjectSummaries()) {
GetObjectRequest getObjectRequest = new GetObjectRequest(bucket, summary.getKey());
executor.submit(() -> {
s3Client.getObject(getObjectRequest, new File(summary.getKey()));
});
}
executor.shutdown();
executor.awaitTermination(10, TimeUnit.MINUTES);
} catch (AmazonServiceException e) {
log.error("Amazon service exception: ", e);
} catch (InterruptedException e) {
log.error("awaitTermination exception: ", e);
}
}여기서 사용한 ExecutorService는 병렬 작업 시 여러 개의 작업을 효율적으로 처리하기 위해 제공되는 JDK API다. ExecutorService는 task 할당을 위해 자동으로 스레드 풀을 제공한다.
이 블로그에 좀더 자세한 설명이 적혀있었는데 그 내용은 다음과 같다.
동시에 여러 요청을 처리해야 하는 경우에 매번 새로운 쓰레드를 만드는 것은 비효율적이다. 그래서 쓰레드를 미리 만들어두고 재사용하기 위한 쓰레드 풀(Thread Pool)이 등장하게 되었는데, Executor 인터페이스는 쓰레드 풀의 구현을 위한 인터페이스이다
직접 쓰레드를 다루는 것은 번거로우므로, 이를 도와주는 팩토리 클래스인 Executors를 사용한다. ExecutorService는 인터페이스 이므로 Executors 클래스에서 제공하는 Static Factory Method를 사용해 초기화 할 수 있으며 newFiexedThreadPool의 경우 실행 머신의 CPU 코어 수를 기준으로 생성하면 더 좋은 퍼포먼스를 얻을 수 있다고 한다. 현재 사용하는 노트북의 코어 수는 8개이므로 8개로 지정했다.
ExecutorService에 작업을 submit하면, 내부에서 해당 작업을 스케쥴링 하면서 적절하게 일을 처리한다. ThreadPool에 있는 스레드들이 각자 본인의 Task를 가지고 작업을 처리하여, 개발자 입장에서는 스레드들의 생명주기를 따로 관리할 필요가 없다.
그래서 위처럼 수정한 코드로 다시 테스트를 진행해보았다.
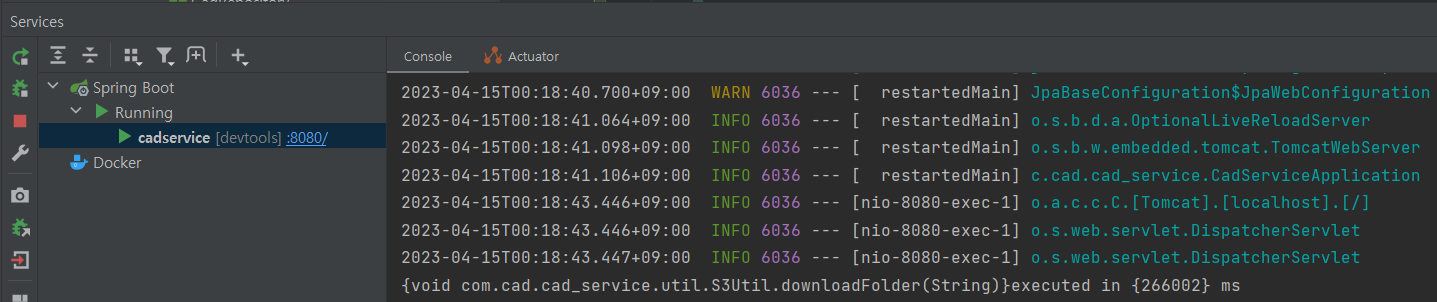
소요 시간: 266.002초
드디어 유의미할 정도로 줄었다..!
이제 하드 코딩된 부분들을 고쳐보자
@MeasureExecutionTime
public void downloadFolder(String project) {
try {
project = URLDecoder.decode(project, StandardCharsets.UTF_8);
ExecutorService executor = Executors.newFixedThreadPool(Runtime.getRuntime().availableProcessors());
ListObjectsV2Result result = s3Client.listObjectsV2(bucket, project);
for (S3ObjectSummary summary: result.getObjectSummaries()) {
GetObjectRequest getObjectRequest = new GetObjectRequest(bucket, summary.getKey());
executor.submit(() -> {
s3Client.getObject(getObjectRequest, new File(summary.getKey()));
});
}
executor.shutdown();
executor.awaitTermination(TIMEOUT, TimeUnit.MINUTES);
} catch (AmazonServiceException e) {
log.error("Amazon service exception: ", e);
} catch (InterruptedException e) {
log.error("awaitTermination exception: ", e);
}
}하드코딩된 부분을 고치니까 이상하게 다운로드 속도가 더 빨라졌다.
소요 시간: 222.496초
여기서는 스레드를 8에서 local 머신의 CPU 코어수를 직접 가져올 수 있게 변경한게 거의 전부다. 왜 갑자기 빨라졌나 했더니
System.out.println(Runtime.getRuntime().availableProcessors()); // 16JVM에서 이용 가능한 CPU 코어수가 16으로 찍힌 것이다. 내 CPU는 8코어 짜리지만 어떻게 이것이 가능한가 헀더니 하나의 코어에서 둘 이상의 스레드를 실행할 수 있게 해주는 Hyper-threading(하이퍼 스레딩) 기술 덕분이라고 한다. 물리적으로 CPU 코어는 8개지만 현재 OS가 논리적으로 코어를 16개로 인식할 수 있게 해주는 기술이다.
리펙토링 후
@Component
@RequiredArgsConstructor
public class S3Util {
private final TransferManager transferManager;
private final AmazonS3Client s3Client;
private static final int TIMEOUT = 5;
@Value("${cloud.aws.s3.bucket}")
public String bucket;
@MeasureExecutionTime
public void downloadFolder(String project) {
try {
project = URLDecoder.decode(project, StandardCharsets.UTF_8);
ExecutorService executor = Executors.newFixedThreadPool(Runtime.getRuntime().availableProcessors());
ListObjectsV2Result result = s3Client.listObjectsV2(bucket, project);
for (S3ObjectSummary summary: result.getObjectSummaries()) {
GetObjectRequest getObjectRequest = new GetObjectRequest(bucket, summary.getKey());
executor.submit(() -> {
s3Client.getObject(getObjectRequest, new File(summary.getKey()));
});
}
executor.shutdown();
executor.awaitTermination(TIMEOUT, TimeUnit.MINUTES);
} catch (AmazonServiceException e) {
log.error("Amazon service exception: ", e);
} catch (InterruptedException e) {
log.error("awaitTermination exception: ", e);
}
}
}끝!
