getElementById, querySelector가 DOM tree를 검색하는 방법
INDEX
querySelector와 getElementById의 내부 알고리즘
호스트 객체와 네이티브 객체
Id를 이용해 Element를 찾는 법
id를 이용해 DOM을 찾고 싶을떄, 어떻게 할나요?
<div id="id"> 텍스트 </div>DOM에 id값이 적용되어 있다면 아래와 같은 방식으로 DOM을 찾는 방식이 일반적일 겁니다.
document.getElementById("id");위와 같은 방식이 아니더라도, querySelector를 사용해 element를 찾는 방식도 있을 겁니다.
많이 사용해봤지만, 내부적으로 어떻게 동작하는지 확실하게 알고 넘어가 봅시다.
여기서는 getElementById의 내부 동작원리에 대해서만 을 다룹니다.
호스트 객체와 네이티브 객체
브라우저 환경(Chrome, Safari, Firefox)에 따라 각자 여러가지 방식으로 구현이 가능하다.
호스트 객체 :
ECMAScript으로 정의된 객체, 전역의 공통 기능을 제공한다.
ex) Object, String, Number, Function, Array, RegExp, Date, Math, Boolean, Error(+기타 에러관련 obj), Symbol(ES6), JSON, Promise, Proxy, Map, Set...
네이티브 객체:
행 환경에서 제공하는 객체(OS, Web browser에 따라 제공 객체 달라짐)
네이티브객체가 아닌 객체는 모두 호스트 객체.
ex) window, XmlHttpRequest, HTMLElement 등의 DOM 노드 객체와 같이 호스트 환경에 정의된 객체.
getElementById는 ECMAScript에 정의되지 않은, window의 하위 객체인, document의 함수임으로 네이티브 객체이다.
DOM tree에서의 Element 찾기
먼저 querySelector가 DOM tree에서 Element를 찾는 방식을 확인해봅시다.
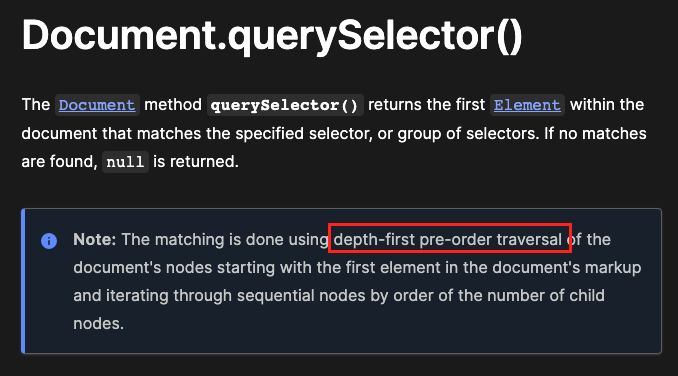
MDN querySelector 문서를 보면 위와 같이 depth-first-pre-order 순회 라는 단어를 통해 DFS알고리즘을 통해 검색을 하는 것을 알 수 있습니다.
그렇다면 getElementById도 마찬가지로 DFS방식을 통해 재귀검색을 할까요?
네 맞습니다. 다만, Id는 검색시 매번 DFS를 통해 Id를 찾는 것이 아닌, hash table을 통해 더 빠르게 데이터를 가져올 수 있습니다.
아래는 WebKit의 getElementById의 구현입니다.
먼저 hash table에서 값을 가져오고 없다면 DFS알고리즘을 통해 다시 한번 찾는 로직을 확인 할 수 있습니다.
Element* Document::getElementById(const AtomicString& elementId) const
{
if (elementId.isEmpty())
return 0;
m_elementsById.checkConsistency();
Element* element = m_elementsById.get(elementId.impl());// hastable 검색
if (element)
return element;
// DFS 검색
if (m_duplicateIds.contains(elementId.impl())) {
// We know there's at least one node with this id,
// but we don't know what the first one is.
for (Node *n = traverseNextNode(); n != 0; n = n->traverseNextNode()) {
if (n->isElementNode()) {
element = static_cast<Element*>(n);
if (element->hasID() &&
element->getAttribute(element->idAttributeName()) == elementId) {
m_duplicateIds.remove(elementId.impl());
m_elementsById.set(elementId.impl(), element);
return element;
}
}
}
ASSERT_NOT_REACHED();
}
return 0;
}
아래는 Firefox의 getElementById의 구현입니다.
FireFox의 GetElementByIdInternal내부 구현에서도 마찬가지로 hash table lookup을 통해 검색 하는 코드를 확인 할 수 있습니다.
nsDocument::GetElementById(
const nsAString& aElementId,
nsIDOMElement** aReturn
) {
NS_ENSURE_ARG_POINTER(aReturn);
*aReturn = nsnull;
nsCOMPtr<nsIAtom> idAtom(do_GetAtom(aElementId));
NS_ENSURE_TRUE(idAtom, NS_ERROR_OUT_OF_MEMORY);
if (!CheckGetElementByIdArg(idAtom))
return NS_OK;
nsIdentifierMapEntry *entry = GetElementByIdInternal(idAtom);
NS_ENSURE_TRUE(entry, NS_ERROR_OUT_OF_MEMORY);
nsIContent *e = entry->GetIdContent();
if (!e)
return NS_OK;
return CallQueryInterface(e, aReturn);
}
nsDocument::GetElementByIdInternal(nsIAtom* aID)
{
// We don't have to flush before we do the initial hashtable lookup, since if
// the id is already in the hashtable it couldn't have been removed without
// us being notified (all removals notify immediately, as far as I can tell).
// So do the lookup first.
nsIdentifierMapEntry *entry = mIdentifierMap.PutEntry(aID);
NS_ENSURE_TRUE(entry, nsnull);
if (entry->GetIdContent())
return entry;
// Now we have to flush. It could be that we know nothing about this ID yet
// but more content has been added to the document since. Note that we have
// to flush notifications, so that the entry will get updated properly.
// Make sure to stash away the current generation so we can check whether
// the table changes when we flush.
PRUint32 generation = mIdentifierMap.GetGeneration();
FlushPendingNotifications(Flush_ContentAndNotify);
if (generation != mIdentifierMap.GetGeneration()) {
// Table changed, so the entry pointer is no longer valid; look up the
// entry again, adding if necessary (the adding may be necessary in case
// the flush actually deleted entries).
entry = mIdentifierMap.PutEntry(aID);
}
return entry;
+
−}결론
이러한 이유때문에, querySelector보다 getElementById를 통한 검색이 보다 빠른 것을 확인 할 수 있습니다.
또한 동일한 ID 를 가진 두 개 이상의 요소가 있는 경우 첫 번째 요소 를 getElementById()반환하는 이유를 DFS알고리즘에 의한 원리라는 것을 확인 할 수 있다.

좋은 글 감사합니다! 다만 호스트 객체와 네이티브 객체 설명이 서로 바뀐 것 같습니다! ㅎㅎㅎ