ML, DL, AI 아무것도 모르는 지금, 당장 해야할 건 공부뿐이라는 말에 정말 열심히 공부해보기로 했다.
그래서 우선 coursera의 설립자인 Andrew Ng 선생님의 ML 강의를 듣기로 했다.
처음 공부하기엔 어렵다곤 하는데 열심히 해야지..
수료율 5프로 이하라곤 하지만 그 5프로 안에 들어봐야지..
앤드류 선생님 힘을 주세요 ㅎㅎ..
급하게 할 건 아니고 마지막 4-2 학기에 수업 들으면서 추가 전공 듣는 느낌으로 해보려 한다. 2-3개월정도?
이 정리노트는 수강하면서 생각나는거, 알아낸 거 막 적을거라 사실상 정리 노트보단 메모장 느낌이다.
아 그리고 전공에서 수학을 거의 안 배워서.. 수학과에서 열리는 선형대수랑 통계도 청강 신청해보려 한다.
이제서야 진짜 대학 공부를 하는 느낌 ㅋㅋ;
What is machine learning?
Arthur Samuel은 머신러닝에 대해 완전히 프로그래밍 되지 않은 채로 컴퓨터가 배울 수 있게 하는 학문이라고 하였다.
이 말을 듣고 처음엔 뭐 맞는 말이지 하고 말았는데, Samuel은 체스 AI를 만들었고, 실제로 Samuel은 체스를 잘하지 못한다는 얘기에 아! 하는 기분이 들었다.
체스 AI는 수백번, 수천번의 게임을 하면서 성능을 향상 시키는데, 만약에 딱 10번만 게임하게 한다면?
당연히 학습 횟수가 적으니 더 나빠질 것이라 생각했다. 당연하게도^^ 정답이었다.
Machine learning algorithms
-
Supervised learning (course 1, 2)
지도 학습으로, 대부분의 실제 애플리케이션에서 사용되며 빠른 향상을 보여준다. -
Unsupervised learning (course 3)
Supervised learning part 1
주어진 "정답"으로 배우는 것
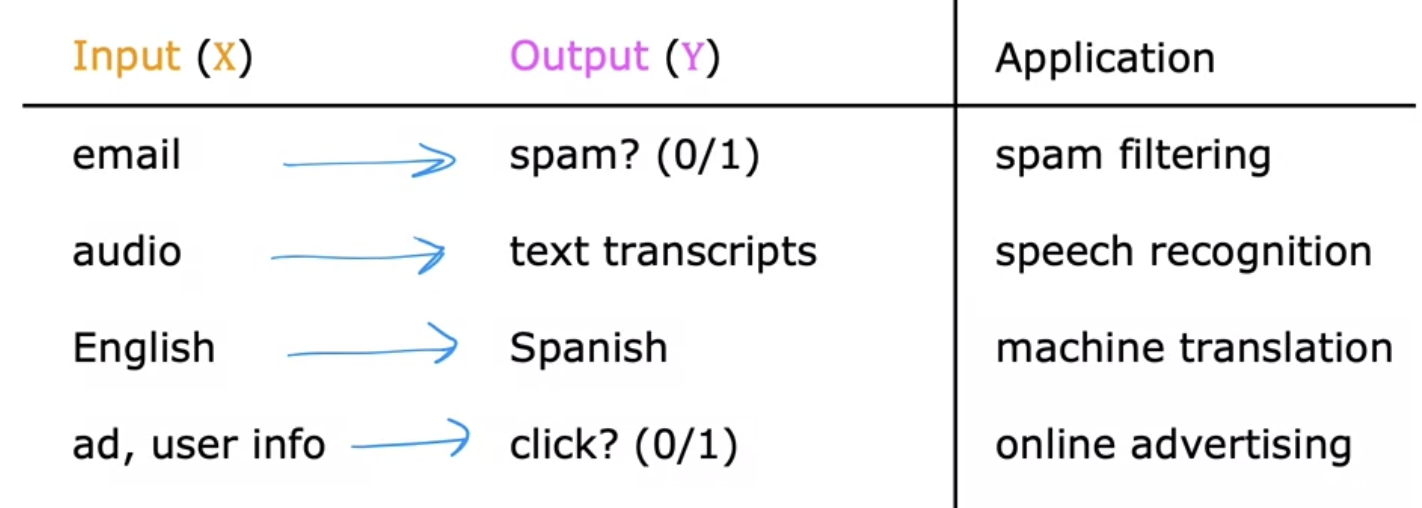
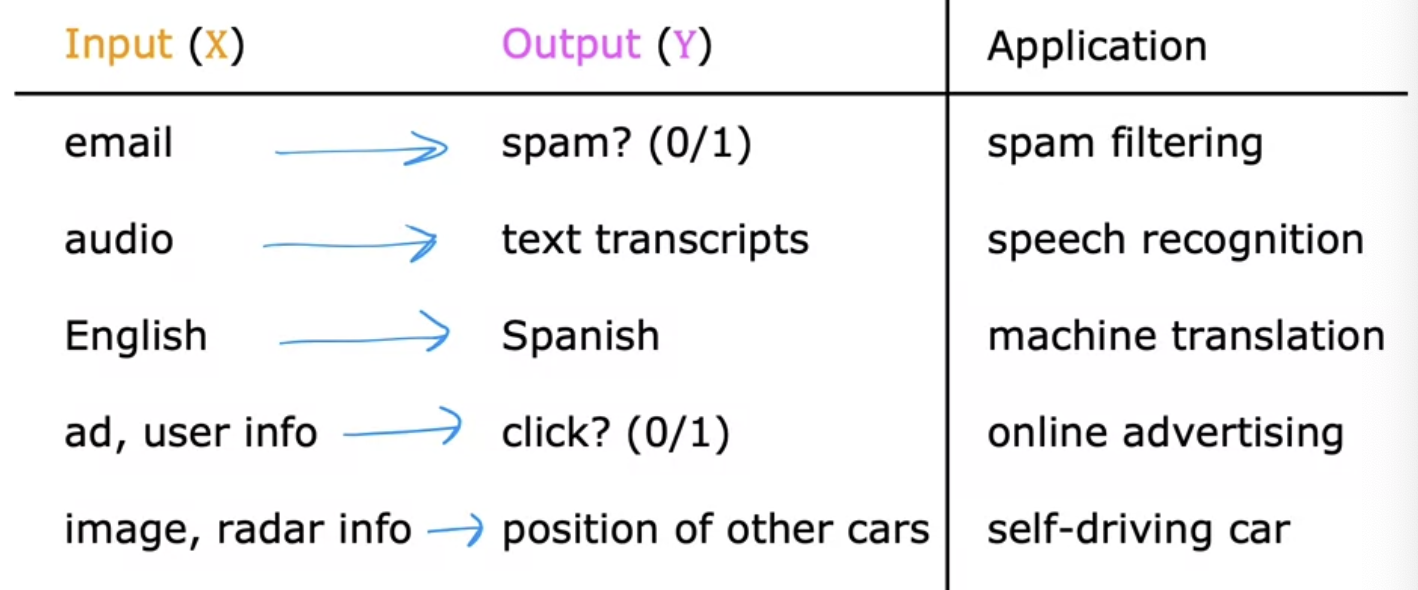
Input(X)로부터 Output(Y)를 매핑하여 도출해낸다.
STT, Translator 같은 ML 기술들을 위의 식으로 정리주면 아래와 같다.
집값을 예측한다고 하자.
다들 그렇듯이 평수(면적)에 대해 값을 메길 수 있을 거다.
친구의 집이 35평일 때 집을 얼마에 팔아야 할까? 3억? 5억? 4억 3천?
이런 문제를 회귀(regression)이라고 한다.
어느 한 숫자를 예측하고, 가능한 결과가 무한정 많은 문제이다.
Supervised learning part 2
두번째 지도 학습으로 classification(분류)를 알아보자.
Breast cancer detection의 예시에서, tumor(종양)에 대해 malignant(악성)와 benign(양성)의 분류를 할 수 있을 것이다.
tumor의 크기와 그 tumor가 malignant인지, benign인지에 대한 데이터가 있다.
새로운 환자의 tumor 크기를 알고 있을 때, 결과를 어떻게 분류할 수 있을까?
regression이랑 다른점은 뭘까?
classification은 categories(classes)를 예측하는 것이다.
그리고 가능한 결과가 객관식 문제처럼 적은 개수로 이루어져있을 것이다.
입력이 하나가 아닌 두 개라면? tumor의 크기뿐만 아니라 age까지 고려한다면?
새로운 환자에 대해 결과를 어떻게 분류할 수 있을까?
알고리즘을 배우는 것은 이런 문제에 대해 maliganat와 benign을 구별하는 바운더리를 찾는 것이다.
이 바운더리로 의사는 환자들에 대해 진단할 수 있을 것이다.
Unsupervised learning part 1
supervised learning이 정답으로 레이블된 데이터를 학습하는 거라면,
unsupervised learning은 레이블되지 않은 데이터에서 패턴이나 interesting한 무언가를 찾는 것이다.
비지도 학습에서 clustering 알고리즘이라는 한 타입이 있다.
구글 뉴스는 하루에도 몇 백, 몇 천 개의 기사들에 대해 clustering을 한다.
일반적으로 기사를 grouping 한다고 하면, 기사에 공통적으로 사용된 단어들을 찾고 그것들을 한 group으로 묶을 수 있을 것이다.
하지만 앞서 말했듯이 하루에도 어마어마하게 많은 수의 뉴스가 도보되고, 그걸 매일 하나하나 사람이 토픽별로 묶는 짓을 할 순 없다.
이를 대신해 알고리즘이 지도 없이 스스로가 오늘 기사의 clusters는 무엇인지 알아내야한다.
또다른 clustering의 예시로 DNA microarray(DNA 판)을 알아보자.
X가 각각의 다양한 사람들이고, Y가 유전자 특성(시력, 키, 취향) 등이라고 할 때, 유전자 특성이 유사한 사람들의 그룹들을 type 1, 2, 3, ...이라고 할 수 있을 것이다.
정답을 주지 않았기에 이것이 unsupervised learning이다.
각 type들의 사람들이 정확히 어떤 차이가 있는지는 모르지만 개인의 주요 type이 무엇인지 알아내고 어떤 패턴이 있는지를 알아낼 수 있다.
세번째 예시로 Grouping customers이다.
전체 고객에 대해 다른 마케팅 세그먼트로 나누면, 더 효과적으로 마케팅 할 수 있을 것이다.
unsupervised learning은 데이터를 레이블 없이 받아서, 자동으로 cluster로 그루핑하려는 것이다.
Unsupervised learning part 2
clustering 말고 다른 unsupervised learning은 뭐가 있을까?
데이터는 input으로 X가 오지만, output은 Y가 아니다. 알고리즘이 데이터 속의 구조를 찾아야한다.
알고리즘을 간단히 적어보고 가자면
clustering은 유사한 데이터 포인트들을 함께 group으로 묶는 것이고
anomaly detection은 평범하지 않은 데이터 포인트를 찾는 것이며
dimensionality reduction은 데이터를 더 적은 수로 압축하는 것이다.
2개의 unsupervised learning을 찾는 문제가 나왔다.
1. 뉴스 기사 데이터 셋으로부터 같은 내용의 기사를 group 짓는 것
2. 스팸인지 아닌지 레이블된 이메일로부터 스팸 필터를 배우는 것
3. 고객 데이터로부터 자동으로 market segments를 찾아내고 고객을 group 짓는 것
4. 이미 진단 받은 환자 데이터 셋으로부터 새로운 환자가 당뇨를 가지고 있는지 분류하는 것
이미 위에서 예시로 명시됐던 것들이기에 쉽게 정답을 맞출 수 있었다.
