확성화 함수로 주로 하이퍼볼릭 탄젠트 사용
:RNN 내에서 vanishing gradient 문제를 예방(gradient가 최대한 오래 유지되도록)
tanh의 미분 최댓값이 큼
그라디언트 폭주 문제: 그라디언트 클리핑 사용
그라디언트 소실 문제: LSTM
LSTM
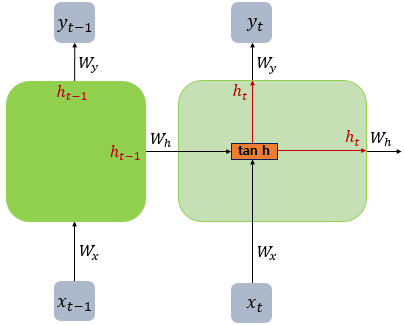
바닐라 RNN
LSTM
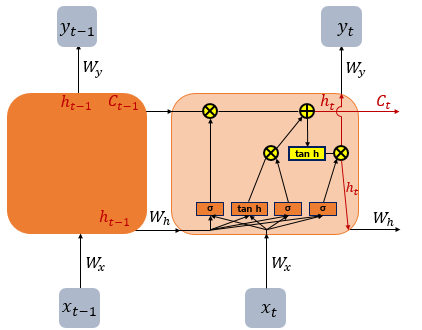

불필요한 것 삭제, 필요한 것 기억
셀 상태 Ct는 전체 input에 대해서 기억
h{t-1}은 이전 input과의 거리가 가까울수록 정보량이 많음
따라서 얼마나 기억하고 삭제할지 결정하는 과정
input gate의 tanh는 cell state의 역할, sigmoid는 gate(input gate)의 역할
입력값 이전의 문장을 기억
- Input/Forget/Output gate
GRU


단어 임베딩
- word2Vec
- 학습 방법 1: CBoW(주변 단어로 중심 단어 예측)
- 학습 방법 2: Skip-Gram(주변 단어로 중심 단어 예측)

Attention
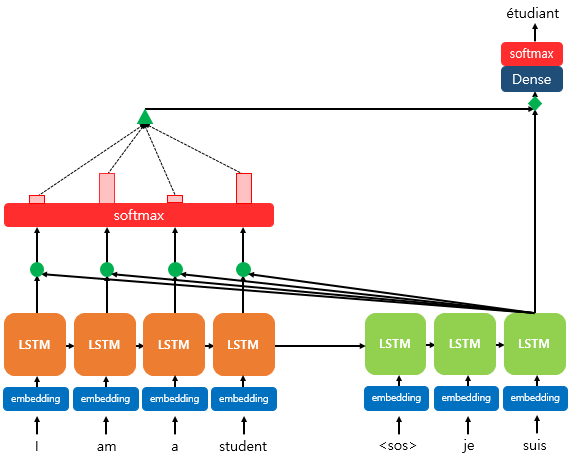
(seq2seq의 dot product attention)
기존 RNN에 기반한 seq to seq의 정보 손실(하나의 고정된 크기의 벡터에 모든 정보를 압축하므로) 및 기울기 손실을 예방하기 위해 고안된 방법
idea: 매 시점마다 인코더에서의 전체 입력 문장을 다시 한 번 참고하되, 예측할 단어와 연관있는 입력단어 부분에 더 집중하자
attention module
- HAN(hierarchical Attention Network)
- Squeeze Excitation Networks
어떤 channel이 더 중요한지 squeeze후에 excitation을 하고 해당 vector와 input을 연산하여 attention (channel attention)
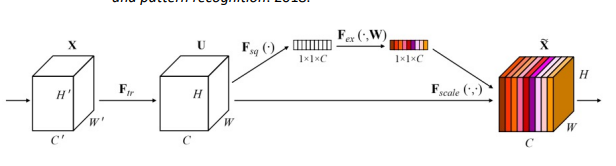
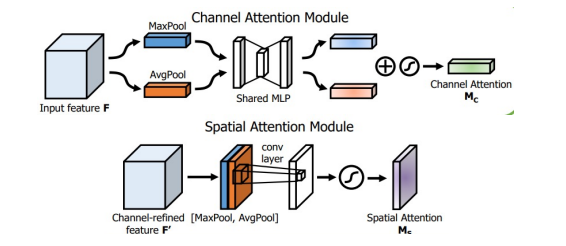
- CBAM(Convolutional Block Attention Module)
spatial attention과 chennel attention을 모두 시행
channel attention을 할 때는 Max Pooling과 Avg Pooling을 모두 사용
- end to end
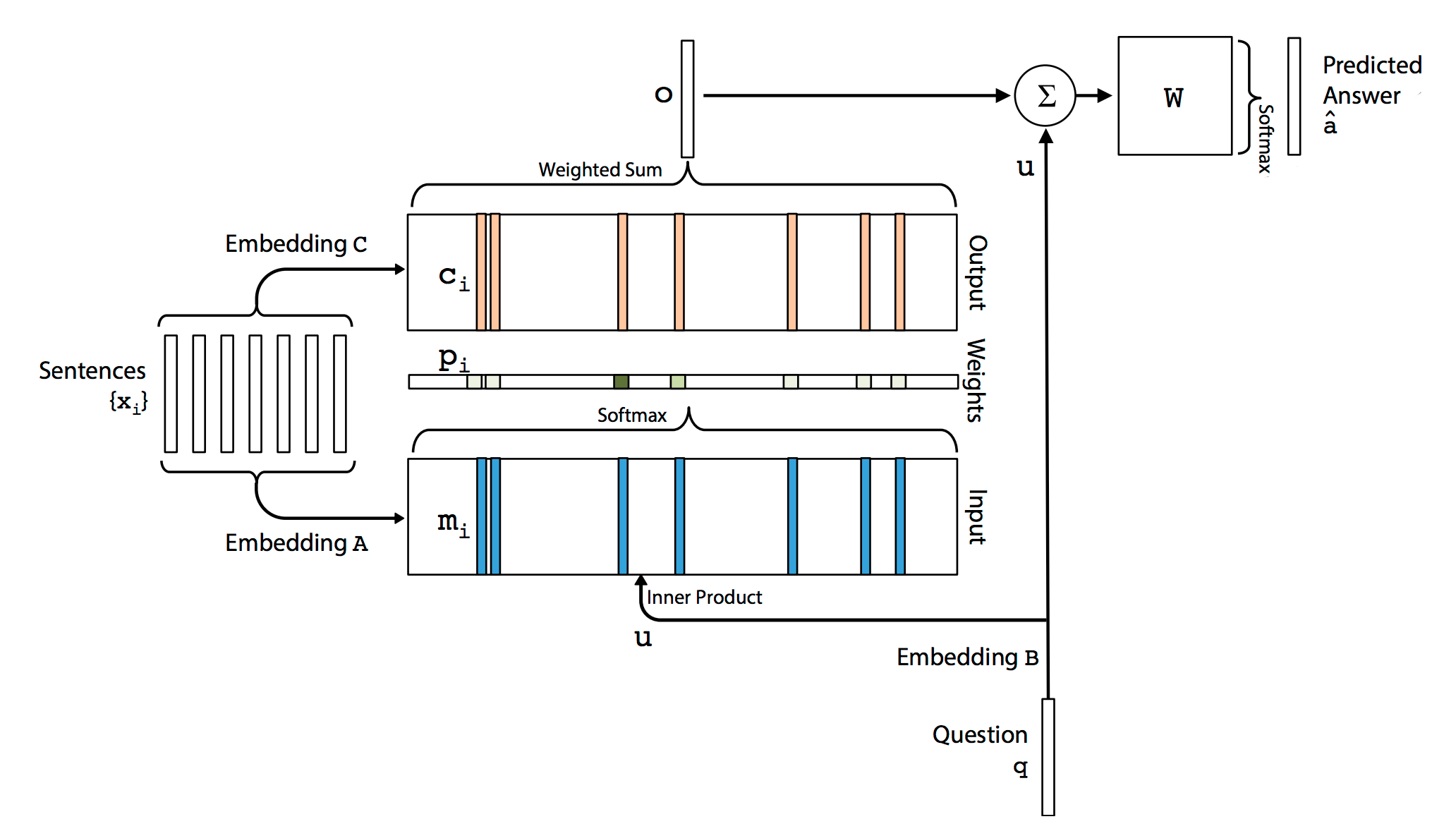
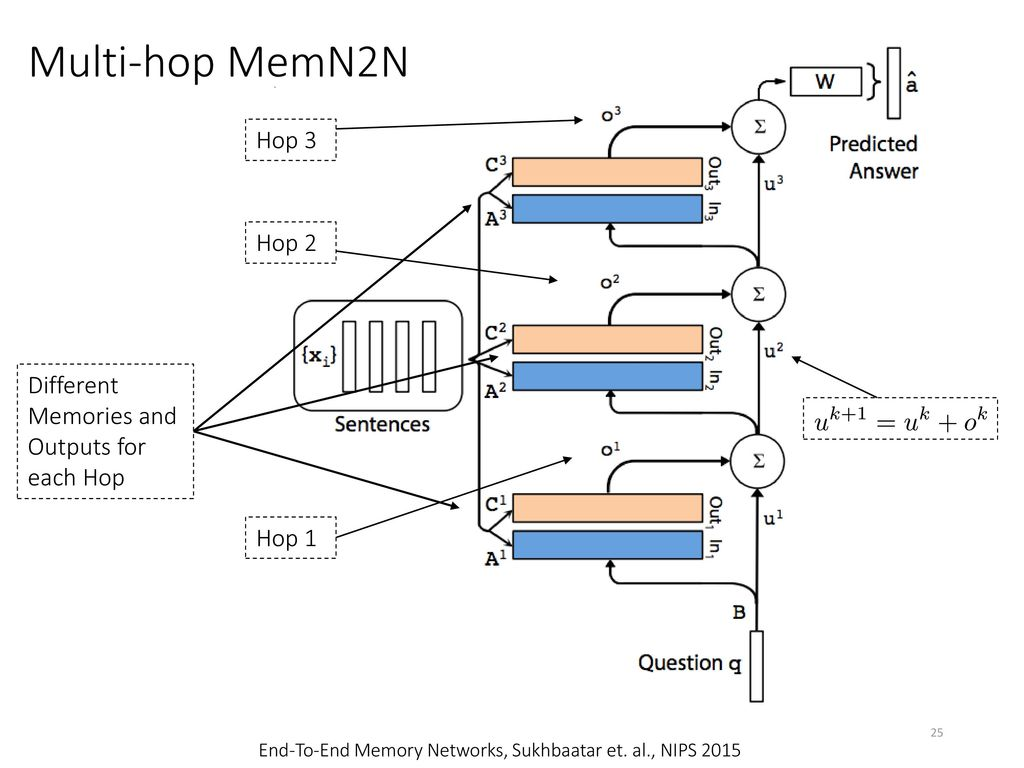
파라미터들은 smooth하므로 역전파가 가능하다

multi-head attention
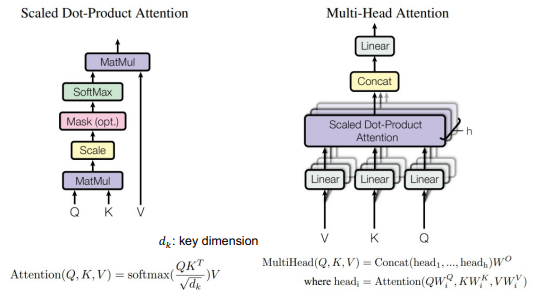
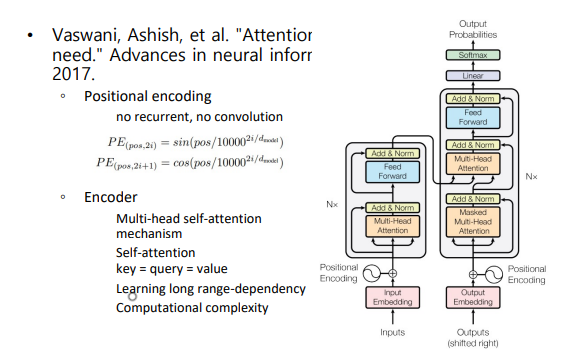
한번에 병렬처리하므로 순서정보를 따로 지정(positional encoding)
병렬처리하는 이유는 정보를 다양하게 포함하기 위해(문장 종류에 치중, 단어에 치중 등등)
self-attention(K=Q=V): 한 문장 내에서 단어간 관계를 이용해 의미 파악
decoder 첫번째 층에서는 mask 사용(문장을 입력받으므로 이어 오는 단어의 예측이 가능하므로)
두번째 층에서 Q와 K는 encoder output 사용하므로 self-attention이 아님
https://kangbk0120.github.io/articles/2018-03/end-to-end-memorynet
https://www.blossominkyung.com/deeplearning/transformer-mha
