[NIPS 2021] SegFormer: Simple and efficient design for semantic segmentation with transformers
Paper Review
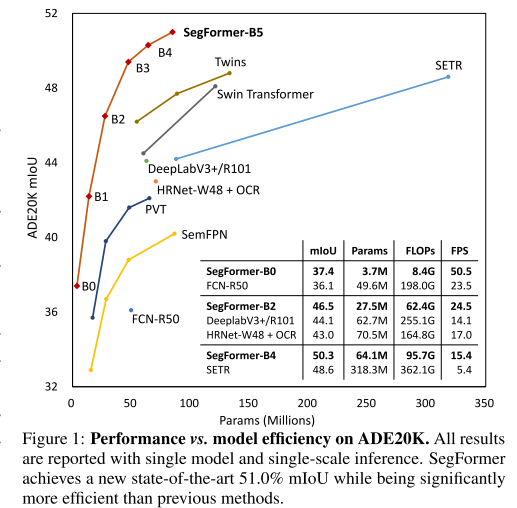
Novelty
- positional-encoding-free and hierarchical Transformer encoder (multi-scale feature를 추출한다)
- A lightweight All-MLP decoder design (decoder가 복잡할 필요가 없다)
고정된 사이즈로 positional encoding을 하는 Transformer는 훈련에 사용한 이미지보다 더 큰 사이즈의 이미지로 테스트하면 성능저하가 일어남
ViT (arXiv 2020)를 backbone으로 사용하여 semantic segmentation에서 좋은 성능을 보인 SETR (CVPR 2020)이 있지만, single-scale feature를 사용하고 larger size에서 high computational cost 요구한다는 한계가 있음
3. Method
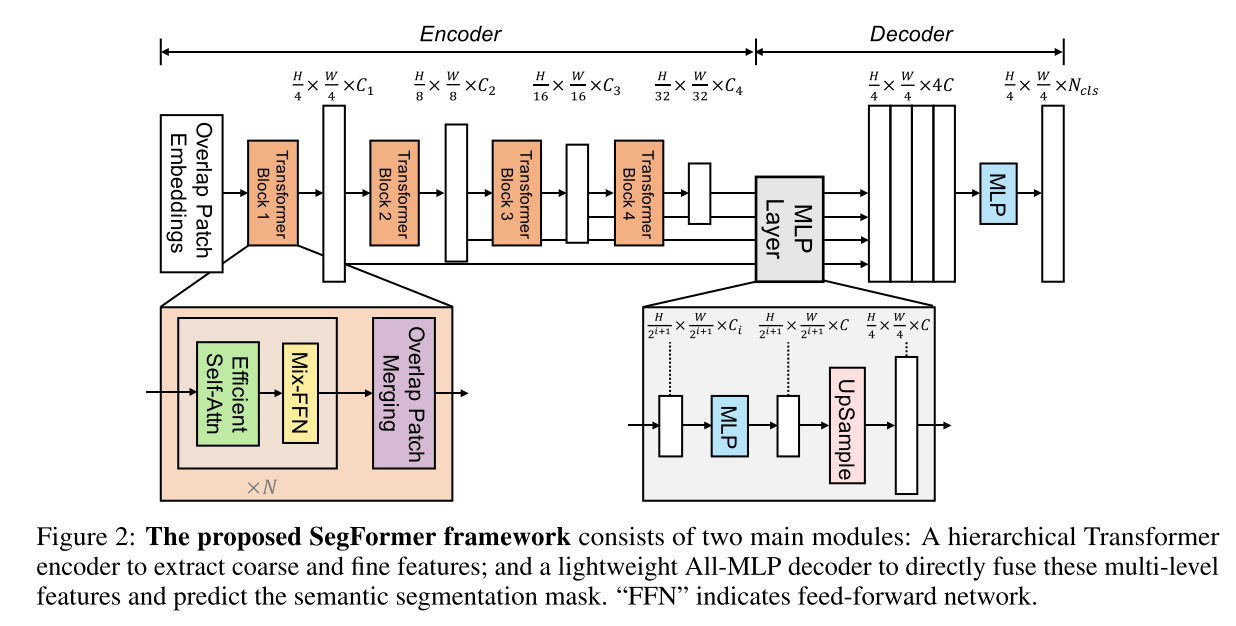
3.1. Hierarchical Transformer Encoder
Hierarchical Feature Representation
single-resolution feature map을 생성하는 ViT와 달리, high-resolution coarse feature와 low-resolution fine-grained feature
- 입력:
- i-th block feature map (1 ~ 4):
Overlapped Patch Merging
- -> vector
- hierarchical feature maps을 얻기 위해 그것은 feature -> feature로 통일하는 것으로 확장될 수 있음
- -> 로 shrink하면서 반복함
- 이건 사실 non-overlapping하게 되어있는데, 그러면 local continuity를 보존하는 데에 실패한다
- non-overlapping process와 같은 사이즈의 feature를 제공하는 overlapping patch merging process를 하기 위해 and 설정
- K: patch size, S: stride btw two adjacent patches, P: padding size
Efficient Self-Attention
encoder의 main computation bottleneck은 self-attention layer
original multi-head self-attention (MSA) process에서는 Q, K, V가 모두 동일한 사이즈 N x C = H x W x C를 갖도록 하는데, 수식은 다음과 같음
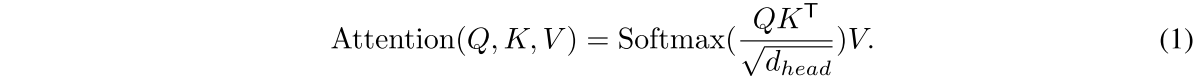
이는 의 복잡도를 가지는데, resolution이 커지면 제곱으로 커진다는 소리다.
대신에 여기선 sequence reduction process를 사용한다. reduction ratio R은 sequence의 길이를 줄이기 위해 사용된다.
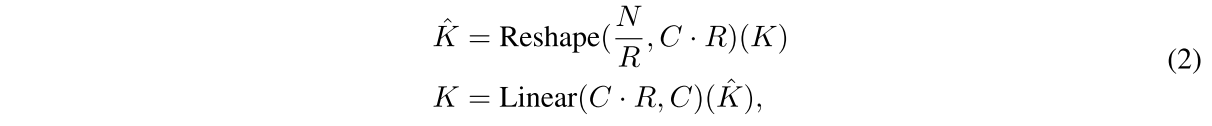
K를 (N/R, CxR)로 reshape하고 Linear layer로 CxR에서 C로 만들어줘서 새로운 K는 N/R, C의 dimension을 갖게 된다. 결과적으로 로 계산 복잡도를 낮춘다.
stage별로 [64, 16, 4, 1]의 reduction ratio를 사용한다
Mix-FFN
ViT는 location 정보를 positional encoding으로 가져오는데, PE의 크기가 고정되어있다보니 훈련보다 더 큰 사이즈의 이미지를 넣을 때 interpolation해주어야하고 이는 정확도를 drop시킨다.
이런 현상을 완화하기 위해, CPVT (arXiv 2021)는 3x3 Conv를 PE에 사용하여 data-driven PE를 구현하였다.
semantic segmentation에서는 positional encoding이 필요하지 않다고 저자는 주장하며 feed-forward network (FFN)에 3x3 Conv를 직접 사용해 정보 누출에 미치는 zero padding 효과를 고려한 Mix-FFN을 소개한다.
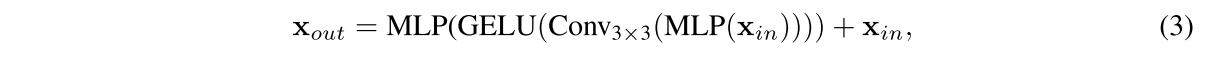
은 self-attention module로부터 온 feature고 Mix-FFN은 3x3 conv와 각 FFN에 들어가는 MLP를 Mix한다. 좀 더 efficient하게 하기 위해 depthwise conv를 사용함
3.2. Lightweight All-MLP decoder
traditional CNN encoder에 비해서 Effective receptive field (ERF)가 더 넓은 hierarchical Transformer encoder가 MLP 형태의 simple decoder를 가능하게 함
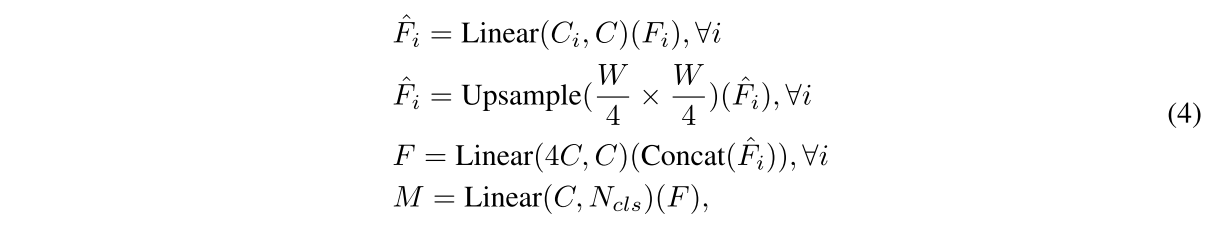
- multi-level features 가 들어오면 Linear layer를 거쳐 C로 dimension을 통일
- H/4 x W/4 크기로 upsample하고 concat (#, 4C, N)
- Linear layer 거쳐서 (#, C, N) -> (#, 2, N)
Effective Receptive Field Analysis
semantic segmentation에서 contextual information을 포함하는 large receptive field를 유지하는 데에 있어서 central issue가 있어옴

특히 decoder는 non-local attention의 장점과 더불어, highly local, non-local attention 둘 다 제공하는 Transformer 기반 feature를 사용하고 있음. 이를 통합함으로써 MLP 디코더는 몇 가지 매개변수를 추가하여 보완적이고 강력한 표현을 렌더링함.
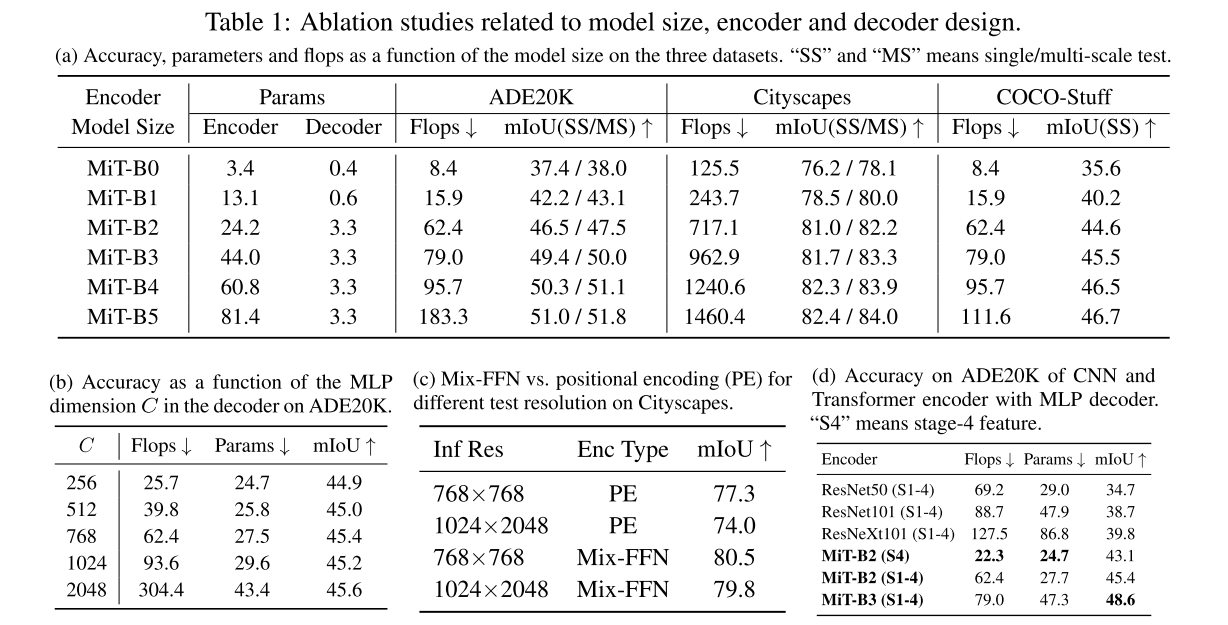
stage-4의 non-local attention만 가져오는 것은 좋은 결과를 내는 데에 부족하다. Table 1d 참고
3.3 Relationship to SETR
- SETR ImageNEt-22K 사전훈련, SegFormer ImageNet-1K 사전훈련
- SETR ViT backbone으로 only single low-resolution feature map 생성, SegFormer ViT보다도 작으면서 high-resolution coarse, low-resolution fine feature 모두를 capture하는 hierarchical arch를 encoder로 사용
- SegFormer는 이미지 사이즈 커지면 성능 저하 생기는 Positional Embedding 안 씀.
- SegFormer 훨씬 compact하고 계산량을 덜 요구하는 MLP decoder 사용, SETR은 여러 개의 3 x3 conv 사용하는 heavy decoder 요구
4. Experiments
Implemenatation details
'mmsegmentation' codebase를 사용해서 8 Tesla V100으로 훈련함
https://github.com/NVlabs/SegFormer/tree/master/mmseg
augmentation
- random resize with ratio 0.5-2.0
- random horizontal flipping
- random cropping to 512 x 512, 1024 x 1024, 512 x 512 for ADE20K, Cityscapes, and COCO-Stuff, respectively
optim
- AdamW (160k iterations on ADE20K, Cityscapes, 80K iter on COCO-Stuff)
- learning rate 0.00006, poly LR schedule with factor 1.0 by default
- not adopt widely-used tricks OHEM, auxiliary losses or class balance loss
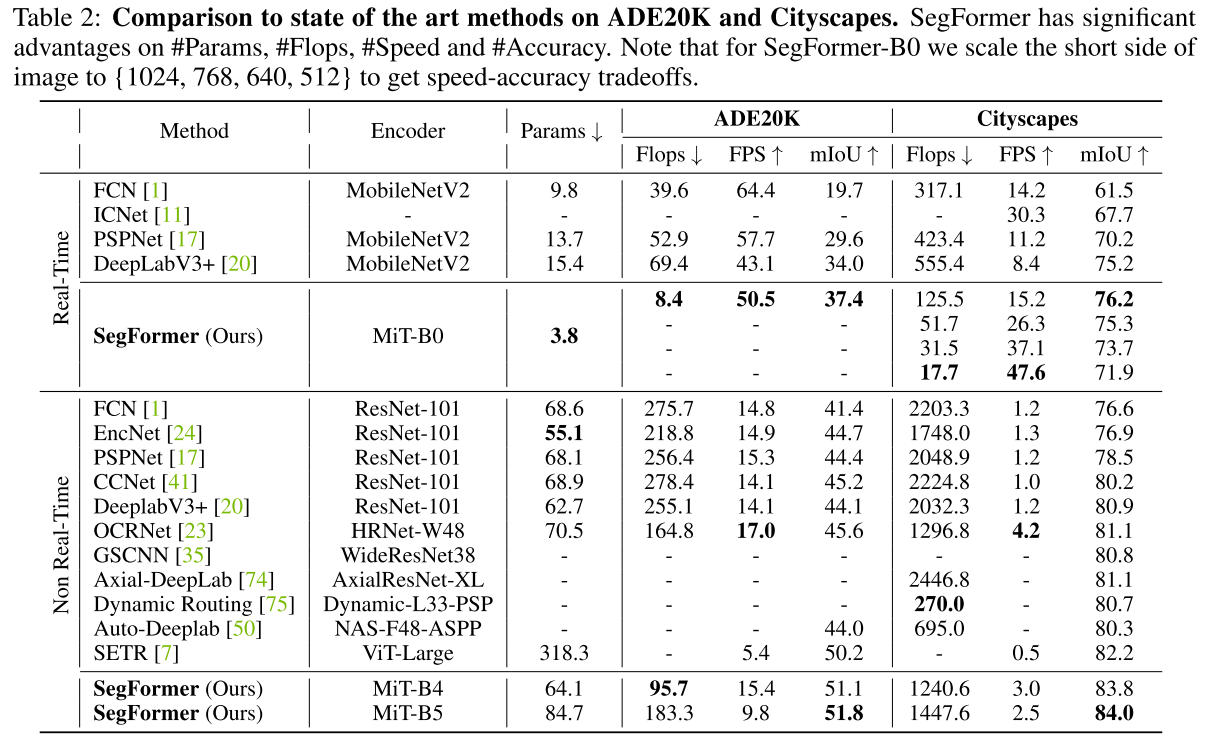
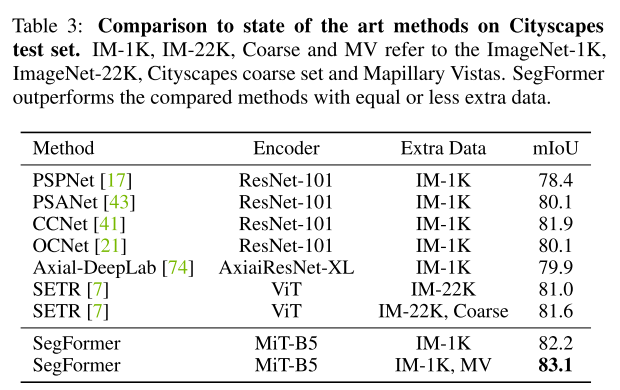
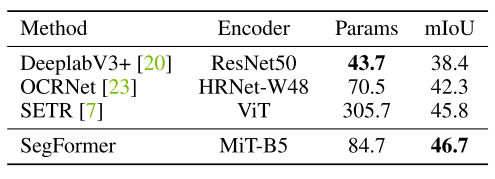
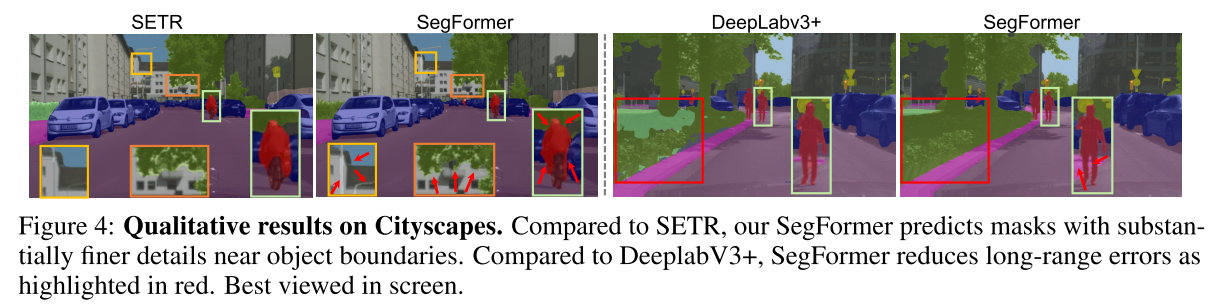
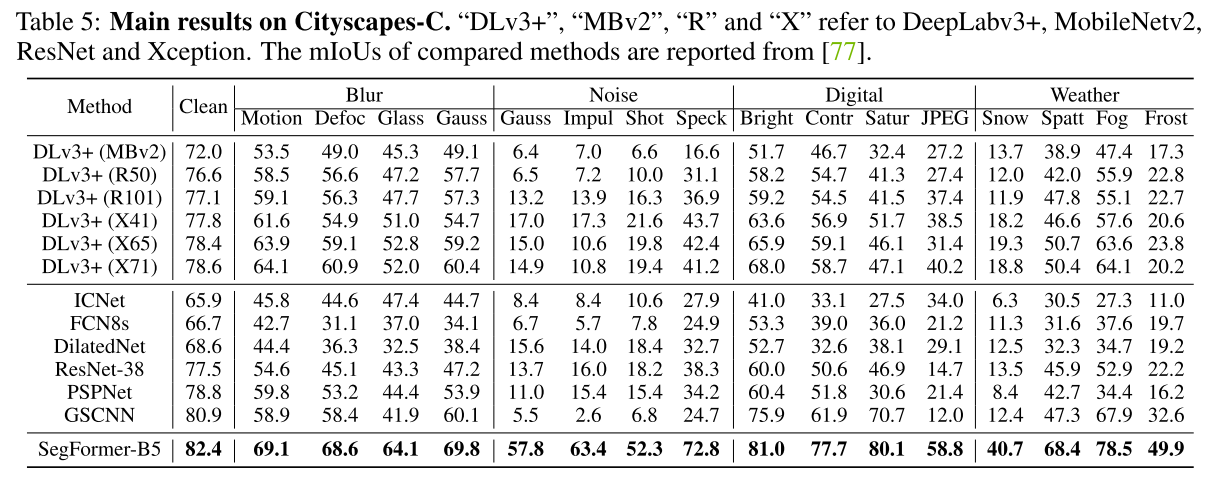
5. Appendix
A Details of MiT Series

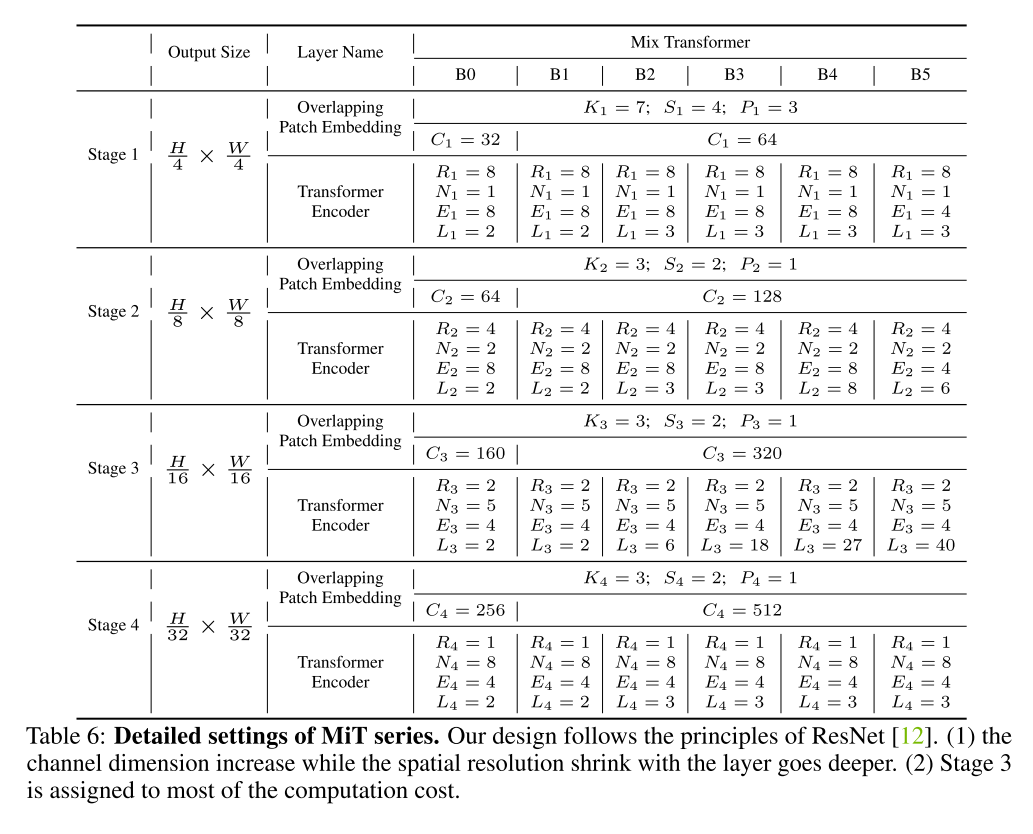
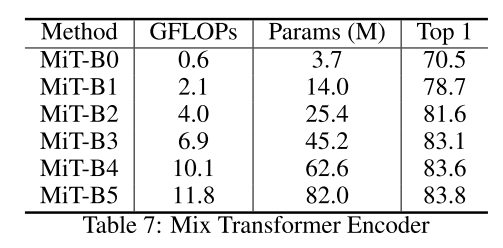
256 x 256, ImageNet-1K에 대한 performance인가..? 입력 사이즈가 명시되어있지 않은 건 아쉽..
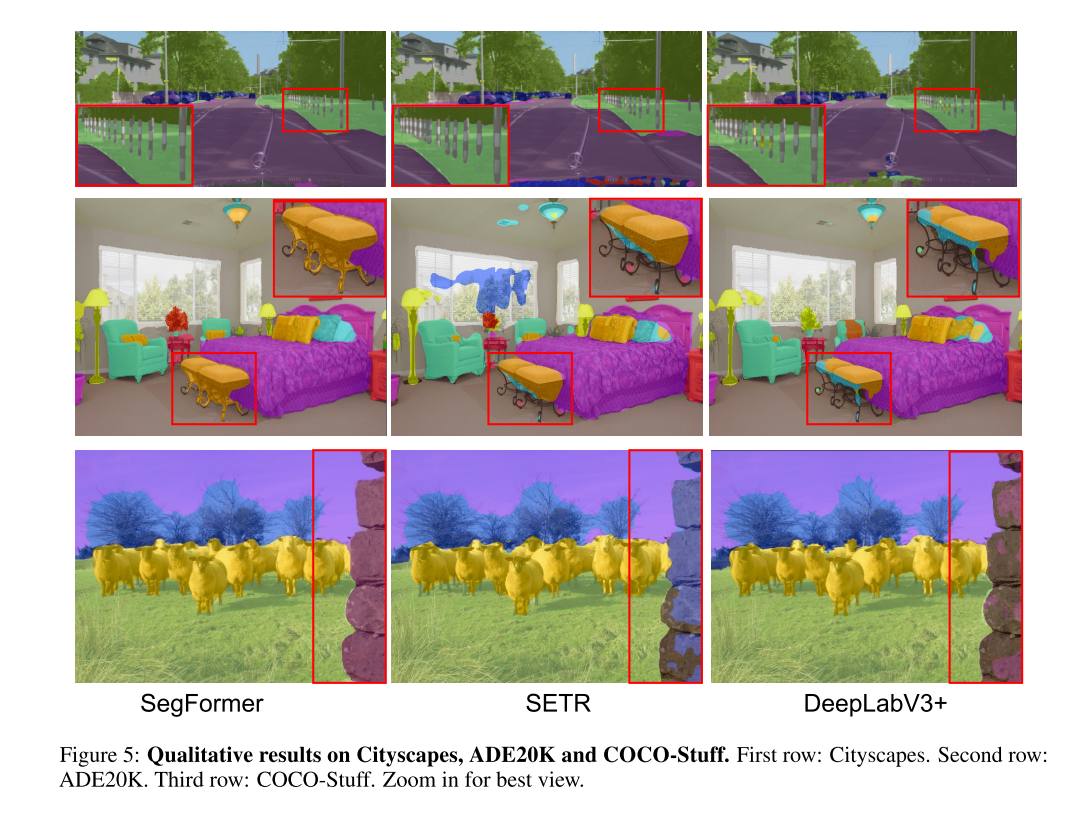
B More Qualitative Results on Mask Predictions
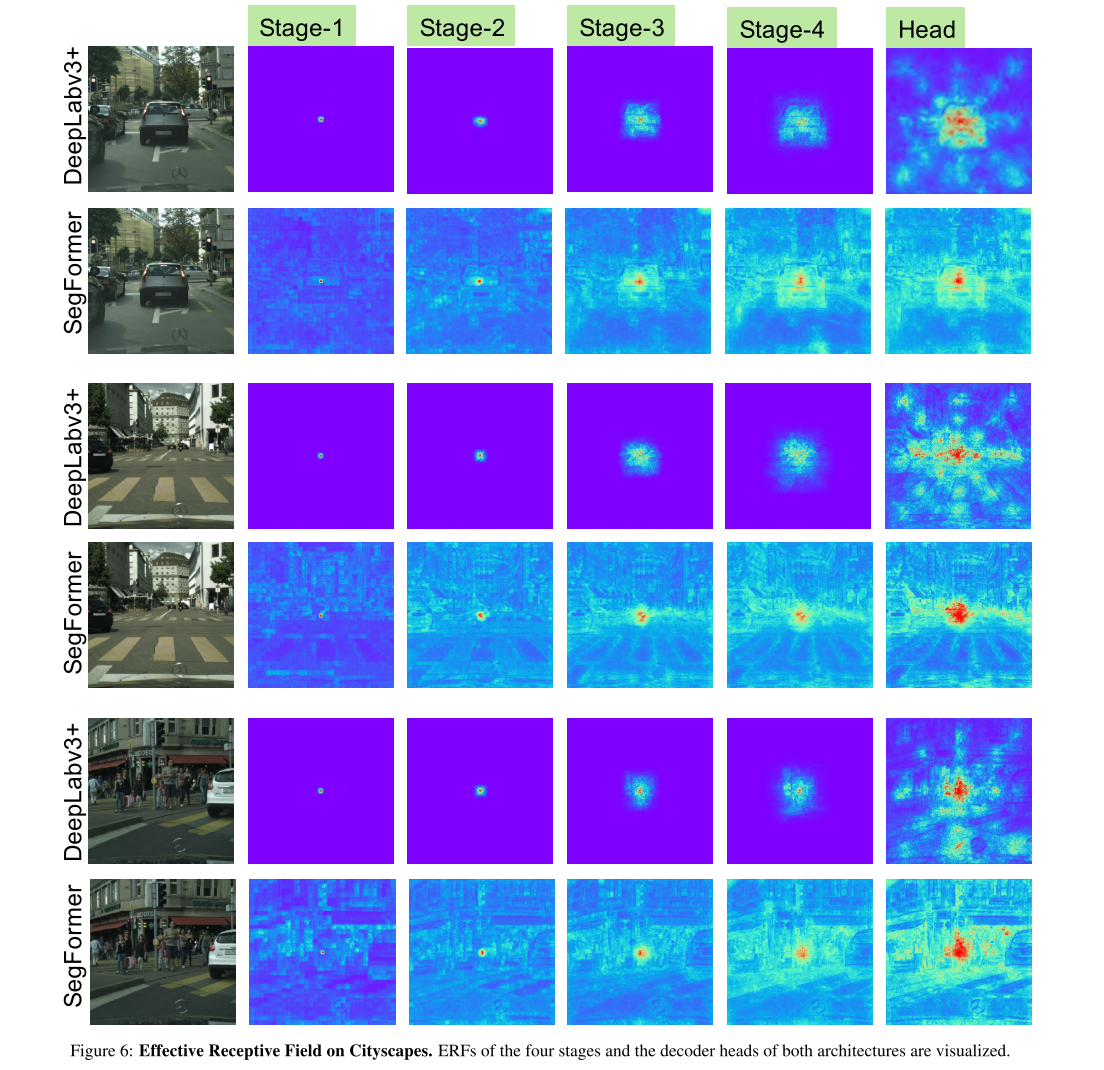
C More Visualization on Effective Receptive Field
SegFormer의 ERF는 image의 context에 더 민감한데, roads, cars, buildings에 대한 pattern을 배움. DeepLabV3+의 ERF는 상대적으로 fixed pattern만 배운다
D More Comparison of DeeplabV3+ and SegFormer on Cityscapes-C
4개의 Noise (3 severities), 12개의 corruption and perturbation (3 severities)
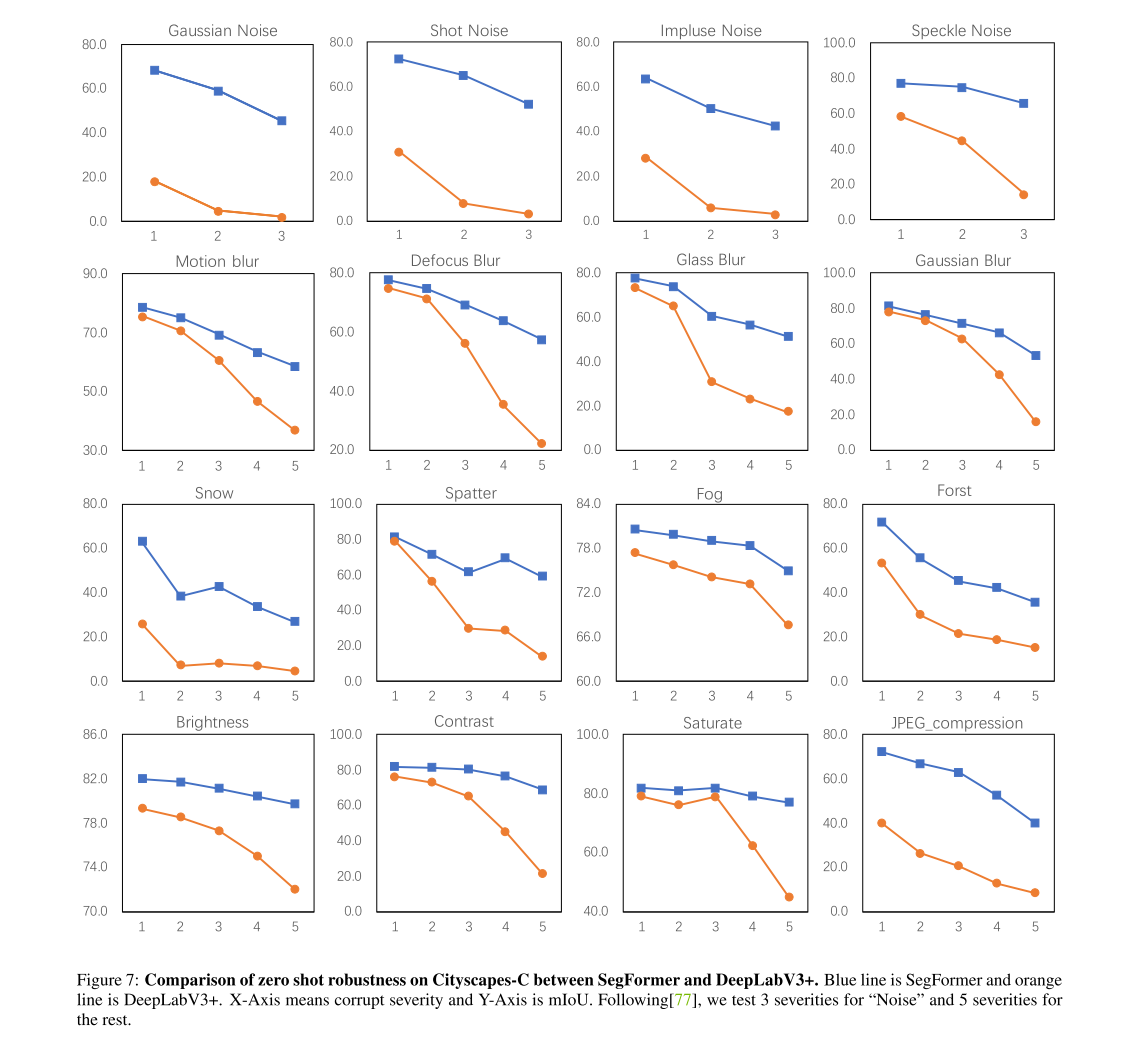
특히나 Brightness Contrast Saturate에 강건한 것으로 보임
