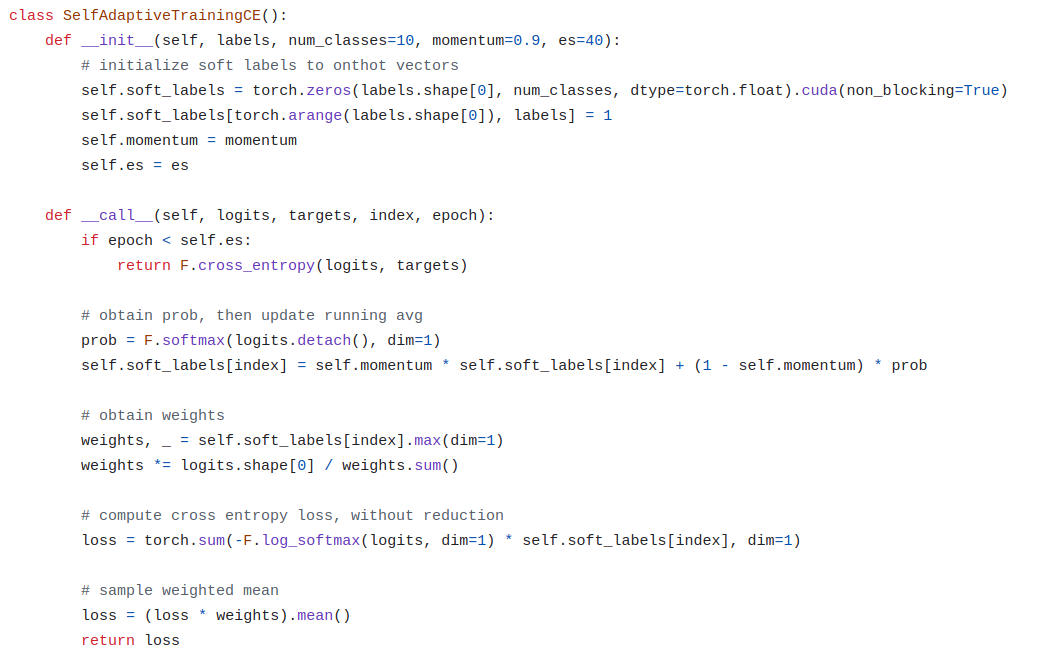
Empricial Risk Minimization (ERM)은 훈련데이터에 쉽게 과적합되는 문제를 지니는데, 훈련데이터의 40%에 서로 다른 네 가지 종류의 noise를 첨가시켰음에도 불구하고 Figure 1a.에 보듯이 ERM으로 훈련시킨 모델은 noisy 훈련셋 (빨간색 dashed line)에 과적합되는 것을 확인할 수 있고 그 종류에 따라 서로 다른 noisy한 훈련셋의 정확도 커브로 구별할 수 없는 generalization 양상을 보인다.
- Corrupted labels. 레이블들을 균일하게 random으로 할당.
- Gaussian. 원래 이미지의 평균과 표준편차와 동일한 Random Gaussian sample로 대체.
- Random pixels. independent random permutations을 사용해 각 이미지의 픽셀을 섞음.
- Shuffled pixels. 고정된 permutation pattern을 사용해 각 이미지의 픽셀을 섞음.
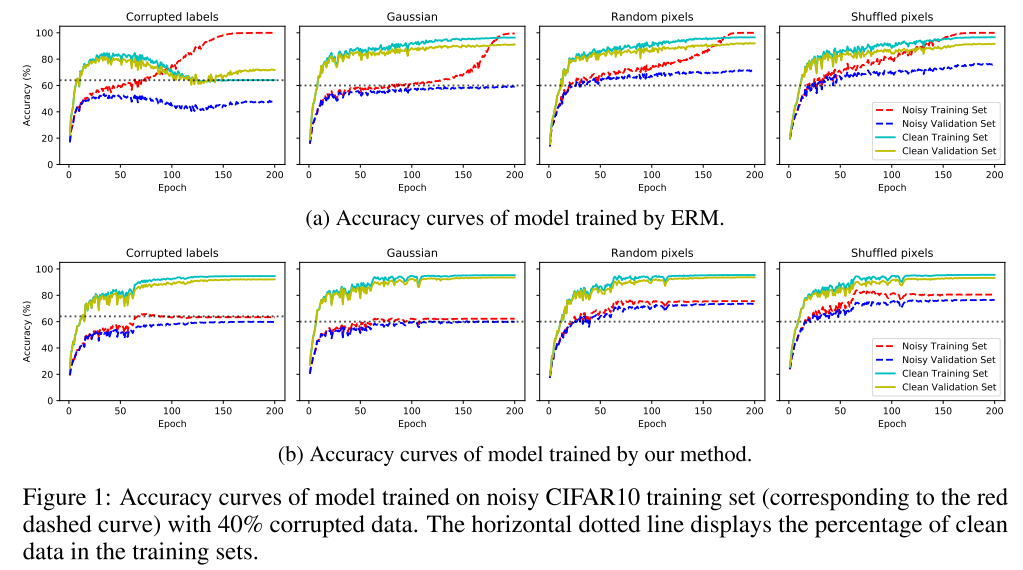
이 논문에서 제안하는 방법은 이는 Figure 2b.에서 볼 수 있듯이, clean dataset보다 낮은 수준에서 converge하며 100%에 가깝도록 noisy training dataset에 과적합되지 않고 clean/noisy 데이터셋 모두에서 훈련 양상을 유사하게 따르며 일반화 (generalization)을 개선함.
제안하는 방법의 이름은 Self-adaptive training,

일정 epoch가 지나고 label 과 prediction 의 convex combination인 training target 와 prediction 과의 cross entropy를 update하는데, training target 을 최대로 만드는 training target의 j-th 채널 값을 weight으로 사용한다. 이는 초기에는 모든 샘플에 대해서 equal (1/c) 하게 취급하다가 점점 더 정답 class 방향으로 높은 확률을 내는 샘플에 대해서 초점을 맞춰서 학습하도록 유도하게 되는데, 논문에서 알고리즘이 잠재적으로 erroneous data에 덜 집중하고 잠재적으로 clean한 데이터를 학습하도록 한다고 설명한다.
정답 class 방향으로 낮은 확률을 내는 샘플에 대해서 더 학습하도록 하는 Focal loss와는 반대방향으로 학습을 유도하는 것처럼 보인다. Focal loss가 어려운 샘플들을 풀기 위해 고안된 손실함수지만, 오염되어있을 수 있는 training data에 과적합되기 더 좋은 loss이기도 하다는 의미로도 볼 수 있다.
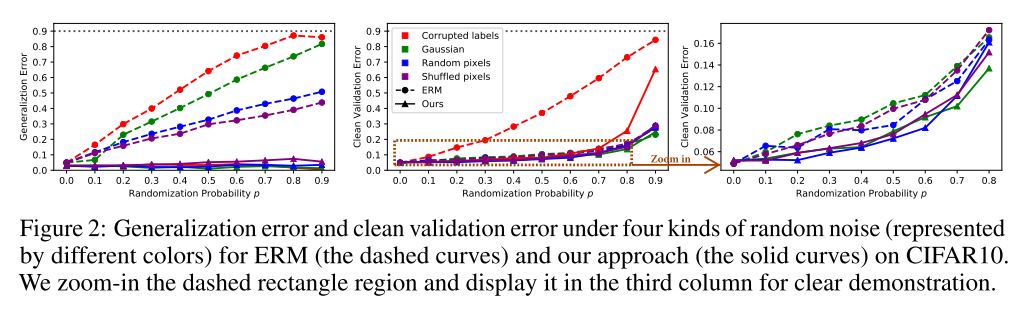
4가지 종류의 random noise에 대해서 randomization 확률을 높여가면서 Generalization error (noisy dataset에서의 training accuracy와 validation accuracy의 차이)과 clean validation error를 plot한 결과인데, 제안한 방법이 ERM보다 generalization error와 clean validation error 모두 더 작게 나오는 것을 확인할 수 있음.
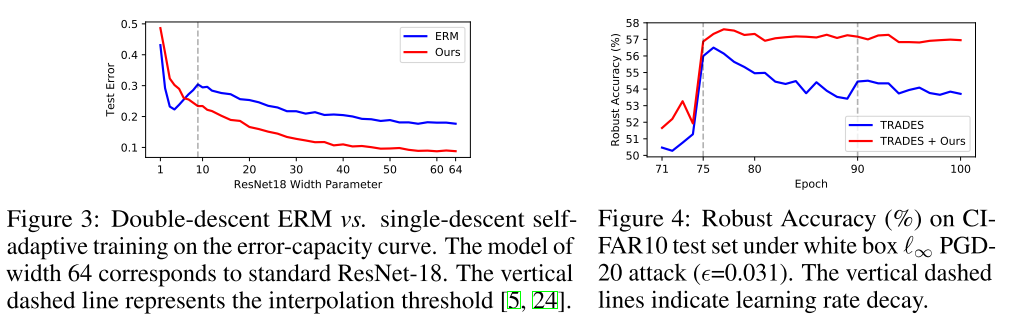
Figure 3은 15%의 training label을 random으로 오염시킨 CIFAR10으로 ResNet18의 width를 점점 더 키우면서 test error를 plot한 것인데, ERM의 경우에는 double descent가 보이지만, 제안한 방법은 single descent로 더 낮은 error를 기록한다. ERM에서 dobule descent가 나오는 것으로 관찰되는데, 이게 label noise를 없애면 double descent가 없어질 수 있어 이 현상이 noise에 overfitting한 결과로 해석할 수 있고 제안한 방법을 그걸 적절하게 bypass할 수 있게 해준거라고 이야기함.
Figure 4은 adversarial noise (사람은 못 알아보는데, 모델 결과에 영향을 주는 noise) 에 대응하는 adversarial training 알고리즘인 TRADES에 제안한 방법을 CE 대신 적용했을때를 비교한 것으로 제안한 방법을 적용했을 때 robust accuracy (adversarial attack 당한 샘플의 정확도) 가 더 향상됨을 확인할 수 있다.
3. Application I: Classification with Label Noise
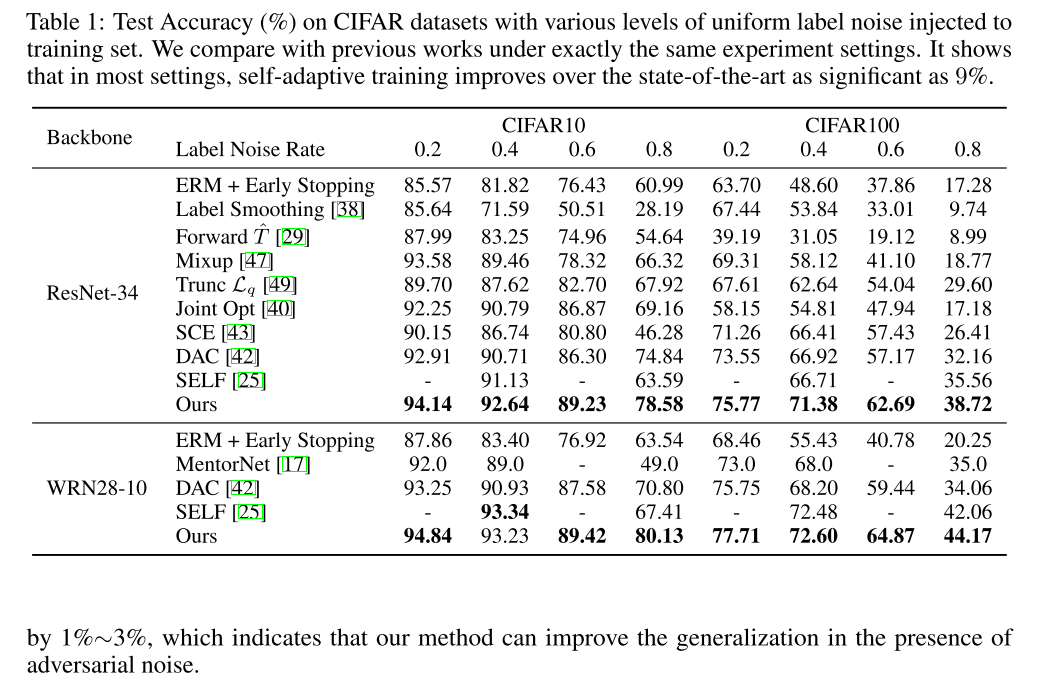
Ablation study
prediction 확률이 높게 나온 샘플에 집중하는 re-weighting보다는 moving average (정답과 일치하는 방향의 확률인 training target을 사용하는 부분)을 제거했을때 성능저하가 더 컸음.
랑 는 정해주는 hyperparameter인데, 40%를 label noise를 적용한 CIFAR 10 훈련셋에서 optimal한 값을 찾은 것으로 다른 실험들에서도 동일하게 사용되었음. ,
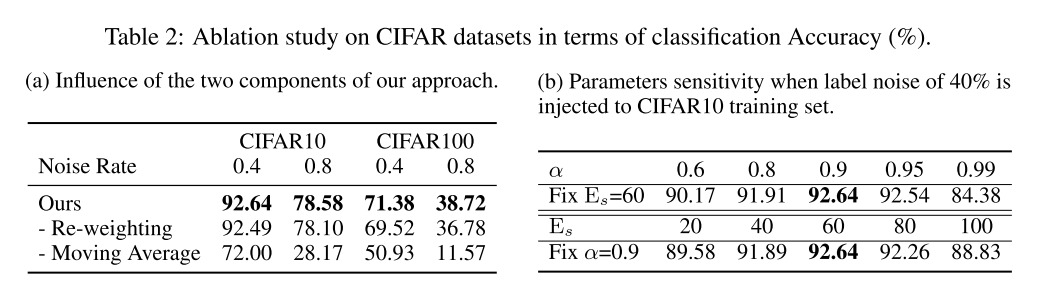
Label recovery
moving average target 를 가지고 noisy training label을 recover할 수 있는지도 봤는데, CIFAR10과 ImageNet 훈련셋에서 40% label을 오염시켰을때 각각 94.6%, 81.1%의 높은 recovered accuracy를 달성함. Figure 5는 CIFAR10에 대한 label recovery의 confusion matrix를 plot함.
recovered accuracy는 전체 N개 중 clean label 과 의 argmax의 일치율.
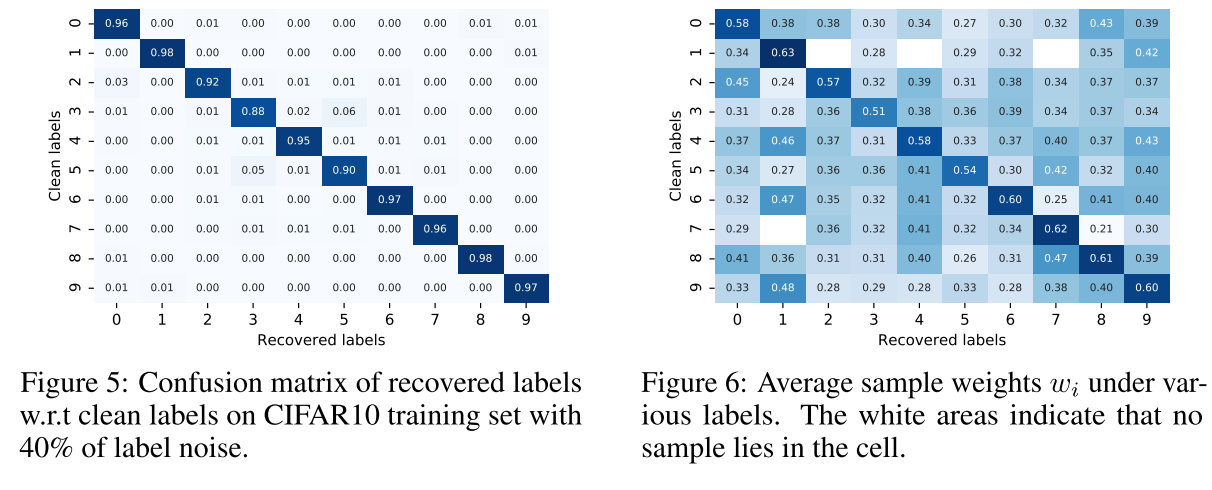
Sample weights
Figure 6. clean label 와 recovered label 과의 average weight 을 보여주는데, diagnoal 성분이 가장 높은 값을 가지면서 self-adaptive training이 noisy한 샘플들을 down-weight함을 보여줌.
4. Application II: Selective Classification
selctive classification (a.k.a. classification with rejection)은 특정 샘플들을 모른다고 허가하여 분류할 데이터의 비율인 coverage에 따른 accuracy를 본다. 보통 f가 c-class classifier고 g가 입력의 uncertatinty를 추정하는 selection fuction라고 할때 다음과 같이 정의된다.
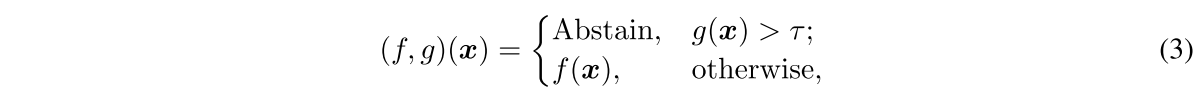
저자는 abstention을 위한 (c+1)-th class를 훈련중에 두고 그 class를 맞추는 f()c를 selection fuction으로 두고 end-to-end로 같이 훈련시킬 수 있도록 하고 손실함수는 다음과 같이 정의됨.
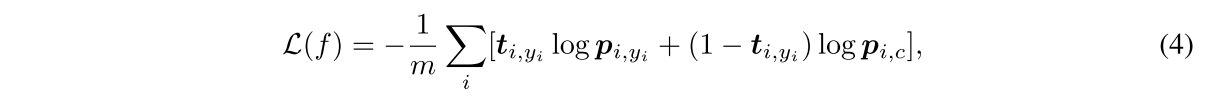
가 아주 작으면 uncertain한 것으로 2번째 term이 해당 샘플을 abstain하게 하고 값이 1에 가까우면 certain한 샘플로 task loss를 줄이는 첫번째 term을 줄이는 쪽으로 간다.
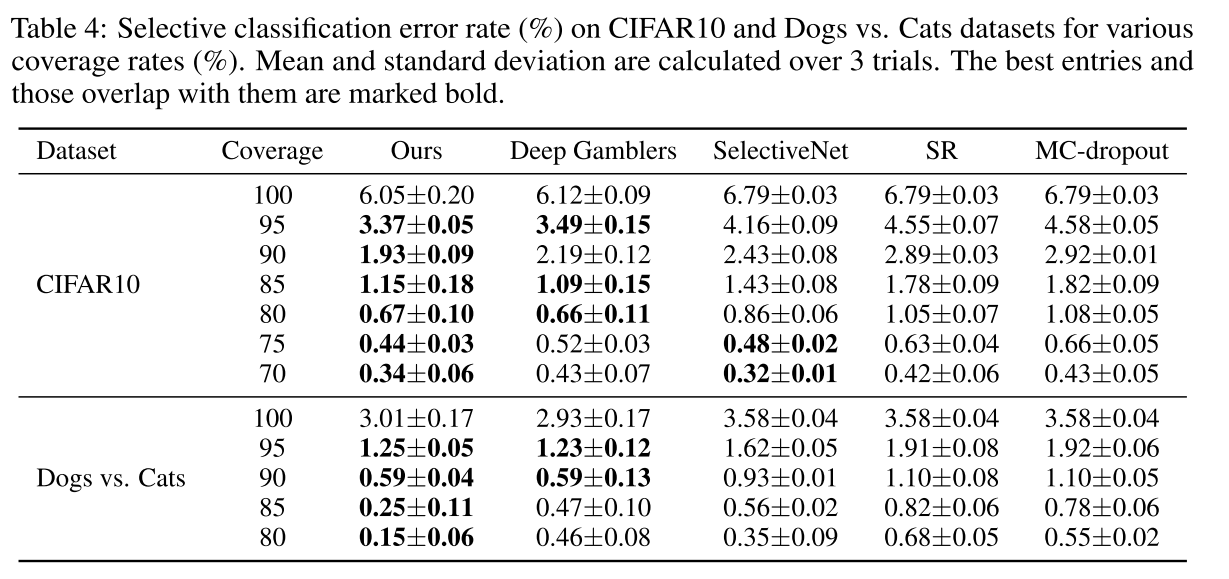
제안한 방법을 적용한 selective classification에서도 가장 좋은 성능을 보여준다.
Conclusion
ERM을 사용한 표준 훈련 다이나믹을 분석하고 내재적인 실패 케이스들을 살펴보았고, 그런 관찰로부터 Self-Adaptive Traning을 제안하게 되는데, 다양한 corruption에서 deep neural networks의 generalization을 개선함을 입증했다.
Code
Official code에서 해당 loss를 구현한 부분은 아래와 같음.