[2022 arXiv] MobileViTv3: Mobile-Friendly Vision Transformer with Simple and Effective Fusion of Local, Global and Input Features
Paper Review
1 Introduction
CNN (ResNet (2016), DenseNet (2017), Efficient Net (2019))이 computer vision에 널리 사용되었고, mobile phone과 같은 edge device을 고려하는 것에 대해서는 MobileNets (2018, 2019), ShuffleNets (2018), Efficients (2019)들이 연구되었음
최근에 ViT (2020) 이 CNN의 대체제로 떠오름. CNN은 이 아키텍처 디자인 때문에 feature map에서 이웃한 부분과 상호작용해서 local information을 담은 feature map을 제공하고 반대로 ViT의 self-mechanism은 이미지, feature map의 모든 부분과 상호작용해서 global information이 포함된 feature map을 제공함
다만 이런 global processing은 ViT가 CNN과 상응하는 성능을 달성하기 위해 많은 parameter를 요구하게 됨..
ViT (Transformer 계열) 연구에서도 Variants를 개량해왔는데, DeiT (2021), SwinT (2021), MViT (2021), Focal-ViT (2021), PVT (2021) , T2T-ViT (2021), XCiT (2021) 들에선 ViT가 훈련시킬 때 lr, optimizer, weight decay와 같은 hyper-parameters에 민감하다는 것을 보였었음
그래서 가장 최근 연구들엔 parameter size의 efficinconvolution layer를 ViT architecture에 도입하는 hybrid 형태의 network를 소개하고 있음. MobileViTv1 (2021), MobileViTv2 (2022), CMT (2022), CvT (2021), PVTv2 (2022), ResT (2021), MobileFormer (2022), CPVT (2021), MiniViT (2022), CoAtNet (2021), CoaT (2021)...
이들 중 MobileViT와 MobileFormer만이 제한된 resource에 대해서 설계되었고, 다른 hybrid network와 비교하여 더 적은 파라미터와 FLOPs로 견줄만한 성능을 달성하였다
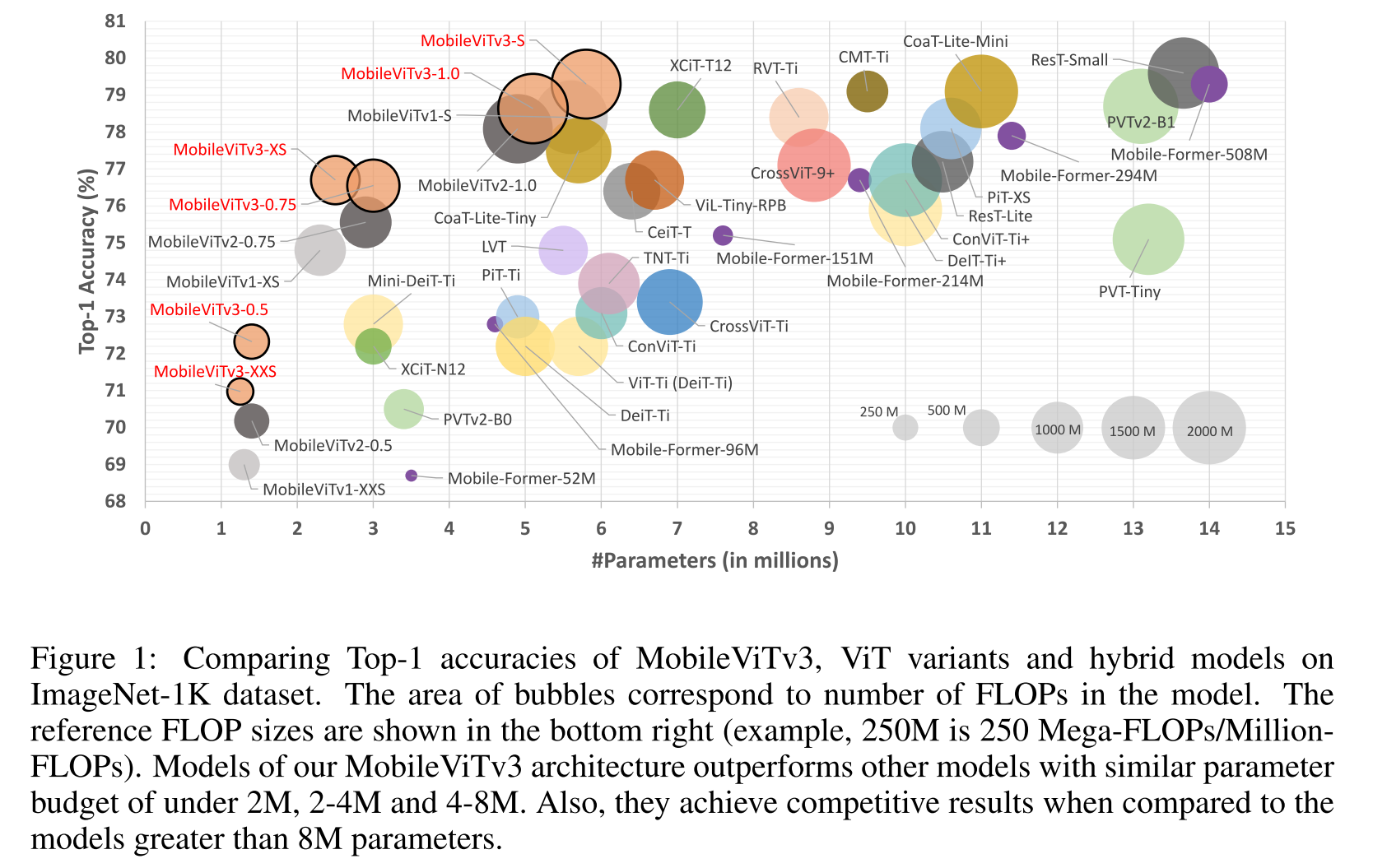
이 연구는 MobileViT 계열을 개선하는데 집중하고, 6 million 600백만 개 이하의 파라미터에서 MobileViT 패밀리들이 state-of-the-art 결과를 달성하고 있다.
2 Related Work
Vision Transformers
ViT (2020)이 NLP쪽에 사용되던 transformer 모델을 visual domain에 처음 소개했고
이후에 DeiT (2021)이 큰 사전훈련 데이터의 의존성을 줄이면서 좀 더 나은 training technique을 소개하면서 성능을 개선했다
성능을 강화하기 위해 self-attention mechanism에 집중한 연구들로는 XCiT (2021), SwinT (2021), ViL (2021), Focal-transformer (2021)이 있다.
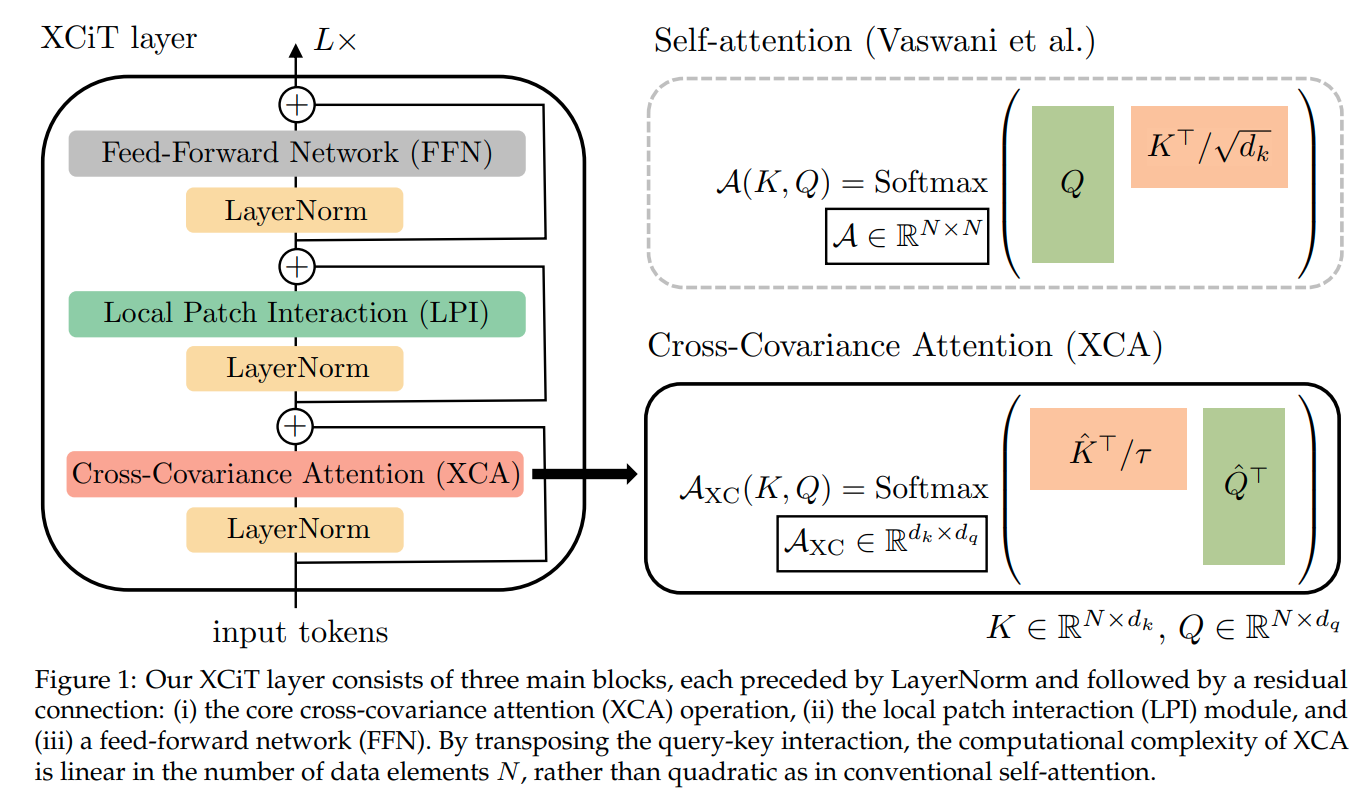
XCiT (2021) 는 token 대신에 feature map에서 작동하는 self-attention으로 key와 query와의 cross-covariance matrix를 소개하고
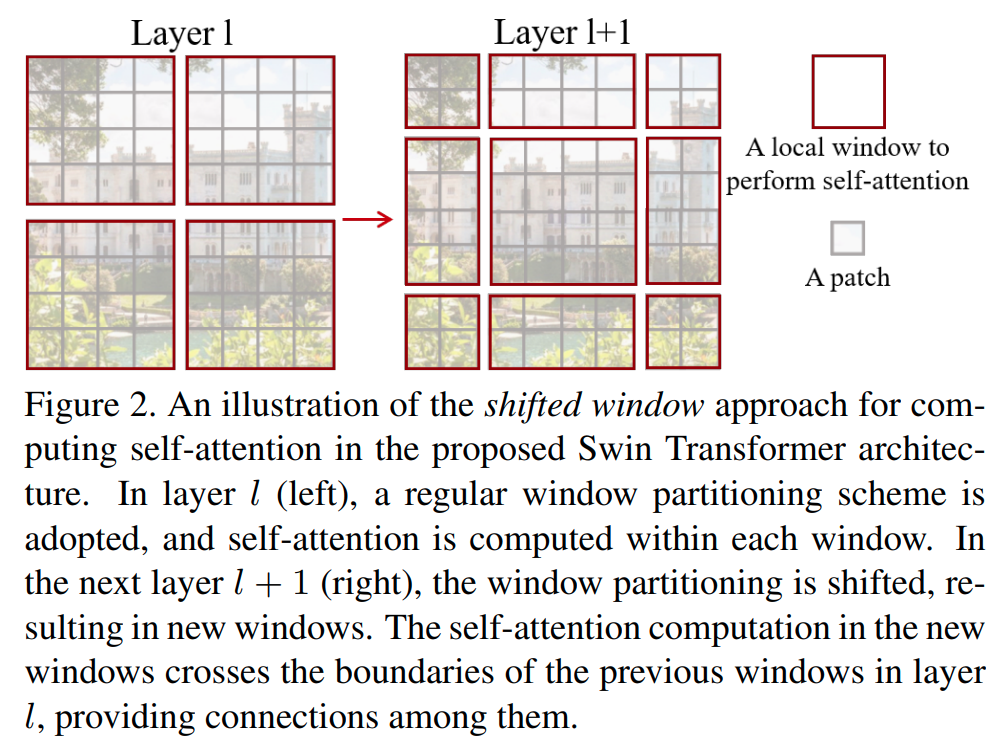
SwinT (2021)는 모델이 다른 입력 이미지 스케일에 adapt하고 input 이미지 스케일에 따라 linear한 computational complexity를 달성하도록 효율적으로 작동하게 해주는 shifted-window based self-attention을 소개하고
ViL (Vision Longformer, 2021)은 multiple scale의 이미지를 encoding하면서 self-attention mechanism을 사용하는 방식으로 ViT를 개선시키는데, Longformer (2020)이 개량된 형태이다
T2T-ViT (2021), PVT (PVTv1, 2021)과 같은 최근 연구들은 각 layer 결과의 token size나 spatial resolution을 줄임으로서 hierarchical feature를 학습하는 CNN을 소개하는데 집중한다.
T2T-ViT (2021)는 local structure를 capture하면서 token 길이를 줄이기 위해 이웃하는 token들을 하나의 token으로 결합하는 layer-wise token-to-token transformation을 제안했고
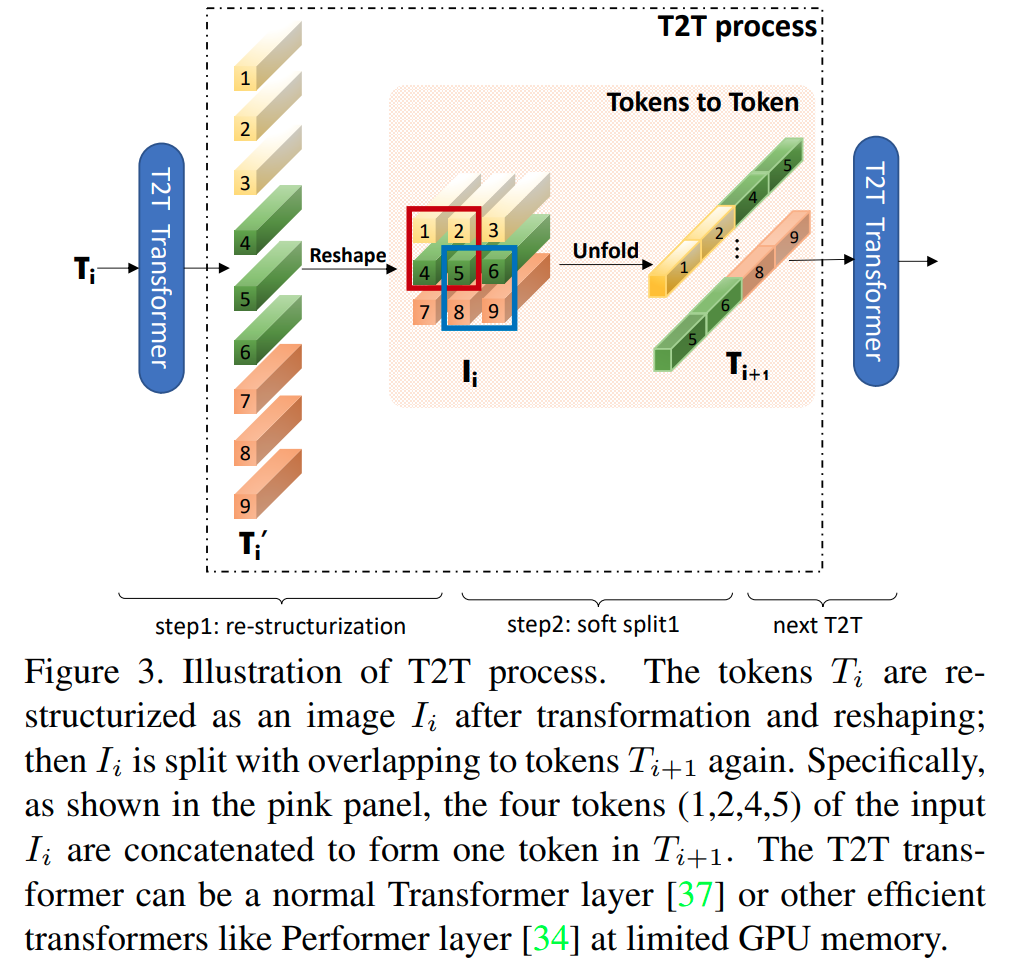
PVT (2021)은 pyramid vision transformer로 feature map의 resolution 크기를 줄여 성공적으로 연산복잡도를 줄이면서 ImageNet-1K에서 competitive한 결과를 달성했다
CrossViT (2021), MViT (2021), MViTv2 (2022), Focal-transformer (2021)과 같은 새로운 아키텍처들은 local feature (이웃한 pixels/features/patches로부터 배우는)와 global feature (모든 pixels/features/patches로부터 배우는) 두 가지 모두 학습하는 것으로 고안되었는데,..
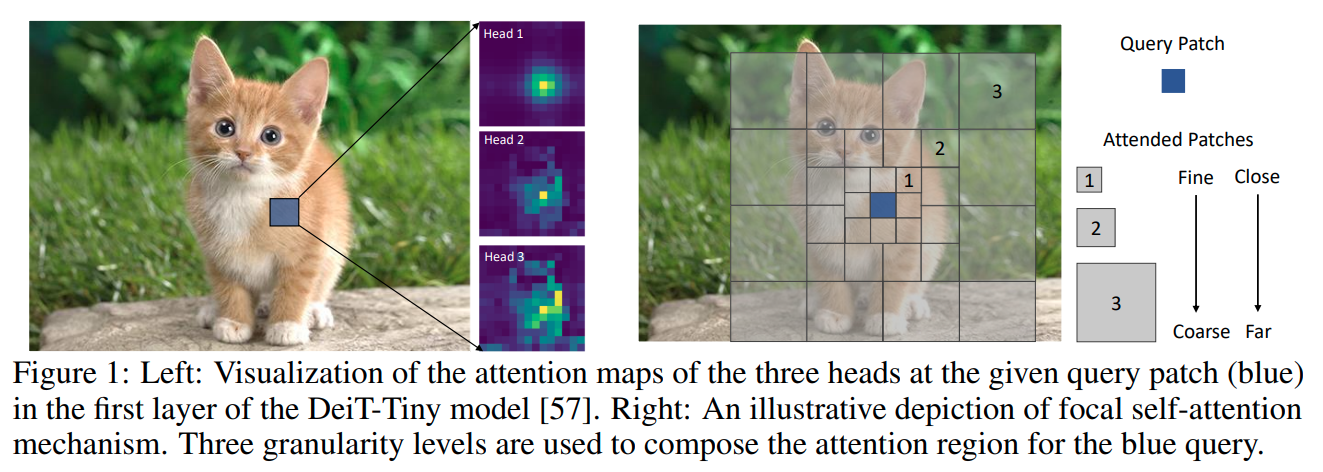
Focal-transformer (2021) 는 self-attention 대신에 focal-self-attention을 제안하는데, 이는 각 token이 가장 가까운 둘러쌓인 토큰들을 fine granularity 과 멀리있는 token들을 coarse granularity로 처리하여 짧고 긴 visual 의존성을 모두 포착할 수 있게 한다
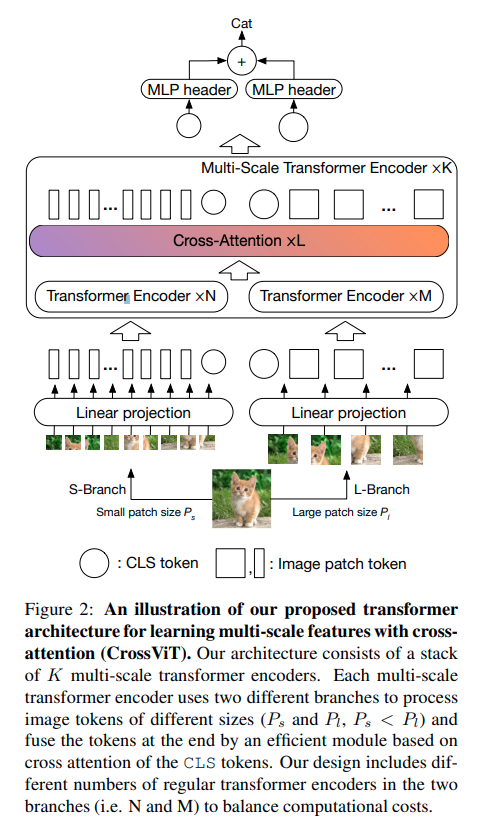
CrossViT (2021)는 작은 patch 큰 patch 각각 처리하고 여러 차례 attention으로 결합시켜 서로를 보완하게 한다.
MViT (2021)은 video and image recognition을 위해 설계됐는데 초반 layer에서는 low-level 시각 정보를 capture하고 더 깊은 layer에서는 복잡하고 고차원의 feature를 capture하는 multi-scale pyramid를 학습한다.
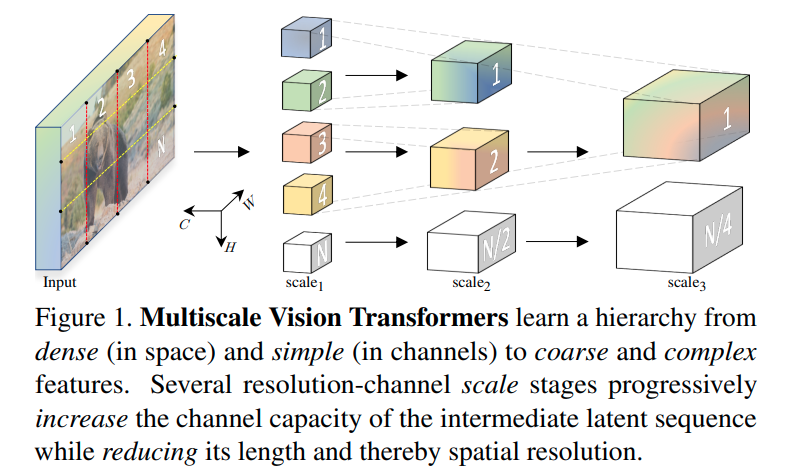
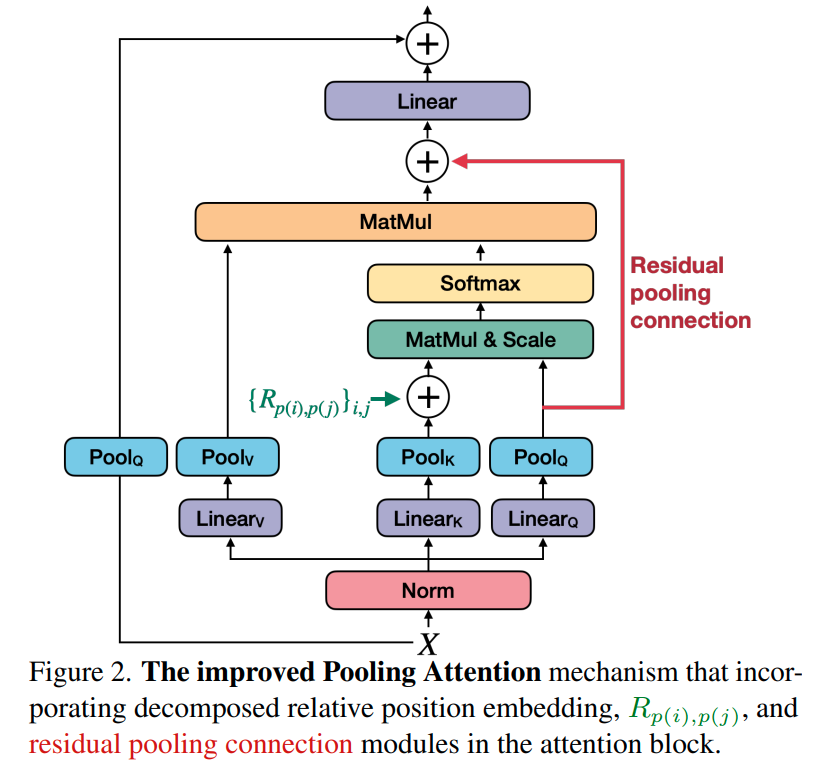
MViTv2 (2022)는 positional embedding과 residual pooling connection을 도입해서 MViT를 개선했다.
CNNs
ResNet (2016): 더 깊은 layer들의 최적화를 도운 residual connection 제안 이 이후 더 깊은 network가 가능해짐
DenseNet (2017): ResNet보다 dense하게 residual connection하도록 해서 성능 개선
이후로 이런 CNN 아키텍처를 개량해가면서 ImageNet state-of-the-art 성능을 계속 달성해나감
경량화 CNN: EfficientNet (2019), MobileNetV3 (2019), ShuffleNetv2 (2018), ESPNetv2 (2019)
Efficient (2019)는 CNN의 scaling에 대해서 조사했고 parameter와 FLOPS의 관점에서 가장 효율적인 CNN 중 하나인 EfficientNet 패밀리를 제공한다
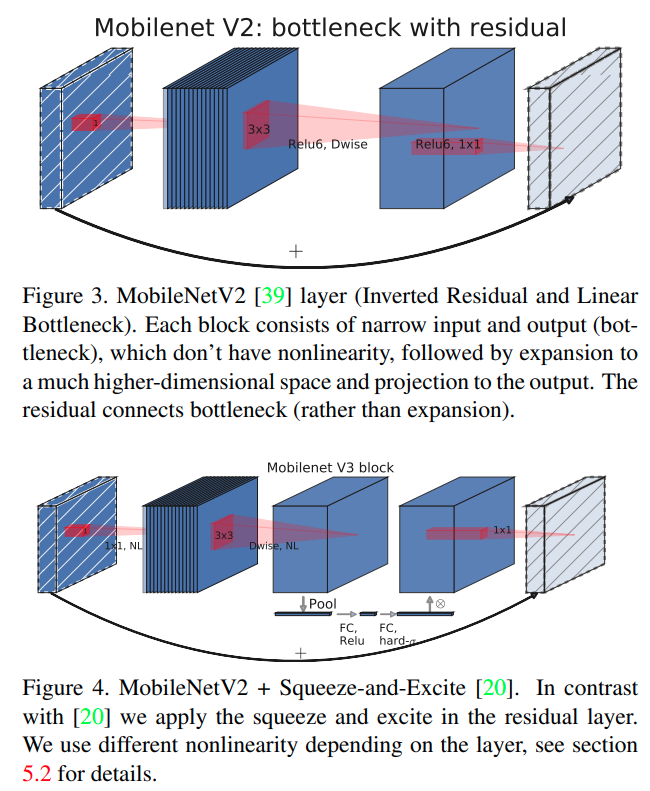
MobileNetV3 (2019)는 모바일 폰과 같은 resource constrained env를 위해 설계된 모델들의 category에 속하는데, MobileNetv2 (2018) block과 Squeeze-and-Exite (2018)을 모두 사용하는 block을 building한다.
ShuffleNetv2 (2018)는 효율적인 모델 설계에 대한 guideline을 조사하고 제안하면서 다른 경량화 CNN 모델과 competitively 성능을 내는 ShuffleNet family를 제공한다
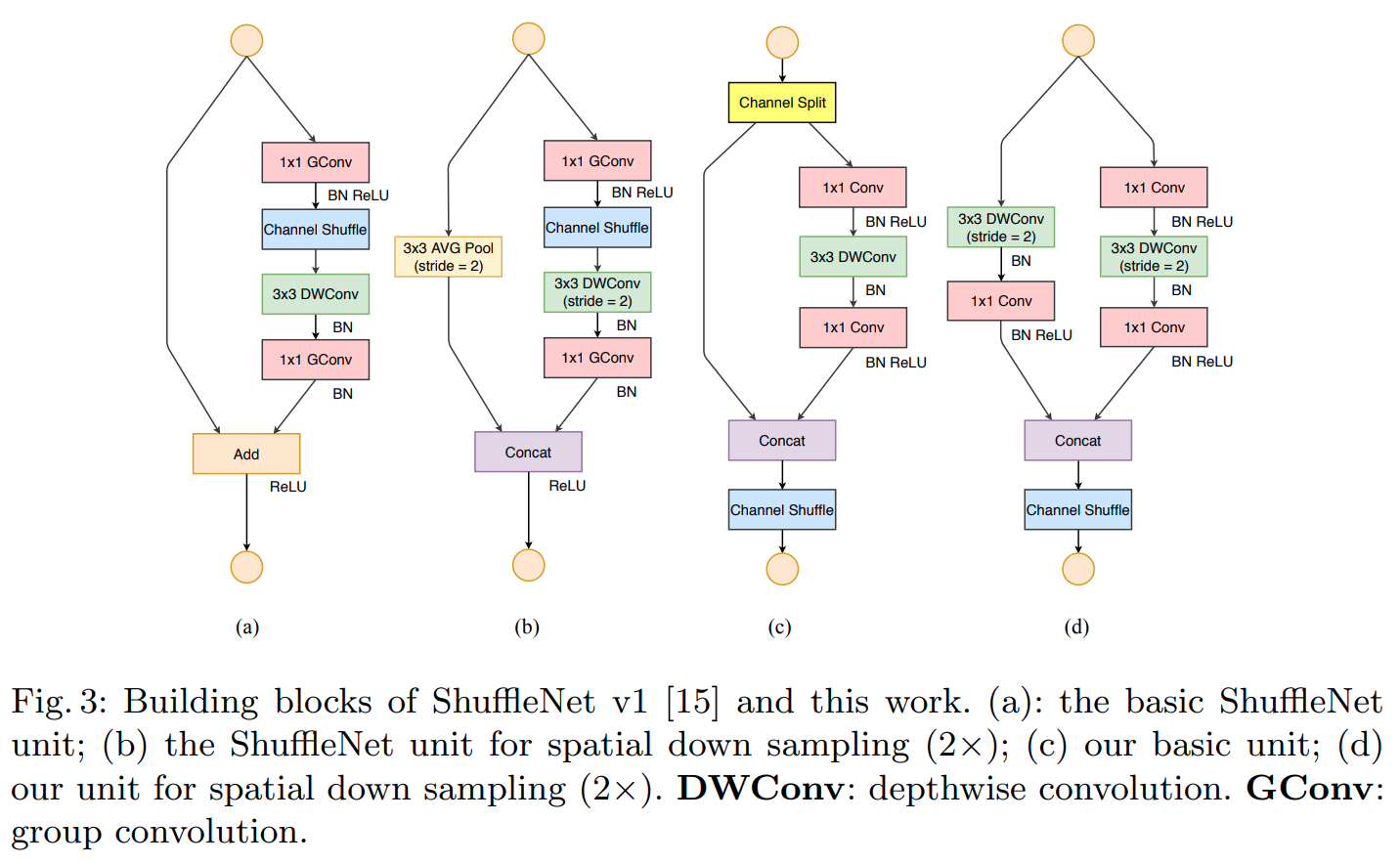
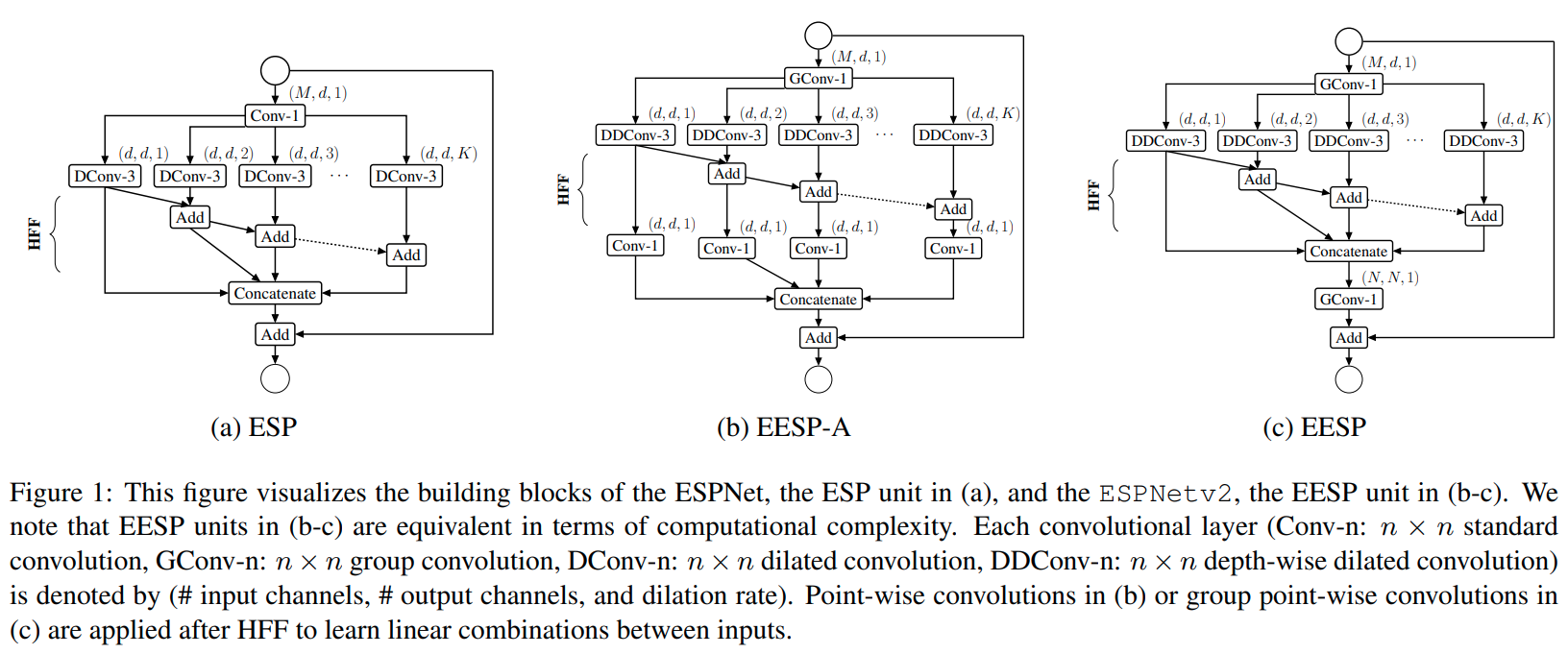
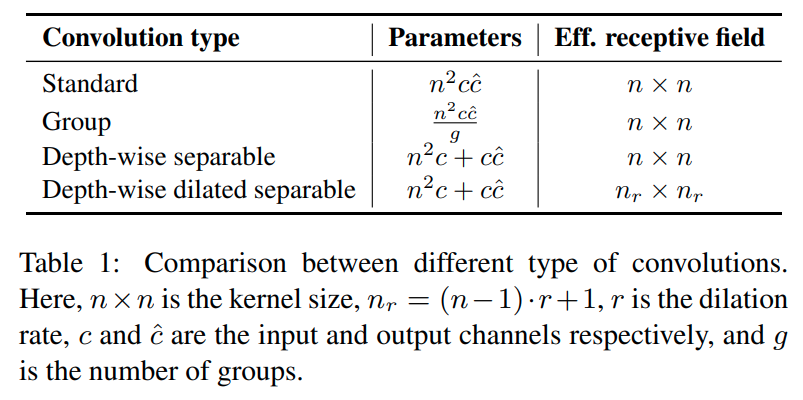
ESPNetv2 (2019)는 파라미터와 FLOPs를 줄이면서 견줄만한 성능을 내는 EESP (Extremely Efficient Spatial Pyramid) unit을 만들기 위해 depth-wise dilated separable convolution 사용한다
Hybrids
최근에는 CNN과 ViT를 하나의 아키텍처로 결합하는 모델들이 제안되고 있는데, ViT의 self-attention mechanism으로 long range 의존성 (global information), CNN의 local kernel로 local information을 capture해 vision task에서 성능을 올리고 있다.
MobileViT (v1, v2) (2021)과 MobileFormer (2022)는 mobile device와 같은 resource contrained env.를 위해 설계되었는데, MobileViT (v1, v2)는 6M 이하의 파라미터에서 sota를 달성했음
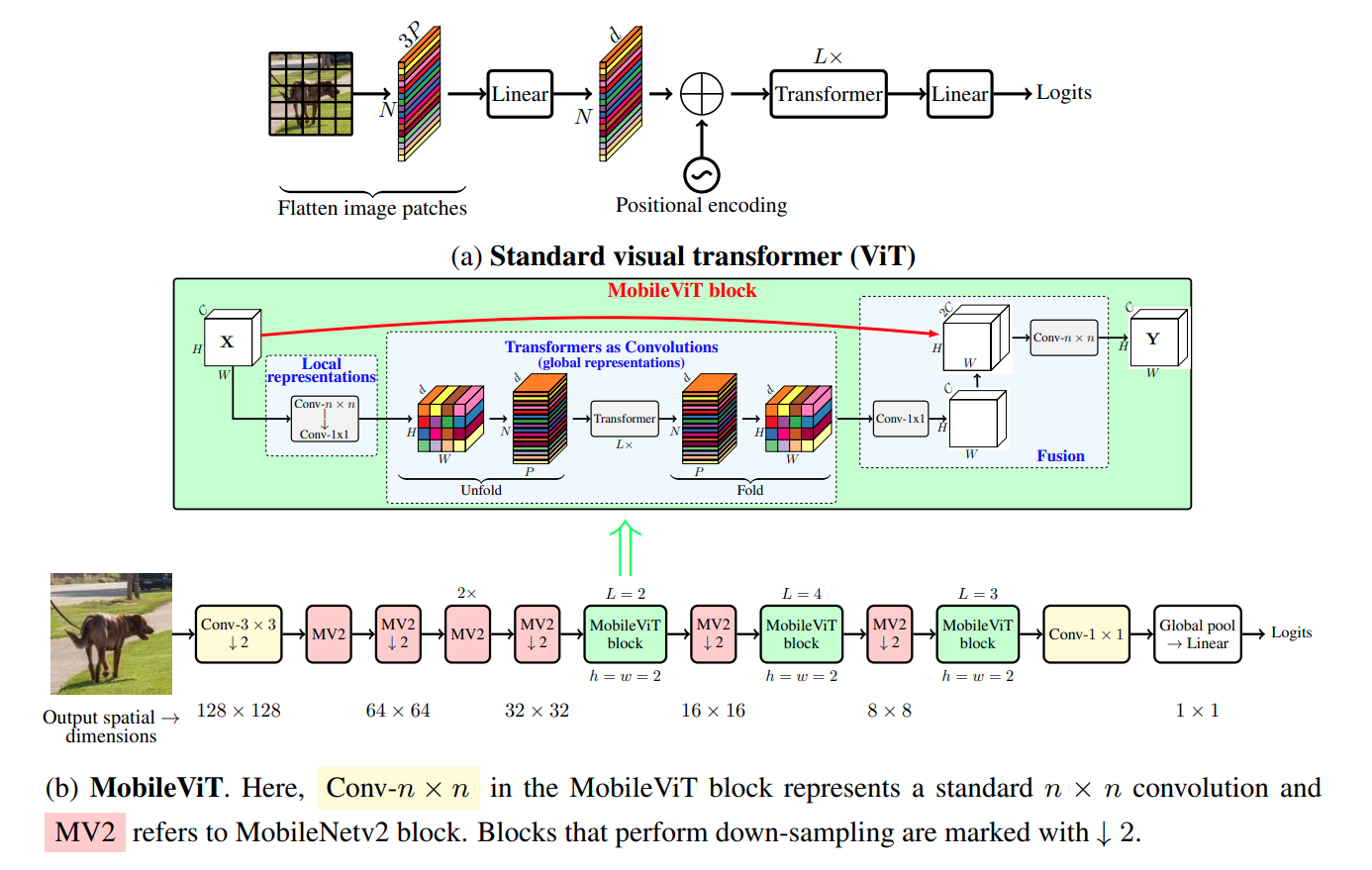
MobileFormer (2022)는 MobileNetv3와 ViT를 결합해 competitive한 성능을 달성했다.
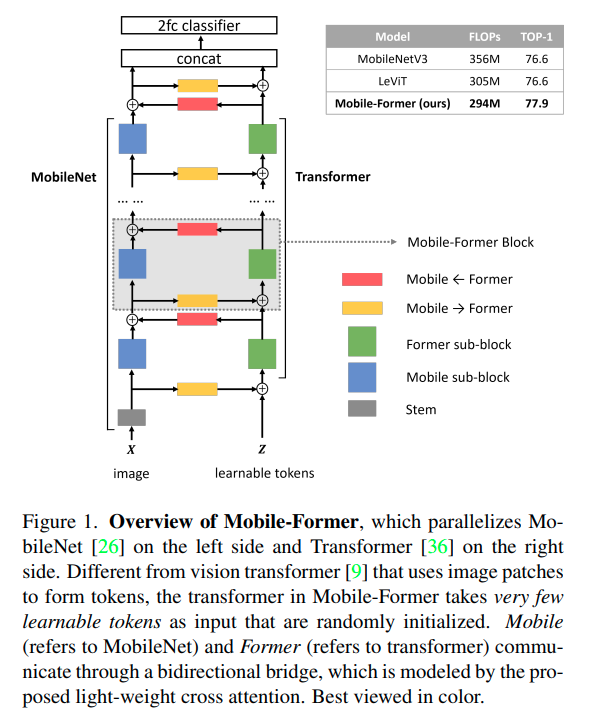
CMT (2022)는 모든 transformer block 직전에 convolution layer인 convolutional stem이 있고 conv layer와 transformer layer를 번갈아 stack한다.
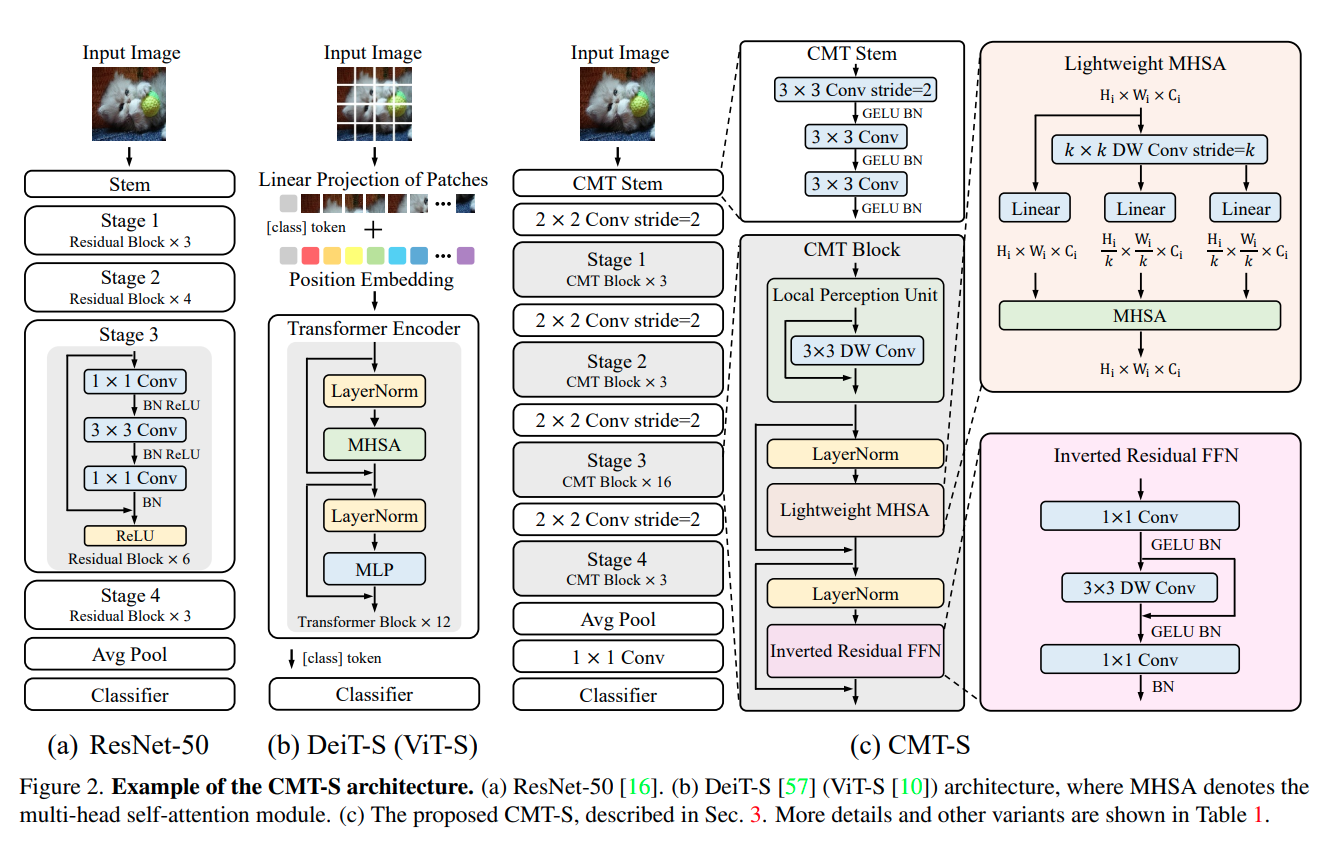
CvT (2021)은 linear embedding 대신에 convolutional token embedding을 사용해서 성능을 개선한다.
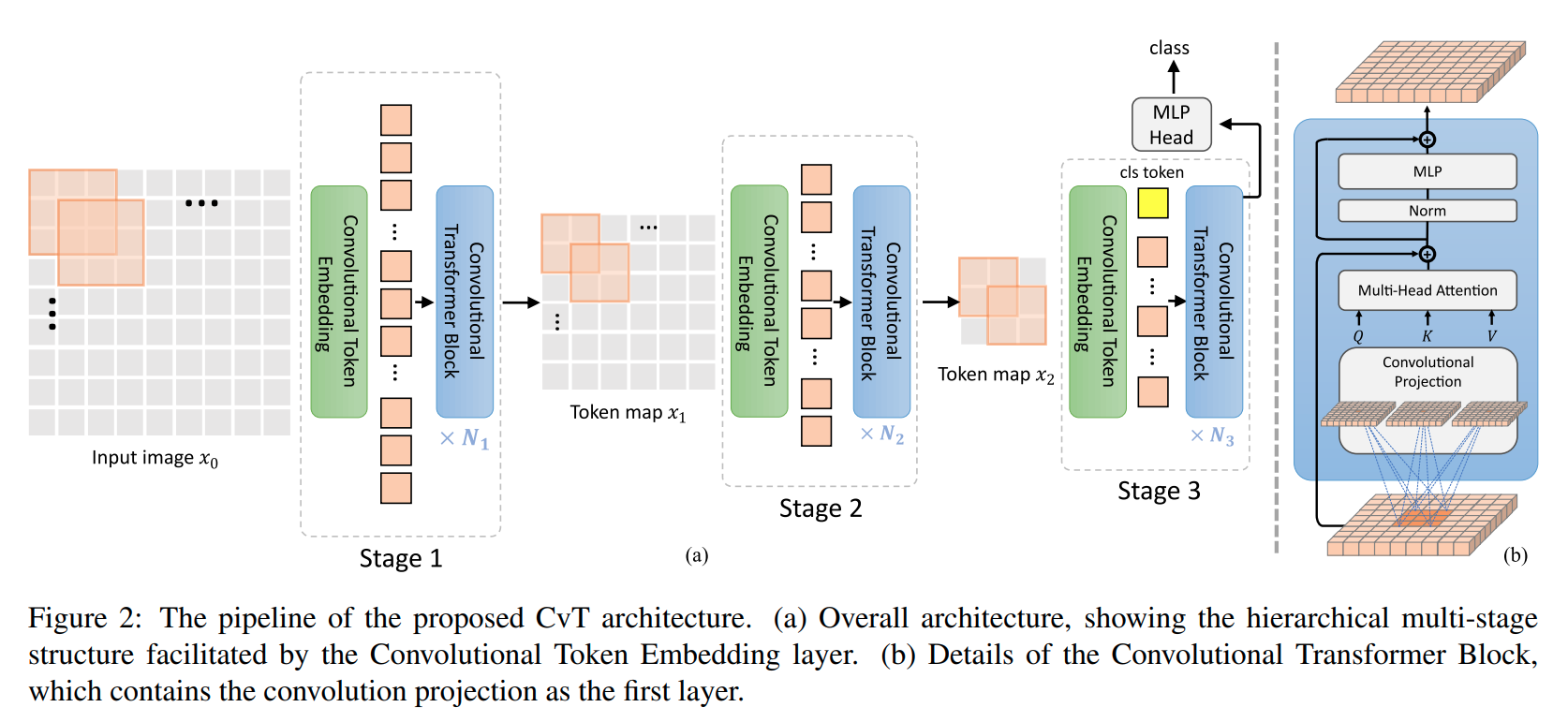
PVTv2 (2022)는 transformer 안에 convoltuional feed-forward layer, overlapping patch embedding, 선형 복잡도의 attention layer를 사용해 PVT보다 성능향상의 이득을 가져왔다.
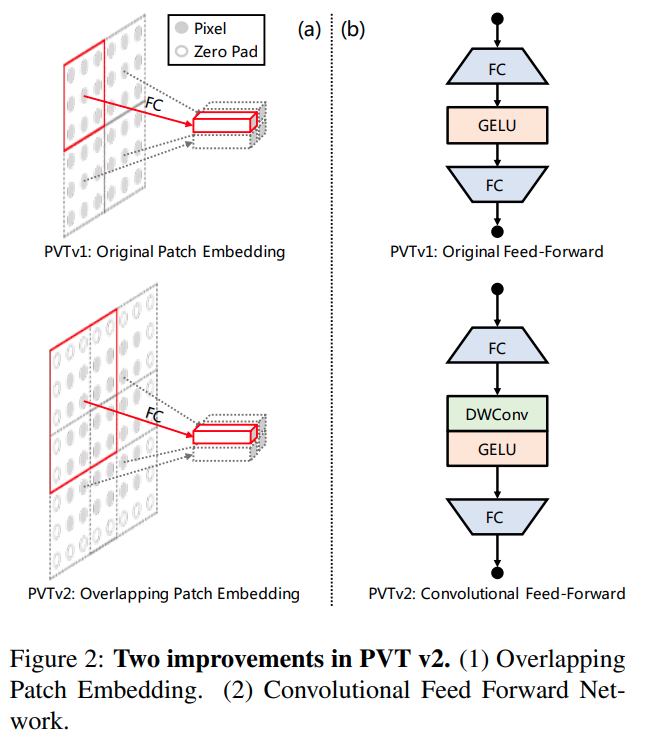
ResT (2021)은 메모리 효율을 위해 self-attention에서 depth-wise conv를 사용하고 token map의 convolutional operation을 겹쳐서 stack함으로서 patch embedding을 사용한다.
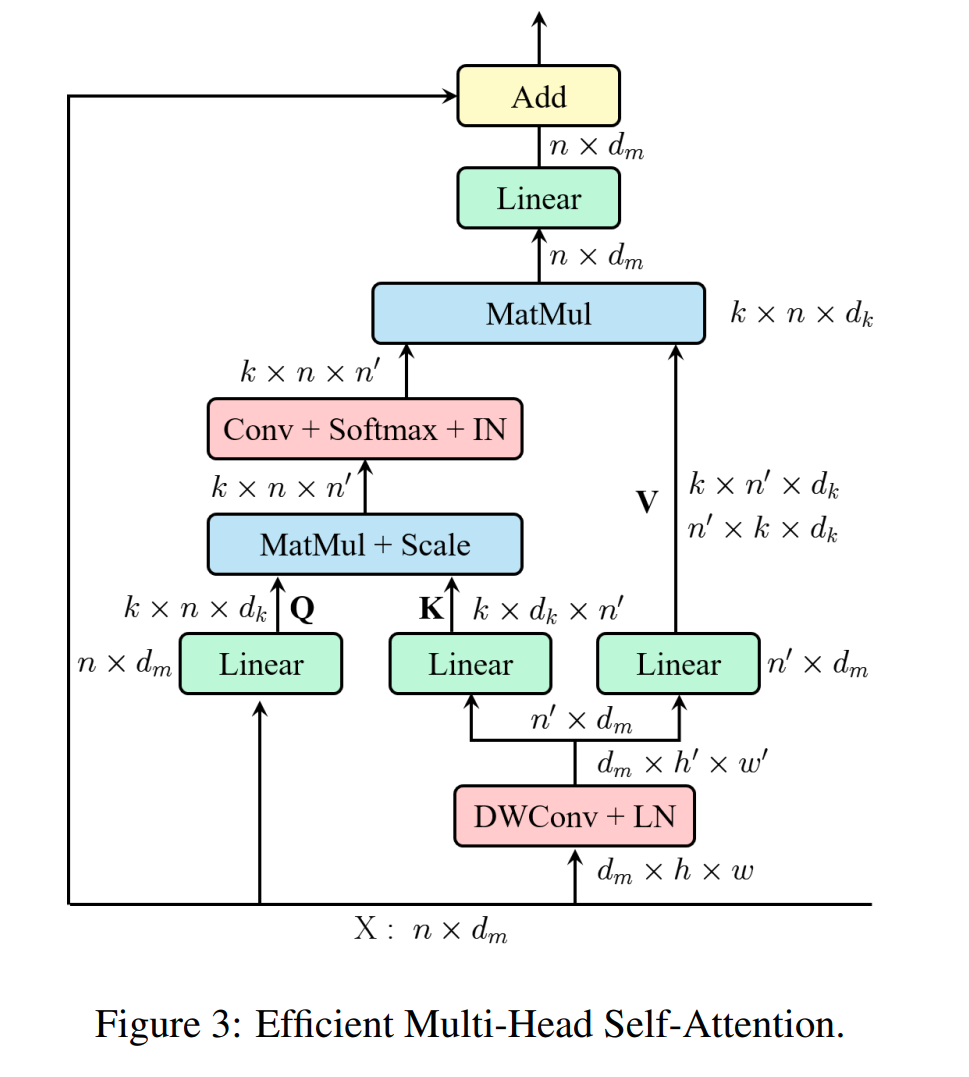
CoAtNet (2021)은 간단한 relative attention을 사용해 depth-wise conv랑 self-attention을 통합하고 conv layer와 attention layer를 수직으로 쌓았다
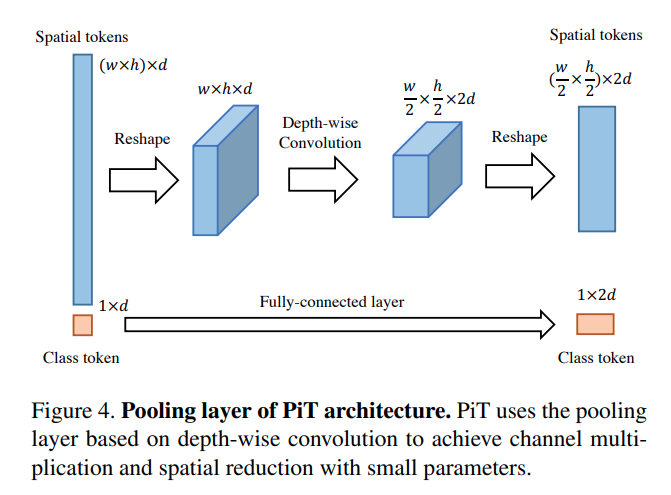
PiT's (2021)의 pooling layer는 성능 개선을 위해 spatial reduction을 달성하는 depthwise-convolution을 사용하고
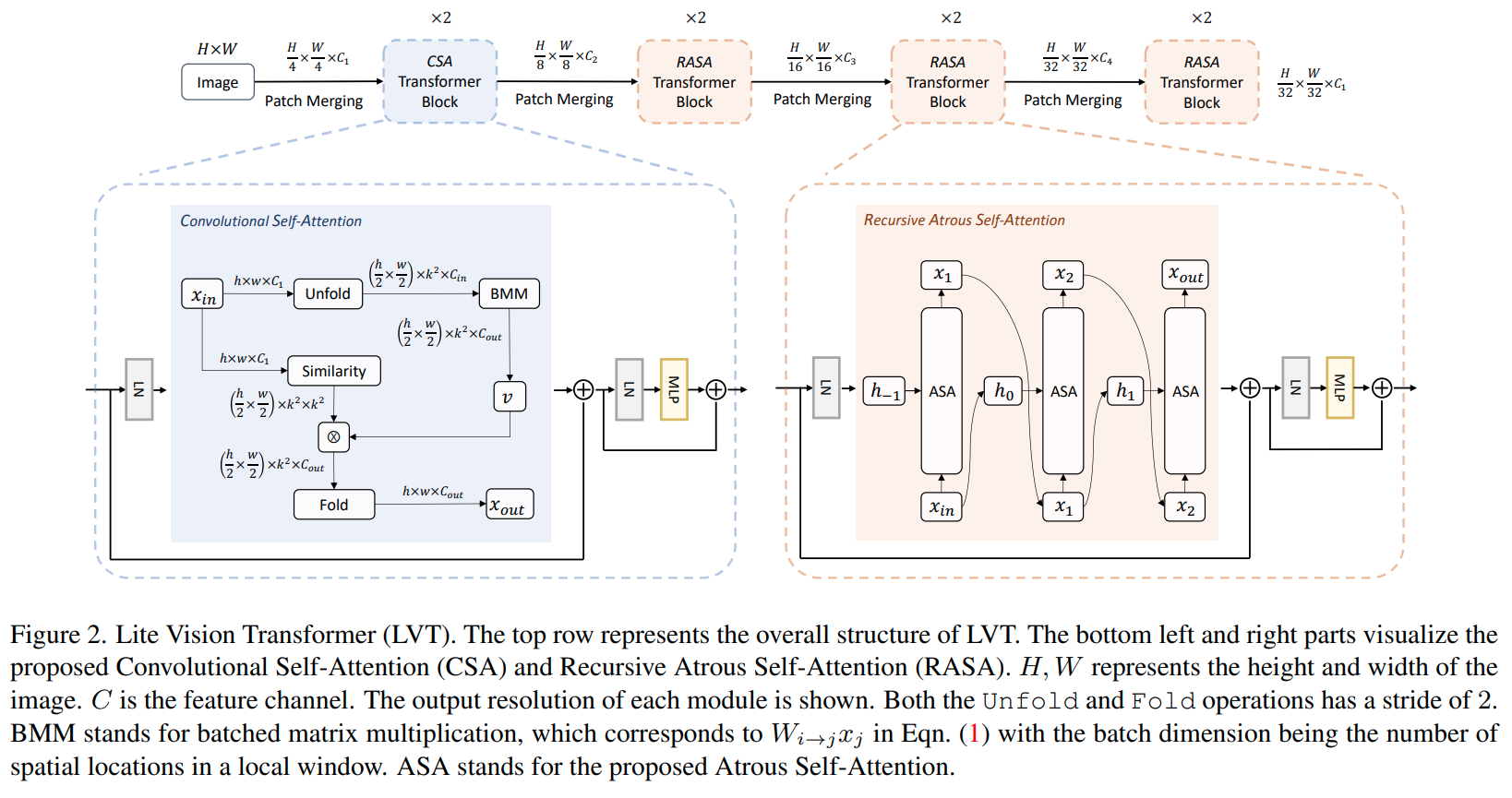
LVT (2022)은 conv kernel로 local self-attention하는 convolutional self-attention과 multi-scale context를 encompass하는 recursive atrous self-attention을 소개한다.
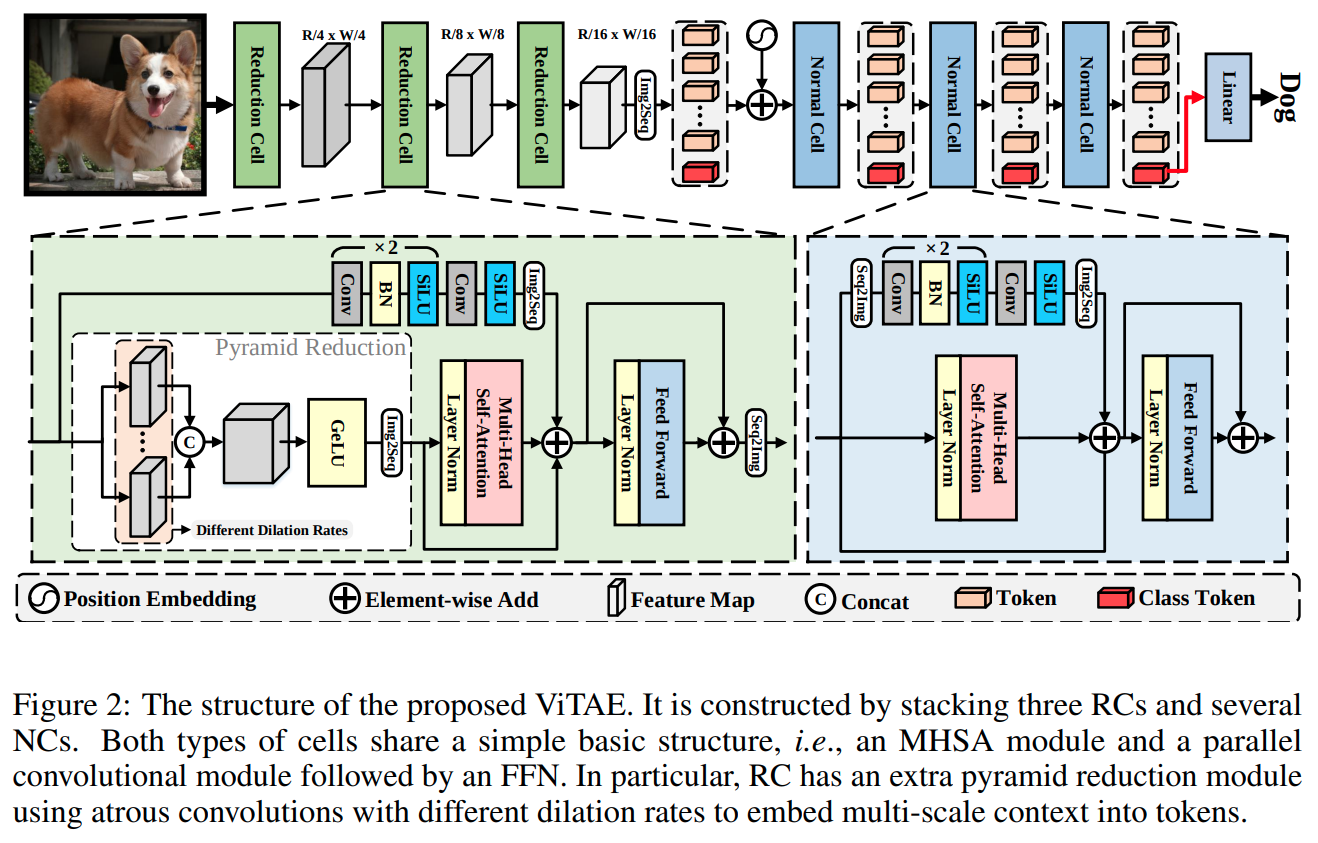
ViTAE (2021)은 multi-head self-attention의 병렬로 conv layer가 있고 둘 다 결합되어 feed-forward network에 입력되고 또한 input을 token으로 embedding할때 conv layer를 쓴다.
RVT (2022)은 patch embedding을 생성하는 conv stem을 사용하고 convolutional feed-forward network을 transformer안에서 사용하면서 성능을 개선했다.
3 New MobileViT Architecture
3.1 MobileViTv3 Block
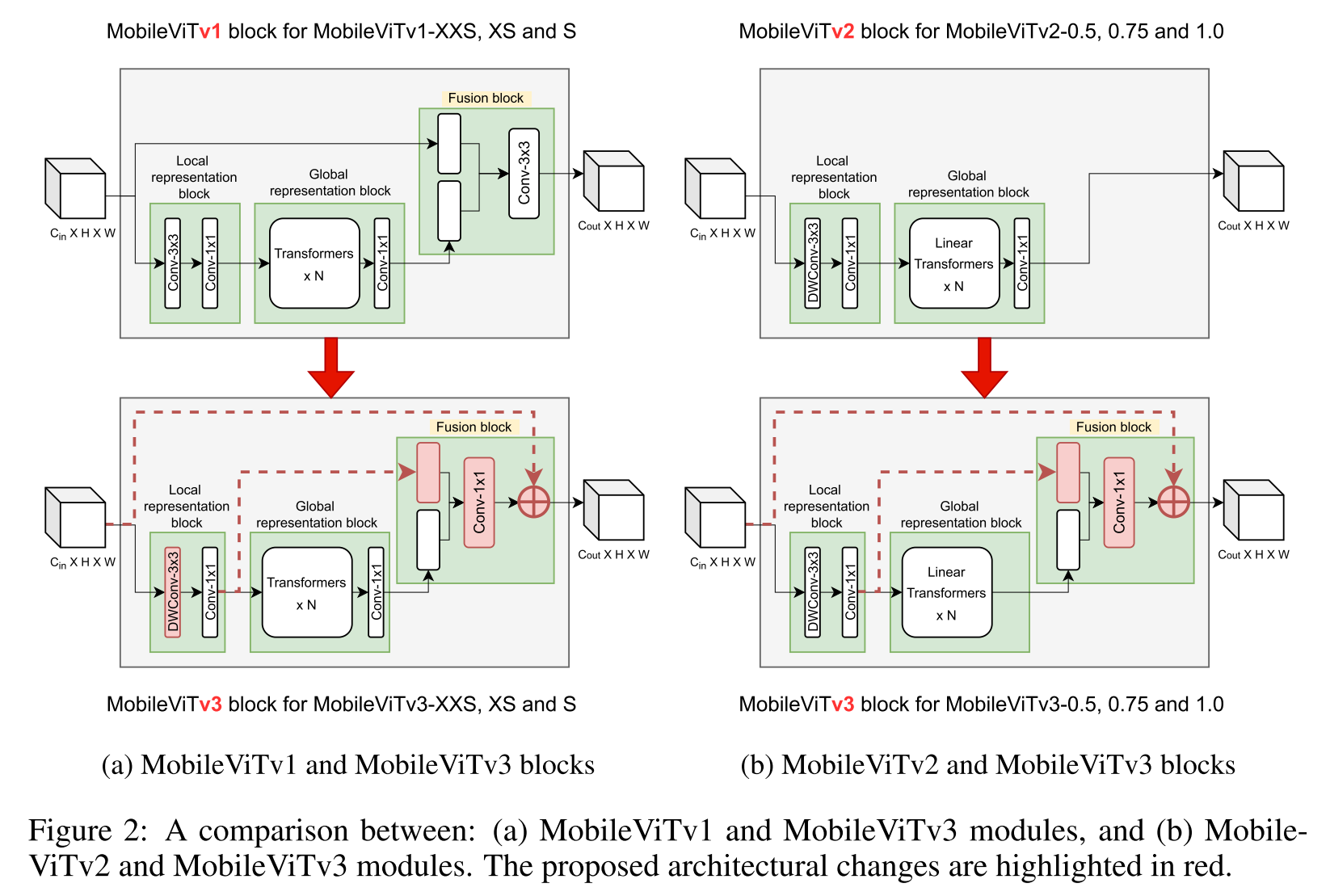
- fusion blcok의 conv 3x3 -> conv 1x1
첫째로, conv 3x3 fusion block의 목표는 location의 상관없이 input과 global feature를 합치는 거였으므로 conv 1x1가 더 적당하다
3x3 conv가 scaling하는데 가장 major한 걸림돌이었다. MobileViT block에 input 과 output channel이 두 배가 되면, fusion block 내부의 3x3 conv layer로 들어가는 입력 channel은 4배로 증가하는 것이고 output 채널은 2배 더 증가한다.. input과 global feature가 concat해서 들어가기 때문.. conv 1x1을 사용해 parameter와 FLOPs 증가를 줄일 수 있다.
-
local representation block의 local feature를 global feature와 fusion
parameter가 늘어나는 듯 보이지만 fusion하는 걸 conv 3x3에서 conv1x1로 바꾸면서 total parameter는 MobileViTv1보다 적더라 -
input feature은 fusion된 feature에 residual connection하는 걸로 변경
-
local representation block의 3x3 conv를 depth-wise conv로
MobileViTv2는 모델 paramter를 잡아먹는 Fusion block을 없애고 local representation block에 depth-wise convolution을 없앴었다. (실제로는 가장 가벼운 모델)
3.2 Scaling Up Building Blocks
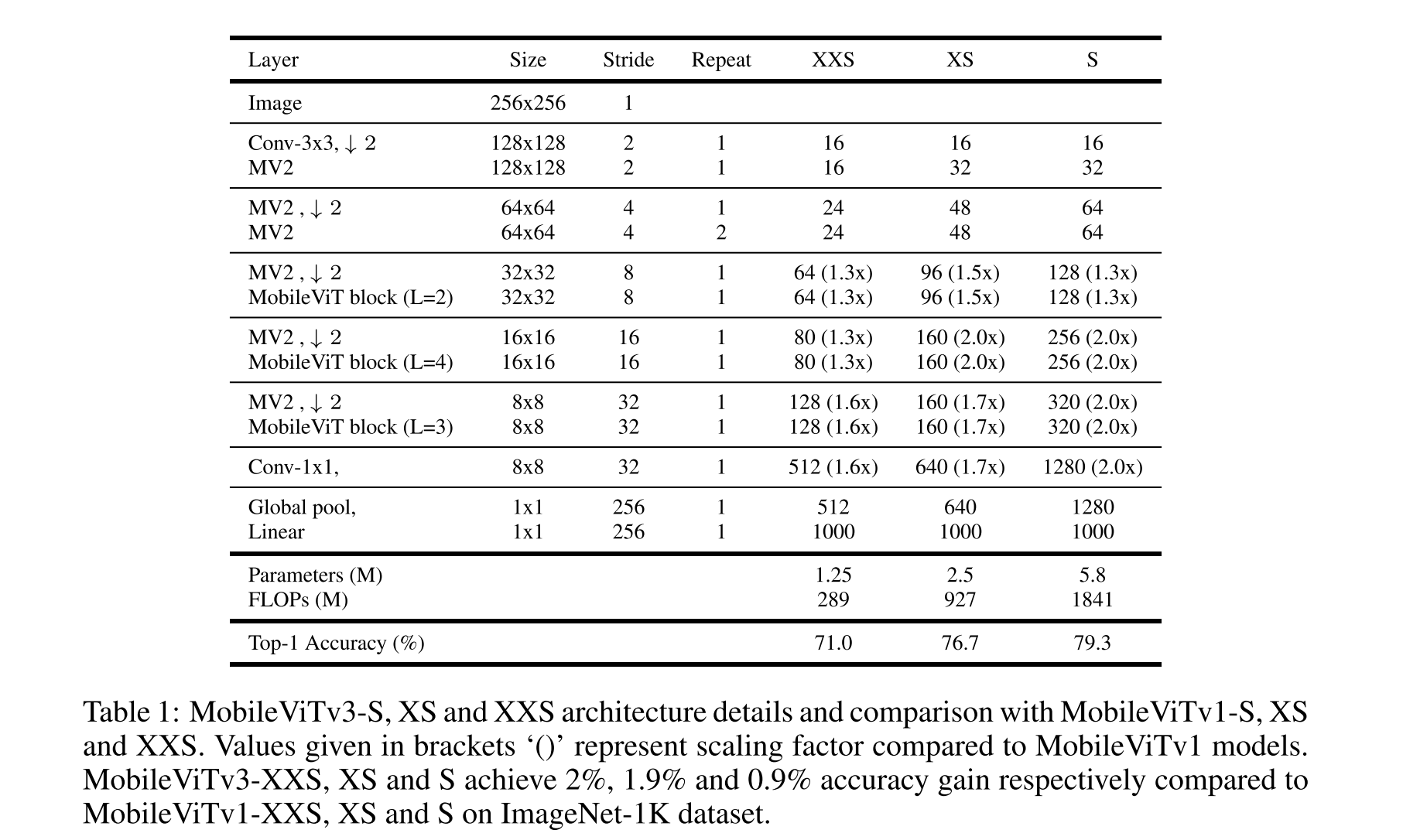
MobileNetv1-XXS ~ S로 scaling up하는 것에 동일하게 적용했을때 성능향상이 이루어졌음
4 Experimental Results
4.1. Image Classification on ImageNet-1K
4.1.1 Implementation Details
resource 제한으로 총 384 (32 per GPU)의 batch size를 사용
MobileViTv3-S, XS and XXS
default hyperparamter: MobileViTv1
- optimizer: AdamW
- L2 weight decay: 0.01
- multi-scale sampler: (160, 160), (192, 192), (256, 256), (288, 288), (320, 320)
- learning rate 처음 3000 iteration동안은 0.0002에서 0.002로 증가하고 그 이후론 cosine schedule을 사용해 0.0002로 annealing한다
- basic data aug: random resized cropping, horizontal flipping
MobileViTv3-1.0, 0.75 and 0.5
default hyperparamter: MobileViTv2
- optimizer: AdamW
- L2 weight decay: 0.05
- multi-scale sampler: (256, 256)
- learning rate 처음 2만 iteration동안은 1e-6에서 0.002로 증가하고 그 이후론 cosine schedule을 사용해 0.0002로 annealing한다
- advanced data aug: random resized cropping, horizontal flipping, random augmentation, random erase, mixup, cumix
4.1.2 Comparsion with MobileViTs
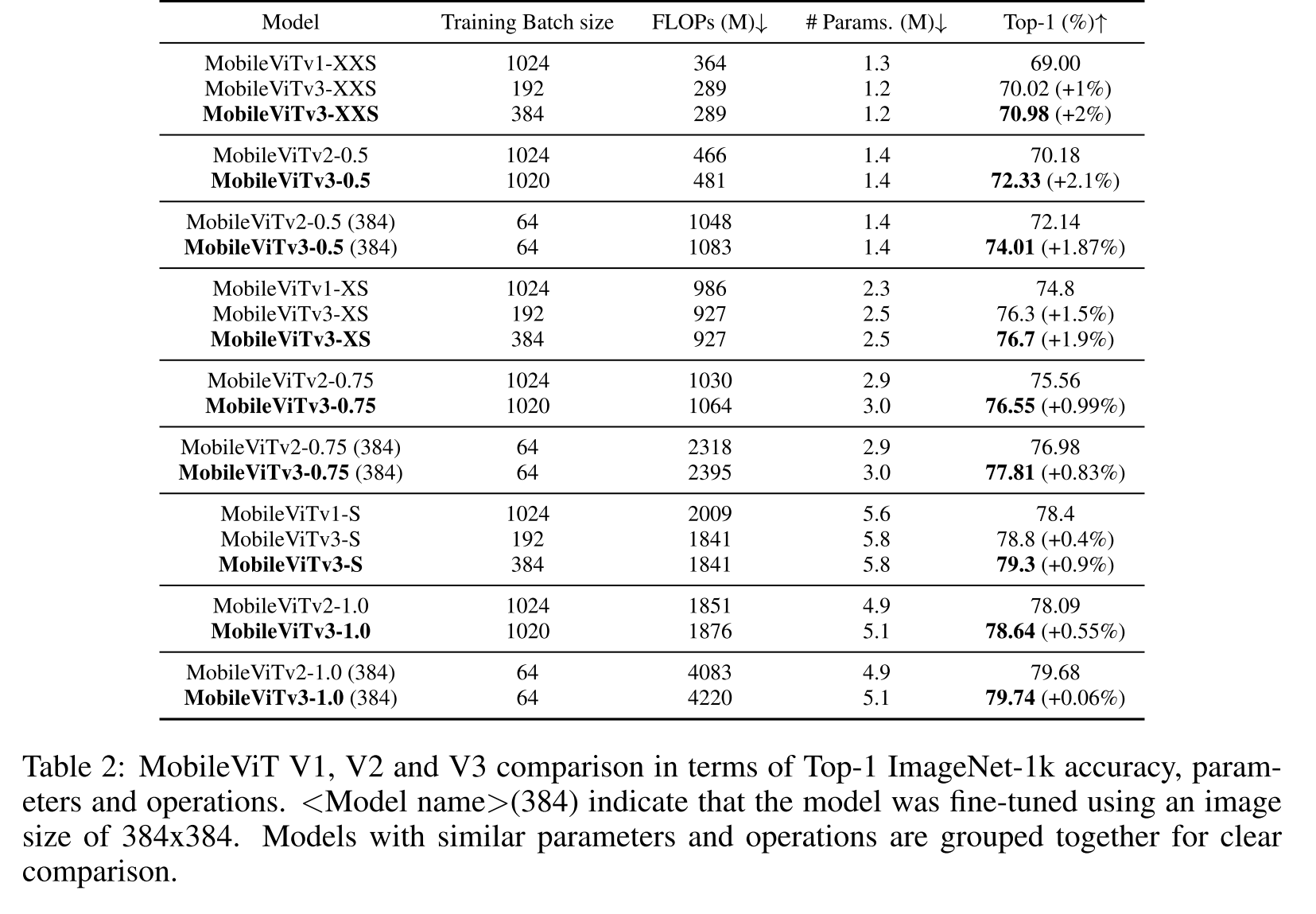
MobileViTv1과는 파라미터를 비슷하게 맞춰주는데 FLOPs가 줄어들고 더 적은 batch size로 성능 앞서고 MobileViTv2와 비교해선 파라미터 수를 비슷하게 맞췄을때 FLOPs가 조금 늘어나는 대신 성능도 앞선다.
4.1.3 Comparsion with ViTs
parameter 2 M 이하: MobileViTv3-XXS, MobileViTv3-0.5가 MobileViT 패밀리의 성능을 모두 앞섰고, MobileViTv3-0.5가 최고
2M ~ 4M: MobileViTv3-XS, MobileViTv3-0.75이 모든 모델에 앞선다
MobileViTv3-XS의 Top-1 accuracy로 비교하면 Mini-DeiT-Ti (2022)보다 3.9% 높고, XCiT-N12 (2021)보다 4.5% 높고, PVTv2-B0 (2022)보다 6.2% 높다. Mobile-Former-53M (2022) 53 GFLOPs만 사용했하긴 했지만, MobileViTv3-XS에 비해 12.7% 정도 뒤쳐진다.
4M ~ 8M: MobileViTv3-S가 최고
Coat-Lite-Tiny (2021)봐다 1.8%, ViL-Tiny-RPB (2021)보다 2.6%, CeiT-Ti (2021)보다 2.9% 성능 향상
8M ~ : basic data aug로 300 epoch 훈련시킨 MobileViTv3-S로 비교했을때, CoaT-Lite-Mini는 약 2배의 parameter수, 비슷한 FLOPs, 더 많은 data augmentation으로 비슷한 정확도, MobileFormer-508M은 더 많은 data augmentation과 450 훈련 epoch에서 3.5배 적은 FLOPs와 2.5배 많은 paramter수로 비슷한 정확도를 달성한다.
ResT-Small (2021), PVTv2-B1 (2022)은 2배 이상 많은 paramter와 비슷한 FLOPs으로 비슷한 성능을 CMT-Ti (2022)는 1.6배 더 많은 paramter와 2.9배 적은 FLOPs로 비슷한 성능을 달성한다.
parameter 줄인 걸로는 최고구나 Mobile-Former와 CMT-Ti는 FLOPs를 더 잘 줄여놓았다..
FLOPs가 연산에 대한 계측으로 치면 FLOPs가 더 실제 속도와 연관있는 거 아닌가...
4.1.4 Comparsion with CNNs
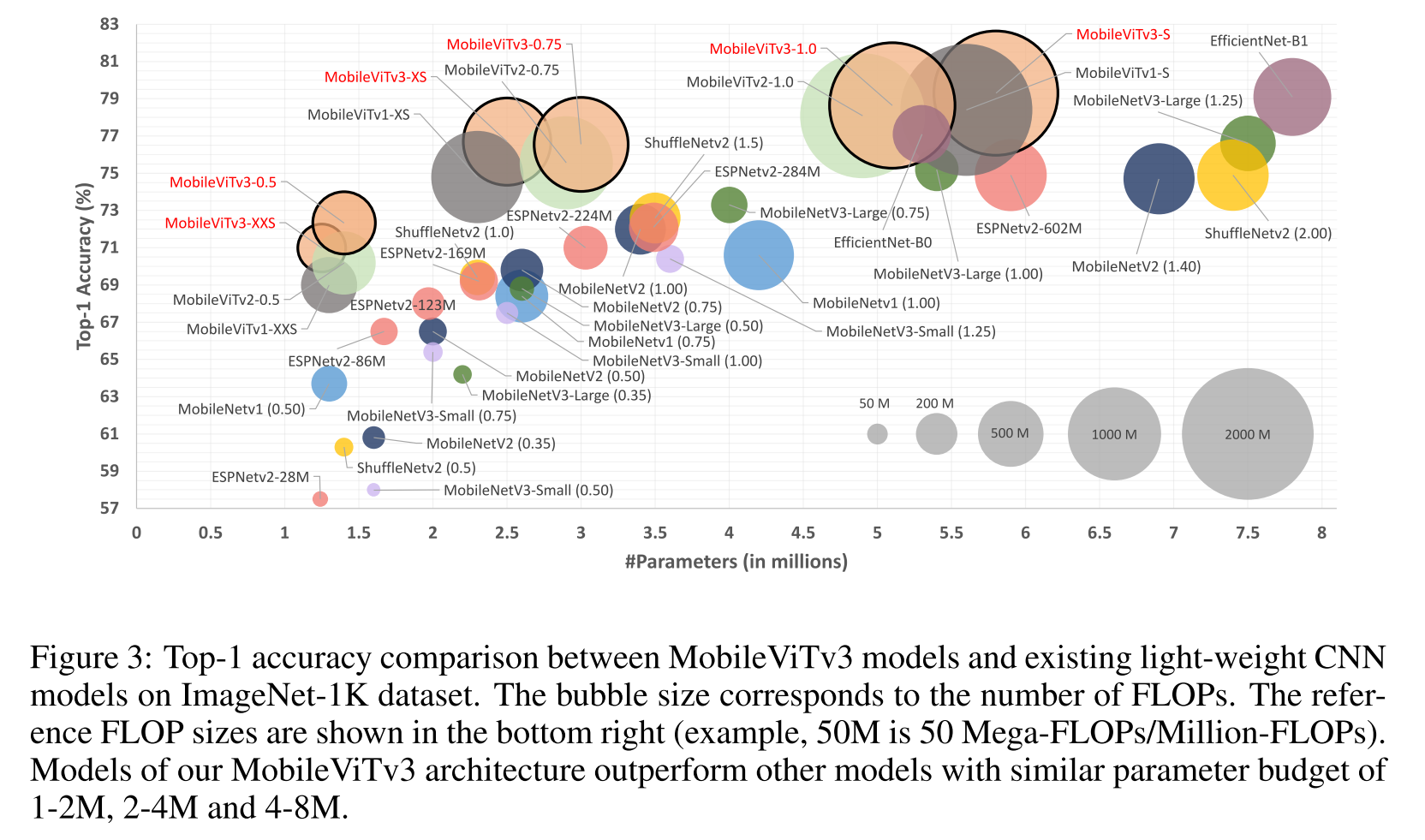
1~2M: MobileViTv3-0.5와 MobileViTv3-XXS가 가장 앞섰고 MobileViTv3-0.5로 비교했을때 MobileNetv3, ShuffleNetv2, ESPNetv2 등 경량화 CNN과 비교하여 2.5% 이상의 성능개선을 이루었다
2~4M: MobileViTv3-XS가 비슷하게 4% 이상의 성능개선을 이루었다.
4~8M: 다른 경량화모델들은 MobileViTv3-S가 2% 이상 성능개선을 이루었는데, EfficientNet-B1은 1.3배 파라미터수는 많지만, FLOPs가 2.6배 더 적은 걸로 비슷한 성능을 내더라
뭔가 실제적인 FLOPs, latency speed에서 비교하면 별로 이득이 없는 모델일 수 있겠는데
4.2 Segmentation
Deeplabv3 (2017)에 결합되는 형태로 사용됨
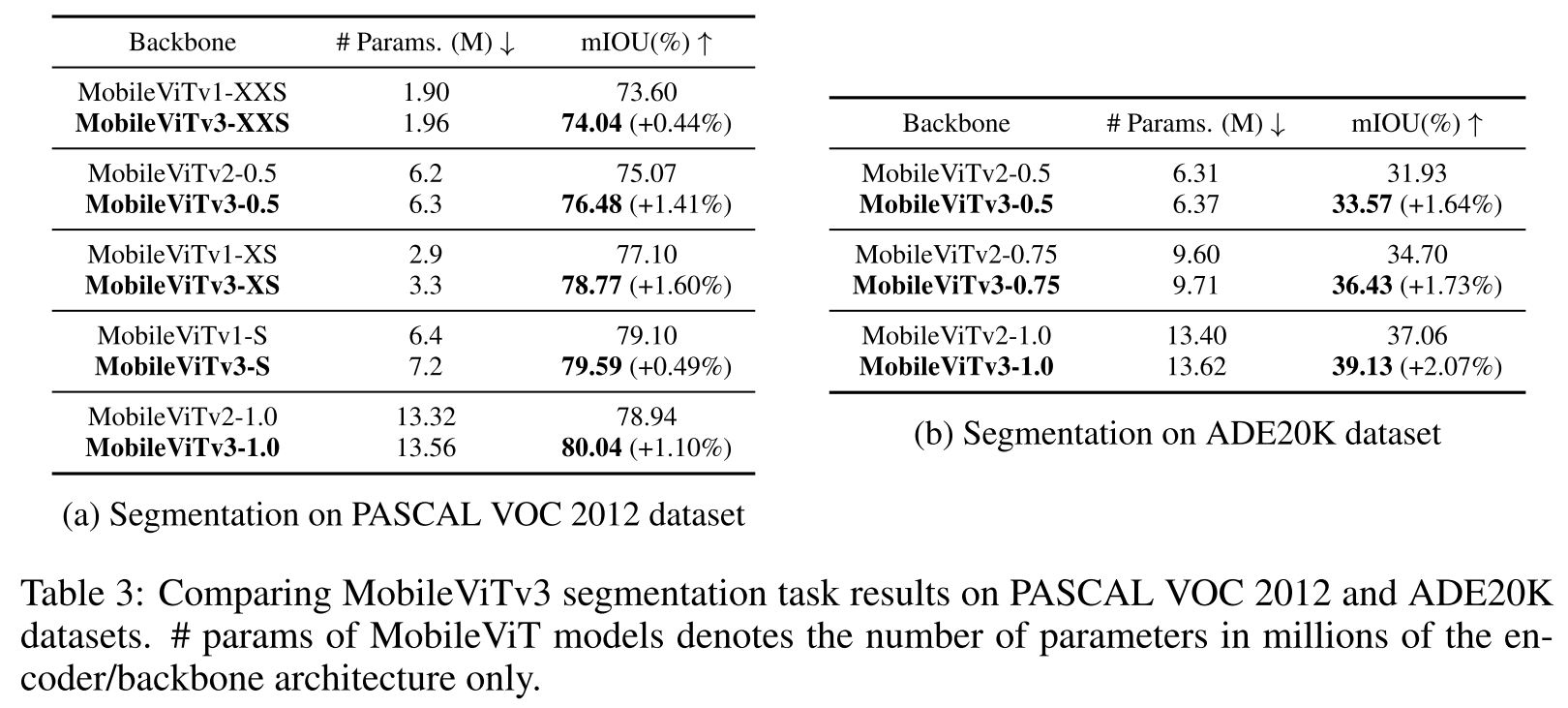
segmentation architecture로 만드니 파라미터수는 MobileNet v1보다도 늘어나지만, 모두 성능향상이 이루어짐
4.3 Object Detection
MS-COCO에서 제안하는 architecture를 head는 Single Shot Detection network (SSD, 2016)의 backbone으로 사용하는데, SSD의 head에 있는 그냥 conv를 separable conv로 대체한 SSDLite network로 개량해서 사용함
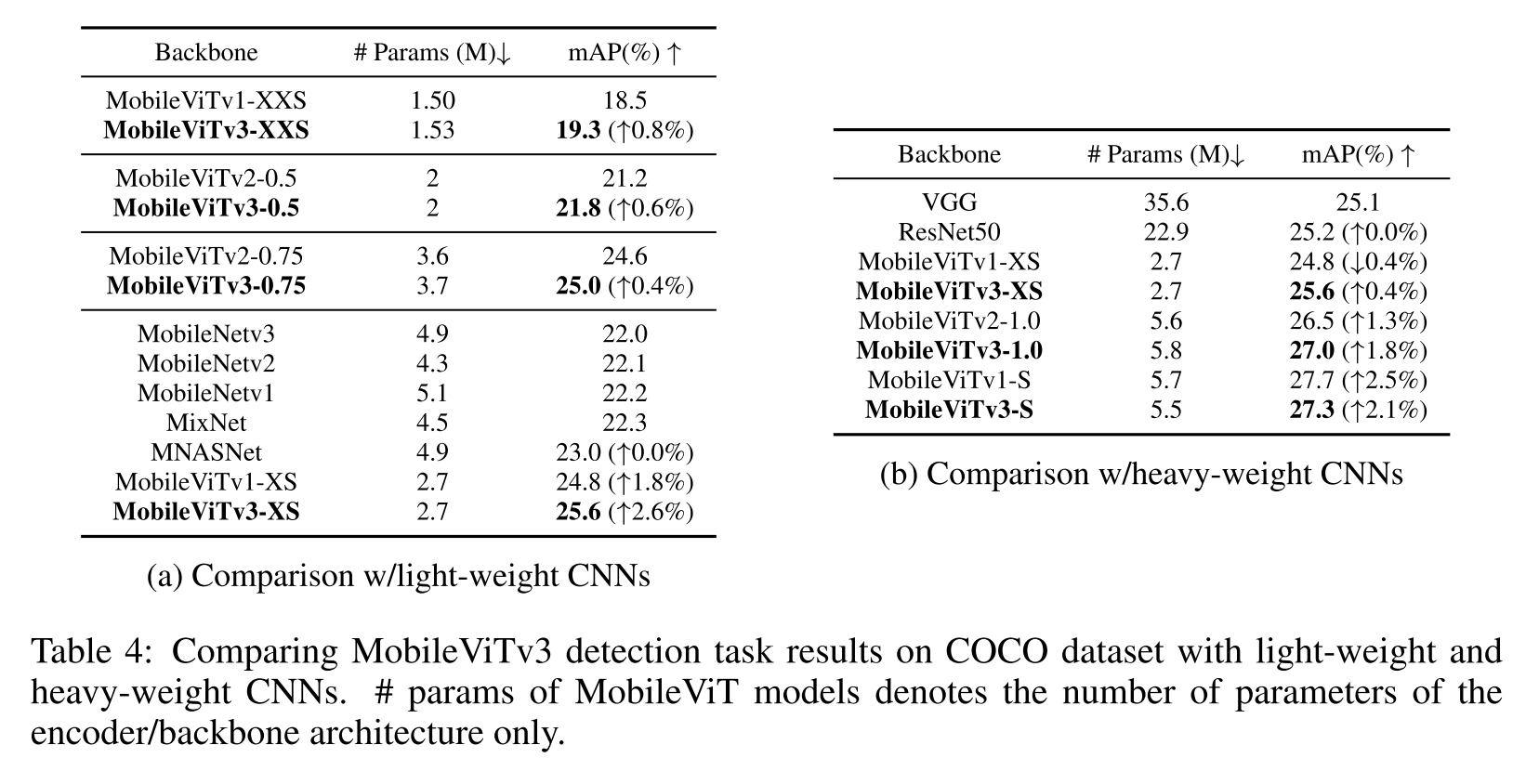
모든 것에서 성능향상이 이루어짐 ResNet50과 비교해서 파라미터수 엄청 작은 거 보여줌
4.4 Improving Latency and Throughput
GeForce RTX 2080 Ti GPU로 10000 iteration한 걸 평균내서 latency 시간 결과를 사용함
throughput은 100 batch size로 1000 iter 돌려서 계산됨
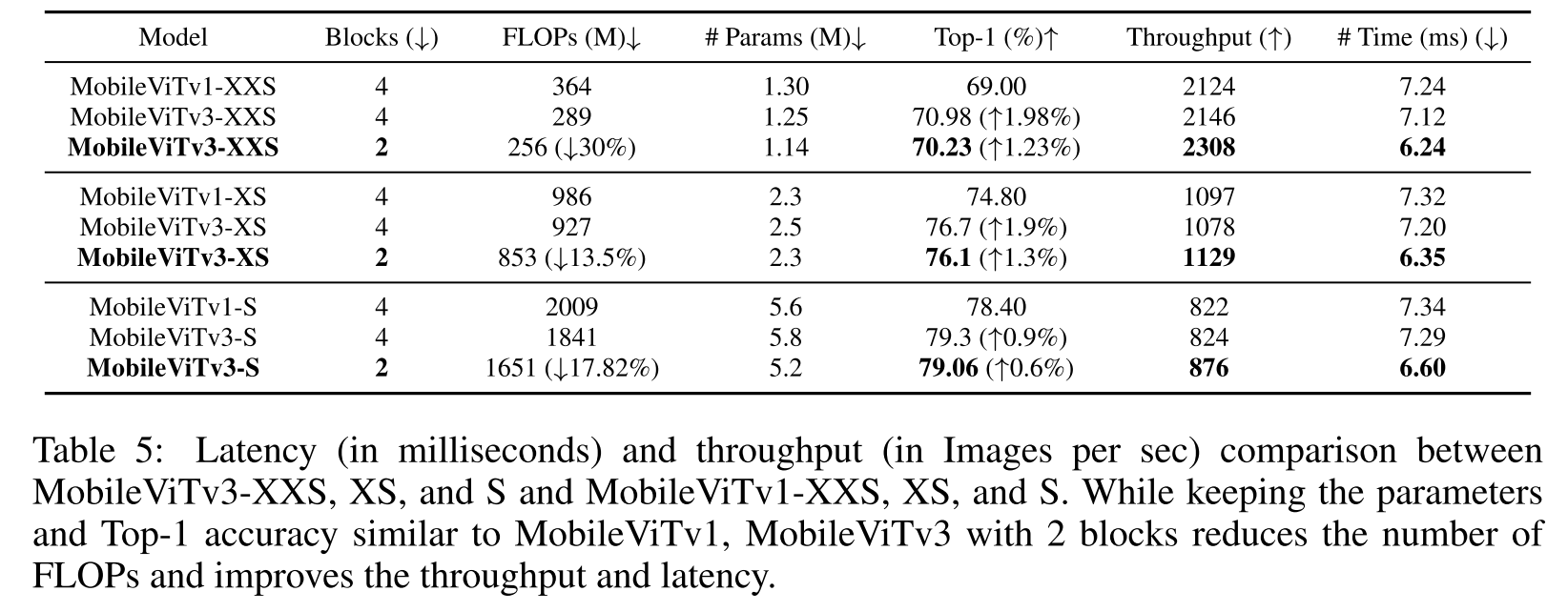
latency (in milliseconds), throughput (images per sec) 모두 향상시켰음
;layer 4'에서의 block 수를 줄여보기도 했는데 MobileViTv1에 비해서 성능을 올리면서도 더욱 빨라졌다
FLOPs 줄어든 걸 강조하는데, FLOPs가 연산속도에 훨씬 관여를 많이 하는 걸 스스로 보여주는 느낌인데..?
4.5 Ablation Study
4.5.2 With 100 Training Epochs

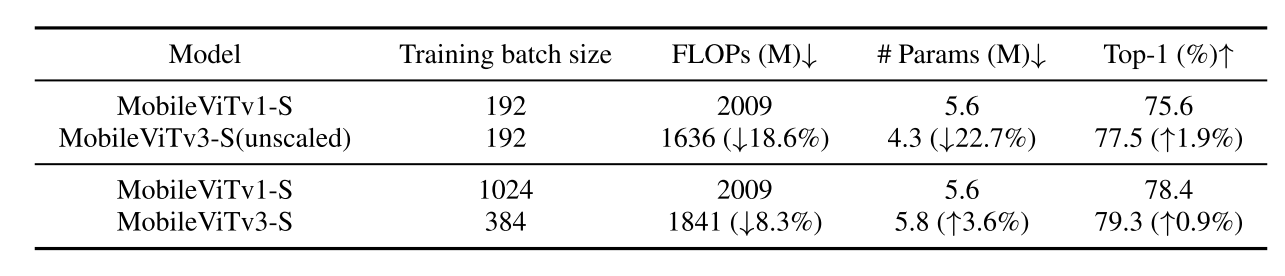
unscaled는 MobileViTv3를 MobileViTv1 파라미터수에 맞춰주려고 channel수를 늘렸던 scaling 작업을 안 하고 MobileNetViTv1의 channel을 그대로 썼다는 것
fusion block에서의 conv는 3x3보다 1x1이 연산량도 줄지만 더 효과가 좋았다..? 각 location에 대한 정보를 훼손하지 않아서 그런가
5. Discussion and Limitation
mobile phone과 같은 resource 제한 환경에서 성능을 개선하는 연구를 했다. 정확도와 throughput을 boosting하면서 memory (parameters), computation (FLOPs), latency를 줄이는 것을 조사했고, 제안하는 MobileViT 아키텍처가 baseline MobileViTv1과 v2에 비교하여 같은 memory와 computation에 가지고 더 높은 성능을 달성했다.
하지만, 경량화 CNN들에 비해 파라미터수는 적거나 비슷하게 좋은 성능을 내는데, FLOPs가 아직 매우 커서 edge device에서는 이슈가 될 수 있다. (MobileFormer, CMT-Ti에 비해서도 FLOPs가 많았음) self-attention block을 최적화하는 쪽으로 탐구할 것이다.
한계에서 말한 것처럼 FLOPs가 한계로 비춰지는데, MobileFormer (MobileNetv3를 합친)나 CMT-Ti (conv stem + conv/transformer alternatively) 를 참고해서 CNN쪽 block을 더 추가하는 쪽으로 self-attention block을 개량하면 뭔가 더 FLOPs를 줄일 수 있을듯,,
하지만, memory (parameter수) 관점에서 가장 efficient한 Hybrid (ViT + CNN) 아키텍처로 고 이점을 가지고 있다.
