[2021 ICIP] Attention toward neighbors: A context aware framework for high resolution image segmentation
Paper Review
주변 패치와의 관계를 계산한 접근방법을 찾다가 DeepAI에서 보게 되었음.


방법 요약: 인코더의 결과인 feature 기준으로 타겟 패치 feature를 query, 타겟 패치와 인접 패치 feature를 concat한 9개의 패치 feature를 key, value로 타겟 패치와 인접 패치와의 공간적 상관관계를 global attention으로 계산하여 이웃 패치의 정보를 포함한 feature를 디코더의 입력으로 사용하는 프레임워크
1. Introduction
고해상도 이미지에서의 segmentation은 여전히 그들의 큰 크기 때문에, 여전히 challenging하다. 전체 이미지를 한 번에 입력으로 넣으면 엄청난 크기의 중간 feature map들 때문에 모델 훈련이 불가능 (impractical) 하다. 이를 완화하기 위해 이미지를 다운샘플링하거나 여러 사각 패치로 나누어 입력으로 사용하는데, 후자의 방법이 시각 정보를 잃어버리지 않기 때문에, 더 좋은 결과를 낸다.
하지만, 패치 기반의 방법은 인접한 패치들의 어떠한 contextual information 없이 모든 패치가 각각 독립적으로 segmentation하게 된다. 경계 픽셀들을 분류하기 위한 정보가 거의 없는 독립된 패치들의 경계에서 오류가 두드러지게 나타나게 된다. 1024x1024 이미지를 256x256로 downsampling하기도 하는데, 고해상도 이미지의 다운샘플링은 분할 에러에 기여하는 중요한 정보 손실을 초래한다.
서로 다른 attention 메커니즘을 이용해 classification과 segmentation task에서 성능을 개선한 연구들도 있었지만, 그 연구들도 독립된 패치들에 한해서 성능을 올렸다.
이러한 기존 방법들의 한계를 극복하고자, 저자들은 인접한 패치의 context information을 조합하여 패치를 분할하는 프레임워크를 제안한다. 구체적으로, 프레임워크는 이웃한 패치들간의 공간적 상호 의존성을 배운다. long-range contextual information을 합쳐 상호의존성을 활용하는 건 특히 대상 패치의 경계에서 더 나은 분할을 할 수 있게 한다.
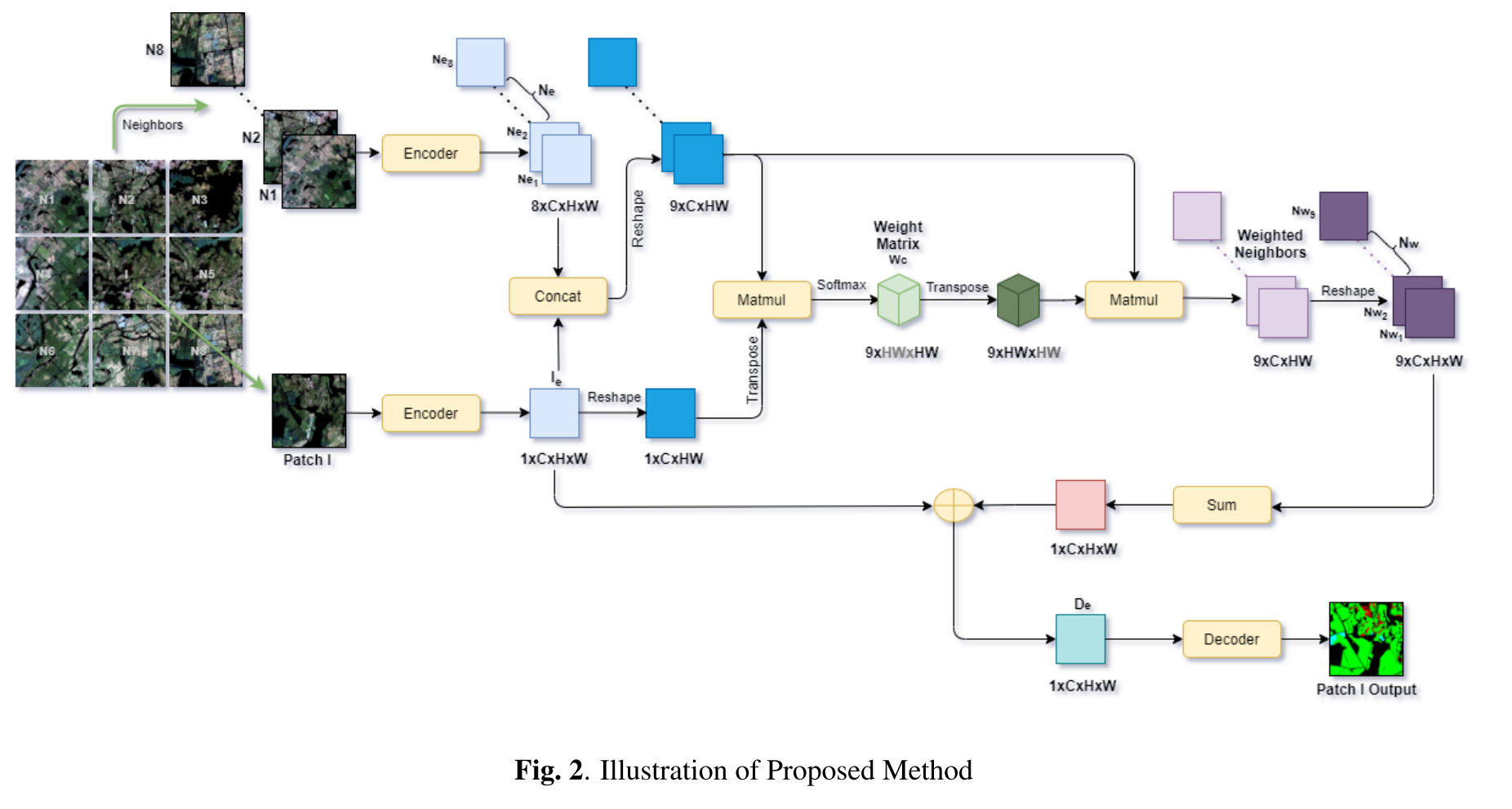
overview는 다음과 같은데, 주변 패치 8개의 feature와 타겟 패치의 feature간의 관계 (spatial interdependencies) 를 배울 수 있도록 attention mechanism을 거치고 그렇게 만들어진 contextual information (1xCxHxW)를 타겟 패치 feature에 더하여 decoder로 보내는 것으로 보인다.
저자들은 세 가지 contribution을 주장함
- 주변 패치의 contextual information을 capture하여 patch 기반 방법을 쉽게 개선하는 attention-based framework을 제안한다.
- JSRT Chest X-ray dataset, Dhaka Satellite Dataset (DSD)에서 제안하는 framework로 베이스라인보다 더 나은 분할 결과를 보였다.
- GID dataset에서는 the state of the art 분할 결과를 냈다.
2. Method
우선, full image를 non-overlapping square patch로 나누고 각 패치를 segment하는 것을 목표로 함. 분할할 패치를 I라고 그 주변에 8개의 이웃 패치가 있음. full image의 경계에 있는 패치들의 경우 zero 값을 가진 패치로 누락된 이웃을 채웠다.
-
패치 I to encoder:
-
neighbors to frozen encoder:
-
sotfmax(matmul(, concat), axis = -1) =
3.1. where 는 위치의 패치 에 대한 위치의 이웃 의 영향을 측정한다.
3.2. 두 위치의 가장 비슷한 feature가 그들간의 correlation을 더 높인다.
3.3. 이 weight 값들은 이웃으로부터 오는 공간적 contextual information의 흐름을 조절하는 gate 역할을 수행한다.
3.4. target 패치 feature를 query, target 패치와 이웃 패치 feature를 concat한 인접한 그룹을 key, value로 두고 이웃간의 상관관계를 유추하는 attention 메커니즘. target 패치의 feature (i, j) 위치 픽셀이 이웃 패치 feature의 어떤 위치 픽셀과 연관성이 깊은가.. -
fusing contextual information: matmul(concat, )
4.1. final weighted neighbors :
4.2. 각 이웃 의 각 픽셀 위치는 나머지 픽셀 위치의 선형결합이다. -
feature for decoder,
5.1. learnable parameter alpha
5.2. 그러므로 는 patch I의 정보와 그를 둘러싼 이웃으로부터 contextual information를 가지게 됨
5.3. 를 decoder input으로 prediction mask를 만듬3. Experiments
실험은 두 가지 파트로 구성된다. 첫번째는 기본 패치 기반 방법들과 제안한 방법을 비교 (on JSRT Chest X-ray, Dhaka Satellite Data (DSD) 하는 것이고 두번째는 GID dataset에서 sota를 달성한 multi-patch 기반 방법과 비교하는 것이다.
result on JSRT Dataset
전체 이미지 크기는 1024x1024, FCN-32와 Deeplab v3+로 비교하였음.
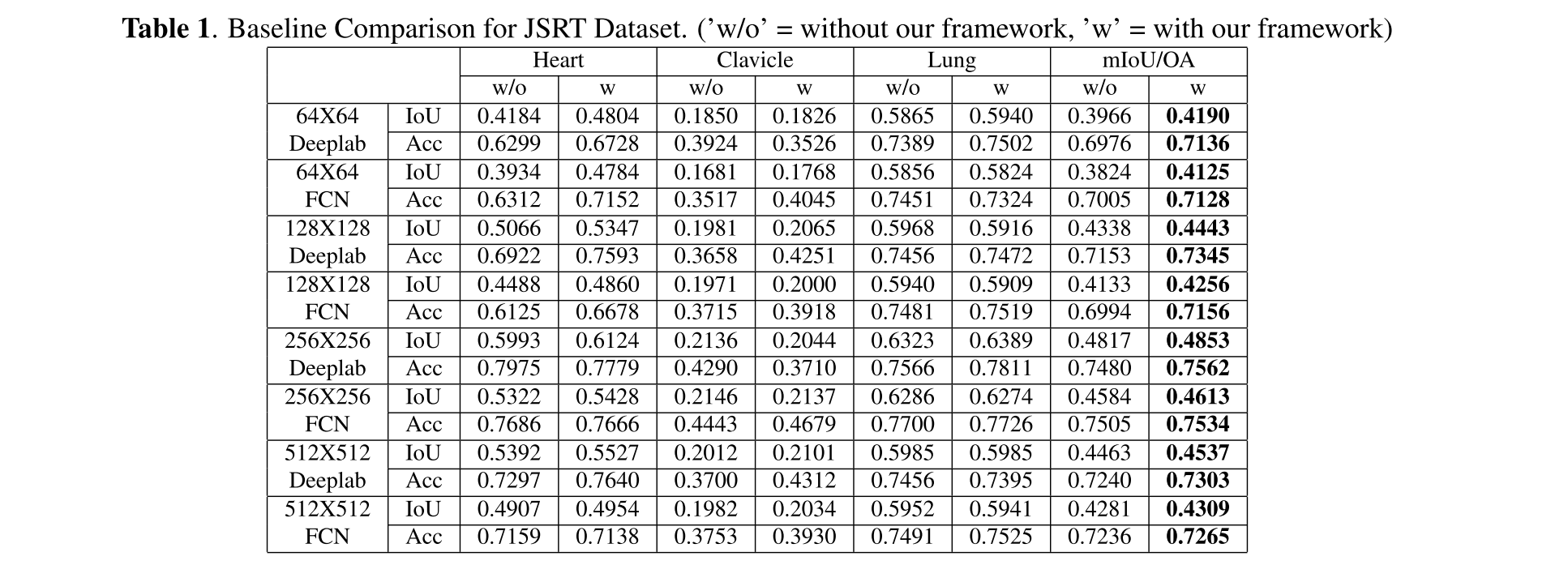
전반적으로 성능을 다 향상시켰다.
기본적으로 256x256이 가장 성능이 좋았는데.. 그럴 이유가 있는 건지..?
result on Dhaka Satellite Dataset
이미지 한 장 크기가 51146x15233
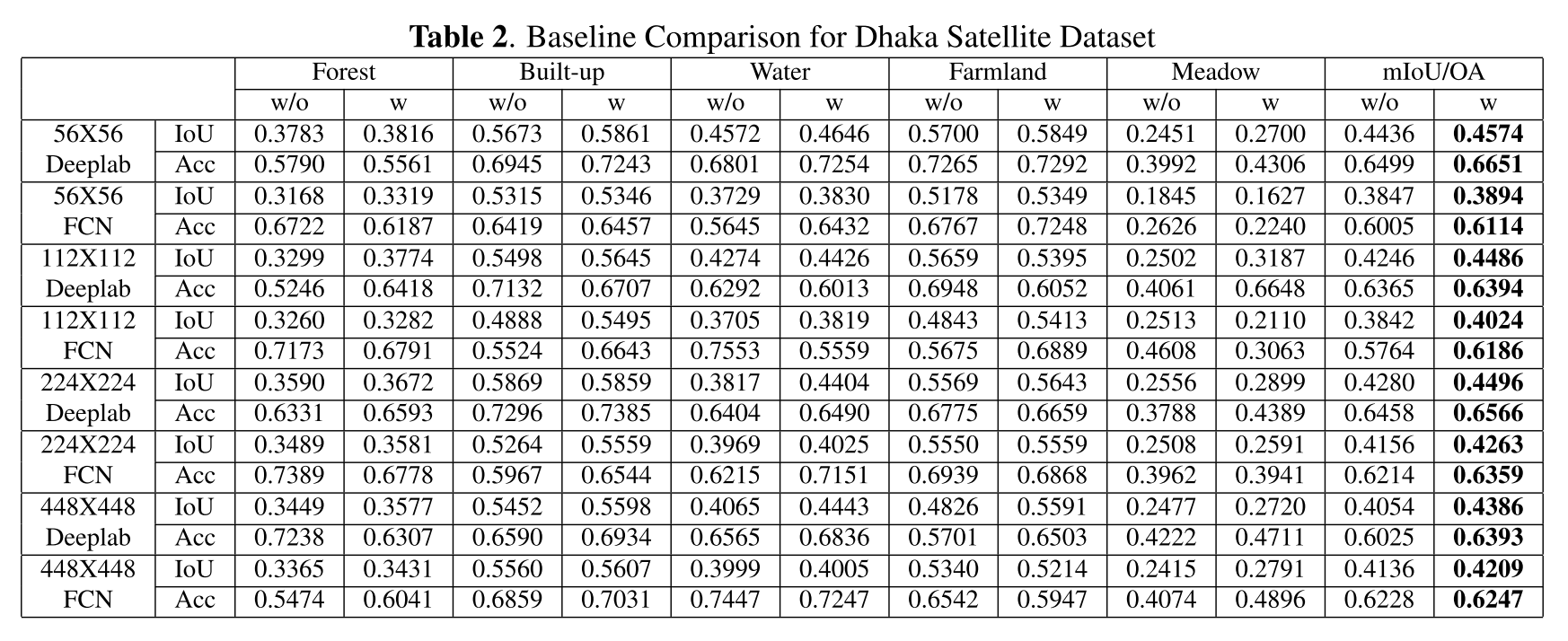
성능향상 폭이 JSRT보다 높아보임.
result on GID
7200X6800 크기의 고해상도 이미지 150장
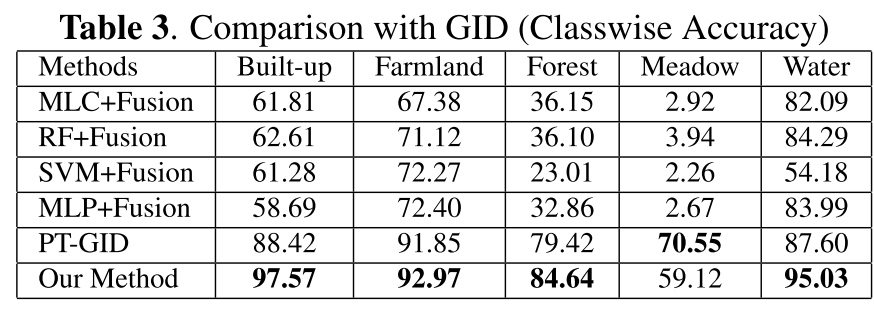
5개 클래스 중 4개에 대해서 기존 sota (PT-GID)를 앞섬. 성능은 다 논문에서 바로 가져왔다고 함.
Meadow는 데이터가 적었고 저자는 아무런 data augmentation을 안 했다고 함
4. Conclusion
이 연구에서 segmentation을 위해 인접 패치의 contextual information을 결합하는 프레임워크를 제안하였다. 다양한 실험에서 target 패치에 대해서 더 넓은 영역을 보게 되어 더 나은 결과를 이끌어냈고 GID dataset에서는 sota 정확도를 개선시켰다.
5. Comments
border에서 못하던 걸 잘하게 되었다거나 주변 패치의 feature와 상관관계를 보여서 segmentation 결과가 바뀌어 맞추는 경우를 예시로 들어줬으면 참 좋았을 것 같다.. 제공하는 정보가 많아진 건 사실이나 실제로 인접한 이웃과의 공간적 상호의존성을 잘 배운 건지는 알 수가 없다.
6. Further Approach
저대로 하면 training하는 데에 엄청 걸릴 것 같다.
패치단위 segmentation network는 훈련 시키다가 어느 정도 saturation 되었을 때, 패치 feature와 주변 패치 feature를 셋팅하고 주변 patch의 feature와의 상관관계를 계산하는 network 모듈 (neighbor context injection module, NCI module)의 output feature를 입력으로 frozen decoder로 통과시켜 target 패치의 ground truth와 비교해서 NCI module만 훈련시키면 훈련도 그렇게 오래 걸리지 않고 특히 inference 때에는 encoder로 feature를 모두 추출해놓고 feature들을 훈련된 NCI module을 통과시켜 decoder로 보내면 돼서 그렇게 오래 걸리지 않을 것으로 생각된다.
이 연구는 패치 경계에서의 error를 지적하고 이를 개선하고자 했는데, 종양 영역을 분할하는 모델에서 개별 독립 패치에서 파악할 수 있는 context가 한정적이어서 판단이 쉽지 않기에 주변의 정보를 주입시켜 인접한 패치임에도 전혀 다른 (inconsistent) 결과를 내보내지 않기 위함이다.
low-level, mid-level, high-level이 있다면 high-level의 feature를 고려해야할 것이다. resolution이 작기 때문에, 굳이 channel 방향으로 concat하지 않고 C x 9H x 9W로 붙여놓고
target patch를 query로 주고 wider view 패치 feature 공간을 k, v로 두고 coarse하게 보고 가까울수록 fine-graind하게 보는 focal attention를 기반으로 module을 만들어볼 수 있을 것 같다.
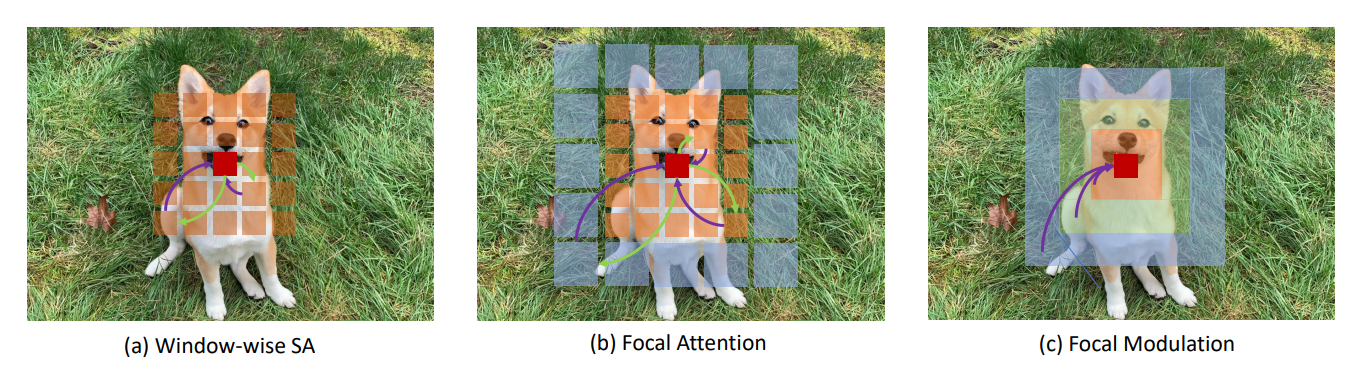
Focal attention이 더 변형된 형태인 Focal modulation networks이 작년에 마이크로소프트에서 나오기도 했다.
