
이번 글에서는 여기서 사용한 데이터셋과 전처리를 이용하여 다른 모델을 만들어 볼 것이다.
이전에서는 BiLSTM을 이용했지만 이번에는 BiLSTM과 CNN을 동시에 이용하여 만들어보자.
이번 내용에서는 단어(Word)와 글자(Character)의 차이를 헷갈리지 않도록 조심하자.
여기서이미 1D CNN을 이용한 텍스트 분류를 진행했던 적이 있다. 이 내용을 잠시 가져와보면
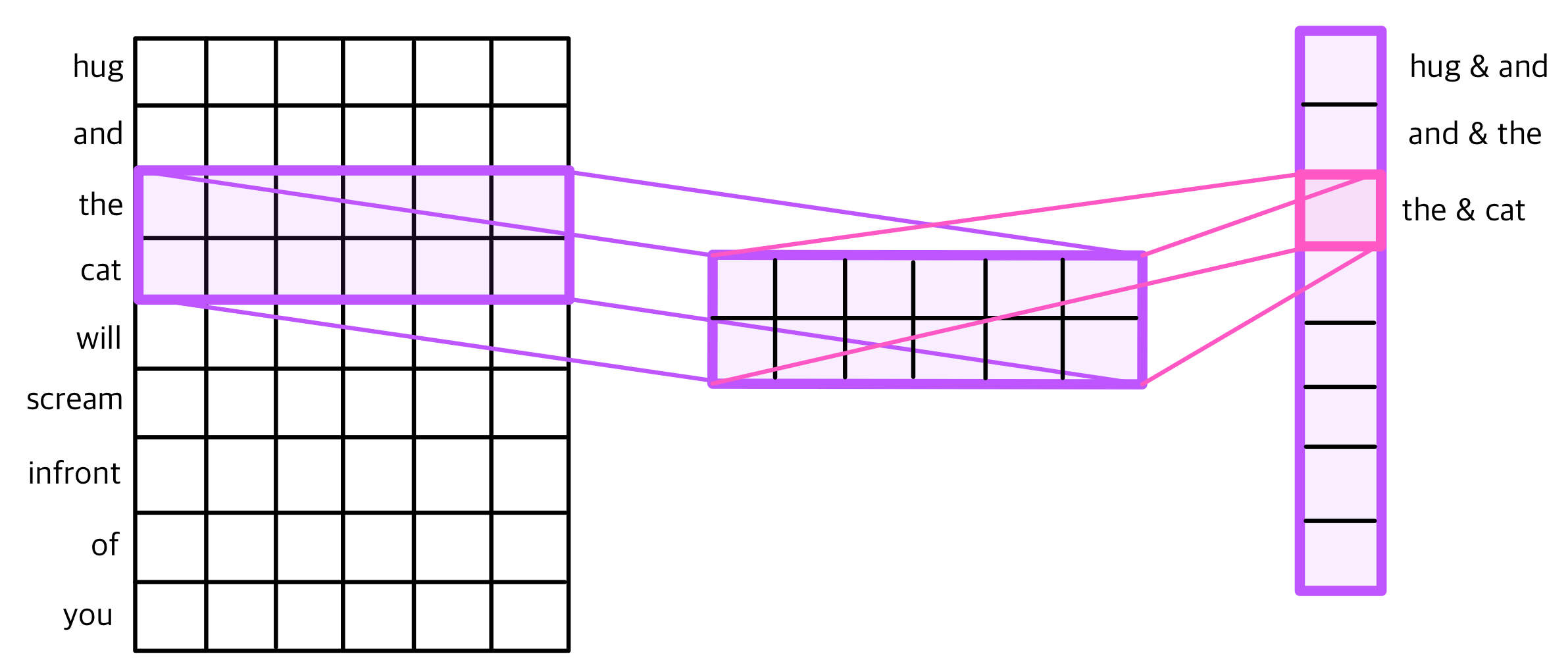
이런 느낌이었다. 이번에는 단어 대신에 글자(char)를 넣게 된다.
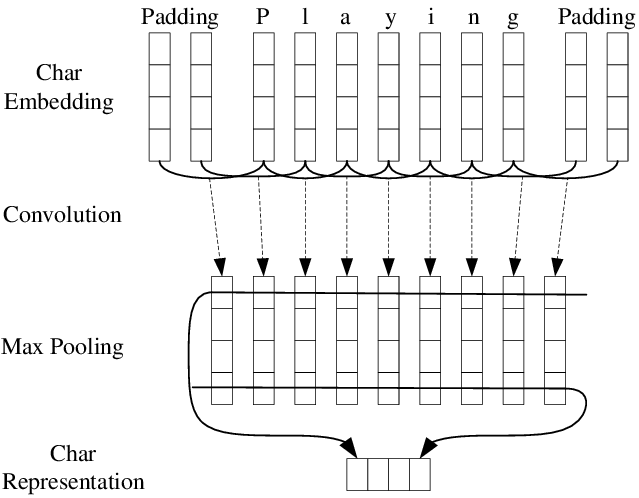
위와 같이 생각하면 된다.
단어를 글자 단위로 분리한 후, 임베딩을 글자에 대해서 하게 된다. 여기서 패딩을 추가적으로 진행할 수 있다. 이후에 1D CNN을 진행하게 된다. 예제에서는 백터가 4개이므로 맥스 풀링을 한 후에는 4개의 스칼라 값을 얻는데, 이렇게 얻은 스칼라 값은 전부 concatenate하여 하나의 벡터로 만들어주게 된다.
이 벡터는 해당 단어의 벡터로 사용된다. 이렇게 글자 벡터는 어떤 단어가 나와도 글자 기준으로 단어를 쪼개기 때문에 OOV문제 (Out of Vocabulary)를 해결할 수 있게 된다.
이전글에서 진행했던 전 처리 작업을 해준 후, 추가적으로 char정보를 사용하기 위해 전처리를 진행해주자.
Data Preprocessing
먼저 Word행에 있는 단어들을 살펴보자.
data["Word"].values
이런 단어들이 있었다.
이제 여기에 나오는 글자들을 쪼개서 글자 사전을 만들어준다.
words = list(set(data["Word"].values))
chars = set([w_i for w in words for w_i in w])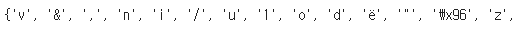
이 집합 안에는 모든 글자와 문자가 들어있다.
이 집합으로부터 글자➡정수 해주는 딕셔너리인 char_to_index와 반대로 정수➡글자 해주는 딕셔너리인 index_to_char를 만들어주자.
char_to_index = {c: i + 2 for i, c in enumerate(chars)}
char_to_index["OOV"] = 1
char_to_index["PAD"] = 0
index_to_char = {}
for key, value in char_to_index.items():
index_to_char[value] = key그리고 인코딩을 해줘서 한 글자에 대해 숫자로 나타낼 수 있게 하자.
max_len_char = 15 #한 단어의 길이가 15 안넘음
def padding_char_indice(char_indice, max_len_char):
return pad_sequences(
char_indice, maxlen=max_len_char, padding='post',
value = 0)
def integer_coding(sentences):
char_data = []
for ts in sentences:
word_indice = [word_to_index[t] for t in ts]
char_indice = [[char_to_index[char] for char in t]
for t in ts]
char_indice = padding_char_indice(char_indice, max_len_char)
for chars_of_token in char_indice:
if len(chars_of_token) > max_len_char:
print("최대 단어 길이 초과!")
continue
char_data.append(char_indice)
return char_data여기서 max_len_char는 단어의 최대 길이가 15 이상이면 끊겠다는 얘기다.
sentences를 이 integer_coding함수에 넣어줘서 모든 단어를 인코딩해주자.
X_char_data = integer_coding(sentences)이제 이전에 구해놨던 X_data[0]의 출력값을 확인해보자.

254가 의미하는 단어는 뭐였을까?
sentences[0]을 확인해보면 알 수 있다.
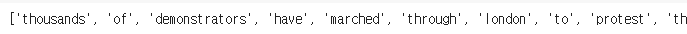
첫번째 글자인 thousands가 254를 의미할 것이다.
방금 전에 단어를 글자로 인코딩 했었다. X_char_data[0]을 출력해서 어떻게 바뀌었는지 확인해보자.

thousands라는 글자는 맨 첫번째줄인
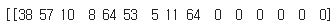
이 부분으로 바뀌었다.
실제로 확인해보면 38이라는 숫자는 t, 57이라는 숫자는 h로 인코딩 되었다. 64가 두번 나왔다는 것으로 s가 두번 잘 인코딩 되었다는 사실을 알 수 있기도 하다.
그렇지만 여기서 문제가 있다. X_data는 최대 길이를 70으로 설정해놓아서 그것보다 적으면 0으로 패딩해줬는데, 여기서는 0으로 패딩된 단어에 대해 무시되었다.
따라서 문장 길이 방향으로도 패딩을 해 줘야 한다.
X_char_data = pad_sequences(X_char_data, maxlen=max_len, padding='post', value = 0)다시 X_char_data를 출력하면
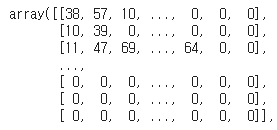
전체 부분이 출력되지는 않지만 뒤에 0으로 패딩되었던 부분까지 출력된 것을 확인할 수 있다.
단어 단위 인코딩 결과로는 이미 test와 train세트로 분리가 되었다. 이번에는 같은 방법으로 글자 단위 인코딩 결과를 분리해보자.
X_char_train, X_char_test, _, _ = train_test_split(X_char_data, y_data, test_size=.2, random_state=777)길이를 확인해보면 2:8 비율로 분리되었다.
배열로 변환해주고 출력해보자.
X_char_train = np.array(X_char_train)
X_char_test = np.array(X_char_test)X_char_train[0][0]를 출력해서 확인해보았다.
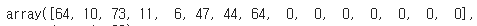
이런 배열이 나왔는데 어떤 글자인지 궁금하니 확인해보자.
print(index_to_char[11])11숫자 대신 원하는 인코딩 숫자를 넣으면 해당 글자가 나온다.
반복하여 구해보았더니 X_char_train[0][0]는 soldiers라는 글자로 출력되었다.
print(' '.join([index_to_char[index] for index in X_char_train[0][0]]))위 코드로도 원하는 위치의 글자를 확인할 수 있다.
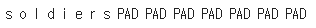
이런 출력결과를 얻을 수 있다.
여기서 글자 임베딩에 대한 전처리 설명을 마친다.
Build Model
이제 모델을 빌드해보자.
Packages
from keras.layers import Embedding, TimeDistributed, Dropout, concatenate, Bidirectional, LSTM, Conv1D, Dense, MaxPooling1D, Flatten
from keras import Input, Model
from keras.initializers import RandomUniform
from keras.callbacks import EarlyStopping, ModelCheckpoint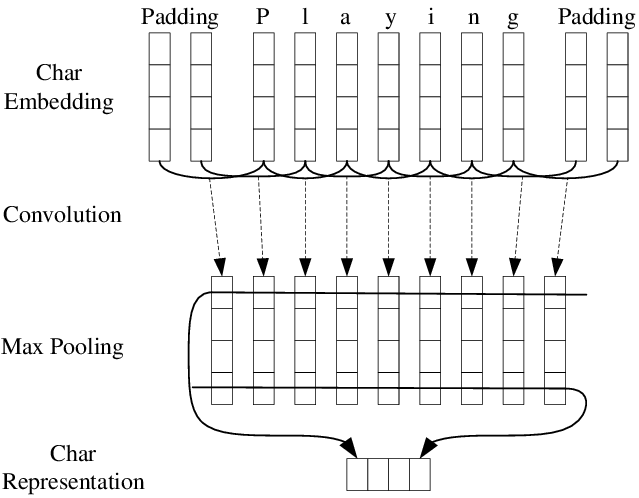
단어 임베딩을 해주고,
글자 임베딩을 해 준다.
그리고 글자 임베딩에 대해 Con1D를 수행시킨 후 단어 임베딩과 연결시켜준다. (사진의 마지막 단계)
마지막으로 concatenate한 벡터를 가지고 문장의 길이만큼 LSTM을 수행한다.
출력층까지 넣어주고 .summary로 모델을 확인해보자.
# 단어 임베딩
words_input = Input(shape=(None,),dtype='int32',name='words_input')
words = Embedding(input_dim = vocab_size, output_dim = 64)(words_input)
# char 임베딩
character_input = Input(shape=(None, max_len_char,),name='char_input')
embed_char_out = TimeDistributed(Embedding(len(char_to_index), 30, embeddings_initializer=RandomUniform(minval=-0.5, maxval=0.5)), name='char_embedding')(character_input)
dropout = Dropout(0.5)(embed_char_out)
# char 임베딩에 대해서는 Conv1D 수행
conv1d_out= TimeDistributed(Conv1D(kernel_size=3, filters=30, padding='same',activation='tanh', strides=1))(dropout)
maxpool_out=TimeDistributed(MaxPooling1D(max_len_char))(conv1d_out)
char = TimeDistributed(Flatten())(maxpool_out)
char = Dropout(0.5)(char)
# char 임베딩을 Conv1D 수행한 뒤에 단어 임베딩과 연결
output = concatenate([words, char])
# 연결한 벡터를 가지고 문장의 길이만큼 LSTM을 수행
output = Bidirectional(LSTM(50, return_sequences=True, dropout=0.50, recurrent_dropout=0.25))(output)
# 출력층
output = TimeDistributed(Dense(tag_size, activation='softmax'))(output)
model = Model(inputs=[words_input, character_input], outputs=[output])
model.compile(loss='categorical_crossentropy', optimizer='nadam', metrics=['acc'])
model.summary()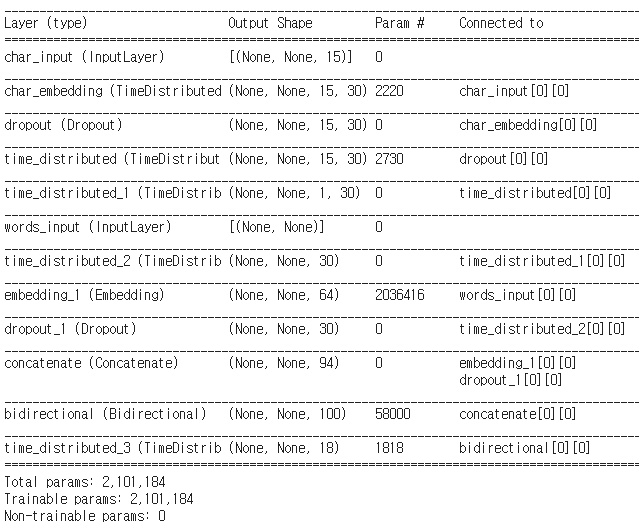
이번에는 학습할 때, Early Stopping과 Model Checkpoint라는 함수를 사용할 것이다. 각각의 인자는 위 링크를 통해 확인할 수 있다.
너무 많은 Epoch 은 overfitting 을 일으킨다. 하지만 너무 적은 Epoch 은 underfitting 을 일으킨다.이런 상황에서 Epoch 을 어떻게 설정해야하는가? 에 대한 대답이 되어줄 수 있다.
Epoch 을 정하는데 많이 사용되는 Early stopping 은 무조건 Epoch 을 많이 돌린 후, 특정 시점에서 멈추는 것이다.
그리고 Model Checkpoint는 모델이 학습하면서 정의한 조건을 만족했을 때 그 모델의 가중치값을 저장해준다.
es = EarlyStopping(monitor='val_loss', mode='min', verbose=1, patience=4)
mc = ModelCheckpoint('bilstm_cnn.h5', monitor='val_acc', mode='max', verbose=1, save_best_only=True)그리고 모델을 학습해준다.
history = model.fit([X_train, X_char_train], y_train, batch_size = 128, epochs = 10, validation_split = 0.1, verbose = 1, callbacks=[es, mc])그래프를 그려보자.
epochs = range(1, len(history.history['val_loss']) + 1)
plt.plot(epochs, history.history['loss'])
plt.plot(epochs, history.history['val_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'val'], loc='upper left')
plt.show()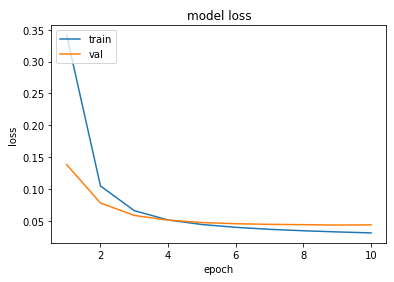
여기서 나온 정확도는 98.7%이다.
하지만 이전에도 언급했다시피 이 방법은 정확하지 않다.
F1-Score방식을 이용하여 정확도를 측정해보자.
F1-Score
이 방법을 사용하기 위해서는 !pip install seqeval을 이용하여 seqeval을 설치해주는 것을 잊지말자.
def sequences_to_tag(sequences): # 예측값을 index_to_ner를 사용하여 태깅 정보로 변경하는 함수.
result = []
for sequence in sequences: # 전체 시퀀스로부터 시퀀스를 하나씩 꺼낸다.
temp = []
for pred in sequence: # 시퀀스로부터 예측값을 하나씩 꺼낸다.
pred_index = np.argmax(pred) # 예를 들어 [0, 0, 1, 0 ,0]라면 1의 인덱스인 2를 리턴한다.
temp.append(index_to_ner[pred_index].replace("PAD", "O")) # 'PAD'는 'O'로 변경
result.append(temp)
return resulty_predicted = model.predict([X_test, X_char_test])
pred_tags = sequences_to_tag(y_predicted)
test_tags = sequences_to_tag(y_test)from seqeval.metrics import precision_score, recall_score, f1_score, classification_report
print(classification_report(test_tags, pred_tags))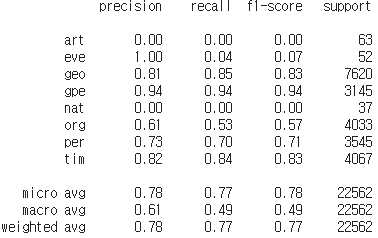
이런 출력값이 뜨고 정확도는 78.0%가 나온다.
