
우선 제목에서의 1D Multi kernel이 무엇인지 알아보자.
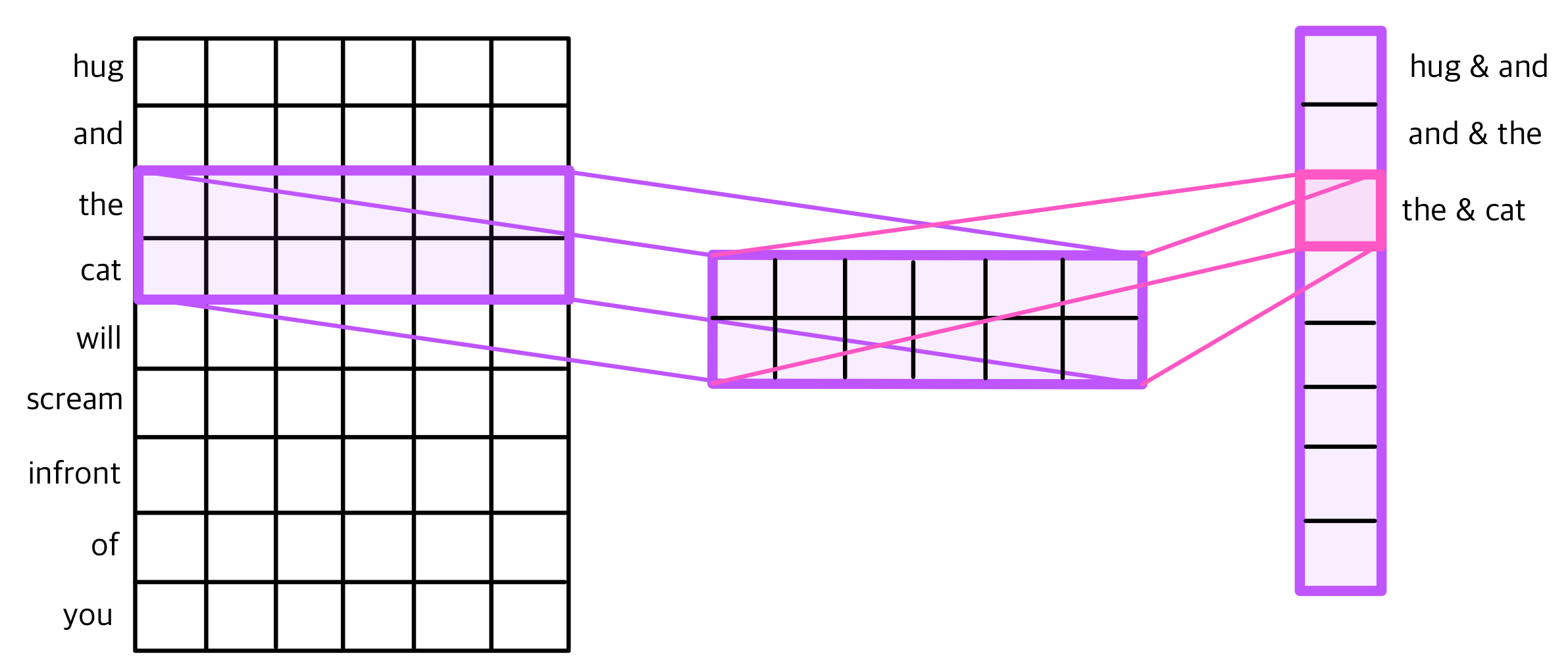
위 그림은 커널이라는 행렬로 임베딩 행렬의 가장 맨 위 부터 가장 맨 아래까지 순차적으로 훑으면서 겹쳐지는 부분의 임베딩 행렬과 커널의 원소의 값을 곱하여, 모두 더한 값을 출력으로 한다. 위 그림의 예시는 the와 cat 두 단어의 행렬이 겹쳐질 때 그 부분을 가져와 마지막에 하나의 윈도우로 반환한다. 이처럼 한쪽 방향으로만 행렬이 진행되는 것을 1D Multi Kernal이라고 한다.
커널은 제일 왼쪽 그림처럼 (위 그림에서는 2*6 행렬) 윈도우를 말하는데, 이 커널의 크기가 커질수록, 좀 더 많은 단어들을 한번에 참고할 수 있을 것이다.
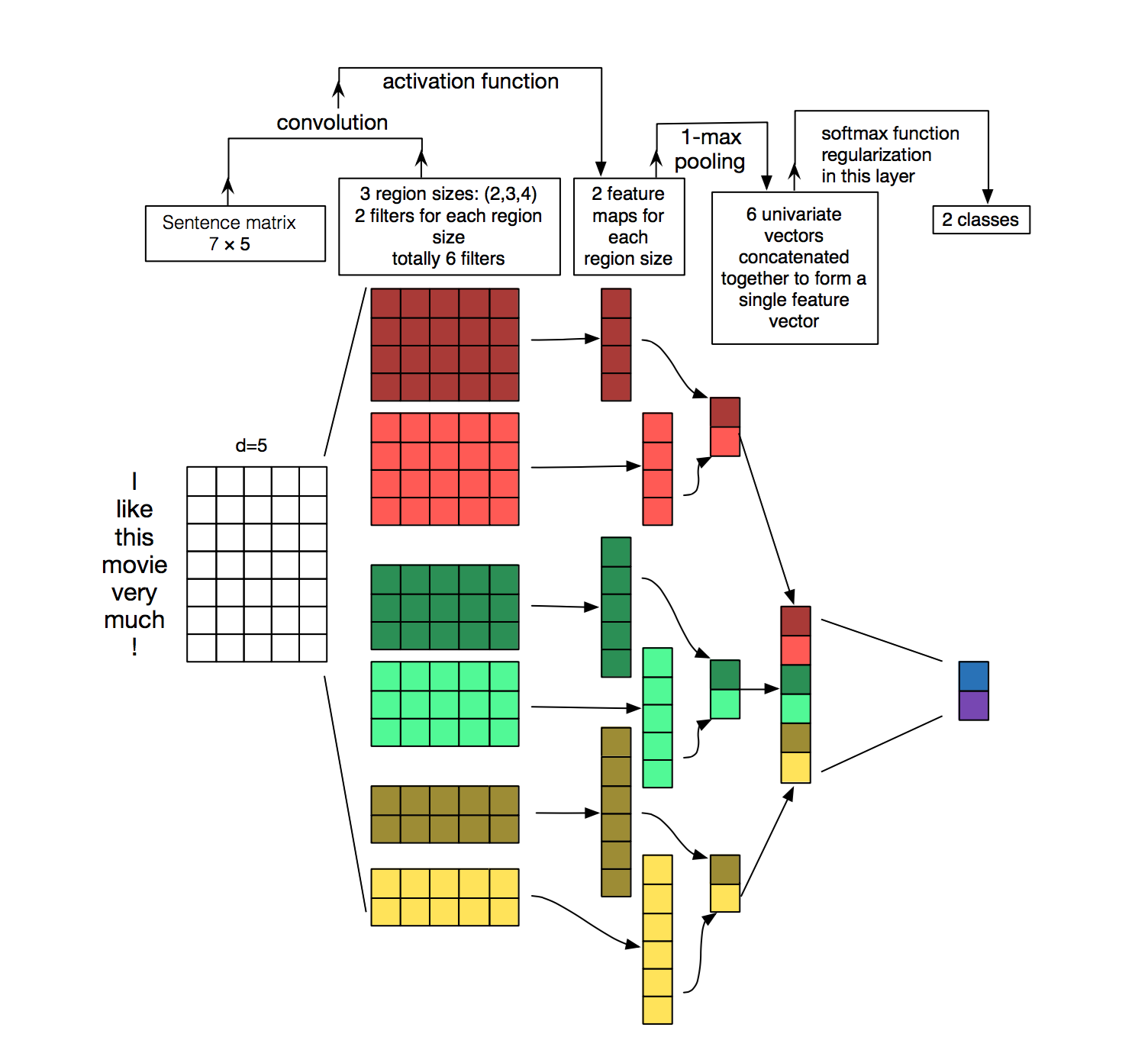
예시를 보자.
여기서는 4개짜리 3개짜리 2개짜리 필터가 각각 두개씩 존재한다.
위 그림에서 1D의 파라미터 개수를 세어보면, 매 칸마다 가중치가 붙는다. 각각 칸의 개수를 세어보자. (2x4x5 + 2x3x5 + 2x2x5 = 90) 에다가 각 필터마다 bias가 있으므로 90 + 6 = 96개의 파라미터가 존재한다.
이제 이 내용을 가지고 네이버 영화 리뷰를 분류해보자.
packages
Okt를 사용해주기 위해 konlpy를 설치해주자.
pip install konlpy패키지를 다운받아준다.
import pandas as pd
import numpy as np
%matplotlib inline
import matplotlib.pyplot as plt
import re
import urllib.request
from konlpy.tag import Okt
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences전처리를 해주자.
Data Preprocessing
트레이닝 데이터와 테스트 데이터를 가져와준다.
urllib.request.urlretrieve("https://raw.githubusercontent.com/e9t/nsmc/master/ratings_train.txt", filename="ratings_train.txt")
urllib.request.urlretrieve("https://raw.githubusercontent.com/e9t/nsmc/master/ratings_test.txt", filename="ratings_test.txt")train_data = pd.read_table('ratings_train.txt')
test_data = pd.read_table('ratings_test.txt')내용물을 확인할 차례이다.
train_data개수를 확인해보자.
len(train_data)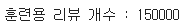
15만개가 나온다.
내용을 확인해보자.
train_data[:5]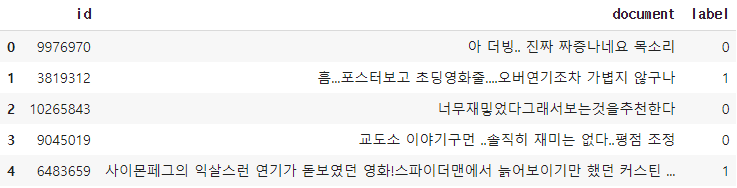
동일한 방법으로 test_data길이와 내용을 확인해보자.


이제 중복 샘플이 있는지 없는지 확인해보자.
train_data['document'].nunique(), train_data['label'].nunique()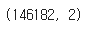
여기서 2는 레이블 개수 즉, 0과 1을 의미한다.
146182개의 중복 없는 샘플이 있다.
아까 위해서 150000개의 샘플이 있다고 했으니까 약 3818개의 중복 샘플이 존재한다. 중복 샘플을 제거하자.
train_data.drop_duplicates(subset=['document'], inplace=True)다시 train_data의 길이를 확인해보면

146183개를 확인할 수 있다.
이제 0과 1로 태그에 샘플이 각각 몇개씩 있는지 bar형태로 확인해보자.
train_data['label'].value_counts().plot(kind = 'bar')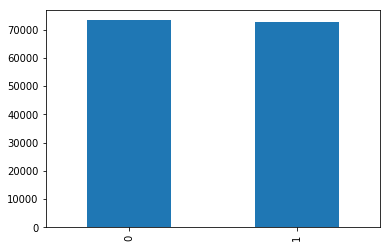
각각 몇개씩인지 확인하고 싶으면 아래 코드를 실행시키면 된다.
print(train_data.groupby('label').size().reset_index(name = 'count'))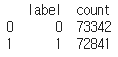
태그0에는 73342개가, 태그1에는 72841개의 샘플이 존재한다.
이제 Null값을 가진 샘플이 있는지 확인해보자.
print(train_data.isnull().values.any())
비어져있는 값도 같이 제거해줘야 하므로 어느 칸에 Null값이 존재하는지 확인해봐야 한다.
print(train_data.isnull().sum())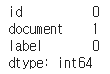
Document열에 빈값이 존재한다.
그 행을 찾아서 확인해보자.
train_data.loc[train_data.document.isnull()]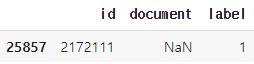
Null값이 존재하는 이 행을 지워주자.
train_data = train_data.dropna(how = 'any')이어서 아까 실행했던 코드로 Null값이 존재하는지 확인해보자.
print(train_data.isnull().values.any())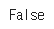
이번에는 False가 뜬다.
train_data의 길이는 아마 146182일 것이다.
다음으로 한글과 공백을 제외한 모든 글자를 제거해보자.
전처리 작업에 꼭 필요한 단계이다.
train_data['document'] = train_data['document'].str.replace("[^ㄱ-ㅎㅏ-ㅣ가-힣 ]","")앞에 5개 샘플만 확인해보자.
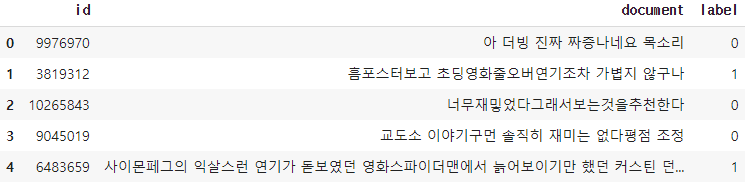
이것저것 지우고 났으니 아마 몇개 샘플엔 아무것도 남아있지 않을 수도 있다. 위의 작업을 반복해서 Null값을 가진 샘플들을 지워주자. 그렇게 되면 145393개의 샘플만 남는다.
위에서 해줬던 작업들을 요약하면 총 5가지의 단계가 된다.
- document열에서 중복인 내용 제거
- 한글과 띄어쓰기 이외의 내용 제거
- 공백이 있다면 empty값으로 변경
- 공백이 있다면 Null값으로 변경
- Null값 제거
이 작업을 테스트 데이터에도 똑같이 전처리 해 준다.
test_data.drop_duplicates(subset = ['document'], inplace=True) # document 열에서 중복인 내용이 있다면 중복 제거
test_data['document'] = test_data['document'].str.replace("[^ㄱ-ㅎㅏ-ㅣ가-힣 ]","") # 정규 표현식 수행
test_data['document'] = test_data['document'].str.replace('^ +', "") # 공백은 empty 값으로 변경
test_data['document'].replace('', np.nan, inplace=True) # 공백은 Null 값으로 변경
test_data = test_data.dropna(how='any') # Null 값 제거
print('전처리 후 테스트용 샘플의 개수 :',len(test_data))마지막으로 test_data의 길이를 출력한 값은

48852가 나온다.
tokenization
토큰화를 해준다.
데이터 양을 줄이기 위해서 stopwords를 추가하여 해당하는 단어들을 제거한다. stopwords에 들어가는 단어들은 정의되어있지 않아서 여기서는 임의로 몇개를 사용한다. 실제 서비스할 때에는 경과에 따라 특정 조사나 접속사를 다시 추가하거나 제거하기도 한다.
여기서는 아래 단어들을 stopwords안에 넣겠다.
stopwords = ['의','가','이','은','들','는','좀','잘','걍','과','도','를','으로','자','에','와','한','하다']한국어를 토큰화하기 때문에 여기서는 Okt를 사용한다.
okt = Okt()Document안에 있는 단어들을 Okt를 사용하여 토큰화를 한 다음, stopwords에서 정의한 불용어를 제거하고 남은 단어들을 X_train안에 넣자.
X_train = []
for sentence in train_data['document']:
temp_X = okt.morphs(sentence, stem=True)
temp_X = [word for word in temp_X if not word in stopwords]
X_train.append(temp_X)X_train 세개만 확인해보자.
[['아', '더빙', '진짜', '짜증나다', '목소리'], ['흠', '포스터', '보고', '초딩', '영화', '줄', '오버', '연기', '조차', '가볍다', '않다'], ['너', '무재', '밓었', '다그', '래서', '보다', '추천', '다']]동일하게 test_data안의 샘플들한테도 토큰화를 해준다.
X_test = []
for sentence in test_data['document']:
temp_X = okt.morphs(sentence, stem=True)
temp_X = [word for word in temp_X if not word in stopwords]
X_test.append(temp_X)Integer Encoding
이제 텍스트를 숫자로 바꿔주는 정수 인코딩 작업을 해 줘야 한다.
케라스에서 가져온 Tokenizer패키지에서 다해준다.
tokenizer = Tokenizer()
tokenizer.fit_on_texts(X_train)끝이다.
알아서 단어 집합(tokenizer.word_index)을 만들어주고 안에 레이블까지 다 해준다. 출력해서 확인해보자.
print(tokenizer.word_index)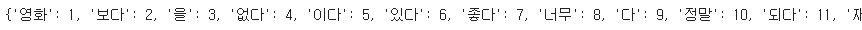
마지막까지 확인해보면 43752번까지 있다.
이는 빈도수가 높은 글자 순서대로 번호가 주어지기 때문에 숫자가 클 수록 빈도수가 낮은 글자들이다.
글자 수를 제한하기 위해서, 등장 빈도수가 3회 미만(2회 이하)인 단어들이 전체 데이터에서 얼만큼의 비중을 차지하는지 확인해보자.
threshold = 3
total_cnt = len(tokenizer.word_index) # 단어의 수
rare_cnt = 0 # 등장 빈도수가 threshold보다 작은 단어의 개수를 카운트
total_freq = 0 # 훈련 데이터의 전체 단어 빈도수 총 합
rare_freq = 0 # 등장 빈도수가 threshold보다 작은 단어의 등장 빈도수의 총 합
# 단어와 빈도수의 쌍(pair)을 key와 value로 받는다.
for key, value in tokenizer.word_counts.items():
total_freq = total_freq + value
# 단어의 등장 빈도수가 threshold보다 작으면
if(value < threshold):
rare_cnt = rare_cnt + 1
rare_freq = rare_freq + value
print('단어 집합(vocabulary)의 크기 :',total_cnt)
print('등장 빈도가 %s번 이하인 희귀 단어의 수: %s'%(threshold - 1, rare_cnt))
print("단어 집합에서 희귀 단어의 비율:", (rare_cnt / total_cnt)*100)
print("전체 등장 빈도에서 희귀 단어 등장 빈도 비율:", (rare_freq / total_freq)*100)
비중은 1.9%정도 차지한다. 이 단어들은 전체 데이터에서 별로 중요하지 않다고 판단하여 제외시키도록 하자.
43752의 단어 중에서 희귀 단어 개수를 빼 준다.
계산할 때에는 0번 패딩을 고려하여 +1 해줘야 한다.
vocab_size = total_cnt - rare_cnt + 1
print('단어 집합의 크기 :',vocab_size)
이제 이 단어 크기를 가지고 토크나이저의 인자로 넘겨주면 이만큼의 텍스트 시퀀스를 숫자 시퀀스로 변환해준다.
트레이닝 세트와 테스트 세트 둘 다에게 해준다.
tokenizer = Tokenizer(vocab_size)
tokenizer.fit_on_texts(X_train)
X_train = tokenizer.texts_to_sequences(X_train)
X_test = tokenizer.texts_to_sequences(X_test)앞 세개의 샘플만 확인해보자.
[[50, 454, 16, 260, 659], [933, 457, 41, 602, 1, 214, 1449, 24, 961, 675, 19], [386, 2444, 2315, 5671, 2, 222, 9]]
단어들이 숫자로 변환되었다.
이제 아까 토크나이저 패키지가 만들어준 단어 집합에서 y_train과 y_test를 별도로 저장해준다.
y_train = np.array(train_data['label'])
y_test = np.array(test_data['label'])delete empty sample
방금 전에 우리는 빈도수가 낮은 단어들을 제거해줬다. 만약 한 샘플 안에 빈도수가 3미만인 단어들만 있었다면 그 샘플은 빈 샘플이 된다. 이 샘플들의 인덱스를 확인하고 제거해주자.
drop_train = [index for index, sentence in enumerate(X_train) if len(sentence) < 1]이렇게 되면 rop_train에는 empty sample의 인덱스가 저장되어있다. 이 인덱스를 가진 샘플들을 제거해주자.
X_train = np.delete(X_train, drop_train, axis=0)
y_train = np.delete(y_train, drop_train, axis=0)
print(len(X_train))
print(len(y_train))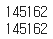
Padding
모든 샘플의 길이는 다르기 때문에 각각의 샘플 길이를 같게 하는 작업을 해줘야 한다.
우선 모든 샘플의 길이가 어떤지 파악하기 위해서 샘플들 중 최대 길이와 평균 길이를 그래프와 숫자로 확인해보자.
print('리뷰의 최대 길이 :',max(len(l) for l in X_train))
print('리뷰의 평균 길이 :',sum(map(len, X_train))/len(X_train))
plt.hist([len(s) for s in X_train], bins=50)
plt.xlabel('length of samples')
plt.ylabel('number of samples')
plt.show()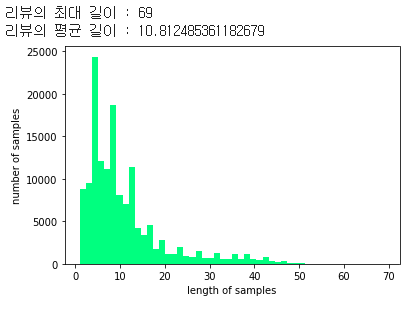
최대 길이는 69, 평균적으로 10.8개정도의 글자를 가지고 있다.
여기서는 max_len이 30정도면 적당할 것 같다.
전체 샘플에서 max_len이 30일때 비율이 어느정도인지 확인해보자.
def below_threshold_len(max_len, nested_list):
cnt = 0
for s in nested_list:
if(len(s) <= max_len):
cnt = cnt + 1
print('전체 샘플 중 길이가 %s 이하인 샘플의 비율: %s'%(max_len, (cnt / len(nested_list))*100))
max_len = 30
below_threshold_len(max_len, X_train)
94.32%의 비율의 샘플만 반영한다. 테스트셋과 트레이닝셋에 있는 모든 샘플들의 길이를 30으로 맞춰주는 작업을 한다.
X_train = pad_sequences(X_train, maxlen = max_len)
X_test = pad_sequences(X_test, maxlen = max_len)print(X_train.shape)
print(X_test.shape)마지막에 크기를 출력해보면
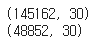
max_len에 따라 shape가 일괄적으로 맞춰졌다.
Build Model
Packages
from tensorflow.keras.models import Sequential, Model
from tensorflow.keras.layers import Embedding, Dropout, Conv1D, GlobalMaxPooling1D, Dense, Input, Flatten, Concatenate
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint
from tensorflow.keras.models import load_model하이퍼파라미터들을 정의한다.
embedding_dim = 128
dropout_prob = (0.5, 0.8)
num_filters = 128- 여기서
embedding_dim은 위에서 언급했던 이 필터들의

가로 길이를 의미한다. dropout_prob에 대해서는 이 글의 아래 부분에서 설명해놓았다. 여기서는 0.5와 0.8을 사용한다.num_filters는 필터들의 개수를 의미한다.
먼저 입력층과 임베딩층을 정의해준다.
임베딩 층 이후에는 50%의 dropout을 해 주었다.
model_input = Input(shape = (max_len,))
z = Embedding(vocab_size, embedding_dim, input_length = max_len, name="embedding")(model_input)
z = Dropout(dropout_prob[0])(z)그 다음으로 위 그림과 다르게, 여기서는 3,4,5의 (세로)크기를 가지는 커널을 각각 num_filter의 개수, 즉 128개만큼 사용한다. 그리고 maxpolling한다.
conv_blocks = []
for sz in [3, 4, 5]:
conv = Conv1D(filters = num_filters,
kernel_size = sz,
padding = "valid",
activation = "relu",
strides = 1)(z)
conv = GlobalMaxPooling1D()(conv)
conv = Flatten()(conv)
conv_blocks.append(conv)이렇게 필터의 종류가 많으면 for문을 사용해서 해결할 수 있다.
지금까지 알고있는 정보로 우리는 parameter의 개수를 구할 수 있는데, 3크기를 가지는 필터의 파라미터 개수를 구해보자.
먼저 3*128(embedding_dim)개의 필터가 128(num_filter)개 있으므로 3x128x128에다가, 각 필터당 bias가 하나씩 추가되므로 3x128x128+128인 49280개가 된다. 나중에 확인해보도록 하자.
그리고 각각 maxpooling한 결과를 concatenate한다. 80%의 확률로 dropout한 이후에 dense layer(밀집 층)으로 연결시킨다. 마지막으로 출력층까지 만들어준다.
z = Concatenate()(conv_blocks) if len(conv_blocks) > 1 else conv_blocks[0]
z = Dropout(dropout_prob[1])(z)
z = Dense(128, activation="relu")(z)
model_output = Dense(1, activation="sigmoid")(z)
model = Model(model_input, model_output)
model.compile(loss="binary_crossentropy", optimizer="adam", metrics=["acc"])모델이 완성되었다.
model.summary()를 통해서 자세히 확인해보자.
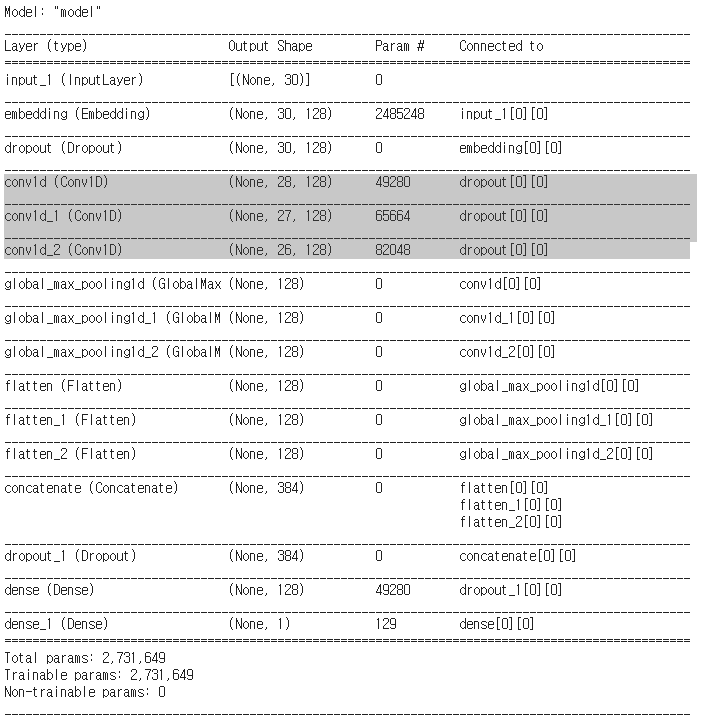
드래그 한 부분을 자세히 살펴보면 아까 언급했던 parameter의 개수가 정확이 맞는 걸 확인할 수 있다.
테스트 세트에 넣어서 정확도를 확인해보자.
model.fit(X_train, y_train, batch_size = 64, epochs=10, validation_data = (X_test, y_test), verbose=2)
model.evaluate(X_test, y_test)[1]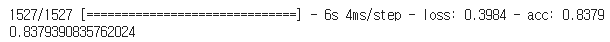
약 83.8%의 정확도가 나온다.
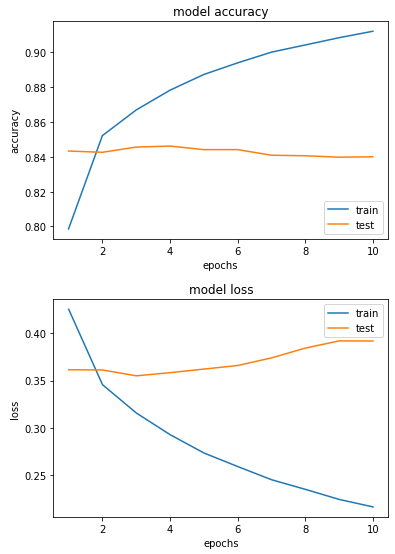
loss와 acc의 그래프를 나타내 보았다.
여기서 1D CNN과 그 예제 설명을 마무리하겠다.
