요즘 LLM 논문 구경하는게 왜 재밋지
원래 자기가 안하는 주제가 제일 재밋음
제목에 factuality 들어간 논문을 오랜만에 봐서 오호 하면서 예전에 읽었던 논문 생각이 나서 대충 구경해봤다.
예전에 Factuality Enhanced Language Models for Open-Ended Text Generation (NeurIPS 2022) 이란 논문을 봤었는데 그때 봤던 논문 내용이 (기억이 안나서 인터넷 찾아옴)
- Open-Ended Text Generation 상황에서 Pretrained Language Model(PLM)의 Factuality를 평가하기 위한 Dataset인 FactualityPrompts와 평가 지표 제안
- PLM의 Factuality를 향상시키는 Decoding 방법 및 추가 Training을 위한 Loss Masking 방법론 제안
이런거였는데
뭐 이런데는 짤막한 fact확인하는 수준이었고
이게 아니더라도 long factuality 벤치마크도 단일주제로만 있었음
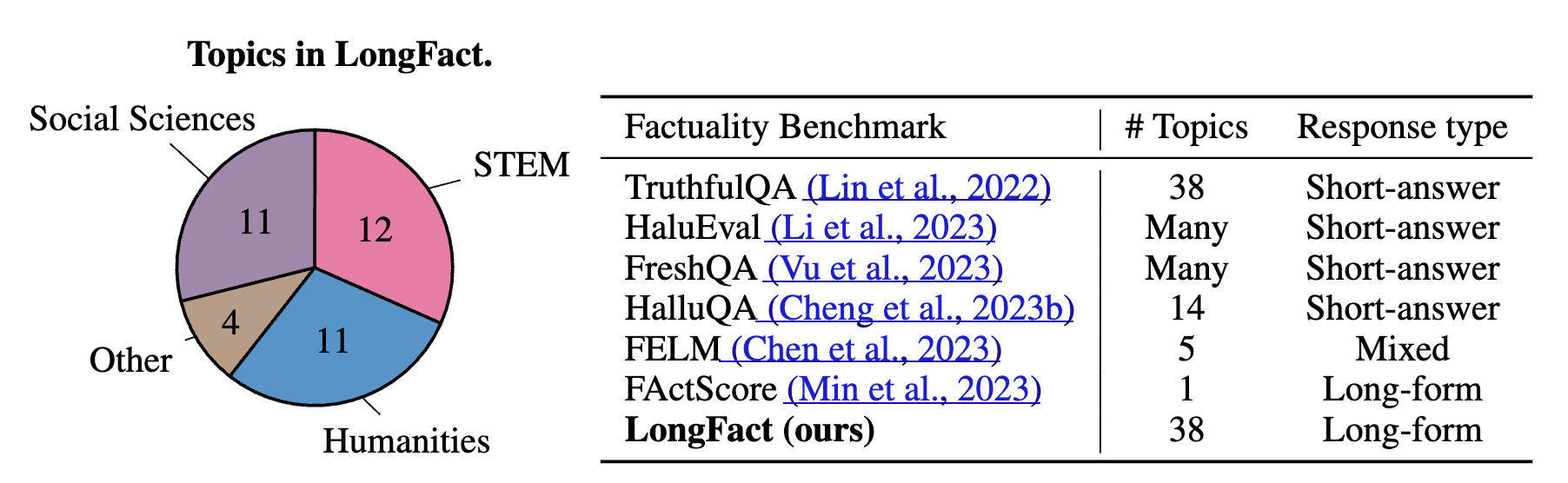
논문 안에 저자들은 LLM factuality를 확인하는 벤치마크로 GPT-4를 이용해 긴 답변이 필요한 팩트를 물어보는 질문 2280개를 개발함.
논문 열자마자 보이는 피겨인데

정답을 비교하는 식에서 벗어나 '답안'을 평가하는 방식 SAFE(Search-Augmented Factuality Evaluator)방식을 개발햇고
답안을 작은 fact 조각으로 쪼개서 각각을 google search API를 통해서 검증하는 방식으로 확인
결과는 1. supported 2. not supported 3. Irrelevant 로 나눠서 정량적으로 평가한다.
인간이 검증한 것과 SAFE로 자동 검증한 것을 비교했더니

72%에서 일치함.

위처럼 불일치의 경우에서 SAFE가 76% 맞고 인간이 19% 맞음, 나머지 5%는 둘다 틀림.
인간의 인건비와 API 비용을 구했더니 인간이 20배 이상 비쌌음.
인간을 쓸 이유가 없는 것임...... <<
그래서 이 결과를 바탕으로 precision 과 recall(len of answer) 를 적절히 조절한 F1@K 지표를 만듦.
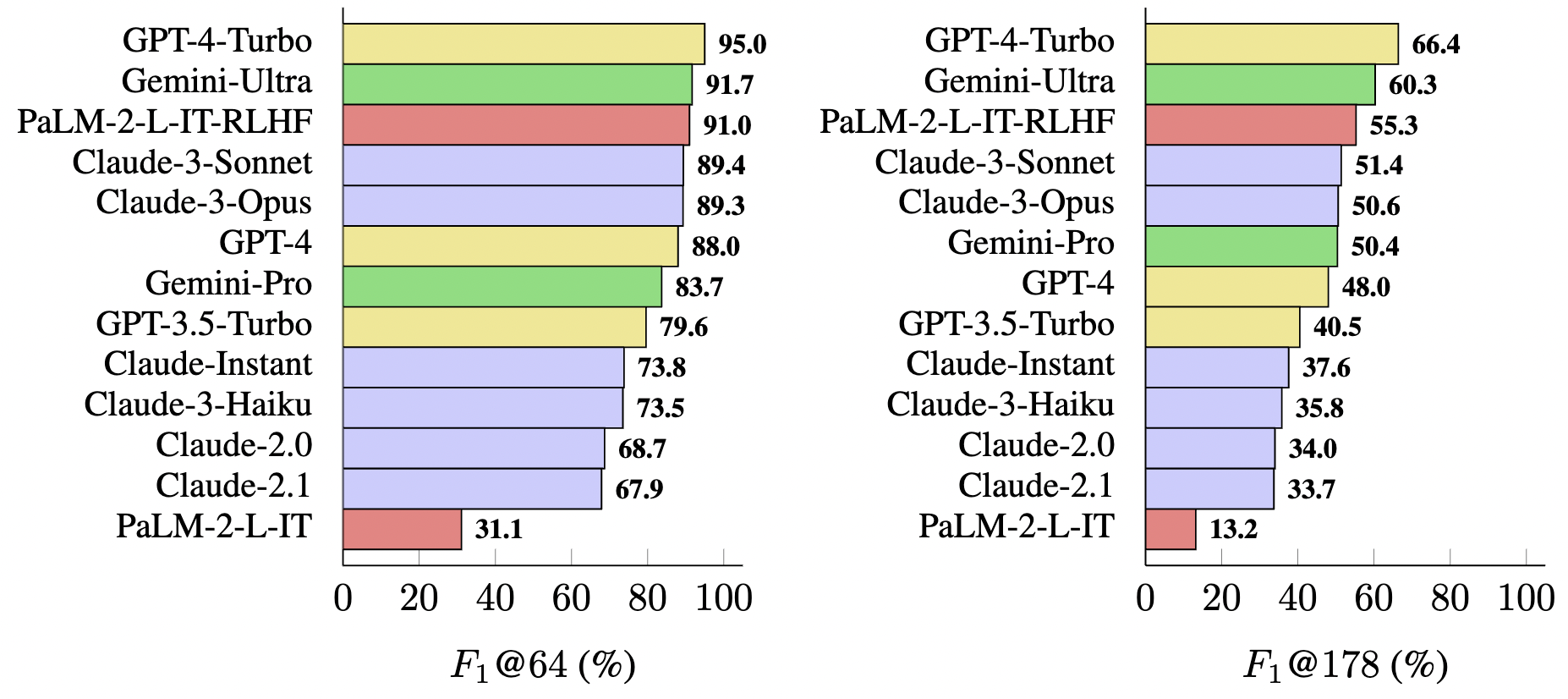
이 지표로 13개 LLM을 평가한 결과
GPT-trubo(압도적;;), 그리고 잼미니, PaLM, 그리고 클로드 순으로 factuality 성능이 나옴
PaLM-2의 경우 RLHF를 해준 게 압도적으로 성능이 좋앗음
사람이 원하는 형태의 대답을 하는게 이 벤치마크에 적절한 답을 만들어내는 듯
지피티가 하도 구라를 지어내는 치명적인 단점이 있다 보니까 이런 연구가 흥미로웁니다.
어서 빨리 팩트체크도 해주고 문장주면 사이테이션 탁탁 해주는 모델이 나왔으면
