EWMoE - An Effective Model for Global Weather Forecasting with Mixture-of-Experts
Paper Review
목록 보기
36/52
중국 电子神技大学랑 스촨 AI 리서치 기관에서 쓴 논문
사용한 데이터는 ERA5 이고 2015, 2016을 학습으로 사용하고 2017을 검증, 2018을 테스트에 사용.
학습 데이터 기간이 짧은데
- 계산 자원 절약 하기 위해서 (2년치 학습을 2개 3090으로 9일동안 학습)
- 적은양으로도 잘된다는거 보여주기 위해서
- MoE를 대입했어서 성능 유지 가능했다.
과제: 6시간 간격으로 8일간의 예측을 수행.
방법론
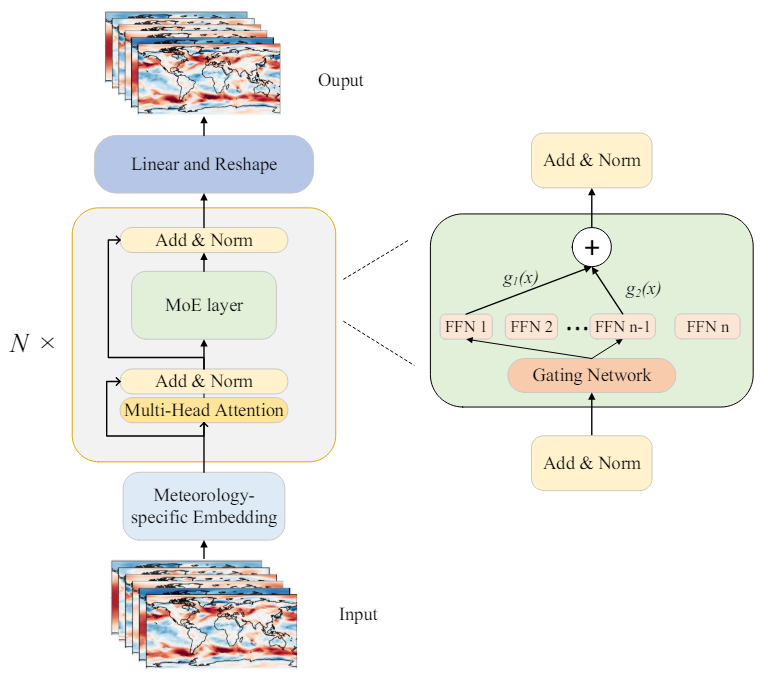
- 기상 데이터 임베딩
여기서 말하는 것은 Patch embedding + Position Embedding 인데
패치 임베딩은 우리가 알고있는 그거고, 포지션 임베딩은 3D 절대 위치 임베딩을 사용해서 패치의 고도, 위도, 경도를 반영한 임베딩 벡터를 학습한다. vit에서 그래프 느낌을 주고 싶어서 사용한 듯. - Mixture-of-Experts(MoE) layer:
MoE 레이어는 여러개의 독립적은 FFN레이어로 구성되어 있음.
각각의 FFN은 하나의 Experts 역할을 함.
Gating Network는 입력 토큰을 최상의 Experts로 routing한다.
-
게이팅 네트워크가 입력 토큰을 상위 k개의 experts에게만 보내도록 한다. (Tpo-k routing)

MoE의 핵심 아이디어는 모든 Experts가 동시에 작동하는게 아니라 주어진 입력에 대해 가장 적합한 몇몇 Experts만 선택되어 작동한다. 여기서 Experts는 피드포워드 네트워크임. 예를들어 20개의 Experts가 있다면 서로 다른 기능을 가짐.
Gating Network는 데이터를 분석해서 어떤 Experts를 사용할지 결정하는 네트워크.
동작 방식:
입력 데이터가 MoE에 들어오면 gating network가 Experts의 중요도를 계산한다. 이 중요도는 각 Experts가 해당 입력에 얼마나 적합한지 나타냄.
Gating Network는 가장 적합한 k개의 Experts를 선택한다. 얘네들이 데이터를 처리하고 출력을 생성하고 나중에 가중치에 따라 결합되어 최종 출력을 만들어냄.
여기서 는 i번째 전문가에 대한 gate값, 는 i번째 전문가의 출력이다.
- 그다음에 Load Balancing(부하 균형), Auxiliary Loss항을 도입한다. 각 Experts에 대해 균등한 load를 유지하기 위해 추가적인 loss function을 도입. 아래에서 더 자세히.
- 손실 함수 : auxiliary loss + position-weighted loss

위 식은 Auxiliary Loss, Experts사이의 Load를 균형있게 분배, 는 i번째 Experts에 할당된 token의 비율, 는 Gating network의 확률 분포

위 식은 Position-weighted Loss이고 예측할때 지표면 근처의 대기 변수를 더 정확하게 예측하기 위함이라고 함.
여기서 f(v)는 변수 v의 가중치 값, L(i)는 위도 가중치 계수이다. 예측시 가중치를 더 주는것.kaggle에서 사용해도 좋을듯.
- 좀 더 자세히 살펴봄.
오차 제곱에다가, 변수v의 가중치랑 위도 가중치를 곱해주면 된다.
근데 여기서 위도 가중치는 지구 구조로 인해서 셀의 크기가 위도에 따라 달라지기 때문에 적용되는 것으로 아래의 식을 따른다.

변수 가중치는 어케 정하는지는 모르겠음. 아마 모델 안에서 자연스럽게 정해지나? 논문에서는 안나옴
결과
RMSE, ACC를 통해 평가

각 단계별 영향


뜬금없지만 세계여행이 꿈입니다.