
Paging
페이징(Paging)은 앞서 설명드린 압축의 비효율성을 해결하기 위한 방법입니다.
Frame과 Page
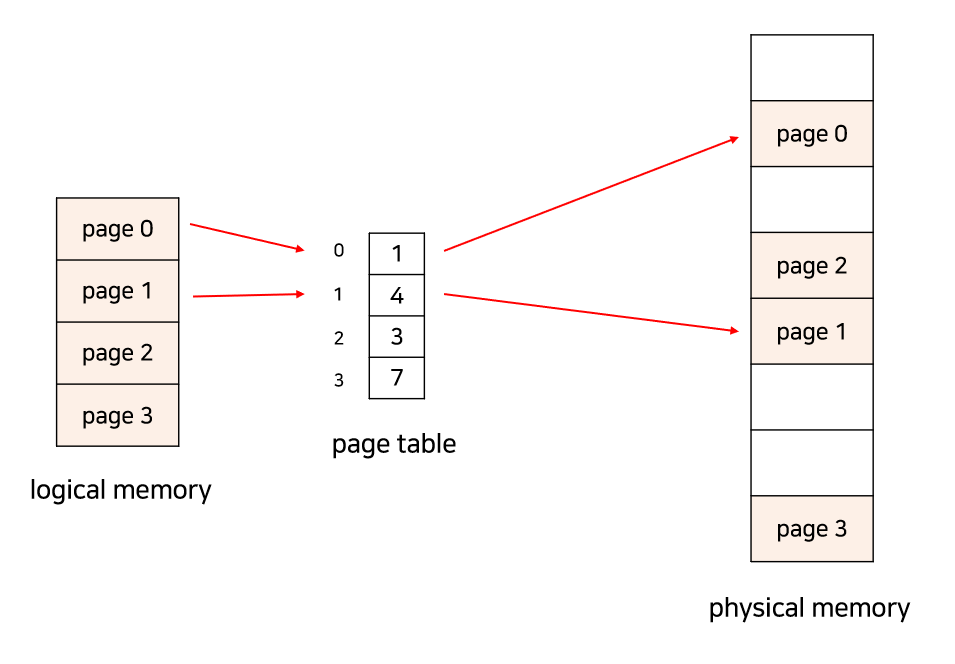
프레임(Frame)은 물리 메모리를 일정한 크기로 나눈 블록, 페이지(Page)는 가상 메모리를 일정한 크기로 나눈 블록입니다. 둘의 크기는 같습니다.
모든 프로세스는 CPU가 정한 페이지 크기만큼 조각화되고 메모리도 프레임 크기만큼 조각화됩니다. 그리고 프로세스의 각 페이지는 메모리의 프레임에 불연속적으로 할당됩니다.
프로세스의 페이지가 불연속적으로 프레임에 할당되기 때문에 프로세스가 정상적으로 실행되기 위해서는 페이지가 어느 프레임에 맵핑되어 있는지를 알아야 합니다. 이에 대한 정보는 페이지 테이블(Page Table)에 저장되어 있습니다. 이 테이블을 사용하여 논리적 주소를 물리적 주소로 변환합니다.
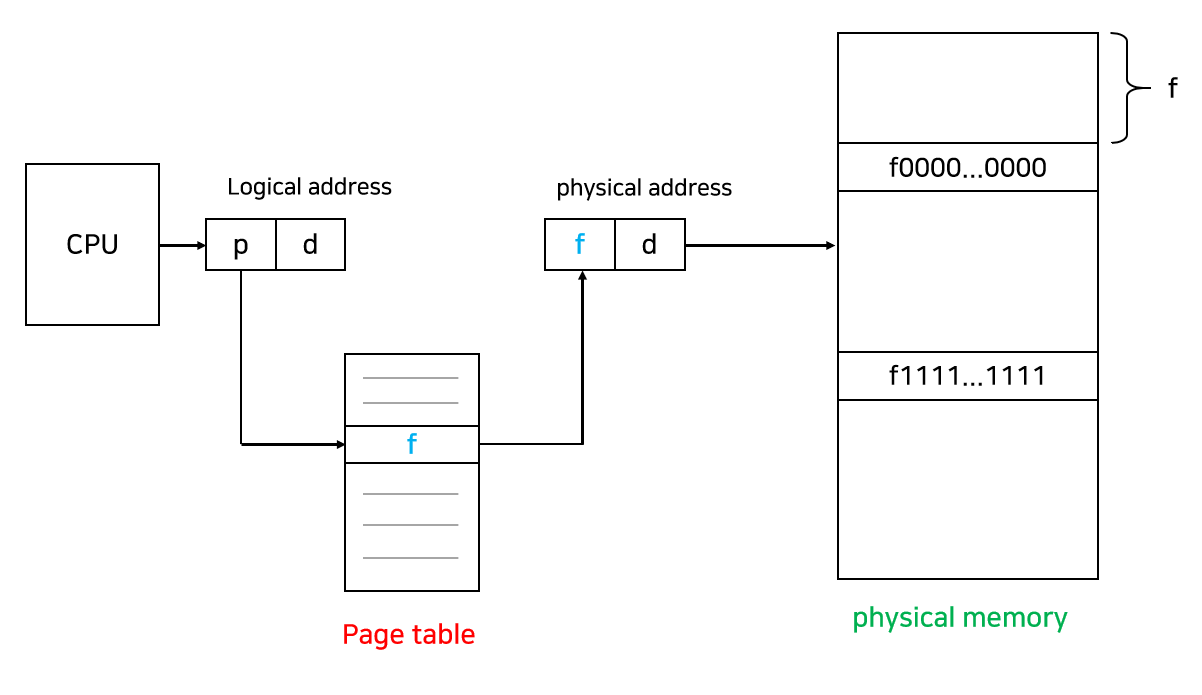
CPU에 의해 만들어진 논리적 주소는 page number와 page offset 두 부분으로 나누어집니다. page number는 page table의 인덱스로 사용됩니다. page offset은 page number를 통해 얻어낸 page table의 값에 더해져 물리적 주소를 얻을 때 사용합니다.
내부 단편화
프로세스 크기가 페이지 크기의 배수가 아닐 경우, 마지막 페이지는 한 프레임을 다 채울 수 없습니다. 결국 내부 단편화가 발생하게 된 것입니다.
내부 단편화는 해결할 수 없습니다. 하지만 메모리가 낭비되는 양이 page size보다 작아 무시해도 될 정도입니다.
Page Table
CPU 내부에 페이지 테이블을 만들 수 있습니다. CPU 내부의 레지스터로 테이블을 만들면 주소 변환 속도가 빠른 페이지 테이블을 만들 수 있습니다. 하지만 레지스터는 한정되어 있으므로 페이지 테이블의 크기가 제한됩니다.
메모리 내부에서 만들 수도 있습니다. 장점은 테이블 크기의 제한이 없습니다. 하지만 주소 변환 속도가 느리다는 단점이 있습니다. CPU가 프로세스의 주소에 접근하기 위해서 메모리의 페이지 테이블에 한 번, 실제 주소로 접근 하는 데에 한 번, 총 2번 접근해야 합니다.
이를 해결하기 위해 페이지 테이블도 캐시로 만들어 해결하였습니다. 전체 페이지 테이블은 메인 메모리에 두고 일부만 캐시로 가져와서 사용합니다. 이 캐시의 이름은 TLB 입니다.
TLB
TLB(Translation Look-aside Buffer)는 메모리 주소 변환을 위한 별도의 캐시 메모리입니다. Page Table에서 빈번히 참조되는 일부 엔트리를 캐싱하고 있습니다.
TLB는 key-value 쌍으로 데이터를 관리합니다. key에는 page number, value에는 frame number가 대응됩니다.
CPU는 Page Table보다 TLB를 우선적으로 참조하여 원하는 페이지가 TLB에 있다면 frame number를 얻을 수 있고, 그렇지 않다면 Page Table을 참조합니다.
원하는 엔트리를 찾기 위해 TLB 전체를 찾아봐야하는 단점이 있습니다만 parallel search가 가능하기에 탐색 시간을 적습니다.
- TLB에서 원하는 엔트리가 있을 확률(hit ratio) = 80%
- TLB를 읽는 시간 = 20ns
- 메모리를 읽는 시간 = 100ns
다음과 같이 정의하고 메모리 접근 시간의 기댓값을 계산해봅시다.
x * (a + b) + (1 - x) * (a + b + b)0.8 * (20 + 100) + 0.2 * (20 + 100 + 100) = 140nshit ratio를 80%로 가정하고 계산해도 TLB를 쓰지 않을 때의 200ns보다 효율적입니다. 실제로 hit ratio는 95%이라고 하니 TLB를 사용하는 것은 충분히 효율적이라고 볼 수 있습니다.
보호
모든 주소는 Page Table을 경유합니다. 따라서 테이블을 통해 페이지를 보호할 수 있습니다. 대표적인 방법으로 페이지 테이블 엔트리에 r(read), w(write), x(execute) 비트를 두는 것입니다.
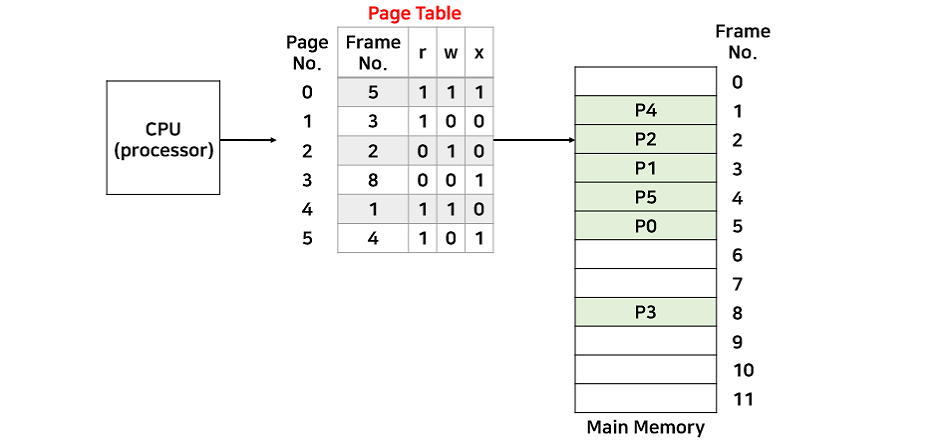
비트가 꺼져 있는 페이지에 쓰기 작업을 시도하면 CPU에 인터럽트가 발생해서 ISR에서 해당 프로세스를 종료시킵니다.
공유
메모리를 낭비를 방지할 수 있습니다. 다수의 프로세스가 같은 프로그램을 사용한다면 그 프로그램의 code 영역은 같은 것입니다. 이 하나의 code 영역을 프로세스가 공유한다면 메모리의 낭비를 방지할 수 있습니다. 단, 이 code가 변하지 않는 프로그램이어야 합니다. 이를 pure code라고 합니다.
