📚 23.10.30
- 무한스크롤 (window.scroll VS IntersectionObserver)
- git comment --amend
무한스크롤
컨텐츠를 페이징 하는 기법 중 하나. 아래로 스크롤하다가 컨텐츠의 마지막 요소를 볼 즈음 다음 컨텐츠가 있으면 불러오는 방식
구현 방식
window의 scroll이벤트를 통해 스크롤링이 일어날 때마다 화면 전체의 height와 스크롤 위치를 통해 스크롤이 컨텐츠 끝 즈음에 다다랐는지 체크하여 처리intersection observer
그전에 알아둘 것!!
뷰포트(Viewport)
컴퓨터 그래픽스에서, 뷰포트(viewport)는 현재 화면에 보여지고 있는 다각형(보통 직사각형)의 영역입니다. 웹 브라우저에서는, 현재 창에서 문서를 볼 수 있는 부분(전체화면이라면 화면 전체)을 말합니다. 뷰포트 바깥의 콘텐츠는 스크롤 하기 전엔 보이지 않습니다.
뷰포트 중에서도 지금 볼 수 있는 부분을 시각적 뷰포트라고 부릅니다. 사용자가 두 손가락으로 대상을 확대 및 축소하는 동작과 같은 특정 상황에서, 레이아웃 뷰포트의 크기는 변하지 않지만 시각적 뷰포트는 더 작아집니다.
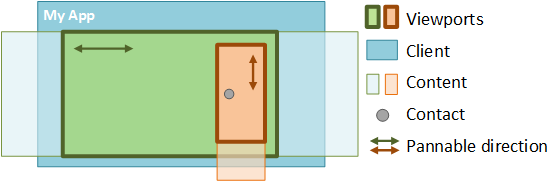
우리가 보는 노트북 등의 화면에 나타나는 만큼이 시각적 뷰포트이다. 이것의 세로 길이는 window.innerHeight 를 통해 알아낼 수 있다.
얼마나 스크롤하여 내려왔는지 알기 위해선 window.scrollY 를 사용한다. 가장 처음 최상단을 보고 있다면 0값을 가진다.
window.scroll
최하단으로 내려왔을 때의 window.scrollY + window.innerHeight === document.body.offsetHeight가 된다!
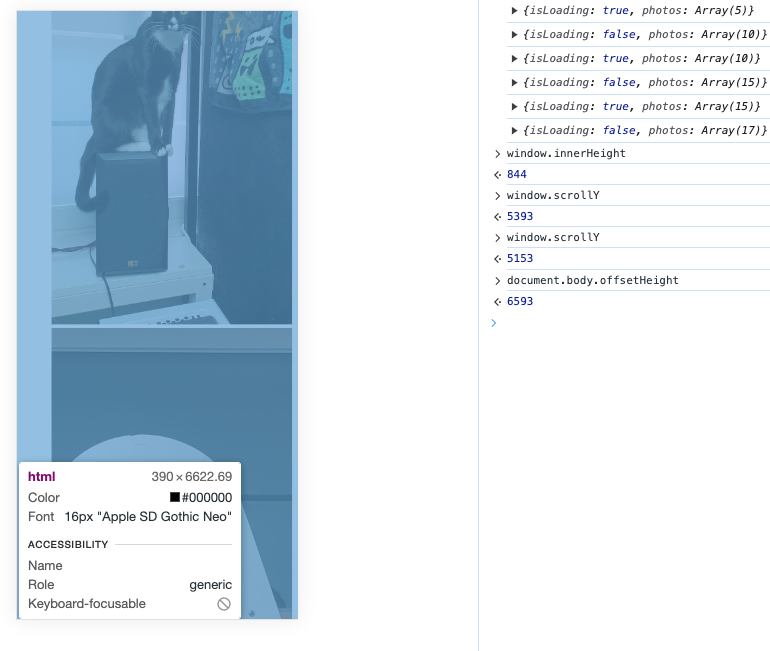 그래서 이렇게 하면, 완전 끝까지 스크롤이 내린 건 아니고 거의 다왔을 즈음(100)에 isScollEnded가 true가 되어 다음 콘텐츠 요청을 보낼 수 있다!
그래서 이렇게 하면, 완전 끝까지 스크롤이 내린 건 아니고 거의 다왔을 즈음(100)에 isScollEnded가 true가 되어 다음 콘텐츠 요청을 보낼 수 있다!
const isScollEnded = window.innerHeight + window.scrollY + 100 >= document.body.offsetHeight데이터의 마지막임을 처리해야한다.
이 API의 데이터는 17개까지인데 스크롤에 의해 계속 요청이 들어가기 때문에 40~50~60~ 등 계속 요청이 들어간다. response값이 없으니까 화면 변화는 없지만 이렇게 요청을 보내는건 안좋으니까!
해결 방법
- 이 Api 전체 데이터 갯수를 알려주는 api가 따로 필요하다. 그래서 현재 내가 불러온 갯수와 비교하는것. 이게 제일 정확함
- 매 response를 확인하면된다. 현재 limit가 5라서 5개씩 값을 가져오는데, 응답의 길이가 5가 안되면 마지막인지로 확인하면된다. 문제는, 딱 5로 나뉘어떨어지는경우엔 문제가 될 수 있다.
- 쓰로틀과 디바운스를 이용할 수도 있다.
-> 강의에서는 1번 방법으로 구현했는데, 이 부분에서 의문이 생겼다.
왜 2번이 안되나? 2번으로도 “길이가 5가 안되는” 조건으로도 되지 않을까? 딱 다섯개로 마무리 되었다면 그다음 요청에선 0개가 오지 않나?
⇒ 그래서! this.state에 totalCount값을 추가했던 것 처럼 isLast 값을 추가했고, api 요청의 응답의 길이가 limit보다 작게 왔다면 이를 true로 처리한다! 그리고 무한스크롤 또한 isLast인 경우엔 더이상 요청하지 않는다!
IntersectionObserver
스무디 개발하면서 열심히 공부했던 API!!! 내가 정리한 구현기이자 공부기록을 보면서 다시 복습했다. 최근 기술이라고 하시고 이렇게 등장하니 뿌듯ㅎㅎㅎㅎ
사용하기!
const observer = new IntersectionObserver(entries =>{
entries.forEach(entry =>{
if (entry.isIntersecting){
console.log("화면 끝",entry)
}
})
}, {
threshold: 0
})- IntersectionObserver(콜백, options)
콜백함수의 인자인 entries는 인스턴스의 배열이다! 그래서 [0]을 사용하거나 위처럼 forEach로 순회하여사용하자.
isIntersection 속성은 관찰대상이 뷰포트에 교차되었는지를 반환한다(Boolean)
- options
threshold는 교차 비율! 인거다. 기본이 0 이다.
또한, 감시대상 지정 필수!
const $nextLi = $photos.querySelector("li:last-child");
if ($nextLi) {
if ($lastLi){ //이전 감시 대상 없애줘야함!
observer.unobserve($lastLi);
}
$lastLi = $nextLi;
observer.observe($lastLi); //관찰대상으로 등록
}-
window.scroll과 IntersectionObserver 무슨차이일까!
IntersectionObserver이 window스크롤이벤트보다 직관적이고, 매 스크롤마다 이벤트를 보고 있는 것이 아니기에 성능상의 이점이 있을 것이다. 상황에따라! -
무한스크롤로 추가 데이터 요청 VS 물리적인 버튼 클릭으로 요청
ux면에서 무한스크롤이 이점이 있을 수 있지만, 무한스크롤이 존재하면 Footer에 접근하기 어려움 등의 단점도 있다. -
무한스크롤의 쓰임
이미지 지연로딩에도 이용할 수 있다.
한 화면에서 보여지는 이미지 만큼만 요청한다. 이미지 데이터가 10개인데 첫화면에 3개만 보인다하면, 처음엔 3개만 보이다가 스크롤에 따라 추가 요청하는 것이 최적화방법이다.
배열 합치기
const array1 = ['a', 'b', 'c'];
const array2 = ['d', 'e', 'f'];
console.log(array1.concat(array2);
// > Array ["a", "b", "c", "d", "e", "f"]
console.log([array1, ...array2])
// > Array [Array ["a", "b", "c"], "d", "e", "f"]
console.log([...array1, ...array2])
// > Array ["a", "b", "c", "d", "e", "f"]배열을 풀어서 요소 하나하나로 써야 하니 … 를 꼭 붙이자!
git commit —amend
커밋을 했는데 미처 포함시키지 못한 파일이 있거나, 메시지를 잘 못 입력한 경우 그 해당 커밋을 수정할 수 있다.
참고 :https://www.atlassian.com/ko/git/tutorials/rewriting-history
포함 시키지 못한 파일에 대해 수정을 완료한 후, add한다.
그리고 그냥 git commit이 아니라 git commit --amend --no-edit 으로 커밋한다.
—no-edit 플래그를 사용하면 이전의 커밋 메세지 그대로 유지된다.
매일 깃허브 명령어 하나씩 배우고 있는 것 같다… 맨날 검색하지만;
🫨 느낀 점
무한스크롤에서 마지막 데이터까지 불러왔음을 처리하는것에 배울 수 있었다. 스크롤 위치에 따라 요청을 보내기 때문에, 마지막까지 불러왔음에도 계속 요청이 들어갈 수도 있다.. 또한 데이터가 느린 상황도 고려해주어야 한다. 중복 요청을 막자!
특히 API요청을 사용할 땐 다양한 경우의 예외 처리가 필요하다. 정말 간과하기 쉽고 잘 안떠오르는데 서버에도 부담이 가는거니까 유의하자,,
🤔 오늘 회고
Keep
실습 해볼떄에 의문을 많이 가져보았다. "그래서 그게 뭐지?", "왜 이거보다 저게 좋지?", "뭐가 좋지?" 를 생각하고 답을 찾으려고 노력했다. 정답을 찾은지는 모르지만 내 나름의 시도를 해봤음에 의의를,,
Problem
코드리뷰는 쉽지 않다. 내가 개발하기전에 컴포넌트 구조를 열심히 짰던 것처럼 다른 분들의 코드를 읽을 때 구조와 흐름이해에 오래걸리긴 한다. 많이 해보면 늘지 않을까 라는 마음으로 열심히 보자
Try
기술적인 면에서의 코드리뷰도 남기기
