SELECT : 조회
SELECT *|{DISTINCT] column [alias], .....}
FROM table;distinct: 중복 제거
alias: 열 머리글의 이름을 바꿈 ( as [alias] 형식도 가능)
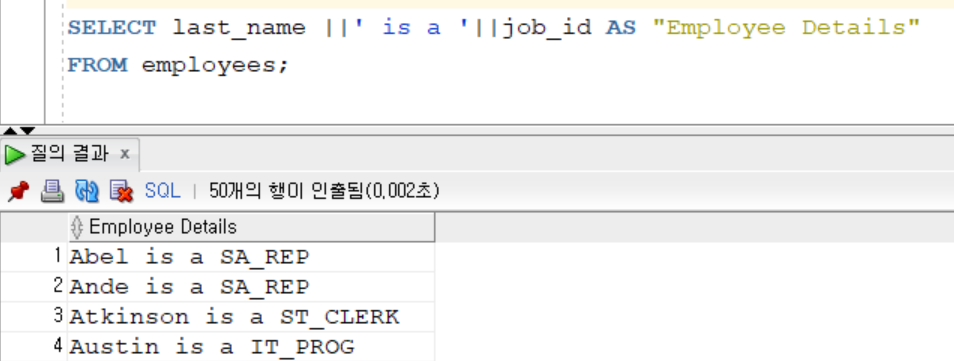
|| : 연결 연산자: 열이나 문자열을 다른 열에 연결
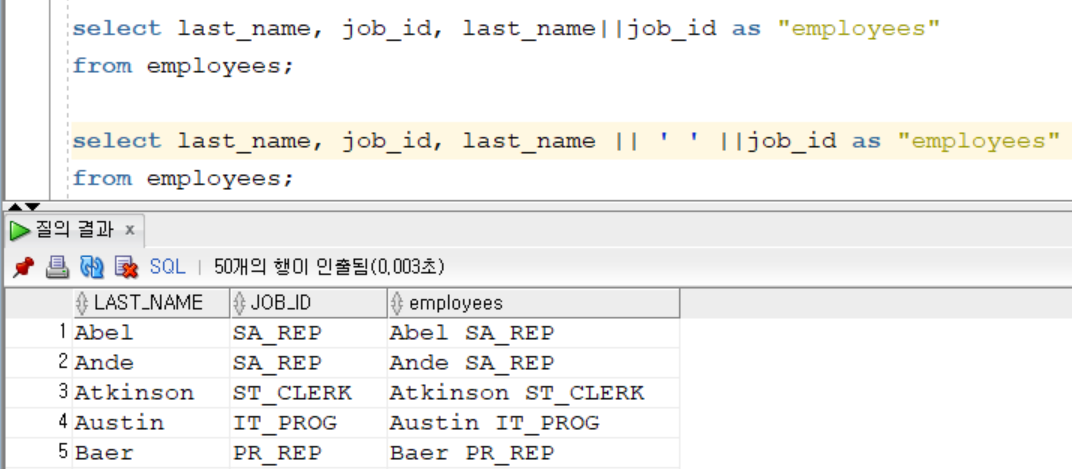
리터럴 문자열
리터럴 = select 문에 포함된 문자, 숫자 또는 날짜
'날짜 및 문자 리터럴' 로 표현
where : 조건절
SELECT *|{DISTINCT] column [alias], .....}
FROM table
WHERE 조건절;비교 연산자
= <= >= ...
BETWEEN ... AND ...
IN NOT IN
LIKE
IS NULL IS NOT NULL
*<> != ^= -> 같지 않음
select last_name, salary
FROM employees
WHERE salary <= 3000;
select last_name, salary
from employees
where salary between 2500 and 3500;
select employee_id, last_name, salary, manager_id
from employees
where manager_id IN (100,101,201);
select employee_id, last_name, salary, manager_id
from employees
where last_name IN ('Hartstein', 'Kochhar', 'De Haan', 'Raphaely');
select first_name
from employees
where first_name LIKE 'S%a';
select last_name, manager_id
from employees
where manager_id IS NOT NULL;논리 연산자
AND OR NOT
select last_name, first_name, job_id, salary
from employees
where salary >= 2500 and salary <= 3500;
SELECT last_name, job_id
FROM employees
WHERE job_id NOT IN ('IT_PROG', 'ST_CLERK', 'SA_REP');
SELECT employee_id, last_name, job_id, salary
FROM employees
WHERE salary >= 10000 OR job_id LIKE '%MAN%';order by
ORDER BY {column, expr, numeric_position}[DEFAULT] ASC | DESC
SELECT 절에 쓴 COLUMN 순서에 따라 1,2,3,4 로도 표현 가능
SELECT last_name, job_id, department_id, hire_date
FROM employees
ORDER BY 3;
SELECT last_name, department_id, salary
FROM employees
ORDER BY department_id, salary DESC; --앞은 ASC, 뒤는 DESC데이터 정의어
CREATE TABLE
CREATE TABLE [schema.]table(column datatype [DEFAULT expr][, …] )'
CREATE TABLE dept
(deptno NUMBER(2),
dname VARCHAR2(14),
loc VARCHAR2(13),
create_date DATE DEFAULT SYSDATE);*실제 데이터가 있는건 -> TABLE
* DESC [tablename] 테이블 구조 표시
데이터 유형
VARCHA2(size): 가변 길이 문자 데이터 (최대 32,757 byte, 레거시 - 4,000 byte)
CHAR[(size)]: 고정 길이 문자 데이터 (최대 2,000 byte)
NUMBER[(p, s)]: p - 숫자 자릿수, s - 소수점 이하 자릿수
LONG: 가변 길이 문자 데이터 (최대 2GB)
DATE: 날짜 및 시간 값
CLOB: (Large Object) 사이즈가 큰 문자열 데이터를 DB 외부에 저장하기 위한 타입. 실제론 다른 곳에 저장되고, 위치 정보만 저장
* BLOB : Binary Large Object 타입
DEFAULT
CREATE 테이블이 표시된 동안 열의 기본값 정의
-- 현재 시간을 기본 값으로
CREATE TABLE hire_dates
(id NUMBER(8),
hire_date DATE DEFAULT SYSDATE);제약 조건
NOT NULL : NULL 이면 안됨
UNIQUE : 테이블의 모든 행에 대해 값이 고유해야 하는 열[조합]
PRIMARY KEY: UNIQUE 보다 많이 씀. 각 행을 고유 식별
FOREIGN KEY: 특정 테이블의 열과 참조 테이블의 열 간에 참조 무결성 설정/적용하여 한 테이블 값이 다른 테이블 값과 일치하도록 함 (보통 PK 참조)
CHECK: 참이어야 하는 조건 지정
*TABLE 은 PK 가 필수가 아님
CREATE TABLE teach_emp (
empno NUMBER(5) PRIMARY KEY,
ename VARCHAR2(15) NOT NULL,
job VARCHAR2(10),
mgr NUMBER(5),
hiredate DATE DEFAULT (sysdate),
photo BLOB,
sal NUMBER(7,2),
deptno NUMBER(3) NOT NULL
CONSTRAINT admin_dept_fkey REFERENCES departments (department_id));보통 제약 조건은 아래와 같이 씀
ALTER TABLE table_name
ADD CONSTRAINT constraint_name PRIMARY KEY (column);
ALTER TABLE table_name
ADD CONSTRAINT constraint_name FOREIGN KEY (column) REFERENCES table_name (column);CREATE TABLE AS
보통 테이블 백업을 할 때 사용함 -> AS subquery
*새로운 작업을 하려는데 자신감이 없다 = 백업 하기!
CREATE TABLE dept_new80
AS
SELECT employee_id, last_name, salary, hire_date
FROM employees
WHERE department_id = 80;
CREATE TABLE dept_new
AS
SELECT * FROM employees
WHERE department_id = 80;
--데이터 없이 테이블만 가져오기
CREATE TABLE dept_new_bak
AS
SELECT * FROM employees
WHERE 1 = 0 --FALSE 가 되므로 데이터 없음ALTER TABLE
테이블에 열 추가, 수정, 삭제
--마지막 열로 추가됨 (컬럼 순서 정할 수 X)
ALTER TABLE dept80
ADD (job_id VARCHAR2(9));
--데이터 크기 변경
ALTER TABLE dept80
MODIFY (last_name, VARCHAR2(30));
--해당 열 삭제
ALTER TABLE dept80
DROP (job_id);
--날짜 데이터를 문자로 바꿔 저장하는 열 추가
ALTER TABLE TBCR_1122
ADD (REG_DD VARCHAR2(10) DEFAULT TO_CHAR(SYSDATE, 'YYYYMMDDHH24MISS')); --24시로 표현마지막 예시문은 오류남 (ORA-00600 ORA-4031 ORA-7445 은 internal error)

보통 버그라서 패치해야함.
위 오류는 19.10 이상 버전에서 해결됨
마지막 예시문은 VARCHAR2(14) 로 변경하면 위 버전(19.03)에서 실행됨
DROP TABLE
테이블 삭제
DROP TABLE table_name [purge];
--purge 미사용시 휴지통에 들어가고 완전히 삭제되지 않음SYNONYM
ex) HR1 유저가 HR 유저에 있는 객체(테이블,뷰,시퀀스,프로시저 등)를 보고 싶을 때 (참조할 때) 사용함
실제로 SYNONYM을 이용하는 이유는 다른 유저의 객체를 사용할 때 유저의 이름과 객체의 실제 이름을 사용하는데, 그 두 개를 감춤으로써 데이터베이스의 보안을 개선하기 위함
SYNONYM 생성
CREATE [OR REPLACE] [PUBLIC] SYNONYM '[스키마명].시노님명' FOR '스키마명,대상오브젝트명'
ex) CREATE SYNONYM employees FOR hr.employees
PUBLIC - 대상 객체 접근 권한 가진 모든 사용자 접근 가능(DEFAULT : PRIVATE - 로그인한 유저 기준 생성되고, 해당 유저만 SYNONYM 사용 가능)
ON REPLACE - 같은 이름의 SYNONYM를 대체(갱신)
SYNONYM 삭제
DROP [PUBLIC] SYNONYM [시노님명] [FORCE]
SYNONYM 조회
현재 계정
SELECT * FROM USER_SYNONYMS
전체 계정
SELECT * FROM ALL_SYNONYMS
*실제 데이터가 있는건 -> TABLE
SYNONYM 생성 권한을 SYS 로 주고, 테이블 접근 권한 부여해야함
-> GRANT CREATE[SELECT|DROP|...] SYNONYM TO 'hr1'
-> GRANT ALL ON hr.table01 TO hr1; // 테이블 접근 권한
