0. 주요 추천 알고리즘 정리
- 내용 기반 필터링(content-based filtering : CB)
- 협업 필터링(collaborative filtering: CF)
- 메모리 기반(memory-based)
- 사용자 기반
- 아이템 기반
- 모델 기반(model-based) → MF 방식
- 지식 기반 필터링(knowledge-based filtering: KB)
- 딥러닝 (deep learning: DL)
- 하이브리드(hybrid)
1. Matrix Factorization(MF) 방식의 원리
- 모델 기반 추천 : 메모리 기반 알고리즘과 다르게, 데이터로부터 추천을 위한 모델을 구성한 후에 이 모델만 저장하고, 실제 추천을 할 때는 모델만을 사용하여 추천을 하는 방식.
- 행렬요인화(Matrix Factorization) 방식이 대표적인 모델 기반 추천 알고리즘
- 딥러닝 방식의 추천도 학습된 신경망을 가지고 한다는 점에서 모델기반 추천 알고리즘이라 할 수 있음
- 장점
- 모델이 만들어지면 원래 데이터는 사용하지 않기 때문에 대규모 사용 사이트에서 빠른 반응이 가능
- 전체 사용자의 평가 패턴으로부터 모델을 구성하기에 데이터가 가지고 있는 약한 신호도 더 잘 잡아냄
- 단점
- 모델을 만드는 과정에서 많은 계산이 필요함
- 원리
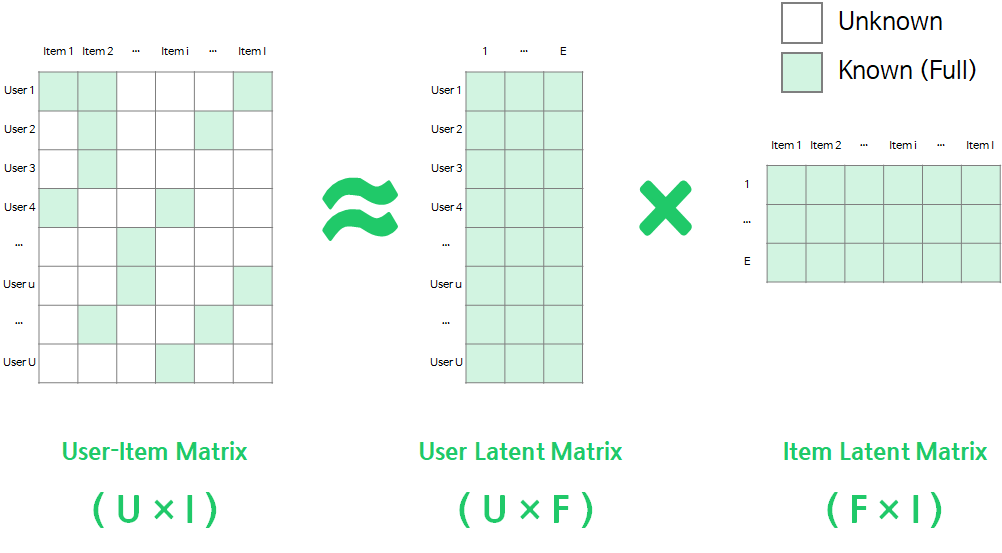
Matrix Factorization은 User-Item Matrix(평가데이터)를 F차원의 User와 Item의 latent factor(잠재요인) 행렬곱으로 분해하는 방법
⇒ 사용자x아이템 평가 데이터 행렬(R) 을 사용자 행렬(P) 과 아이템 행렬(Q)로 쪼개어 분석 !
P는 (MK) 차원, Q는 (NK)개의 차원을 가지기 때문에 다음과 같이 정리할 수 있음.
- ∈ : User, Item Latent Matrix의 벡터
- : 유저 u의 아이템 i 선호도 추정값
다시 정리하면 이고, 여기서 이 최대한 R에 가까운 값을 가지도록 하는 P와 Q를 구하면 그것이 바로 추천을 위한 모델이 된다.
2. Stochastic Gradient Descent (SGD)를 사용한 MF
- 과정
- 잠재요인 개수 K를 정함.
- 주어진 k에 따라 P와 Q행렬을 만들고 초기화한다. 맨 처음엔 임의의 수로 채운다.
- P와 Q를 사용해 예측 평점 R^을 구한다.
- R에 있는 실제 평점에 대해 예측 평점 R^의 예측과 비교해서 오차를 구하고, 이 오차를 줄이기 위해 P, Q값을 수정한다. → SGD 사용
- 전체 오차가 미리 정해진 기준값 이하가 되거나 미리 정해진 반복 횟수에 도달할 때 까지 3번으로 돌아가 반복

3. SGD를 사용한 MF 기본 알고리즘 코드 분석

4. train/test 분리 MF 기본 알고리즘 코드 분석

5. MF의 최적 파라미터 찾기
- 잠재요인 수 K
: 늘릴수록 다양한 패턴을 학습할 수 있으므로 정확도가 높아진다. 하지만 학습 대상은 train set이므로 k가 지나치게 커지면 과적합 현상이 발생한다.
- SGD 반복횟수 iteration
: 마찬가지로 반복이 많아질수록 train set에 더 잘 맞도록 학습이 이루어질 것이므로 test set에 대해서도 정확도도 올라가지만, 지나치게 커지면 과적합이 발생한다.
- 최적 파라미터 찾는 과정
- 최적의 k를 찾기 위해 50~260까지 넓은 범위에 대해 10 간격으로 정확도(RMSE)를 계산
- 최적의 RMSE를 보이는 k를 확인한 후 이 숫자 전후 +-10의 k에 대해서 1 간격으로 다시 RMSE를 계산해 최적의 k를 찾는다.
- iterations는 학습과정에서 충분히 큰 숫자를 주어서 RMSE가 어떻게 변화하는지 관찰해 주어진 k에 대해 최적의 iterations 값을 구한다.
- 코드 실행결과 (코드 분석 생략)
-
k가 커질수록 최적의 iterations 수가 증가하는 경향이 있음
→ k가 커지면 학습해야할 변수(P, Q 행렬의 원소)의 수가 많아지기 때문에 더 많은 반복이 필요하다고 유추
-
코드를 실행해보면 k=240일 때 RMSE=0.90876로 가장 좋은 결과를 보임.
→ 그래프로 보면 사실상 k=200 이후로는 큰 변화가 없기에 k=200을 최적의 k로 간주한다.
→ 또한 iterations=250정도에서 최적의 결과를 보여준다.
-
- 같은 방법으로 알파 베타에 대해서도 최적의 값을 구할 수 있지만, 각각의 파라미터에 대한 최적값을 단순 조합한 것이 최적이라는 보장은 없다.
- ex. k의 최적값을 구할때 사용한 알파, 베타의 값이 최적의 알파, 베타 값과 다르다면 최적의 알파, 베타값을 사용한 k값은 달라질 수 있기 때문이다.
- 그래서 최적의 파라미터를 구할 때는 하나씩 최적값을 구해 고정시킨 후 다음 파라미터 값을 구한다.
6. MF와 SVD
- 특이값분해(Singular Value Decomposition, SVD)
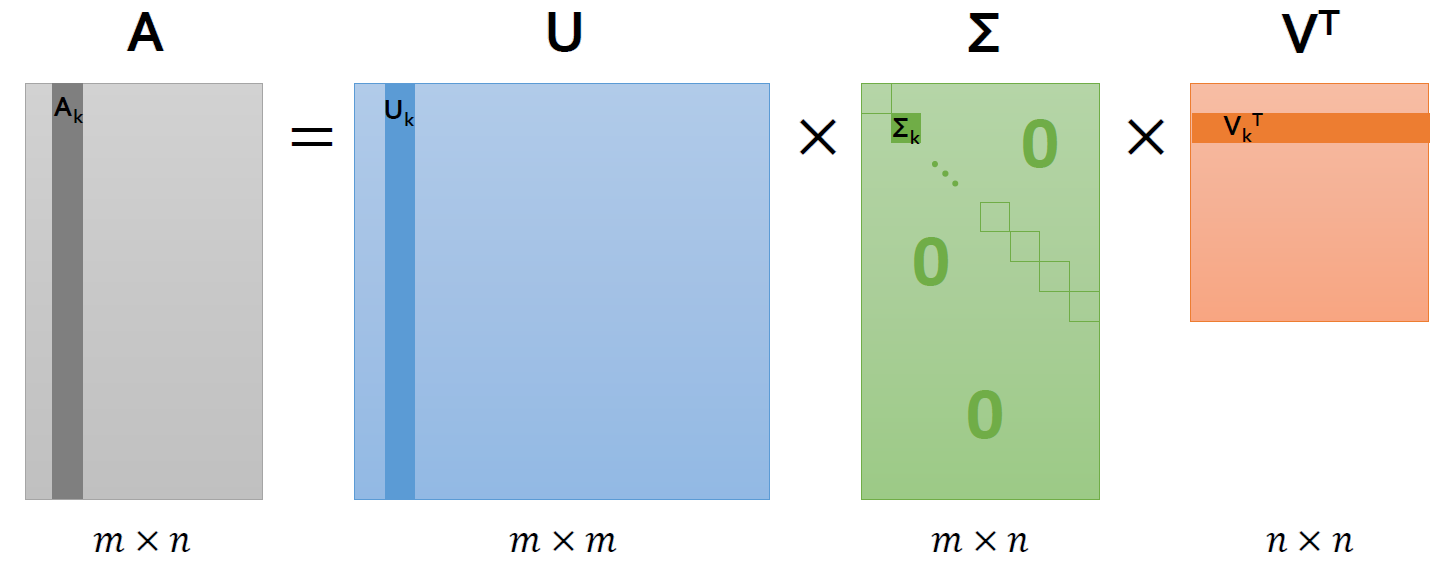
: (m×n)차원의 A행렬을 다음과 같이 분해하는 방법론
-
U : (m×m)차원의 직교행렬
-
V : (n×n)차원의 직교행렬
-
Σ : (m×n) 직사각 대각행렬 (대각성분 이외의 모든 값은 0)
-
SVD는 데이터를 3개의 행렬로 분해해서 이를 학습시키고 이 3개의 행렬로 원래의 행렬을 재현하는 기법
-
MF는 원래 데이터를 P(MK), Q(NK) 2개의 행렬로 분해한다는 차이가 있다.
-
SVD는 원래의 행렬에 null값을 허용하지 않기 때문에 추천시스템 분야에서는 사용되지 않는다.
-
그에 반해 MF는 null값이 있더라도 P, Q행렬은 null이 없이 학습되며, 학습이 끝나고 나면 P, Q를 사용하여 원래 행렬에서 빠져 있는 null값도 상당히 정확하게 예측할 수 있다.
-
하지만 과거에 MF를 SVD로 부르던 관행이 굳혀져 추천시스템 분야에서 SVD를 MF와 같은 의미로 사용한다. (ex. SVD++기법같은 것도 사실은 SVD에 기반한 기법이 아니라 MF에 기반한 기법이다.)
출처 - 책 [Python을 이용한 개인화 추천시스템]
