RDB
관계영 데이터베이스로 불린다. 말 그대로 관계형 모델을 기반으로 하는 데이터 베이스로 이를 유지하고 관리하기 위한 시스템을 RDBMS라고 부릅니다.
이러한 RDBMS는 주로 SQL(Structured Query Lang)을 이용해 데이터를 조회하고 관리하게 됩니다.
| 명령어 종류 | 명령어 | 설명 |
|---|---|---|
| 데이터 조작어(DML : Data Manipulation Language) | SELECT | DB에 들어있는 데이터를 조회하거나 검색하기 위한 명령어를 말함(RETRIEVE라고도 함) |
| INSERT, UPDATE DELETE | DB의 테이블에 들어 있는 데이터에 변형을 가하는 종류(데이터 삽입 수정, 삭제)의 명령어들을 말함 | |
| 데이터 정의어(DDL : Data Definition Language) | CREATE, ALTER, DROP, RENAME, TRUNCATE | 테이블과 같은 데이터 구조를 정의하는데 사용되는 명령어들로 (생성, 변경 삭제, 이름변경) 데이터 구조와 관련된 명령어들을 말함) |
| 데이터 제어어(DCL : Data Control Language) | GRANT, REVOKE | DB에 접근하고 객체들을 사용하도록 권한을 주고 회수하는 명령어들을 말함 |
| 트랜잭션 제어어(TCL : Transaction Controler Language) | COMMIT, ROLLBACK, SAVEPOINT | 논리적인 작업의 단위를 묶어서 DML에 의해 조작된 결과를 작업단위(트랜잭션) 별로 제어하는 명령어를 말함. |
특징
- 2차원 데이터로 표현됩니다. (행/열)
- 상호관련성을 가진 테이블의 집합으로 구성됩니다.
- 테이블 사이의 관계를 외래키로 나타냅니다.
- 스키마 변경이 어렵습니다.
- 수직 확장(Vertical Scale) 가능하지만, 수평 확장(Horizontal Scale)이 어렵습니다.
- 유지관리 비용 / 사용 요금이 비쌉니다.
- SQL을 사용해 데이터를 질의합니다.
- ACID 성질을 갖습니다.
여기서 몇 가지만 자세히 다루고 넘어갑시다.
스키마 변경이 어렵다
RDB는 매우 정교한 초기 설계로 만들어집니다.
테이블 사이에 서로 의존성이 있고, 쳇바퀴처럼 맞물려 돌기 때문에 데이터 타입을 바꾼다던지, 새로운 열을 추가한다던지 하는 작업은 실제 production 환경에서 사실상 불가능합니다.
보통 기존 테이블을 복제해서 거기에 수정을 가한 뒤, 기존 테이블과 교체하는 방식을 택합니다.
스케일링
일반적으로 수직 확장(Vertical Scale)은 하드웨어 스펙의 확장을 의미하고,
수평 확장(Horizontal Scale)은 양적 확장을 의미합니다.
RDB가 수직 확장이 더 용이하고 수평 확장이 어려운 이유는, 데이터가 여러 테이블에 의존해있기 때문입니다.
데이터가 서버에 분산될 경우 이를 중간에서 잘 중재해주는 역할이 중요해지는데, 그럴 바에는 그냥 좋은 서버를 하나 사서 분산 처리에 대한 신경을 쓰지 않는게 더 좋기 때문입니다.
ACID
- Atomicity (원자성)
- Consistency (일관성)
- Isolation (고립성)
- Durability (지속성)
데이터베이스 트랜잭션의 성질을 나타내는 네 가지 요소를 뜻합니다.
NoSQL
Non-SQL이라고도 하고, Not only SQL이라고도 합니다.
이들은 관계형이 아닌 데이터 모델을 총칭하고, Document 모델 / Key-Value 모델 / Graph 모델 / Wide-Column 모델 등 다양한 데이터 모델이 있습니다.
특징
- 다양한 방식으로 데이터를 표현합니다.
- 테이블(혹은 컬렉션 혹은 또 다른 명칭) 사이에 딱히 명시된 제약이나 규칙이 없습니다.
- 스키마가 고정적이지 않고, 매우 유연합니다.
- 수평적 확장(Horizontal Scale)이 쉽습니다.
- 코스트가 저렴하고 오픈소스도 많습니다.
- 연산이 빠르고 빅데이터 & 실시간 연산에 적합합니다.
다양한 방식으로 데이터를 표현
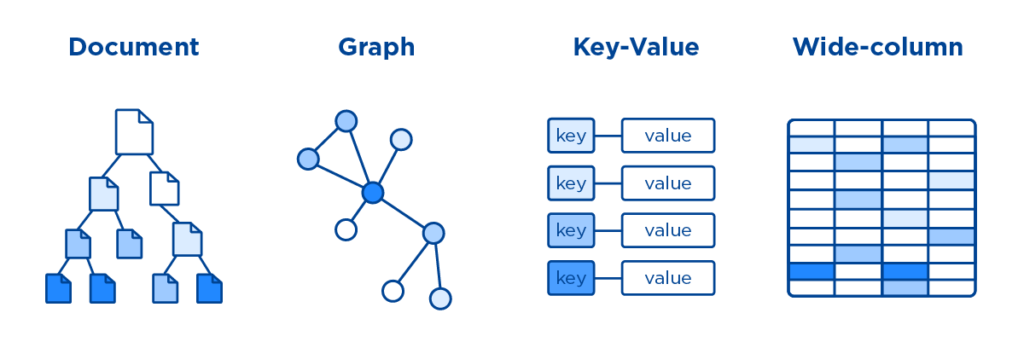
- Document 모델은 레코드 하나를 오브젝트(도큐먼트) 형식을 표현합니다.
자유로운 스키마 구조를 가지며 구조가 확정되지 않은 데이터를 밀어넣고, 자유롭게 작업하기 좋습니다.
MongoDB나 ArangoDB가 대표적인 예시입니다. - Graph 모델은 데이터를 Vertex와 엣지로 그래프에 표현하는 방식입니다.
데이터 사이의 유기적인 관계를 표현하기에 적합합니다
대표적으로 Neo4j와 ArangoDB, Gremlin 등이 있습니다. - Key-Value 모델은 하나의 키 값에 값을 맵핑하는 해시 구조의 데이터 모델입니다.
빠르게 데이터에 접근할 수 있는 장점이 있습니다.
대표적으로 Memcached와 Redis가 있습니다. - Wide-Column 모델은 테이블 형태를 취하지만 행마다 갖는 컬럼의 형태가 고정되어 있지 않은 데이터 모델입니다.
대표적으로 Cassandra가 있습니다.
RDB vs. NoSQL
그럼 이제 둘을 비교해봅시다.
| 분류 | RDB | NoSQL |
|---|---|---|
| 관계 사용 여부 | O | X |
| 스키마 구조 | 정적인 구조를 가짐 | 유연한 구조를 가짐 |
| 확장성 | 수직 확장 용이(용량을 늘리는게 쉬움) | 수평 확장 용이(여러 대 늘리는 게 쉬움) |
| 확장시 다운 타임 | 있을 수 있음 | 거의 없음 |
| 조회 시 특징 | 복잡한 쿼리와 Join 연산 가능 | 구조화된 쿼리 언어가 없는 경우도 많고, 일반적으로 Join이 없음 |
| 적합한 사용처 | OLTP(트랜잭션 처리)에 적합 | OLAP(분석 처리)에 적합 |
언제 어떤 DB를 사용할까?
RDB - MySQL
보통 관계형으로 잘 정리될 수 있는 고객 데이터나 비즈니스 데이터, 결제 데이터 등을 다룰 때 사용합니다.
- 테이블마다 연관되는 키가 잘 드러나기 때문에 관계형으로 표현하는게 매우 효율적
- 트랜잭션을 통해 OLTP의 역할을 해야할 때
- 트랜잭션의 ACID가 보장되어야 할 때
NoSQL - MongoDB
MongoDB는 Document 모델이기 때문에 넣는 데이터의 스키마에 구애받을 필요가 없습니다.
- 중간 분석 데이터를 편하게 밀어넣어 두고, 꺼내쓰기가 편리함
- SQL에서는 간단한 쿼리문이 MongoDB의 언어로 바귀면 수행하기가 어렵기 때문에 애초에 데이터를 잘 가공해서 넣어둠
- 최종적으로 사용할 데이터를 넣어두는 용도로 많이 씀
- 막쓰기 좋으나 심지어 안정적임
NoSQL - Redis
Redis는 in-memory Key-Value 모델이다. 때문에 데이터 접근 & 대기시간이 매우매우 짧습니다.
따라서 주로 데이터 캐시, 메시지 브로커 & 큐로 사용됩니다.
- 동시에 대량의 트래픽을 처리하는 웹서비스에서 데이터를 캐시하는 중간 DB 역할로 많이 사용합니다.
- celery, airflow 등의 분산 처리 프레임워크에서 메시지 브로커로 많이 사용합니다. (분산 처리이기 때문에 워커나 태스크 사이의 데이터를 주고받을 때 중개자가 필요함. 그 역할을 수행함)
