
1장 DBMS 아키텍처
SQL 레벨업이라는 도서를 정리한 내용입니다.
DBMS 아키텍처 개요
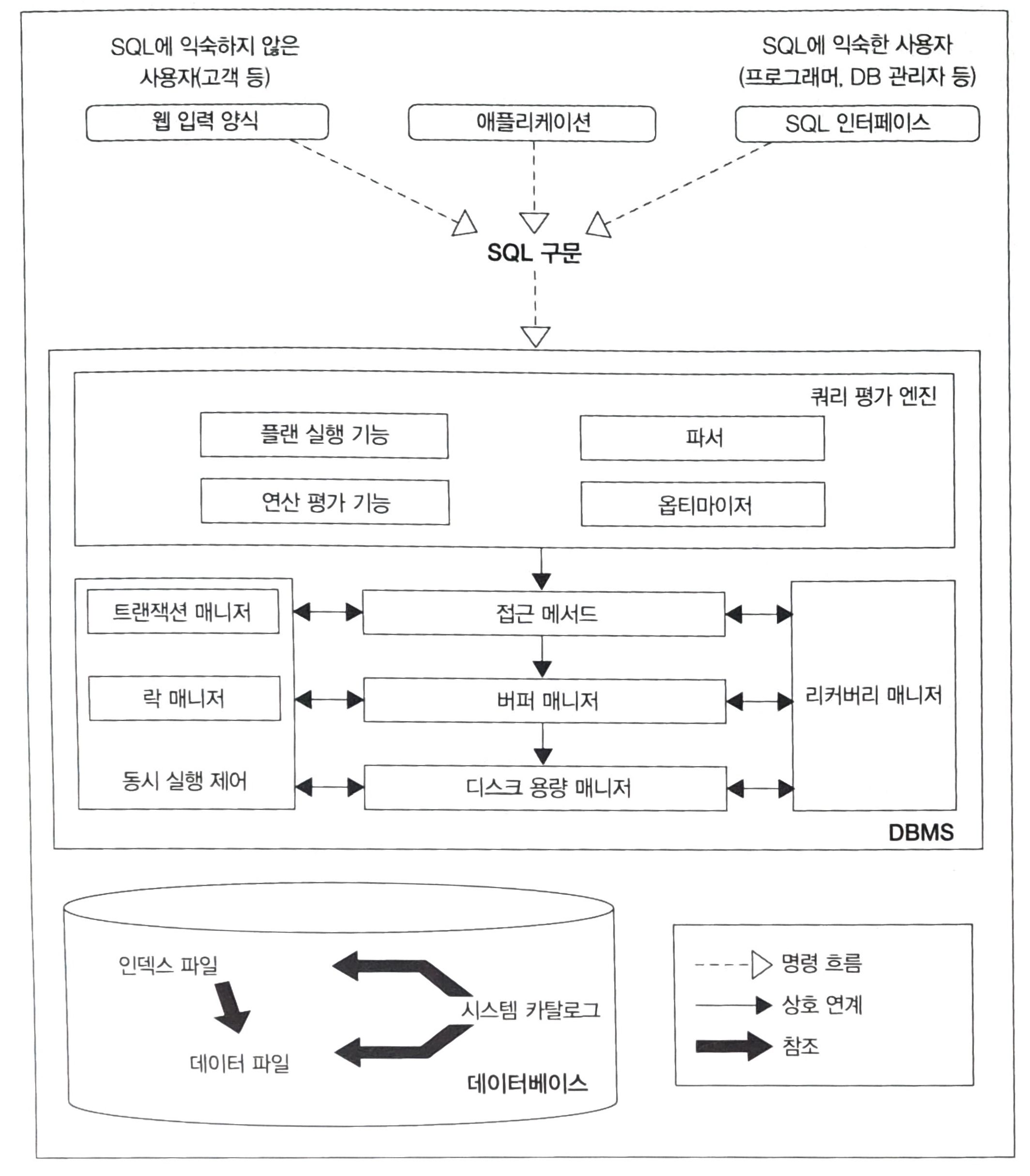
일반적인 DBMS 아키텍처는 위와 같은 구조를 가지고 있다.
DBMS 내부의 기능을 알아보자.
쿼리 평가 엔진
- 사용자로부터 입력받은 SQL 구문을 분석, 실행 계획(Explain Plan, 어떤 순서로 데이터에 접근하는지)을 결정한다.
- 실행 계획을 기반으로 데이터에 접근하는 방법을 접근 메서드(Access Method)라고 한다.
버퍼 매니저
- DBMS는 버퍼라는 메모리 영역을 확보하는데, 이를 관리한다.
- 디스크 용량 매니저와 연동되어 작동한다.
디스크 용량 매니저
- 데이터를 어디에 어떻게 저장할지 관리한다.
- 데이터의 I/O를 제어한다.
트랜잭션 매니저와 락 매니저
- DBMS에서 각각의 처리는 DBMS 내부에서 트랜잭션이라는 단위로 관리되는데, 이를 정합성(무모순성)을 유지하면서 실행시킨다.
- 필요한 경우 데이터에 락을 절어 다른 사람의 요청을 대기시킨다.
리커버리 매니저
- 시스템의 장애를 대비한다.
- 데이터를 정기적으로 백업하고, 문제가 일어났을 때 데이터를 복구한다.
DBMS와 버퍼
버퍼 매니저가 어떤 기능을 수행하는지 알아보자.
메모리는 한정된 자원이다. 따라서 데이터를 버퍼에 어떠한 식으로 확보할지 정하는 부분에서 트레이드오프가 발생한다.
DBMS와 기억장치
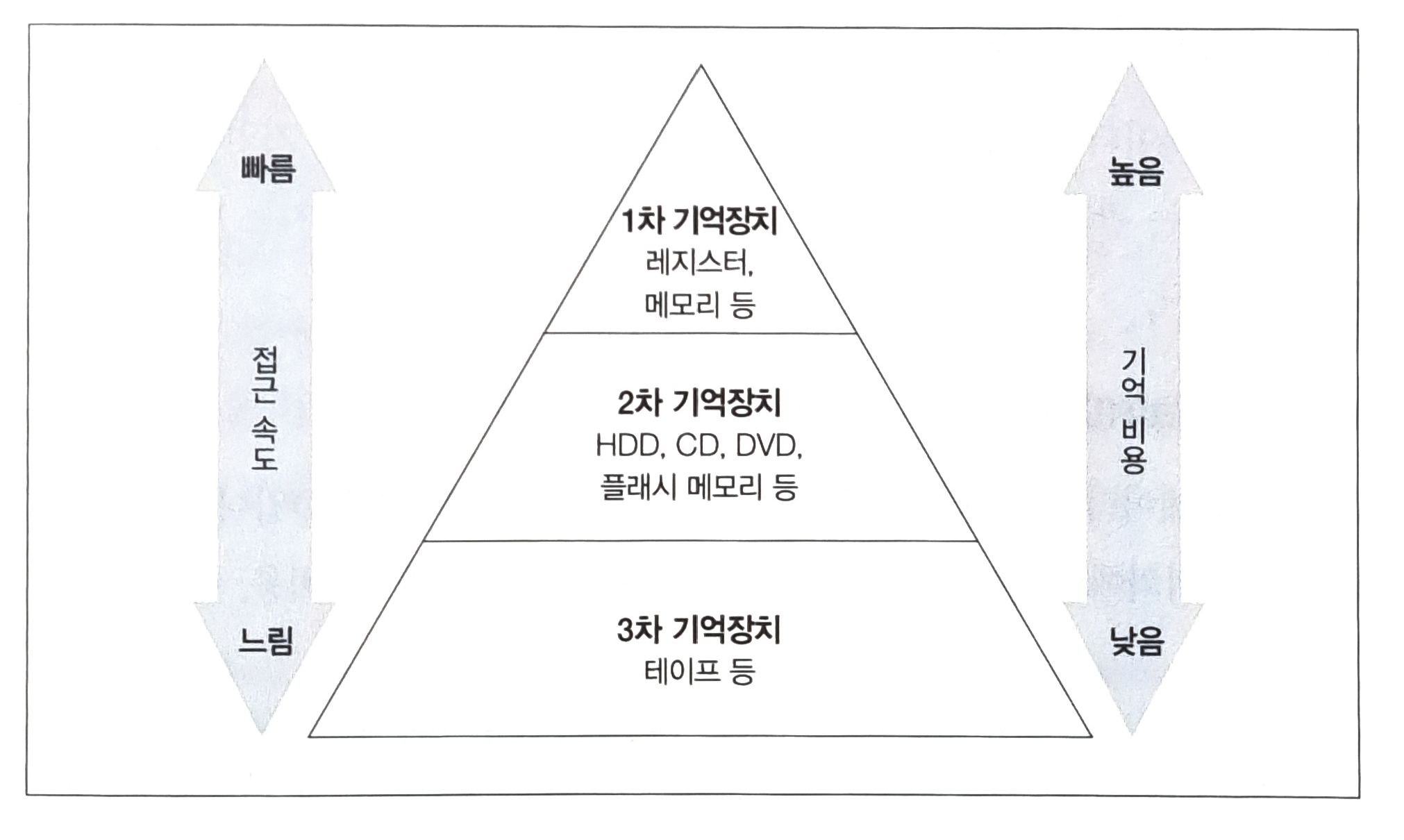
기억장치의 분류를 계층으로 나타낸 그림이다.
여기서 기억비용은 데이터를 저장하는데 소모되는 비용을 말한다.
HDD, SDD
- 현재 DBMS는 데이터를 HDD 또는 SSD에 저장한다.
메모리
- 디스크에 비해 기억비용이 비싸다. (대충 수십만~수백만 배 차이)
- 따라서 DB의 내부 데이터를 모두 올려놓는 것은 불가능하다.
버퍼를 활용한 속도 향상
- 그럼에도 메모리를 사용하는 이유는 성능 향상 떄문이다.
- 일반적인 SQL 구문의 실행 시간 대부분을 I/O에 사용한다.
- 따라서, 자주 접근하는 데이터를 메모리 위에 올려놓으면 성능이 무척 향상된다.
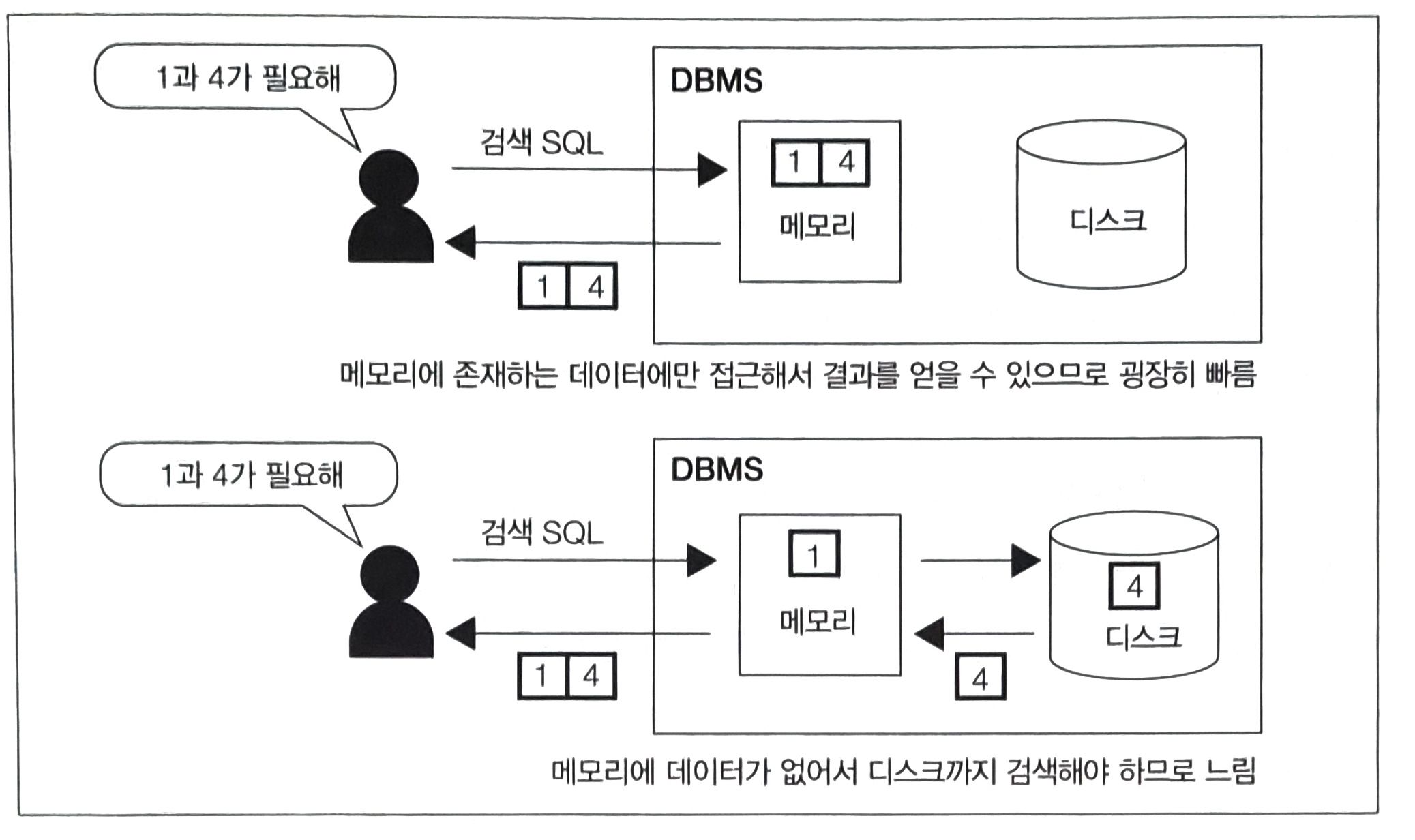
메모리 위의 두 버퍼
DBMS가 사용하는 버퍼는 크게 두 종류다.
- 데이터 캐시
- 로그 버퍼
이러한 버퍼는 사용자가 용도에 따라 크기를 변경할 수 있다.
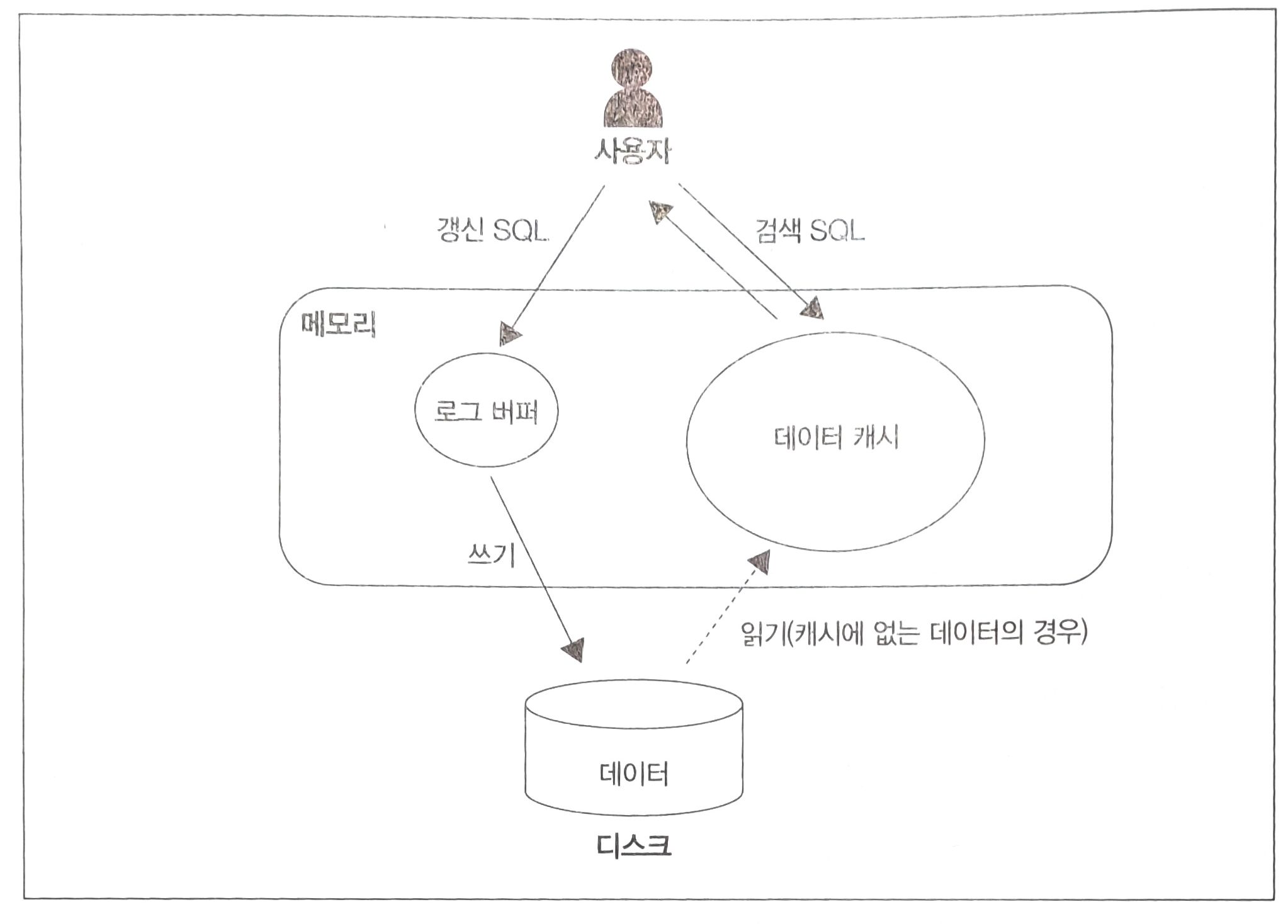
데이터 캐시
- 디스크에 있는 데이터의 일부를 메모리에 유지하기 위해 사용하는 영역이다.
- 데이터 캐시에 필요로 하는 데이터가 전부 있다면 디스크를 접근하지 않고 처리를 수행한다.
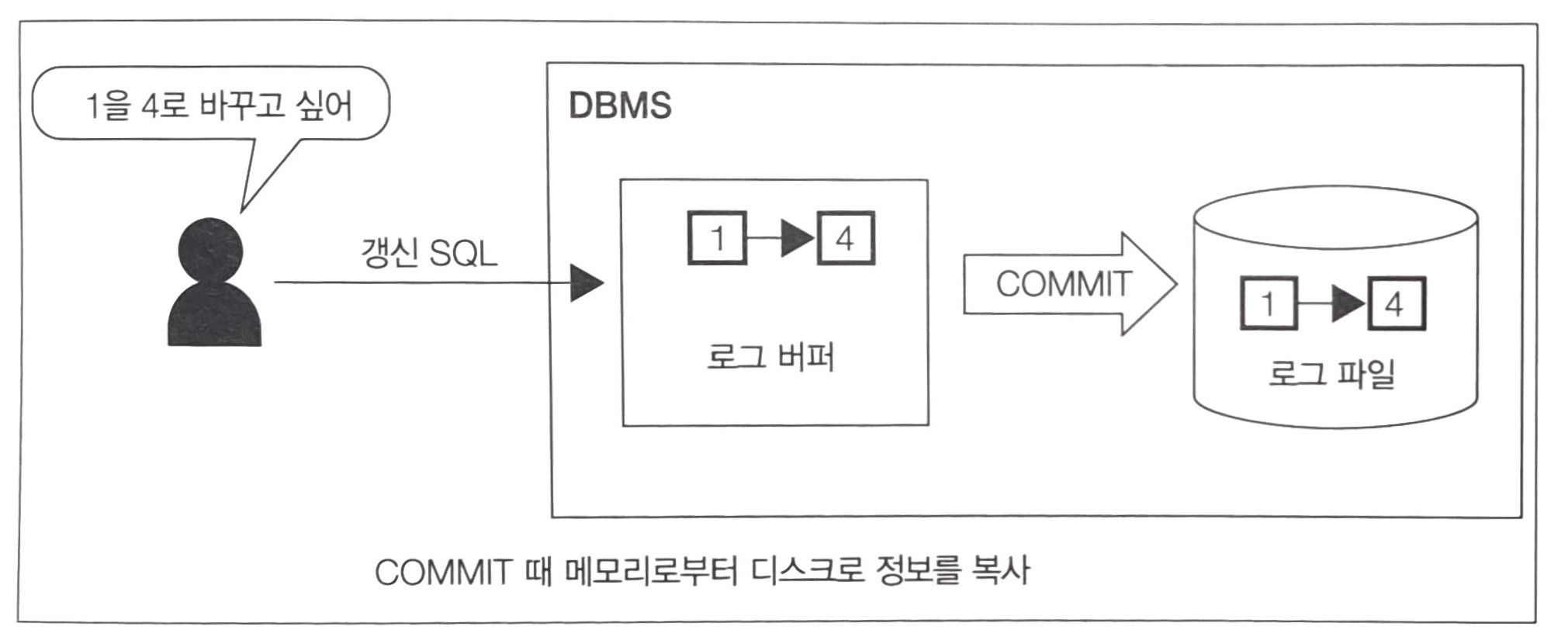
로그 버퍼
- 로그 버퍼는 갱신처리(INSERT, DELETE, UPDATE, MERGE)와 관련있다.
- 갱신처리가 이루어지는 과정
- 갱신과 관련된 SQL 구문을 받으면 로그 버퍼에 변정 정보를 보낸다.
- 이후 디스크에 변경을 비동기적으로 수행한다.
- 갱신처리는 시간소요가 많이 되기에 이처럼 수행된다.
메모리의 성질이 초래하는 트레이드 오프
메모리는 여러 장점만큼 단점도 많이 가지고 있다.
- 가격이 비싸다.
- 휘발성을 가진다, 즉 영속성이 없어 데이터가 지속되지 못한다.
휘발성의 가장 큰 문제는 메모리 위의 데이터가 전부 사라졌을 때 발생한다.
로그 버퍼 위의 데이터가 디스크에 저장되기 전 사라저버리면 복구가 불가능하다.
이는 비즈니스적인 관점에서 심각한 문제이다.
이를 회피하기 위해 커밋 시점에 갱신정보를 로그 파일(영속적인 저장소에 존재함)에 작성해 정합성을 지키고자 한다.
이 때문에 새로운 트레이드 오프가 발생하는데, 커밋 시에는 디스크에 동기 접속이 일어난다. (일부 DBMS는 설정으로 비동기 접속으로 변환 가능하지만... 극단적인 트레이드오프이다.)
시스템 특성에 따른 트레이드 오프
데이터 캐시와 로그 버퍼의 크기
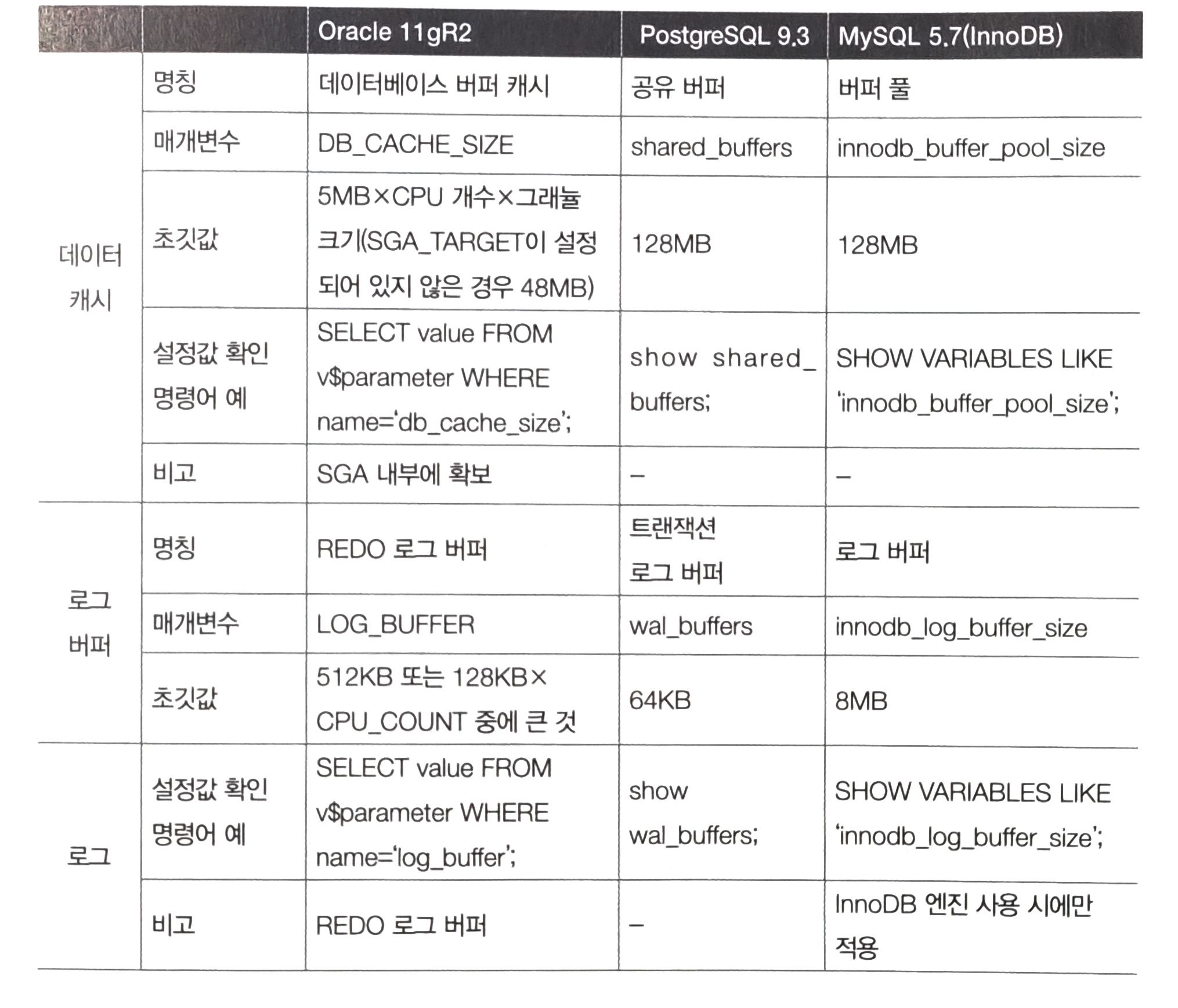
여러 DBMS에서 제공하는 기본 데이터 캐시와 로그 버퍼를 비교하면 로그 버퍼의 값이 적다는 것을 알 수 있다.
이는 DB가 검색을 메인으로 처리한다고 가정하기 때문이다.
일반적으로 검색 시에는 수백만에서 수천만 되는 레코드를 처리하지만 갱신 시에는 많아야 수만 건 정도 밖에 안된다.
실제로도 많은 DBMS가 물리 메모리에 여유가 있다면 데이터 캐시를 되도록 많이 할당하라고 권장한다.
(MySQL 5.7 공식문서에서도 DB전용 서버에서는 물리 메모리의 80%를 차지해도 괜찮다고 쓰여있다.)
설계자는 갱신 처리와 검색 처리의 우선 순위를 정하여 적절하게 리소스를 배분해야 한다.
추가적인 메모리 영역 '워킹 메모리'
워킹 메모리란?
- DBMS는 일반적으로 2개의 버퍼 외에 워킹 메모리라는 영역을 가지고 있다.
- 이는 정렬(일반적으로 ORDER BY), 해시(테이블 조인) 관련 처리에 사용되는 작업용 영역이다.
- 가변적인 용량을 가지고 정렬, 해시가 필요할 때 사용되고, 종료하면 해제되는 임시 영역이다.
- 여러개의 SQL 구문들이 나눠서 사용하므로 동시에 실행하면 메모리의 범위를 넘어가는 일이 생기기도 한다.
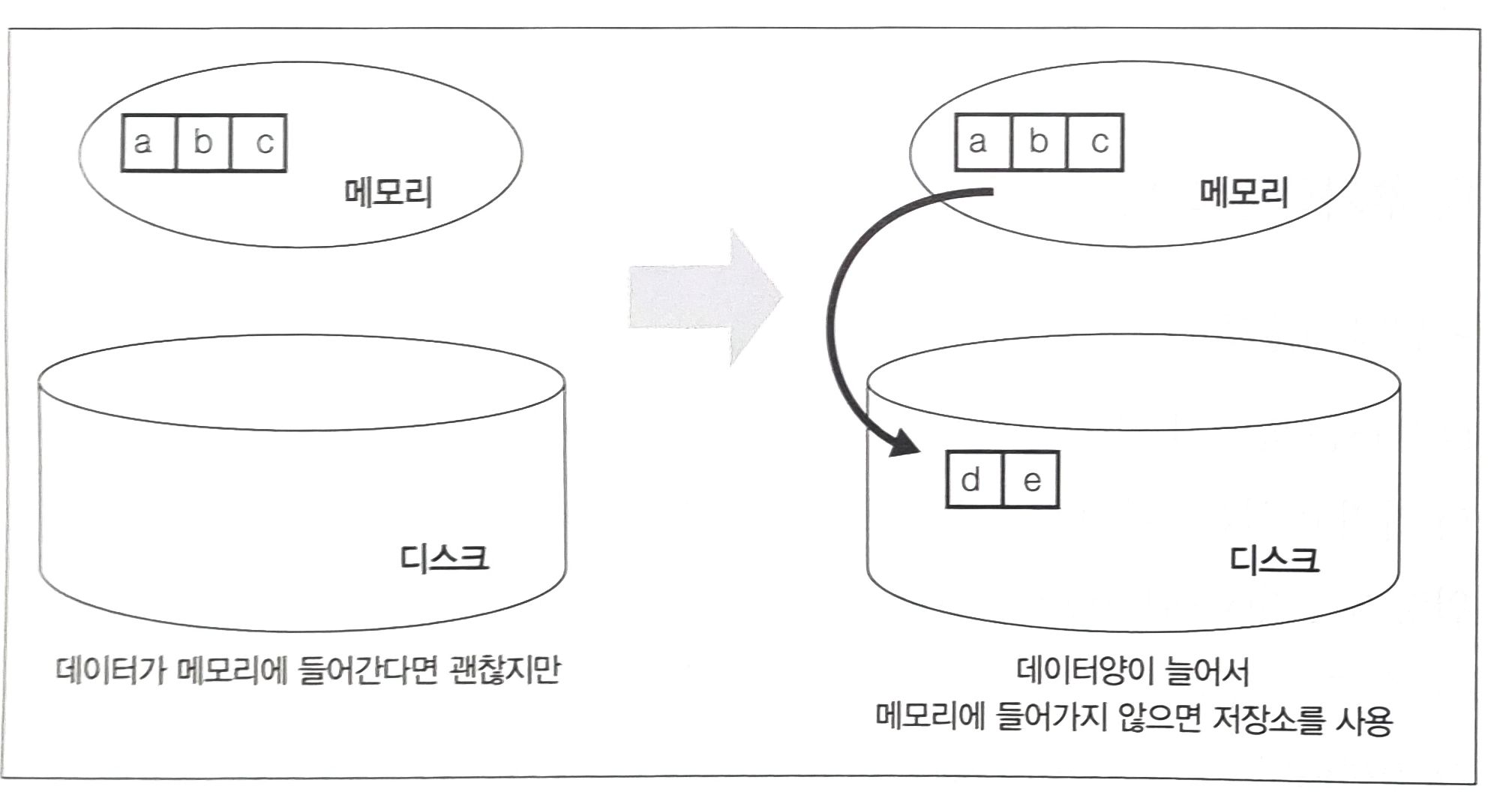
워킹 메모리가 부족하다면?
워킹 메모리가 다루려는 데이터보다 양이 부족하다면 디스크를 사용한다. 즉, 처리가 굉장히 느려지게 된다.
워킹 메모리를 부르는 명칭
| DBMS | 명칭 | 매개변수 | 기본값 |
|---|---|---|---|
| Oracle 11g R2 | PGA(Program Global Area) | PGA_AGGREGATE_TARGET | 10MB or SGA 크기의 20% 중 큰 것 |
| PostgreSQL 9.3 | 워크 버퍼 | work_mem | 8MB |
| MySQL 5.7 | 정렬 버퍼 | sort_buffer_size | 256KB |
워킹 메모리가 부족할 때 사용하는 임시적인 영역
- Oracle : 임시 테이블 스페이스(TEMP Tablespace)
- Microsoft SQL Server : TEMPDB
- PostgreSQL : 일시 영역(pgsql_tmp)
DBMS와 실행 계획
RDB를 조작할 때는 SQL 이라는 전용 언어를 사용한다.
DBMS는 이 SQL을 해석해 처리하고 결과를 제공해준다. 그러므로 우리는 내부 절차를 알 필요가 없다.
하지만 성능 문제 등 내부 절차를 확인해야 할 때가 있다.
DBMS의 쿼리 처리 흐름
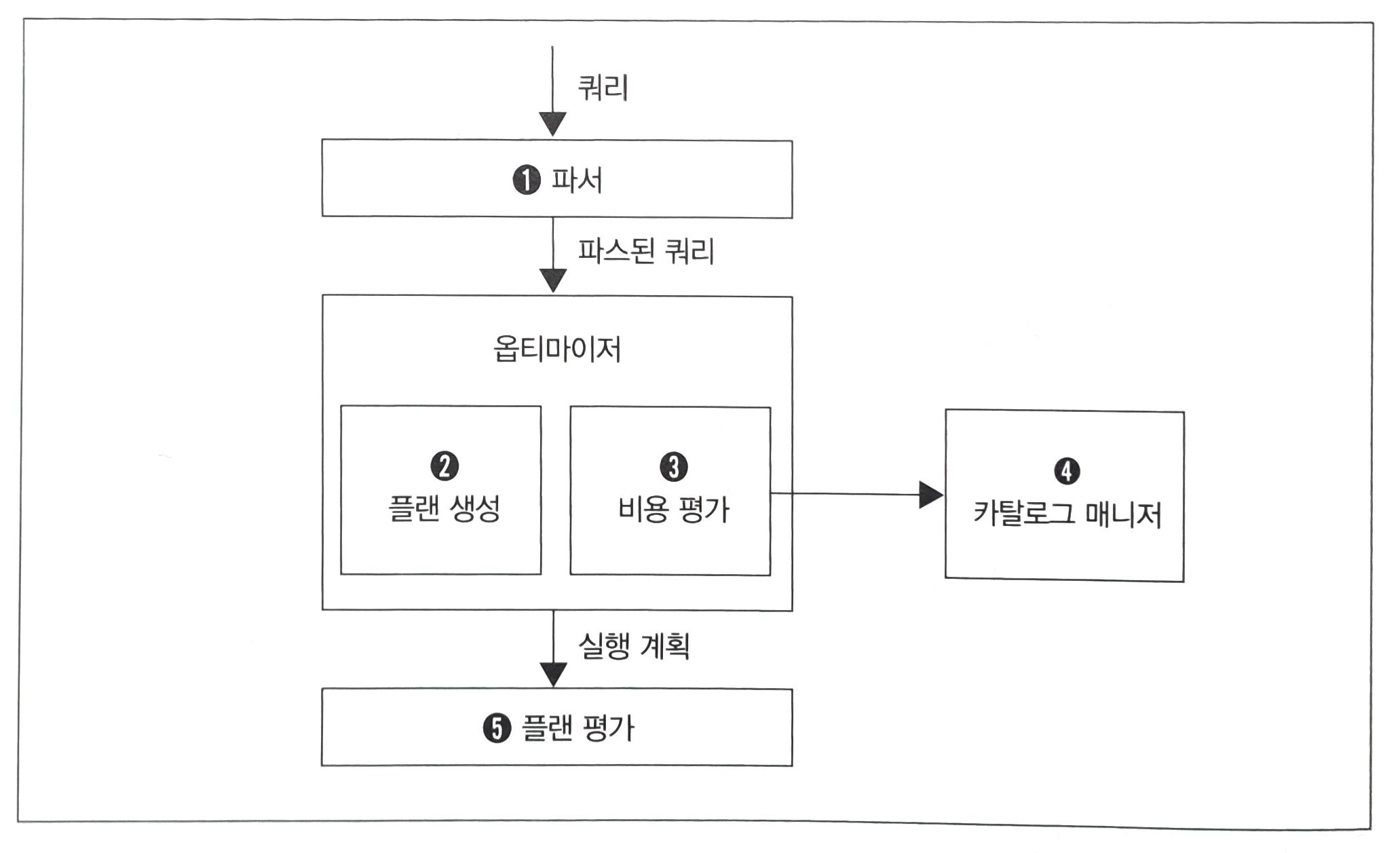
파서(parser)
- SQL 구문을 분석한다.
- 사용자의 실수를 잡아준다. (ex. FROM 없는 테이블)
- SQL 구문을 정형적인 형식으로 변환한다.
옵티마이저(optimizer)
- 데이터 접근법(실행 계획)을 최적화 한다.
- 인덱스 유부, 데이터 분산, 편향 정도 등 여러 조건을 고려해서 낮은 비용을 가진 계획을 선택한다.
카탈로그 매니저(catalog manager)
- DBMS의 내부 정보(카탈로그)를 모아놓은 테이블이다.
- 테이블, 내부 정보가 저장되어 있다.
플랜 평가(plan evaluation)
- 옵티마이저가 여러 실행 계획중 최적의 실행 계획을 선택하는 것을 말한다.
- 이는 사람이 쉽게 읽을 수 있도록 작성 된 일종의 '계획서'이다.
옵티마이저와 통계 정보
옵티마이저가 효율적인 플랜을 선택하지 않는 경우가 있는데, 주로 통계 정보가 부족해서다.
카탈로그에 포함되는 정보
- 테이블의 레코드(row) 수
- 테이블의 필드 수와 필드 크기
- 필드의 카디널리티(값의 중복되는 개수)
- 필드 값의 히스토그램(어떤 값이 분포되어 있는가)
- 필드 내부의 NULL 수
- 인덱스 정보
이러한 정보를 사용해 카탈로그를 만들고 이를 기반으로 옵티마이저가 계획을 세우게 된다.
실제 테이블에 변화가 일어나도 카탈로그를 갱신하지 않으면 옵티마이저는 갱신되지 않은 카탈로그를 기준으로 계획을 세우기 때문에 잘못된 계획을 세우게 될 수 있다.
올바른 통계 정보가 모이는 것은 SQL 성능에 중요한 문제이다.
따라서 테이블의 데이터가 많이 변하면 카탈로그의 통계 정보도 함께 갱신해야 한다.
통계 정보 갱신은 많은 시간을 소요하는 작업이므로 갱신 시점을 잘 설계해야 한다.
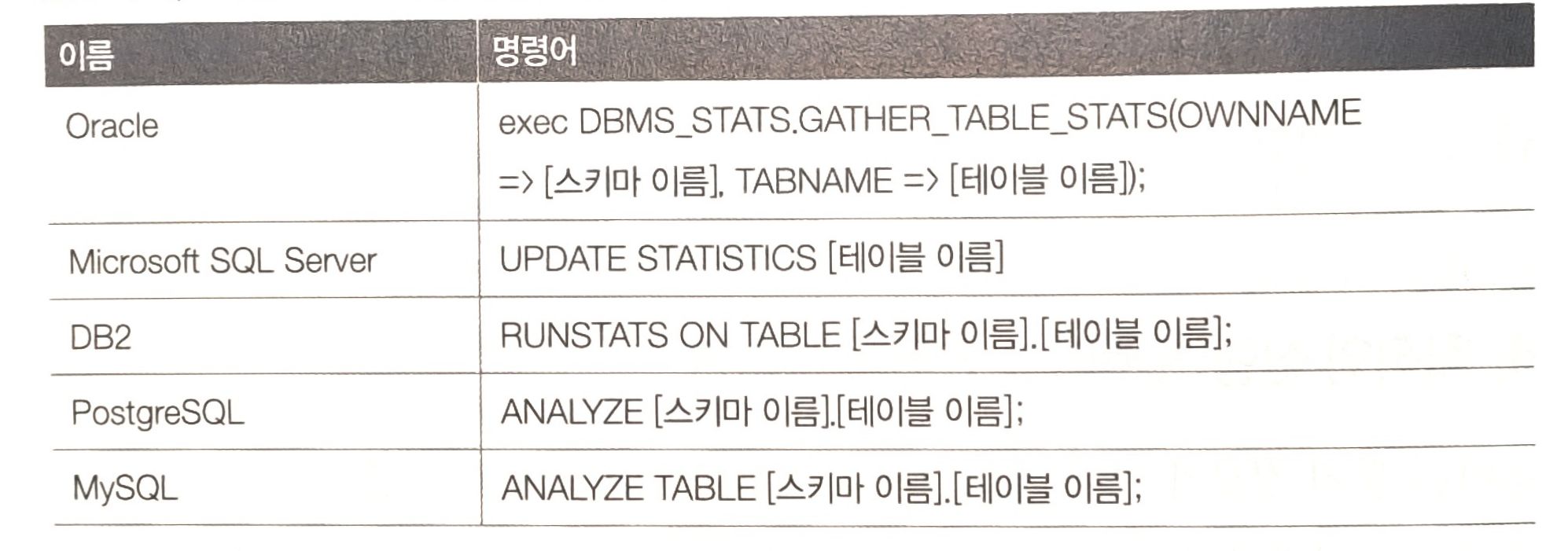
대표적인 DBMS의 통계 정보 갱신 명령어
실행 계획이 SQL 구문의 성능을 결정
이 부분은 이론보다 기술을 사용하는 내용이 많아서 이론적인 부분만 정리하였습니다.
실행 계획 확인 방법

Oracle 과 SQL Server는 해당 명령어 이후에 구문을 입력한다.
실행 계획 해석
실행 계획의 출력 포맷은 DBMS에 따라 다르지만 공통적으로 포함하는 값이 있다.
- 조직 대상 객체
- 어떤 객체를 조작하는지 알려준다.
- 객체에 대한 조작의 종류
- Oracle의 "TABLE ACCESS FULL", PostgreSQL의 "Seq Scan"
- 조작 대상이 되는 레토드 수
- 어느정도의 레코드가 처리되는지 알려준다.
- SQL 구문 전체의 실행 비용을 파악하는데 중요한 지표가 된다.
실행 계획의 실행 비용과 실행 시간
실행 계획에서 표시하는 시간이나 조작 레코드 수는 어디까지나 추정 값일 뿐 지표로 사용할 수 없다.
다만, 일부 DBMS는 구문을 실행해서 실제 시간과 실제 조작 레코드 수를 표시하는 기능을 지원한다.
실행 계획의 중요성
최근의 옵티마이저는 우수하지만 완벽하지 않다.
실행 계획이 잘못 설계되었다고 판단되는 경우, 튜닝을 한다. (수동으로 실행 계획 조작)
사실 실행 계획을 본다던가, 변경하는 것은 물리계층을 은폐한다는 RDB의 목표와 반대되는 일이지만 기술이 완벽하지 않은 지금은 필요한 일이다.
