kafka
1.kafka - 1

데이터를 보내면(메시지) 여러 파티션중 하나에 적재큐 구조와 동일하다.컨슈머가 데이터 가져가도 파티션 데이터는 삭제되지 않는다.배치 데이터 -> 일괄적으로 모아서 한번에 처리, 한정된 데이터 처리, 지연 발생스트림 데이터 -> 무한 데이터 처리, 지속, 분 단위 이하
2.kafka - 2

브로커중 한대가 컨트롤러 역할.다른 브로커들 상태를 계속 체크카프카는 지속적 데이터 처리, 브로커가 비정상이면 빠르게 뺀다.리더 재분배컨슈머가 데이터를 가져가도 토픽 데이터 삭제 X오직 브로커만 데이터 삭제 가능.삭제는 파일 단위로 ->'로그 세그먼트'특정 데이터 삭제
3.kafka - 3

토픽 - 한 개 이상의 파티션 소유파티션 - 데이터 저장(레코드), FIFO, 삭제X라운드 로빈 방식장점 : 한개 브로커에 지속적으로 처리되는게 아니라 분산되어 데이터 처리통신집중 막고, 선형 확장하여 데이터 증가 대응 가능데이터 쏠림 방지kafka-reassign-
4.Kafka - cli

bin -> 실행파일config -> 설정파일broker.id -> 0 ::테스트용listener -> 받을 ip주소bin/zookeeper-server-start.sh config/zookeeper.propertiesbin/kafka-server-start.sh co
5.Kafka - topics.sh

클러스터 정보와 토픽 이름은 토픽을 만들기 위한 필수 값bin/kafka-topics.sh --create --bootstrap-server 클러스터이름:포트 --topic 토픽이름\--describe : 설명, 설정 확인\--alter : 파티션 갯수 증가파티션 줄이
6.Kafka - config.sh

옵션 설정ex) bin/kafka-config.sh --bootstrap-server 클러스터이름 --add -config min.insynce.replicas=2 --topic 토픽이름\-> 설정 수정
7.Kafka - console-producer.sh

토픽 데이터 테스트용도로 사용bin/kafka-console-producers.sh --bootstrap-server 로컬카프카브로커 --topic 토픽이름이렇게 하면 > 이게 화면에 나온다.자기가 원하는 글 적으면 된다.설정이 없으면 key-value로 설정된다.ke
8.Kafka - console-consumer.sh

topic에 있는 데이터를 임시 조회하기 위해 사용\--from-beginning -> 토픽에 저장된 가장 처음 데이터부터 출력\--property print.key=true\--property key.separator="-"\--max-message n -> 최대 컨
9.Kafka - consumer-groups.sh

bin/kafka-consumer-groups.sh --bootstrap-server my-kafka:9092 --list -> 그룹 리스트 확인bin/kafka-consumer-groups.sh --bootstrap-server my-kafka:9092 --group
10.나머지 커맨드 라인 툴

카프카 프로듀서로 퍼포먼스를 측정할 때 사용bin/kafka-producer-perf-test.sh --producer-props bootstrap.servers=my-kafka:9092 --topic 토픽이름 --num-records 숫자 -- throughput 숫
11.kafka - 토픽 생성

브로커의 옵션에 따라 생성이 된다.명시적으로 생성하는 것이 좋다.데이터 특성에 따라 다르게 생성하는게 좋다.동시 데이터 처리량이 많아야 하는 토픽의 경우 파티션의 개수를 크게 설정 가능단기간 데이터 처리만 필요한 경우 보관 기간 옵션을 짧게 설정할 수 있다.토픽에 들어
12.kafka - 프로듀서
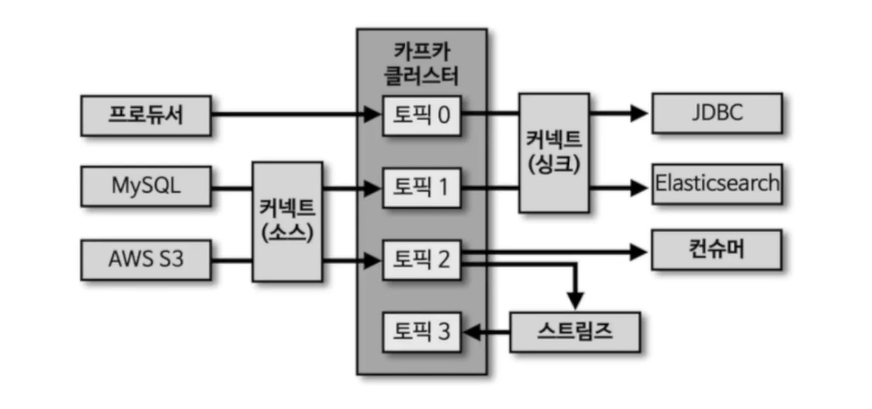
데이터의 시작점카프카에 필요한 데이터를 선언하고 브로커의 특정 토픽의 파티션에 전송데이터를 전송할 때 리더 파티션을 가지고 있는 카프카 브로커와 직접 통신한다.카프카 브로커로 데이터를 전송할 때 내부적으로 파티셔너, 배치 생성 단계를 거친다.ProducerRecord
13.kafka.kafka

Kafka.scala 파일은 Kafka 서버를 시작하는 메인 진입점을 정의합니다. 이 파일은 kafka 패키지에 속하며, 운영에 필요한 여러 유틸리티 클래스와 라이브러리를 가져옵니다.Kafka 객체는 로깅 기능을 제공하는 Logging 트레이트를 확장합니다. getPr