
이진탐색트리(BST)
- 노드의 왼쪽에는 노드보다 작은 값을 가진 노드, 오른쪽에서는 노드보다 큰 값을 가진 노드
- 노드를 3개씩 갖기위해서는?
B tree
-
부모노드에 값을 2개 넣고, 3개의 범위를 갖도록 만든다.
-
자녀노드의 수를 마음대로 정할 수 있음.
-
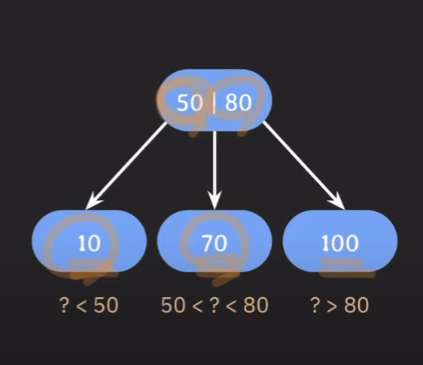
파라미터
- M: 각노드의 최대 자녀노드 수 ex. 3
- M-1: 각 노드의 최대 key수 ex. 2 (?<k1, k1k2)
- [M/2]: 각 노드의 최소 자녀노드 수
- 괄호는 올림을 해달라는 뜻 ex) M=3이면 [M/2]는 2
- leaf 노드, root 노드 제외
- [M/2]-1: 각 노드의 최소 key 수
-
규칙
-
자녀노드의 수는 언제나 key+1 개수
- 즉, 차수와 관계없이 최소 두개의 자녀는 갖게된다.
- 비어있는 노드는 없으므로(무조건 key는 1개)
-
추가되는 노드는 항상 leaf가 된다.
-
노드가 넘치면
-
각 노드가 가질 수 있는 key 이상의 값을 갖게되면
- 최대 key 값: 2
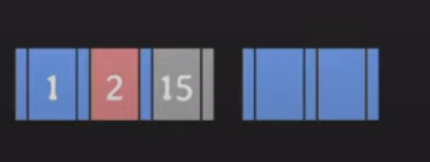
-
가운데 key를 기준으로 좌우 key분할

-
가운데 key를 위로 올린다.
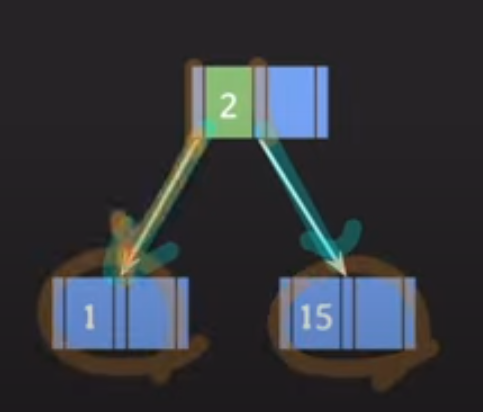
-
-
데이터 삭제

- 삭제또한 항상 leaf 노드에서 발생
- 삭제 후 최소 key보다 적어졌다면 재조정
- key 수가 여유있는 형제의 지원을 받는다.
- 부모와 형제의 값을 변경을 통해 균형을 맞춘다.
- 1번이 불가능하면 부모의 지원을 받고 형제와 합친다.
- 2번 진행 후 부모에게 문제가 있다면 부모를 다시 재조정
-만약 internal에서 노드 삭제가 일어난다면?
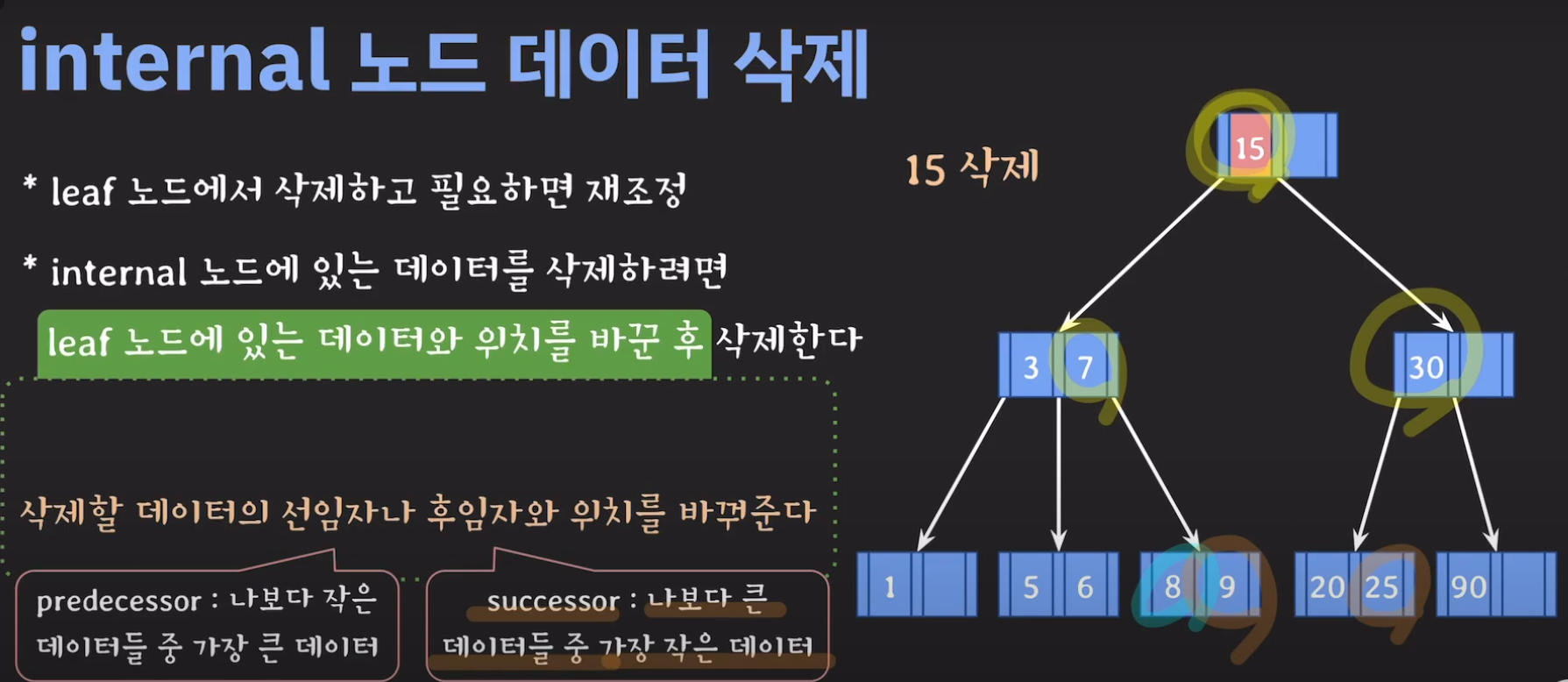
- key 수가 여유있는 형제의 지원을 받는다.

왜 DB index로 쓰이는가?
- B tree 뿐만 아니라, AVG 레드블랙트리도 빅오가 모두 logN인데
- computer system과 연관이 있다.
- DB는 secondary storage에 저장(HDD, SDD)
- 필요한 메모리를 main memory에 끌어와서 사용
- 즉, secondary storage에 적게 접근할 수록 성능이 좋아짐
- block 단위로 읽고 쓰기 때문에 연관된 데이터를 모아서 저장하면 secondary storage를 덜 접근하게된다. => 성능이 좋아짐.
B tree는 연관된 데이터끼리 뭉쳐있기 때문에 secondary storage를 덜 참조한다.
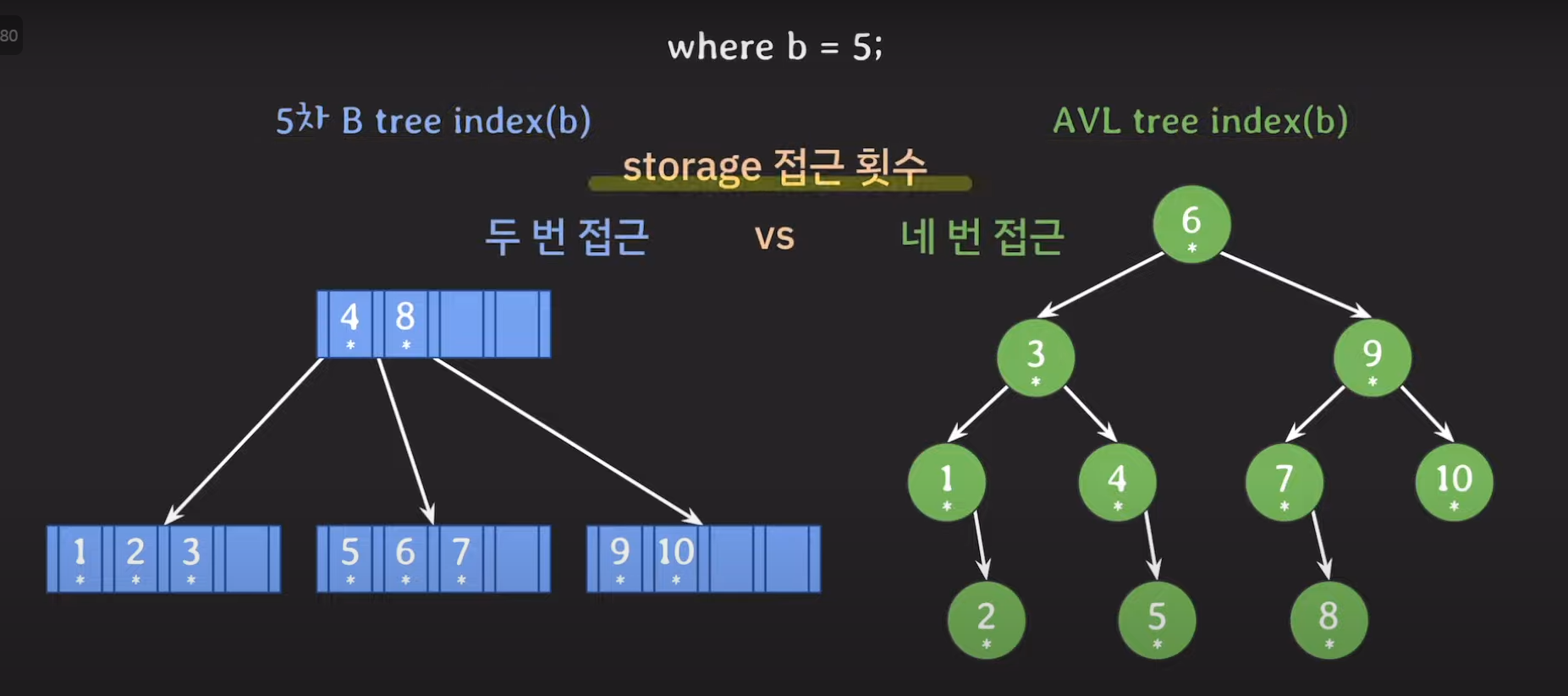
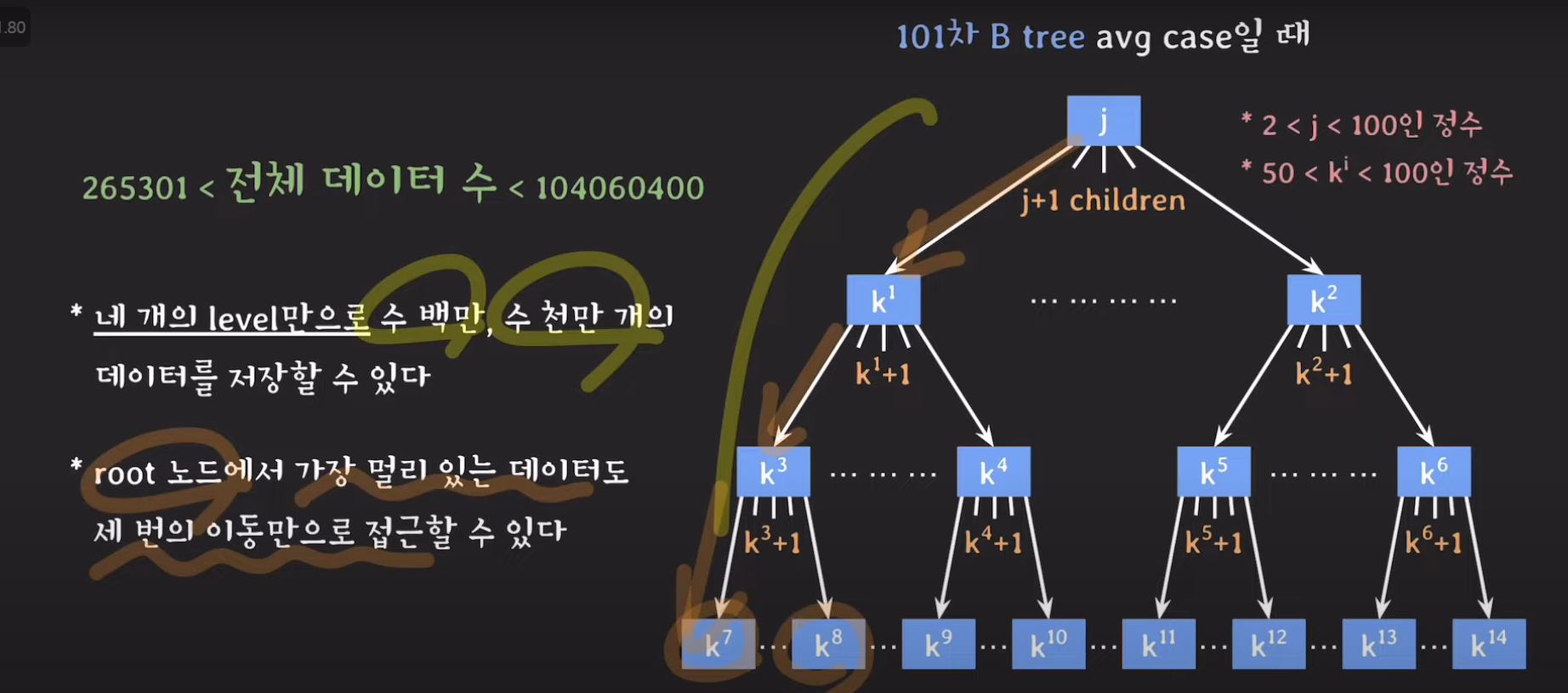
- 더 적은 접근으로 수백만 수천만개의 데이터를 조회할 수 있다.

System.out.print("Bold")