인덱스의 필요성
데이터를 빠르게 찾을 수 있게 해줌
인덱스는 보통 B-트리라는 자료 구조로 이루어져 있음
B-트리
루트 노드, 리프 노드, 그 사이에 있는 브랜치 노드로 나뉨
트리 탐색은 정렬된 값을 기반으로 맨 위 루트 노드부터, 브랜치 노드를 거쳐, 리프 노드까지 내려오며 이루어짐
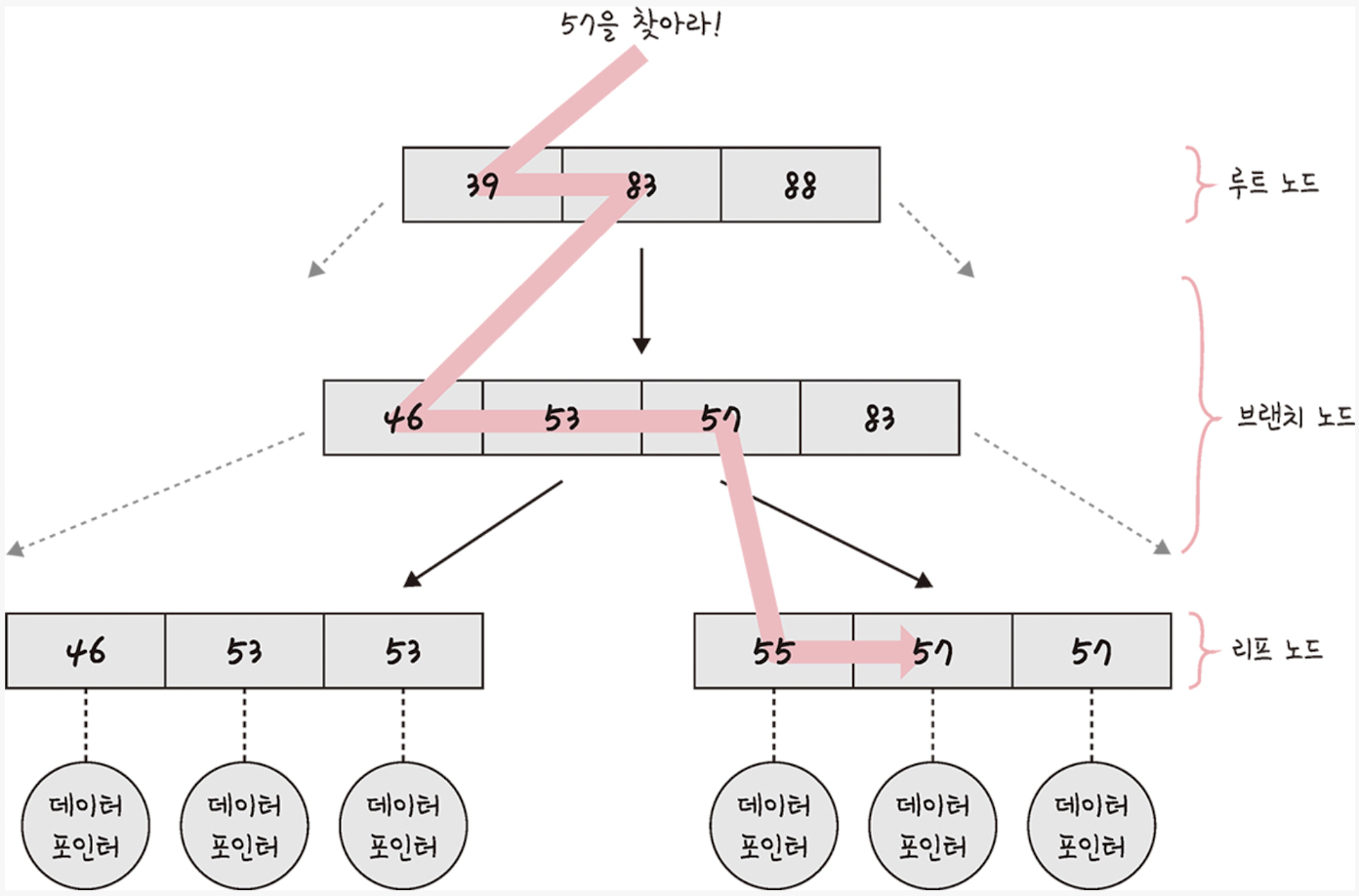
마지막 리프 노드에 도달해서 57이 가리키는 데이터 포인터를 통해 결괏값을 반환함
인덱스가 효율적인 이유
모든 요소에 접근할 수 있는 균형 잡힌 트리 구조와 트리 깊이의 대수확장성 때문
대수확장성: 트리 깊이가 리프 노드 수에 비해 매우 느리게 성장하는 것
기본적으로 인덱스가 한 깊이씩 증가할 때마다 최대 인덱스 항목의 수는 4배씩 증가
인덱스 만드는 방법
MySQL
클러스터형 인덱스와 세컨더리 인덱스가 있음
- 클러스터형 인덱스: 테이블당 하나를 설정할 수 있음
primary key옵션으로 기본키를 만들거나,unique not null옵션을 붙이면 클러스터형 인덱스로 만들 수 있음 - 세컨더리 인덱스: 보조 인덱스로 여러 개의 필드 값을 기반으로 쿼리를 많이 보낼 때 생성해야 하는 인덱스
create index ...명령어를 기반으로 생성
하나의 인덱스만 생성할 것이라면 클러스터형 인덱스를 만드는 것이 성능이 좋음
MongoDB
도큐먼트를 만들면 자동으로 ObjectID가 형성되며, 해당 키가 기본키로 설정됨
세컨더리키도 부가적으로 설정해서 기본키와 세컨더리키를 같이 쓰는 복합 인덱스를 설정할 수 있음
인덱스 최적화 기법
- 인덱스는 비용이다
인덱스는 인덱스 리스트, 컬렉션 순으로 탐색하기 때문에 두 번 탐색함
쿼리에 있는 필드에 인덱스를 무작정 다 설정하는 것은 답이 아님 - 항상 테스팅하라
explain() 함수를 통해 인덱스를 만들고 쿼리를 보낸 후에 테스팅을 통해 걸리는 시간을 최소화해야 함
EXPLAIN
SELECT * FROM t1
JOIN t2 ON t1.c1 = t2.c1- 복합 인덱스는 같음, 정렬, 다중 값, 카디널리티 순으로 생성해야 한다
보통 여러 필드를 기반으로 조회를 할 때 복합 인덱스를 생성하는데, 이 인덱스를 생성할 때는 순서가 있고 생성 순서에 따라 인덱스 성능이 달라짐
- 어떠한 값과 같음을 비교하는 ==이나 equal이라는 쿼리가 있다면 제일 먼저 인덱스로 설정
- 정렬에 쓰는 필드라면 그다음 인덱스로 설정
- 다중 값을 출력해야 하는 필드, 즉 쿼리 자체가 >이거나 < 등 많은 값을 출력해야 하는 쿼리에 쓰는 필드라면 나중에 인덱스를 설정
- 유니크한 값의 정도를 카디널리티라고 하는데, 카디널리티가 높은 순서를 기반으로 인덱스를 생성해야 함
