
Description of Database normalization
Normalization is the process of organizing data in a database. This includes creating tables and establishing relationships between those tables according to rules designed both to protect the data and to make the database more flexible by eliminating redundancy and inconsistent dependency.
Redundant data wastes disk space and creates maintenance problems. If data that exists in more than one place must be changed, the data must be changed in exactly the same way in all locations. A customer address change is much easier to implement if that data is stored only in the Customers table and nowhere else in the database.
What is an "inconsistent dependency"? While it is intuitive for a user to look in the Customers table for the address of a particular customer, it may not make sense to look there for the salary of the employee who calls on that customer. The employee's salary is related to, or dependent on, the employee and thus should be moved to the Employees table. Inconsistent dependencies can make data difficult to access because the path to find the data may be missing or broken.
There are a few rules for database normalization. Each rule is called a "normal form." If the first rule is observed, the database is said to be in "first normal form." If the first three rules are observed, the database is considered to be in "third normal form." Although other levels of normalization are possible, third normal form is considered the highest level necessary for most applications.
As with many formal rules and specifications, real world scenarios do not always allow for perfect compliance. In general, normalization requires additional tables and some customers find this cumbersome. If you decide to violate one of the first three rules of normalization, make sure that your application anticipates any problems that could occur, such as redundant data and inconsistent dependencies.
The following descriptions include examples.
Normalization Rule
Normalization rules are divided into the following normal forms:
- First Normal Form
- Second Normal Form
- Third Normal Form
- BCNF
- Fourth Normal Form
First Normal Form (1NF) (1정규화)
- It should only have single(atomic) valued attributes/columns.
- Values stored in a column should be of the same domain (Attribute Domain should not change)
- All the columns in a table should have unique names.
- And the order in which data is stored, does not matter.
-> Single Valued Attributes
Each column of your table should be single valued which means they should not contain multiple values. We will explain this with help of an example later, let's see the other rules for now.
-> Attribute Domain should not change
This is more of a "Common Sense" rule. In each column the values stored must be of the same kind or type.
For example: If you have a column dob to save date of births of a set of people, then you cannot or you must not save 'names' of some of them in that column along with 'date of birth' of others in that column. It should hold only 'date of birth' for all the records/rows.
-> Unique name for Attributes/Columns
This rule expects that each column in a table should have a unique name. This is to avoid confusion at the time of retrieving data or performing any other operation on the stored data.
If one or more columns have same name, then the DBMS system will be left confused.
->Order doesn't matters
This rule says that the order in which you store the data in your table doesn't matter.
Second Normal Form (2NF)(2정규화)
- It should be in the First Normal form.
- And, it should not have Partial Dependency.
-> What is Dependency?
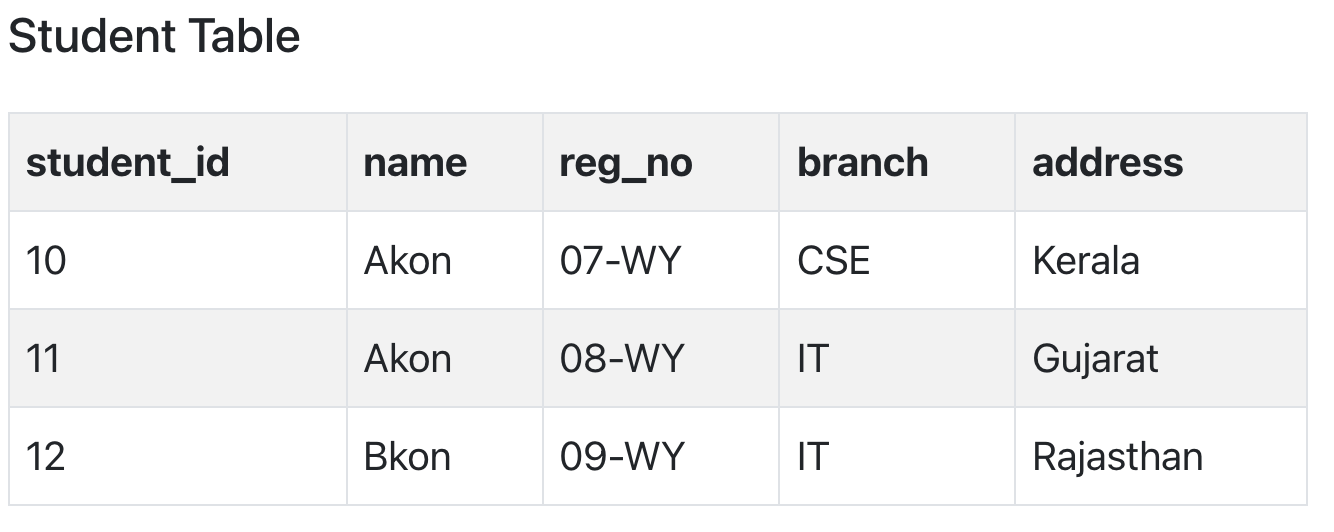
Let's take an example of a Student table with columns student_id, name, reg_no(registration number), branch and address(student's home address).

In this table, student_id is the primary key and will be unique for every row, hence we can use student_id to fetch any row of data from this table
Even for a case, where student names are same, if we know the student_id we can easily fetch the correct record.
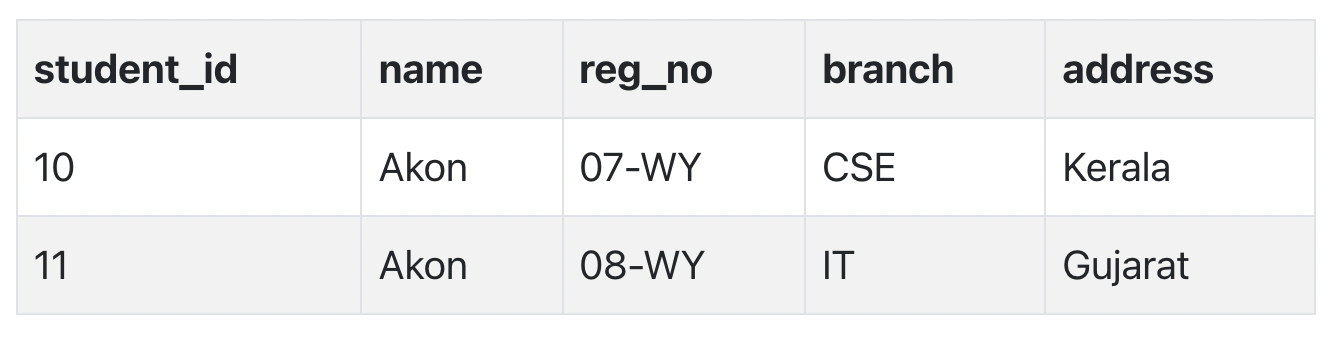
Hence we can say a Primary Key for a table is the column or a group of columns(composite key) which can uniquely identify each record in the table.
I can ask from branch name of student with student_id 10, and I can get it. Similarly, if I ask for name of student with student_id 10 or 11, I will get it. So all I need is student_id and every other column depends on it, or can be fetched using it.
This is Dependency and we also call it Functional Dependency.
-> What is partial dependency?
Now that we know what dependency is, we are in a better state to understand what partial dependency is.
For a simple table like Student, a single column like student_id can uniquely identfy all the records in a table.
But this is not true all the time. So now let's extend our example to see if more than 1 column together can act as a primary key.
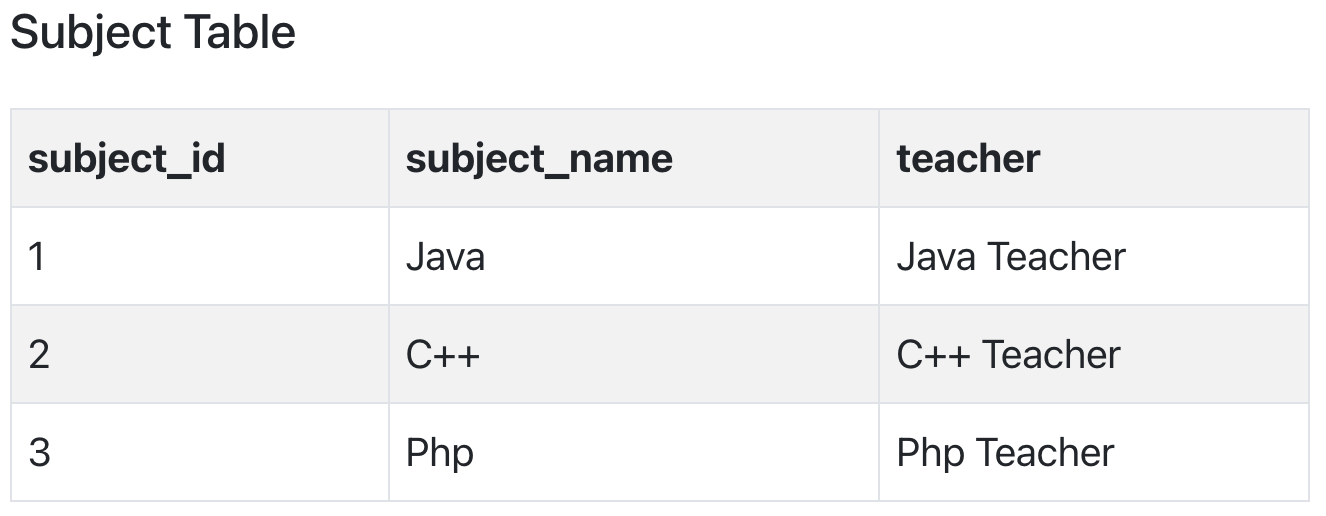
Let's create another table for Subject, which will have subject_id and subject_name fields and subject_id will be the primary key.

Now we have a Student table with student information and another table Subject for storing subject information.
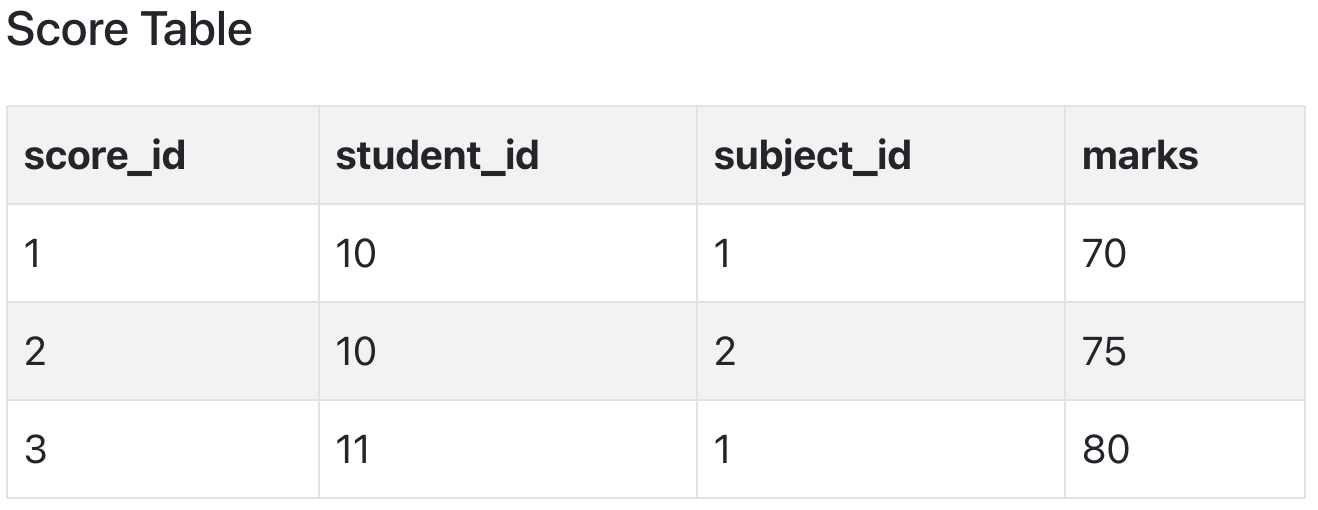
Let's create another table Score, to store the marks obtained by students in the respective subjects. We will also be saving name of the teacher who teaches that subject along with marks.
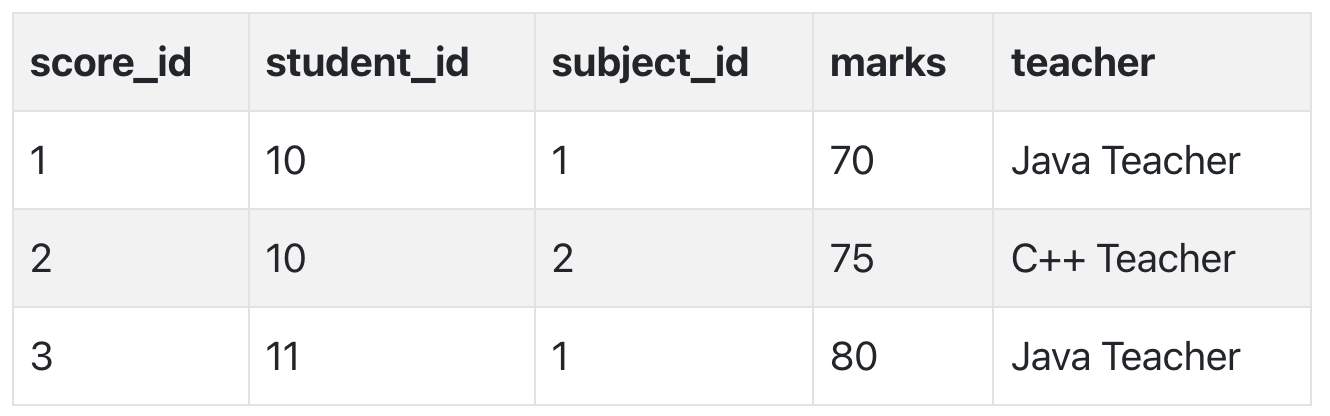
In the score table we are saving the student_id to know which student's marks are these and subject_id to know for which subject the marks are for.
Together, student_id + subject_id forms a Candidate Key for this table, which can be the Primary key.
Confused, How this combination can be a primary key?
See, if I ask you to get me marks of student with student_id 10, can you get it from this table? No, because you don't know for which subject. And if I give you subject_id, you would not know for which student. Hence we need student_id + subject_id to uniquely identify any row.
->But where is Partial Dependency?
Now if you look at the Score table, we have a column names teacher which is only dependent on the subject, for Java it's Java Teacher and for C++ it's C++ Teacher & so on.
Now as we just discussed that the primary key for this table is a composition of two columns which is student_id & subject_id but the teacher's name only depends on subject, hence the subject_id, and has nothing to do with student_id.
This is Partial Dependency, where an attribute in a table depends on only a part of the primary key and not on the whole key.
-> How to remove Partial Dependency?
There can be many different solutions for this, but out objective is to remove teacher's name from Score table.
The simplest solution is to remove columns teacher from Score table and add it to the Subject table. Hence, the Subject table will become:
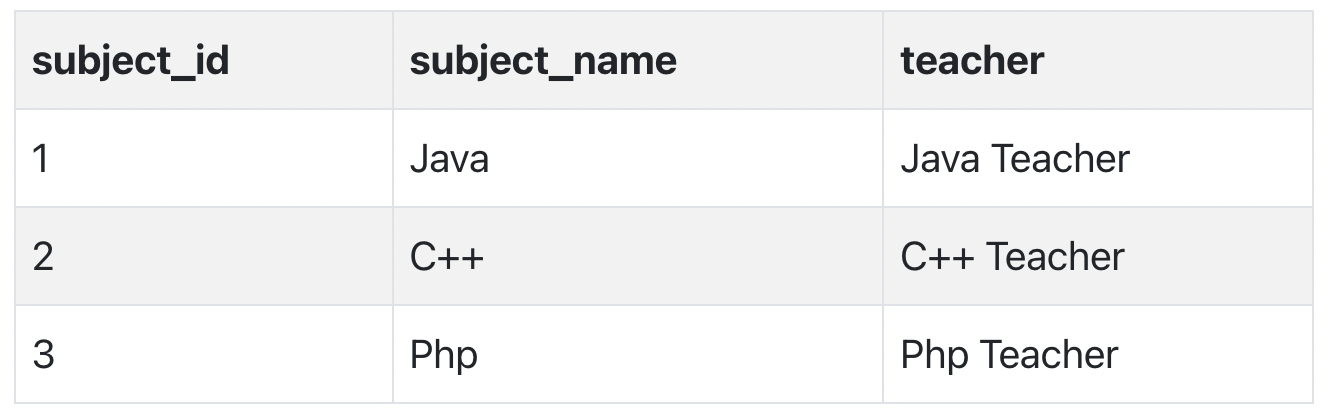
And our Score table is now in the second normal form, with no partial dependency.
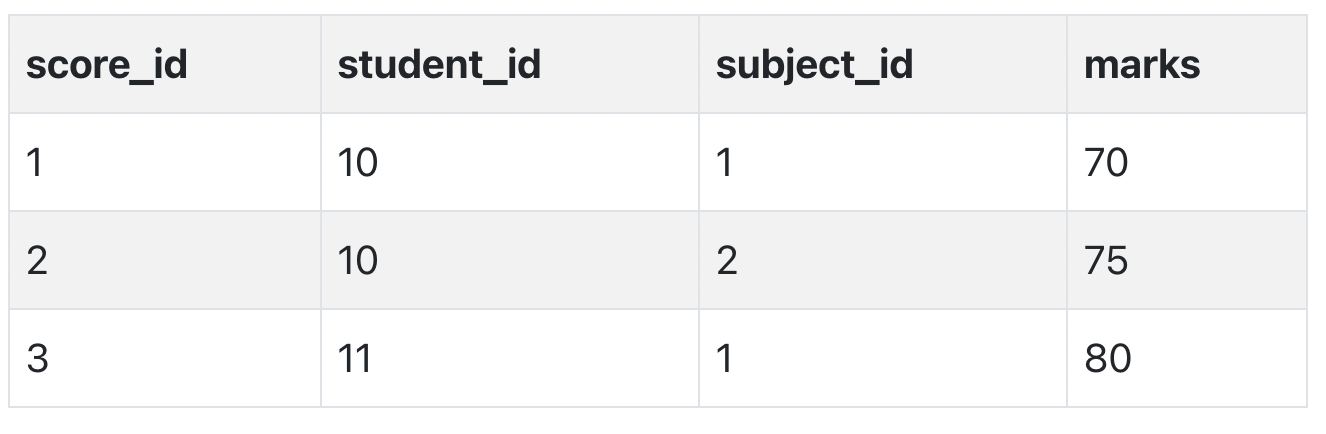
Third Normal Form (3NF)(3정규화)
- It is in the Second Normal form.
- And, it doesn't have Transitive Dependency.
Third Normal Form is an upgrade to Second Normal Form. When a table is in the Second Normal Form and has no transitive dependency, then it is in the Third Normal Form.
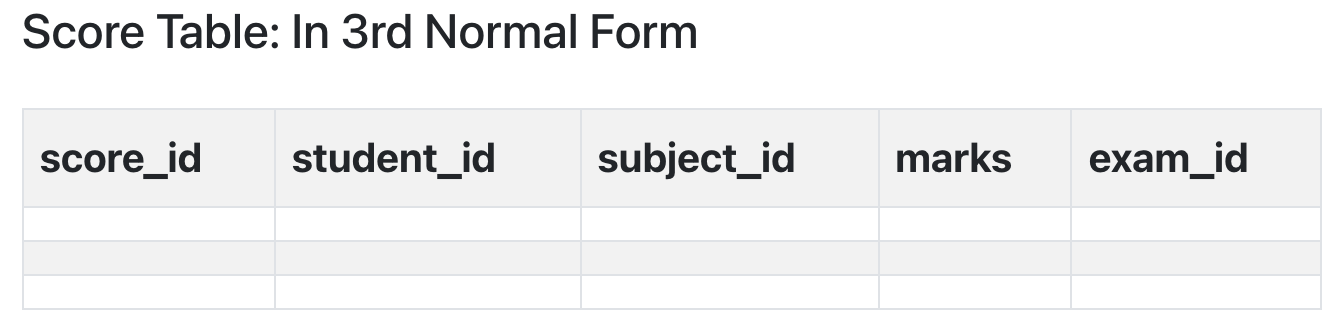
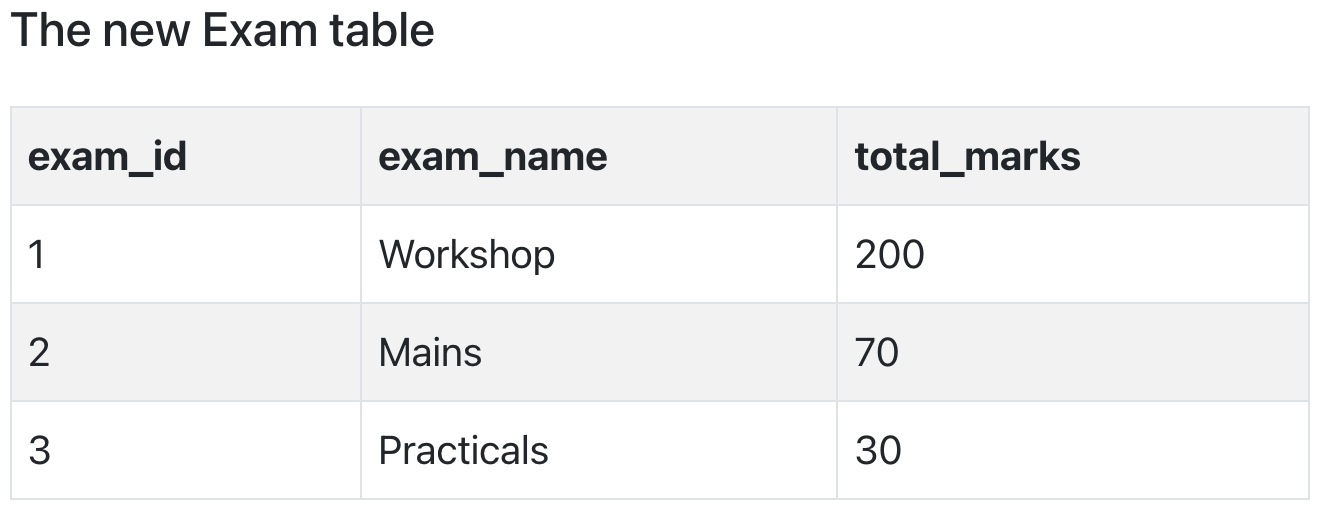
In the Score table, we need to store some more information, which is the exam name and total marks, so let's add 2 more columns to the Score table.

->What is Transitive Dependency?
With exam_name and total_marks added to our Score table, it saves more data now. Primary key for our Score table is a composite key, which means it's made up of two attributes or columns → student_id + subject_id.
Our new column exam_name depends on both student and subject. For example, a mechanical engineering student will have Workshop exam but a computer science student won't. And for some subjects you have Prctical exams and for some you don't. So we can say that exam_name is dependent on both student_id and subject_id.
And what about our second new column total_marks? Does it depend on our Score table's primary key?
Well, the column total_marks depends on exam_name as with exam type the total score changes. For example, practicals are of less marks while theory exams are of more marks.
But, exam_name is just another column in the score table. It is not a primary key or even a part of the primary key, and total_marks depends on it.
This is Transitive Dependency. When a non-prime attribute depends on other non-prime attributes rather than depending upon the prime attributes or primary key.
->How to remove Transitive Dependency?
Again the solution is very simple. Take out the columns exam_name and total_marks from Score table and put them in an Exam table and use the exam_id wherever required.
-> Advantage of removing Transitive Dependency
The advantage of removing transitive dependency is,
- Amount of data duplication is reduced.
- Data integrity achieved.
Boyce and Codd Normal Form (BCNF)
Boyce and Codd Normal Form is a higher version of the Third Normal form. This form deals with certain type of anomaly that is not handled by 3NF. A 3NF table which does not have multiple overlapping candidate keys is said to be in BCNF. For a table to be in BCNF, following conditions must be satisfied:
- R must be in 3rd Normal Form
- and, for each functional dependency ( X → Y ), X should be a super Key.
The second point sounds a bit tricky, right? In simple words, it means, that for a dependency A → B, A cannot be a non-prime attribute, if B is a prime attribute.
Below we have a college enrolment table with columns student_id, subject and professor.
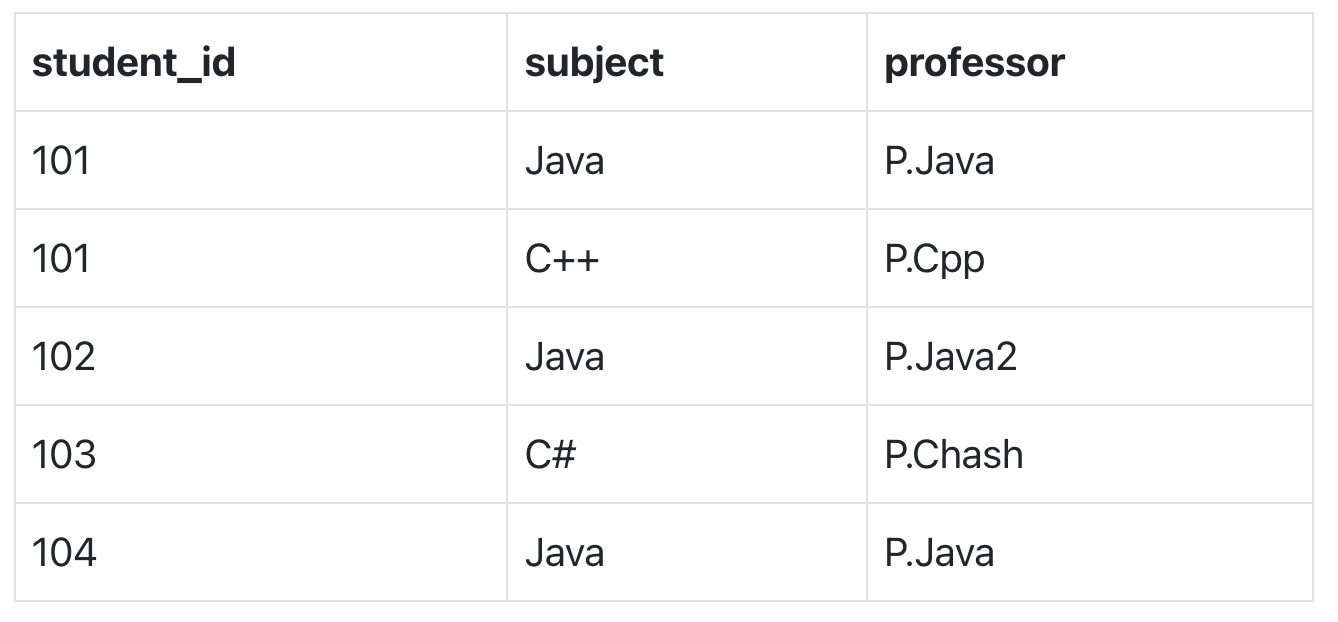
In the table above:
One student can enrol for multiple subjects. For example, student with student_id 101, has opted for subjects - Java & C++
For each subject, a professor is assigned to the student.
And, there can be multiple professors teaching one subject like we have for Java.
What do you think should be the Primary Key?
Well, in the table above student_id, subject together form the primary key, because using student_id and subject, we can find all the columns of the table.
One more important point to note here is, one professor teaches only one subject, but one subject may have two different professors.
Hence, there is a dependency between subject and professor here, where subject depends on the professor name.
This table satisfies the 1st Normal form because all the values are atomic, column names are unique and all the values stored in a particular column are of same domain.
This table also satisfies the 2nd Normal Form as their is no Partial Dependency.
And, there is no Transitive Dependency, hence the table also satisfies the 3rd Normal Form.
But this table is not in Boyce-Codd Normal Form.
-> Why this table is not in BCNF?
In the table above, student_id, subject form primary key, which means subject column is a prime attribute.
But, there is one more dependency, professor → subject.
And while subject is a prime attribute, professor is a non-prime attribute, which is not allowed by BCNF.
->How to satisfy BCNF?
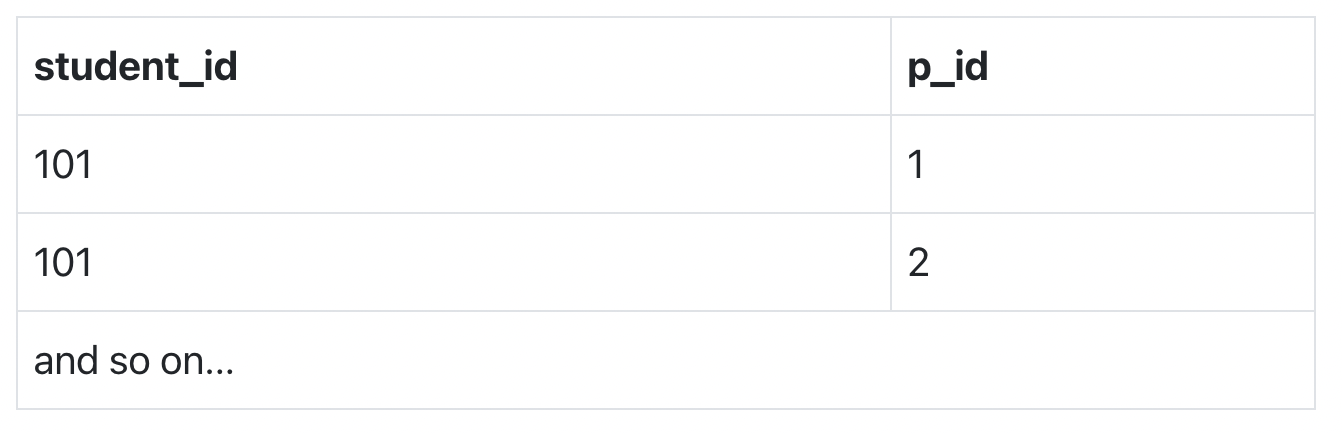
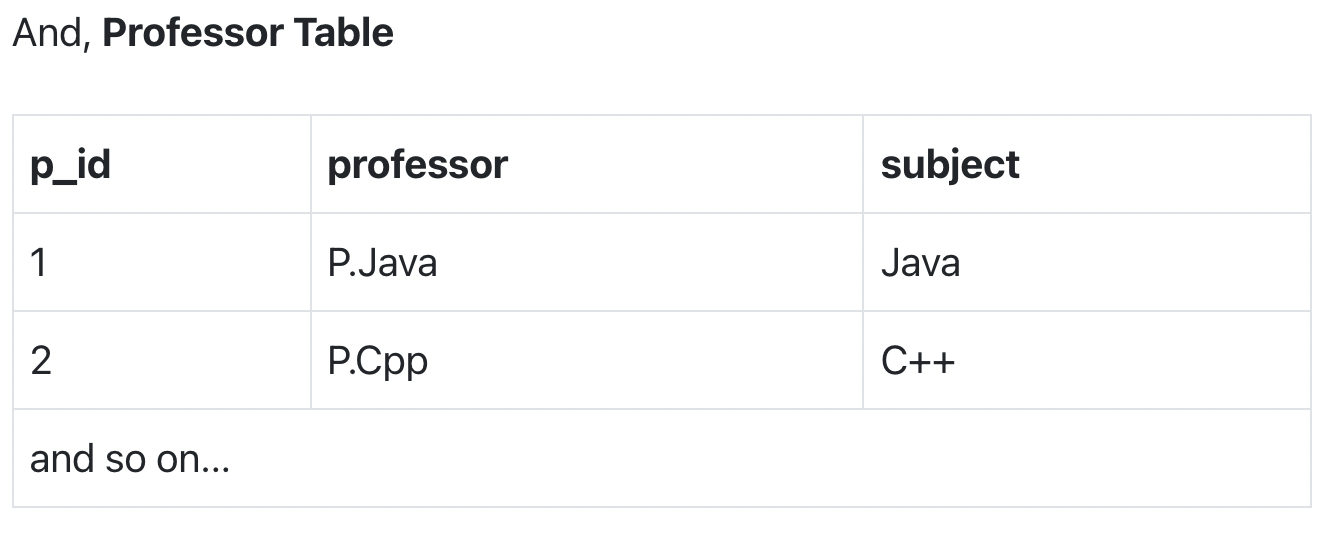
To make this relation(table) satisfy BCNF, we will decompose this table into two tables, student table and professor table.
Below we have the structure for both the tables.
Student Table
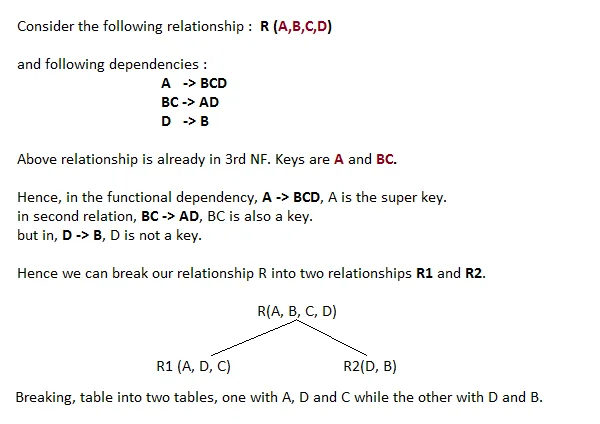
-> A more Generic Explanation
In the picture below, we have tried to explain BCNF in terms of relations.
Resources
https://docs.microsoft.com/en-us/office/troubleshoot/access/database-normalization-description
https://www.studytonight.com/dbms/database-normalization.php
