
트라이 (Trie)
트라이는 검색 트리의 일종으로 일반적으로 키가 문자열인 동적 배열 또는 연고나 배열을 저장하는데 사용되는 정렬된 트리 자료구조이다.
트라이는 실무에 매우 유용하게 쓰이는 자료구조로, 특히 자연어 처리(NLP) 분야에서 문자열 탐색을 위한 자료구조로 널리 쓰인다. 트라이는 이진 트리의 모습이 아닌 전형적인 다진 트리의 형태를 띤다.
트라이는 각각의 문자 단위로 색인을 구축한 것과 유사한데, 수백 개의 문자가 있다고 할 때 트라이 탐색을 하면 찾고자 하는 문자열의 길이만큼의 탐색만 하면 문자열의 존재 여부를 판단할 수 있다. 자연어 처리 분야에서는 형태소 분석기에서 분석 패턴을 트라이로 만들어두고 자연어 문장에 대해 패턴을 찾아 처리하는 등으로 활용하고 있다.
트라이는 문자열을 위한 트리의 형태이기 때문에 사실상 문자 개수만큼 자식이 있어 상당히 많은 자식 노드를 갖고 있는 트리임을 알 수 있다.
LeetCode 208.Implement Trie (Prefix Tree)
트라이의 insert, search, starsWith 메소드를 구현하라.

Solution 1 딕셔너리를 이용해 간결한 트라이 구현
트라이를 직접 구현해보는 문제이다. 여기서는 딕셔너리를 이용해 가급적 간결한 형태로 풀이해본다. 트라이를 저장할 노드는 다음과 같이 별도 클래스로 선언한다.
class TrieNode:
def __init__(self):
self.word=False
self.children={}메소드를 포함해 같은 클래스로 묶을 수도 있지만, 이 경우 구현상 복잡도가 늘어나기 때문에 가능하면 간결하게 구현하기 위해 별도로 구분해 선언했다. 다음으로 트라이 연산을 구현할 별도 클래스를 선언하고 삽입 메소드를 구현해본다.
class Trie:
def __init__(self):
self.root=TrieNode()
def insert(self, word:str)->None:
node=self.root
for char in word:
if char not in node.children:
node.children[char]=TrieNode()
node=node.children[char]
node.word=True처음 Trie 클래스를 생성하게 되면 루트 노드로 별도 선언한 TrieNode 클래스를 갖게 되고, 삽입 시 루트부터 자식 노드가 점점 깊어지면서 문자 단위의 다진 트리 형태가 된다. 만약 apple을 입력하는 경우에는 다음과 같은 삽입 코드를 작성해야 한다.
t=Trie()
t.insert('apple')트라이는 다음 문자를 키로 하는 자식 노드 형태로 점점 깊어지면서 각각의 노드는 word 값을 갖는다. 이 값은 단어가 모두 완성되었을 때만 True가 된다. apple의 경우 단어가 모두 완성되는 e에 이르러야 True로 셋팅된다.
트라이는 같은 문자가 같은 자식을 타고 내려가다가 달라지는 문자부터 서로 다른 노드로 분기된다. appeal과 appear가 완성되는 l과 r 노드가 각각 True로 셋팅된다.
이 값이 존재하는지 확인하려면 문제에 제시된 메소드인 search()와 startsWith() 메소드가 필요하다. search()는 단어가 존재하는지 여부를 판별하는 것이고, startsWith()는 해당 문자열로 시작하는 단어가 존재하는지 여부를 판별하는 것이다. 둘 다 도일하게 문자 단위로 계속 깊이 탐색을 하고 search()의 경우에만 마지막에 word가 True인지 확인하면 된다. search()의 코드는 다음과 같다.
def search(self, word:str)->bool:
node=self.root
for char in word:
if char not in node.children:
return False
node=node.children[char]
return node.word문자열에서 문자를 하나씩 for 반복문으로 순회하면서 자식 노드로 계속 타고 내려간다. 그리고 마지막에 node.word 여부를 반환한다. 만약 단어가 완성된 트라이라면 True로 되어 있을 것이고, 이때 True가 결과로 반환된다. startsWith()의 코드는 다음과 같다.
def startsWith(self, prefix:str)->bool:
node=self.root
for char in prefix:
if char not in node.children:
return False
node=node.children[char]
return Truesearch()와 거의 동일하지만 node.word를 확인하지 않고, 자식 노드가 존재하는지 여부만 판별한다는 점에서 다르다. 자식 노드가 존재한다면 for 반복문을 끝까지 빠져나올 것이고, True를 반환한다. 전체 코드는 다음과 같다.
class TrieNode:
def __init__(self):
self.word=False
self.children=collections.defaultdict(TrieNode)
class Trie:
def __init__(self):
self.root=TrieNode()
def insert(self, word: str) -> None:
node=self.root
for char in word:
node=node.children[char]
node.word=True
def search(self, word: str) -> bool:
node=self.root
for char in word:
if char not in node.children:
return False
node=node.children[char]
return node.word
def startsWith(self, prefix: str) -> bool:
node=self.root
for char in prefix:
if char not in node.children:
return False
node=node.children[char]
return True
# Your Trie object will be instantiated and called as such:
# obj = Trie()
# obj.insert(word)
# param_2 = obj.search(word)
# param_3 = obj.startsWith(prefix)
LeetCode 336.Palindrome Pairs
단어 리스트에서 words[i]+words[j]가 팰린드롬이 되는 모든 인덱스 조합 (i, j)를 구하라
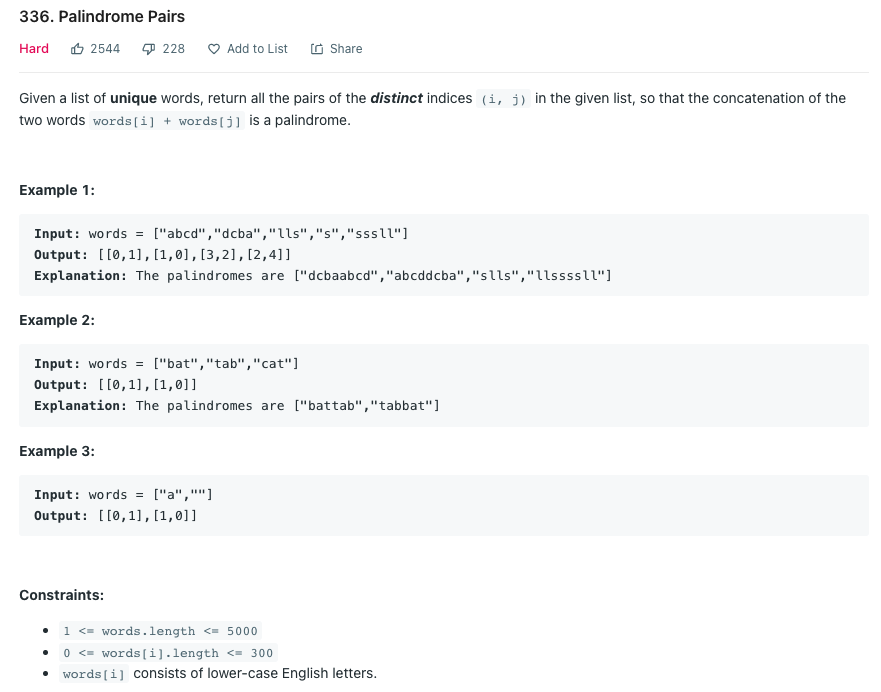
Solution 1 팰린드롬을 부르트 포스로 계산
모든 조합을 구성해보고 이 구성이 팰린드롬인지 여부를 판별하면 O(n^2) 시간 복잡도로 브루트 포스 풀이가 가능할 것 같다.
class Solution:
def palindromePairs(self, words: List[str]) -> List[List[int]]:
def is_palindrome(word):
return word==word[::-1]
output=[]
for i, word1 in enumerate(words):
for j, word2 in enumerate(words):
if i==j:
continue
if is_palindrome(word1+word2):
output.append([i, j])
return output
결과값은 잘 나오지만 시간초과가 발생한다. 다른 효율적인 풀이를 사용해야 할 것 같다.
Solution 2 트라이 구현
O(n^2)를 O(n)으로 풀이할 수 있는 방법으로 트라이가 있다. 앞서 풀었던 트라이 구현 문제의 정답 코드를 뼈대로 하여 트라이 구현을 그대로 활용할 것이다. O(n)으로 풀기 위해서는 모든 입력 값을 트라이로 만들어두고 딱 한번씩만 탐색하는 문제로 변형해야 한다.
def insert(self, index:int, word:str)->None:
node=self.root
for i, char in enumerate(reversed(word)):
...
node=node.children[char]
node.word_id=index뒤집은 다음, 문자 단위로 계속 내려가면서 트라이를 구현하고, 각각의 단어가 끝나는 지점에는 단어 인덱스를 word_id로 부여했다. 이전 문제에서는 True, False 여부만 표기했지만, 여기서는 해당 단어의 인덱스를 찾아가야 하기 때문에 word_id로 부여했다. 이번에는 단어 존재 여부를 찾는 함수의 핵심 코드이다.
results=[]
...
while word:
if node.word_id>=0:
...
result.append([index, node.word_id])단어를 뒤집어서 구축한 트라이이기 때문에 입력값은 순서대로 탐색하다가 끝나는 지점의 word_id 값이 -1이 아니라면, 현재 인덱스 index와 해당 word_id는 팰린드롬으로 판단할 수 있다.
두번째 판별 로직은 트라이 삽입 중에 남아 있는 단어가 팰린드롬이라면 미리 팰린드롬 여부를 세팅 해두는 방법이다. 즉 입력값 ['d', 'cbbcd', 'dcbb', 'cbbc', 'bbcd']에서 cbbc는 단어 자체가 팰린드롬이므로 루트에 바로 입력값의 인덱스인 p=4를 셋팅하고, word[0:len(word)-i]형태로 단어에서 문자 수를 계속 줄여 나가며 팰린드롬 여부를 체크한다. 문자가 하나만 남게 될 때는 단어에서 문자 수를 계속 줄여 나가며 팰린드롬 여부를 체크한다. 문자가 하나만 남게 될 때는 항상 팰린드롬이므로 마찬가지로 p=4를 마지막에 셋팅한다. 당연히 이 마지막 값은 항상 w의 바로 앞 노드가 된다.
이 알고리즘을 추가하여 삽입 함수를 다음과 같이 개선할 수 있다.
def insert(self, index:int, word:str)->None:
node=self.node
for i, char in enumerate(reversed(word)):
if self.palindrome(word[0:len(word)-1]:
node.palindrome_word_ids.append(index)
node=node.children[char]
node.word_id=index코드에서 속성명을 복수형으로 지정한 이유는 p값이 여러 개가 될 수 있기 떄문이다. 따라서 코드에서 palindrome_word_ids는 리스트이며 복수형이다. 이 로직들을 반영한 각 트라이 노드가 저장될 때 TrieNode 클래스를 다음과 같이 수정해야 한다.
class TrieNode:
def __init__(self):
self.children=collections.defaultdict(TrieNode)
self.word_id=-1
self.palindrome_words_ids=[]word_id 외에도 palindrome_word_ids를 트라이 노드의 속성으로 추가하고 TrieNode 클래스로 구현했다.
이번에는 남아있는 단어가 팰린드롬인 경우이다. w는 단어의 끝이고, p는 w 이전 노드에 반드시 셋팅된다. 문자가 하나만 남았을 때는 항상 팰린드롬이기 때문이라고 언급했었다. 다시 한번 입력값 'd', 'cbbcd', 'dcbb', 'cbbc', 'bbcd']을 보면 dcbb의 인덱스는 2이고, 트라이에서는 d->c->b->b의 마지막 노드가 p=1이다. 그렇다면 [2, 1]은 정답 중에 하나가 된다. 실제로 인덱스 1의 입력값은 cbbcd 이므로 dcbb+cbbcd는 팰린드롬으로, 정답 중 하나다. 또 다른 경우로, 인덱스 0의 d를 살펴보면 d 노드는 p=1이다. 즉 [0, 1]도 정답이 된다. d+cbbcd이며 마찬가지로 팰린드롬이다. 이 부분을 판별하는 코드는 다음과 같다.
def palindrome_word_id in node.palindrome_word_ids:
result.apppend([index, palindrome_word_id])세번째 판별 로직은 입력값을 문자 단위로 확인해 나가다가 해당 노드의 word_id가 -1이 아닐 때, 나머지 문자가 팰린드롬이라면 팰린드롬으로 판별하는 경우이다. dcbc+d가 이에 해당하는데 입력값 dcbc는 먼저 d부터 탐색하다가 d의 word_id가 -1이 아니기 때문에 나머지 문자 cbc에 대해 팰린드롬으로 판별한다. 그리고 다음과 같은 판별 로직을 코드에 추가한다.
while word:
if node.word_id>=0:
if self.is_palindrome(word):
result.append([index, node.word_id])
...
node=node.children[word[0]]
word=word[1:]3가지 판별 로직을 다시 정리하면 다음과 같다.
1. 끝까지 탐색했을 때 word_id가 있는 경우
2. 끝가지 탐색했을 때 palindrome_word_ids가 있는 경우
3. 탐색 중간에 word_id가 있고 나머지 문자가 팰린드롬인 경우
이렇게 3가지 경우를 팰린드롬으로 판별할 수 있으며, 입력값을 각각 한번씩만 대입하면 되기 때문에 O(n)으로 풀이할 수 있다. 더 정확히는 단어의 최대 길이를 k로 했을 때 O(k^2n)이며, 앞서 브루트 포스 풀이의 경우는 O(kn^2)이다.
이 문제에서는 k가 훨씬 작기 때문에 트라이 풀이가 더 효율적이며, 이 때문에 앞서 브루트 포스가 타임아웃인 반면에 트라이 풀이는 시간 내에 잘 실행된다. 전체 코드는 다음과 같다.
class TrieNode:
def __init__ (self):
self.children=collections.defaultdict(TrieNode)
self.word_id=-1
self.palindrome_word_ids=[]
class Trie:
def __init__ (self):
self.root=TrieNode()
@staticmethod
def is_palindrome(word:str)->bool:
return word[::]==word[::-1]
def insert(self, index, word)->None:
node=self.root
for i, char in enumerate(reversed(word)):
if self.is_palindrome(word[0:len(word)-i]):
node.palindrome_word_ids.append(index)
node=node.children[char]
node.word_id=index
def search(self, index, word)->List[List[int]]:
result=[]
node=self.root
while word:
if node.word_id>=0:
if self.is_palindrome(word):
result.append([index, node.word_id])
if not word[0] in node.children:
return result
node=node.children[word[0]]
word=word[1:]
if node.word_id>=0 and node.word_id!=index:
result.append([index, node.word_id])
for palindrome_id in node.palindrome_word_ids:
result.append([index, palindrome_word_id])
return result
class Solution:
def palindromePairs(self, words: List[str]) -> List[List[int]]:
trie=Trie()
for i, word in enumerate(words):
trie.insert(i, word)
result=[]
for i, word in enumerate(words):
result.extend(trie.search(i, word))
return results@staticmethod 데코레이터
메소드 위에 @staticmethod라는 표기를 바로 위의 코드에서 볼 수 있다. 파이썬에서는 이 부분을 데코레이터라고 부른다. @staticmethod는 자바의 메소드 static 선언과도 비슷한데, 이렇게 정의한 메소드는 클래스의 독립적인 함수로서의 의미를 강하게 갖는다. 실제로 파라미터에도 클래스 메소드에는 항상 따라붙는 self가 빠져 있고, 함수 자체가 별도의 자료형으로 선언되어 있다.
class CLASS:
def a(self):
pass
@staticmethod
def b():
pass이와 같이 클래스가 선언되어 있을 때, 함수 a(), b()의 타입을 출력해보면 다음과 같다.
>>> type(CLASS.a), type(CLASS.b)
(<class 'function'>, <class 'function>)클래스를 생성하지 않고 바깥에서 직접 호출했을 때 타입은 이처럼 둘 다 함수(Function)이 된다.
>>> cls = CLASS()
>>> type(cls.a), type(cls.b)
(<class 'method'>, <class 'function'>)그러나 클래스를 생성한 후에 함수에 대한 타입을 확인해보면, 클래스 내 함수는 이제 메소드(Method)가 된다. 그러나 @staticmethod로 선언한 함수는 여전히 함수임을 확인할 수 있다. 클래스의 메소드가 아니라 여전히 독립된 함수의 의미를 갖는 것이다. 사실상 클래스 바깥에 함수를 별도로 선언한 것과 같은 의미를 지닌다. 이렇게 하면 클래스 메소드처럼 자유롭게 클래스 인스턴스에 접근하는 것이 제한된다. 따라서 클래스 인스턴스에 접근을 제한하고 분명하게 독립적인 함수로 선언하고자 할 경우 종종 사용된다.
