오늘 뭘 했니?
-
크로스엔트로피 구하기 실습
실습파일: 0900-cross-entropy-loss.ipynb -
텐서플로 공식문서 코랩으로 실습 텐서플로 2.0시작하기:초보자용
텐서플로 2.0 시작하기: 초보자용 | TensorFlow Core -
텐서플로 공식문서 코랩으로 실습 자동차 연비 예측하기: 회귀
자동차 연비 예측하기: 회귀 | TensorFlow Core
뭘 배웠니?(new)
데이터 샘플링
원문보기 - ScienceON (kisti.re.kr)
under-sampling과 over-sampling
SMOTE
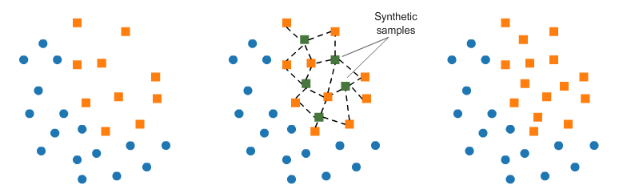
Resampling strategies for imbalanced datasets | Kaggle
- SMOTE는 Synthetic Minority Over-sampling Technique의 약자로 합성 소수자 오버샘플링 기법
- 적은 값을 늘릴 때, k-근접 이웃의 값을 이용하여 합성된 새로운 값을 추가
- k-근접 이웃이란 가장 가까운 k개 이웃을 의미
딥러닝 기초
퍼셉트론(Perceptron)
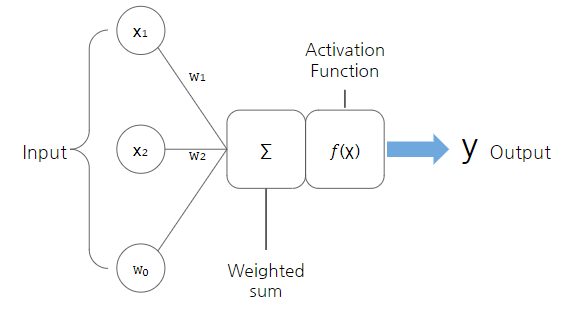
- 초기의 인공 신경망
- 퍼셉트론(Perceptron)은 인공 신경망의 한 종류
단층 퍼셉트론
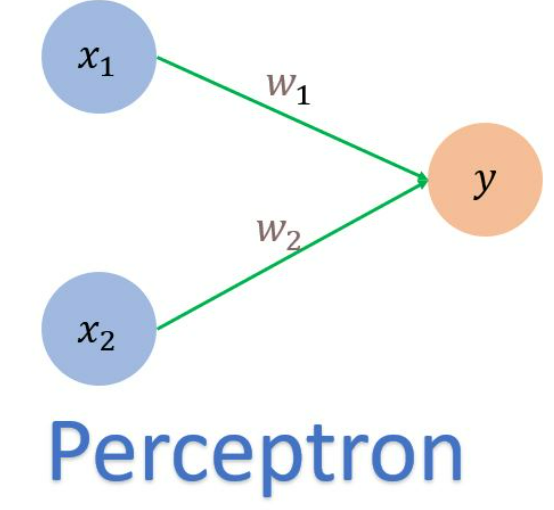
How to Create A Single Layer Perceptron? | pyimagedata
- 입력층과 출력층으로 구성
- 단층퍼셉트론의 한계: 하나의 선으로 0과 1이 불가능하다
순전파와 역전파
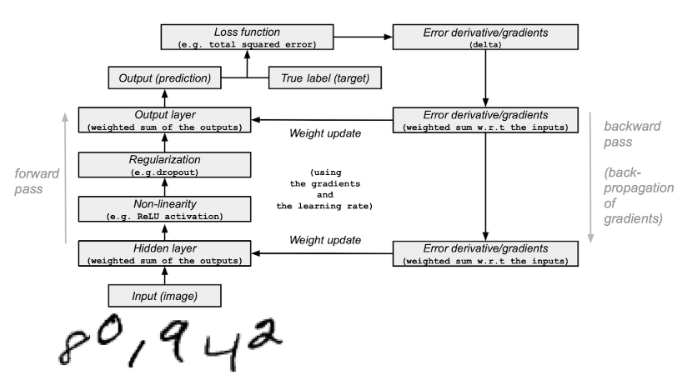
Deep learning on MNIST — NumPy Tutorials
순전파(Forward Propagation)
- 인공 신경망에서 입력층에서 출력층 방향으로 예측값의 연산이 진행되는 과정
- 입력값은 입력층, 은닉층을 지나며 각 층에서의 가중치와 함께 연산되며, 출력층에서 모든 연산을 마친 예측값 도출
역전파(BackPropagation)
- 다층 퍼셉트론 학습에 사용되는 통계적 기법
- 순전파와 반대로 출력층에서 입력층 방향으로 계산하면서 가중치를 업데이트
- 역전파를 통해 가중치 비율을 조정하여 오차 감소를 진행 >> 다시 순전파 진행으로 오차 감소확인 가능
- 출력층에서 제시한 값이 실제 원하는 값에 가까워지도록 학습하기 위해 통계적 방법에 의한 오차 역전법을 사용
- 오차 역전법은 동일 입력층에 대해 원하는 값이 출력되도록 각각의 가중치를 조정하는 방법으로 사용되며, 속도는 느리지만, 안정적인 결과를 얻을 수 있는 장점이 있어 기계 학습에 널리 사용
활성화 함수
- 신호는 실제 뇌를 구성하는 신경 세포 뉴런이 전위가 일정치 이상이 되면 시냅스가 서로 화학적으로 연결
- 활성화 함수는 은닉층과 출력층의 뉴런에서 출력값을 결정하는 함수로 가중치 생성(전위를 만들어 신호 생성)
- 입력값들의 수학적 선형 결합을 다양한 형태의 비선형(또는 선형) 결합으로 변환하는 역할
시그모이드(Sigmoid)
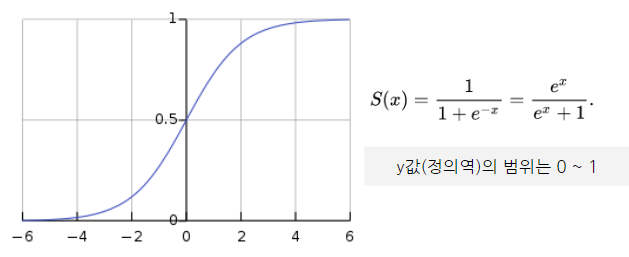
- 시그모이드는 S자형 곡선 또는 시그모이드 곡선을 갖는 수학 함수( ex. 로지스틱 함수)
- 장점) 모델 제작에 필요한 시간을 줄임
- 단점) 미분 범위가 짧아 정보가 손실(Gradient Vanishing 현상)
- 활용 : Logistic regression(로지스틱 회귀), 이진 분류(Binary classification) 등
탄(tanh - 하이퍼볼릭탄젠트 함수)
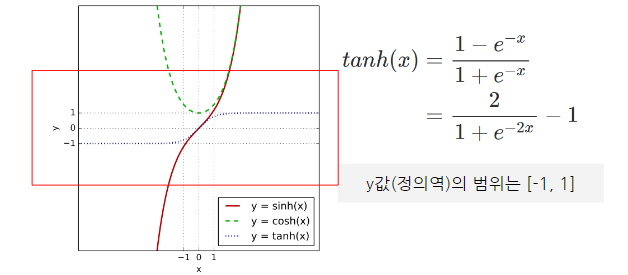
-
tanh는 하이퍼볼릭탄젠트란 쌍곡선 함수 중 하나(Sigmoid의 대체로 사용될 수 있는 활성화 함수)
-
쌍곡선 함수: 삼각함수와 유사한 성질을 가지고, 표준 쌍곡선을 매개변수로 표시할 때 나오는 함수
-
장점) 데이터 중심을 0으로 위치시키는 효과가 있기 때문에, 다음 층의 학습이 더 쉽게 이루어짐
-
시그모이드와 비교시, 출력 범위가 더 넓고 경사면이 큰 범위가 더 크기 때문에 더 빠르게 수렴하여 학습성능↑
-
단점) 미분 범위가 짧아 정보가 손실(시그모이드처럼 Gradient Vanishing 현상)
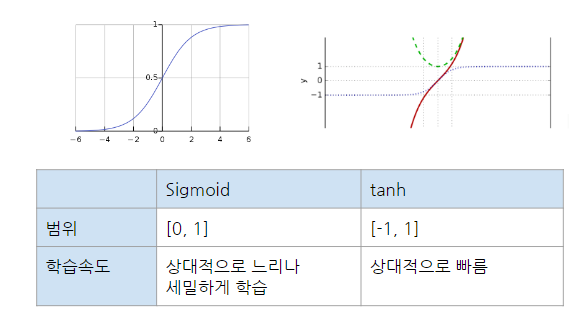
Sigmoid와 tanh
렐루(ReLU)
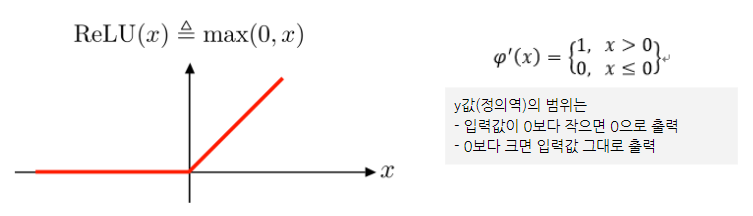
- 기울기 소실을 완화하는 가장 간단한 방법은 은닉층의 활성화 함수로 ReLU나 Leaky ReLU를 사용하는 것
- ReLU 함수는 정류 선형 유닛(Rectified Linear Unit)에 대한 함수로 선형 함수를 개선한 버전
- 장점) Gradient Vanishing문제를 해결 >> 미분 계산이 훨씬 간편해져서 학습 속도가 빨라짐
- 단점) Dying Relu(x가 0보다 작거나 같으면 항상 동일한 값인 0을 출력하기 때문)
리키렐루(Leaky ReLU)

렐루(ReLu)의 Dying ReLu 현상을 해결하기 위해 나온 ReLU의 변형 함수
-
Leaky ReLU는 입력값이 음수일 경우에 0이 아니라 0.001과 같은 매우 작은 수를 반환
-
a는 하이퍼파라미터로 Leaky('새는') 정도를 결정하며 일반적으로는 0.01의 값
-
x가 0보다 작아도 정보가 손실되지 않아 Dying Relu 문제 해결
딥러닝의 학습방법
딥러닝 학습방법 = 출력값과 실제값을 비교하여 그 차이를 최소화하는 가중치(𝒲)와 편향의 조합 찾기
-
가중치는 오차를 최소화하는 방향으로 모델이 스스로 탐색(역전파)
-
오차계산은 실제 데이터를 비교하며, 손실함수(모델의 정확도 평가시 오차를 구하는 수식)를 최소화하는 값 탐색
-
알맞은 손실함수의 선정은 매우 중요 (문제 유형에 따라 다른 손실함수를 적용하여 확인)
-
알맞은 손실함수를 찾아 최소화하기 위해 고안된 방법이 경사하강법이며, 옵티마이저로 경사하강법을 원리를 이용

손실함수(Loss function)
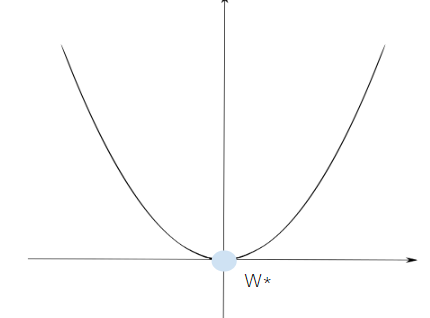
- 손실함수는 실제값과 예측값의 차이를 수치화해주는 함수 → 오차가 작다 == 손실 함수가 작다
- 손실 함수 J(W)가 2차 함수와 같이 볼록 함수의 형태라면 미분으로 손실이 가장 작은 가중치(W* )를 찾을 수 있음
- 2차 함수는 "아래로 볼록한 형태의 2차 함수 그래프에서 기울기(미분)가 0인 지점에서 최솟값을 갖는다."
손실함수의 종류
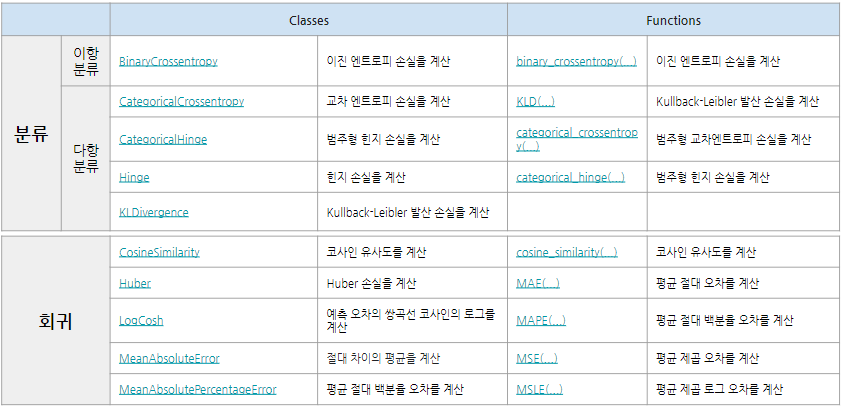
분류의 손실 함수
-
크로스 엔트로피(Cross Entropy Loss)
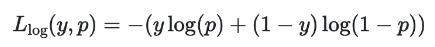
크로스 엔트로피가 낮을 수록 잘 예측한 것
회귀의 손실 함수
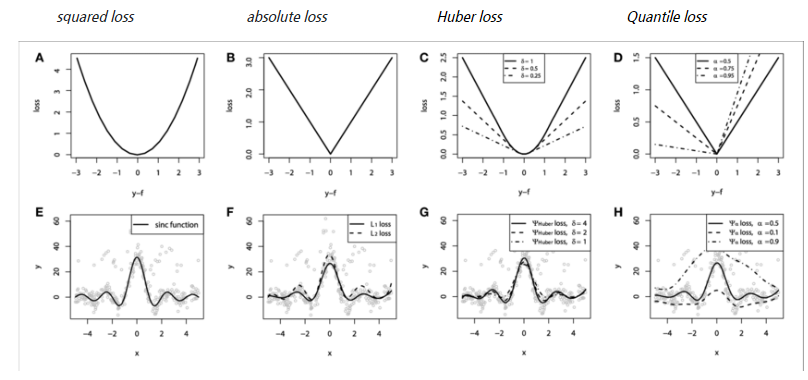
Optimizer 최적화 함수
- 손실함수를 최소화하는 방향으로 가중치를 갱신하는 알고리즘
- 경사하강법에 기반을 둔 옵티마이저로는 SGD, RMSProp, Adagrad, Adam 등
- 등산으로 비유한다면 경사하강법은 내려가는 방향을 찾는방법, 옵티마이저는 효율적(시간,성능 고려)으로 탐색
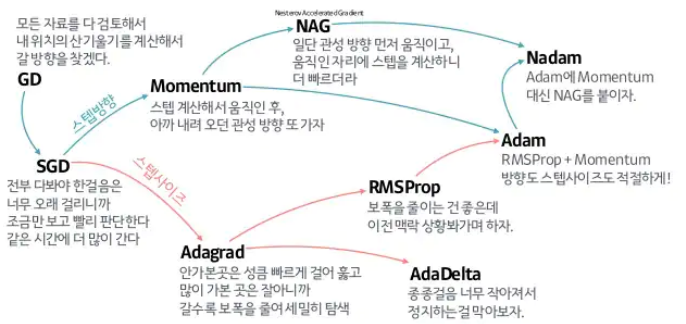
자습해도 모르겠던 딥러닝, 머리속에 인스톨 시켜드립니다. (slideshare.net)
딥러닝 모델링
딥러닝과정

- dropout 과대적합 방지위해 일부 제거
분류의 출력
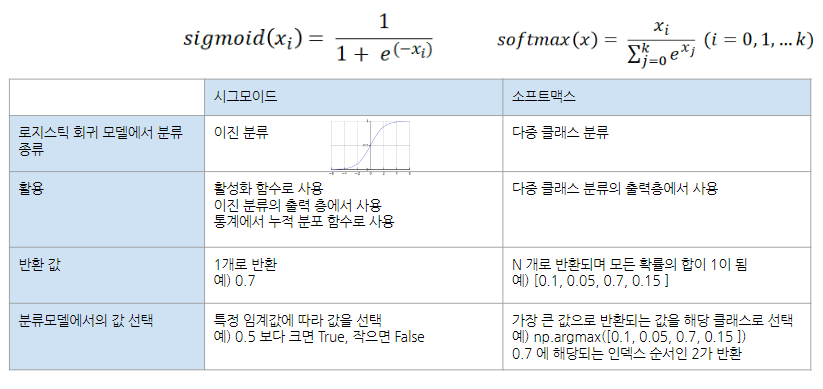
- np.argmax 가장 큰 값의 인덱스 반환
- sparse_categorical_crossentropy 는 정답값이 어떤 형태일 때 사용할 까요?
multi-class category- sparse_categorical_crossentropy 와 categorical_crossentropy 의 차이점?
categorical_crossentropy는 라벨이 원핫 벡터,
sparse_categorical_crossentropy는 라벨이 정수형태
3.optimizer = tf.keras.optimizers.RMSprop(0.001) <= 0.001 은 무엇을 의미할까요?
learnig_rate
4.mnist 실습에서 사용했던 출력층과 mpg 실습의 출력층의 차이?
mnist실습에서는 출력층에서 가능한 class의 개수인 10개, 지금은 연속형 예측치 1개를 출력
부족한 것
- 서브플롯 이쁘게 그리기 ㅠㅠ
- for문 걍 외워버리기
3F
사실(Fact) : 딥러닝 기초에 대해 배웠다.
느낌(Feeling) : 한국어인데 한국어가 아닌거 같은..
교훈(Finding) : 일단 용어에 익숙해질 필요가 있다.
