모델에게 Reasoning을 어떻게 더 잘 학습시킬까 고민하다가 발견한 논문.
논문 리뷰
https://arxiv.org/pdf/2310.01798.pdf
reflection과 같은 방법론들에서 self-correct(self-refine, self-improve 등등)하는 방법론들이 많이 나타나지만 치명적인 단점인 어떤 답변이 correct인지 incorrect인지 자동적으로 구별할 수 없다는 것.
많은 논문들에서는 incorrect한 답변들만을 가지고 feedback을 통한 refine을 거친다.
하지만 그렇기 위해서는 답변이 incorrect한지에 대한 평가가 필요. 이는 code generation과 같은 작업에서는 유효하지만 math reasoning에서는 사용할 수 없고 inference time에 적용이 어렵다.
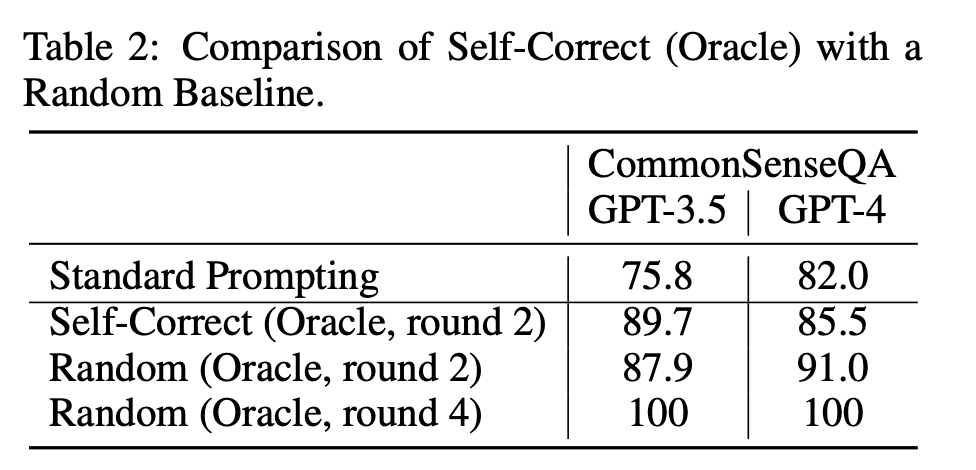
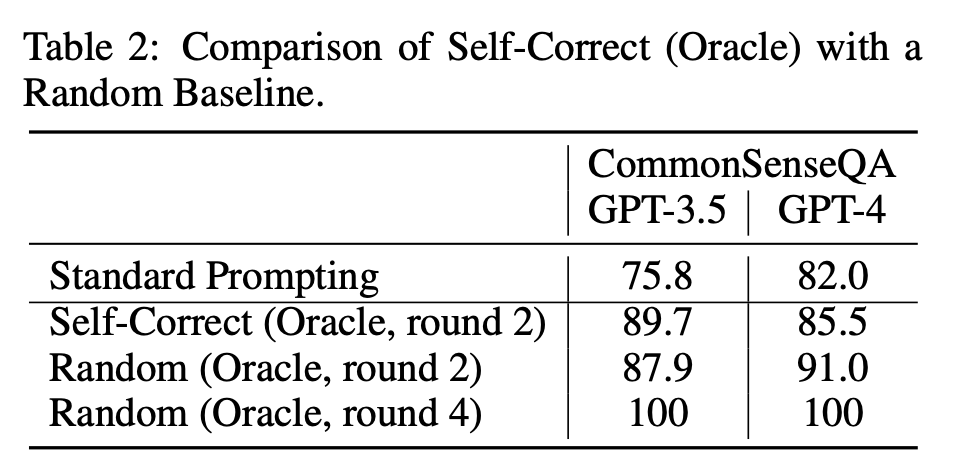
그것을 실험적으로 증명해낸 논문. 결국에 성능이 올랐 것은 incorrect한 answer에 대해 refine을 진행했기 때문. 오히려 random하게 하는 방법론보다도 성능이 떨어지기에 intrinsic-correction 작업은 LLM이 불가능하다고 말함.
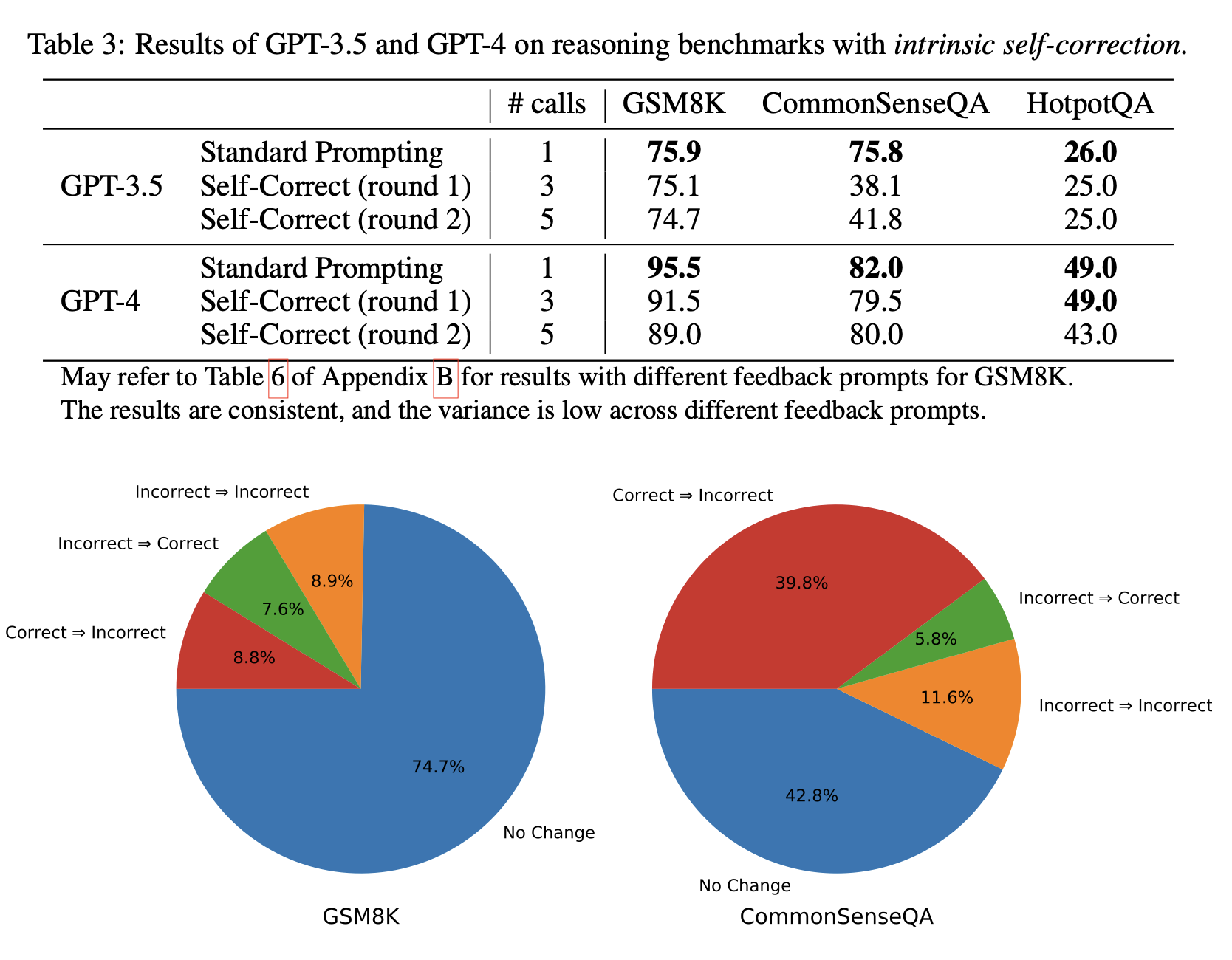
또한, feedback을 주는 방식이 아니라 initial prompting 자체를 보다 정확하게 주는 것이 성능을 높이는데 더 도움이 된다고 얘기함. 이를 토대로 볼 때, LLM은 feedback에 대해 생각해서 답을 refine했던 것이 아닌 correct한지 incorrect한지 평가하는 외부 주체나 external knowledge가 반영되었기에 성능이 오를 수 있었다는 것
그럼 그것도 자동적으로 LLM을 여러 개 두어 debate하는 방식으로 보완할 수 있지 않을까?
하지만 그것보다는 한 모델(논문에서는 여러 모델이라고 얘기함)에 여러 inference를 하고 merging하는 방식인 self-consistency 방식이 더 유효하다고 한다. 즉, 더 나은 방식이 있다는 것.
✏️ 발전방향
우리가 모델에게 생성을 시킬 때에 답을 모르는 상황만 있지는 않기 때문에 논문의 내용이 옳기만 하지는 않다. 그럼에도 모델이 correct answer를 incorrect하게 만드는 상황은 chat-gpt를 사용할 때에도 여러 번 겪는 상황이다. 지금까지 모델이 refine했던 것은 사실상 external knowledge에 의존했다는 것도 맞는 것 같다.
이를 보완하기 위한 방법론에서는 결국 correct와 incorrect를 automatically evaluate할 수 있는 방법론이 나와야 한다는 것인데 reasoning 특성 상 쉽지 않다. 따라서 refine하는 방법론보다는 모델 자체에 잘못 생성된 답변에 대한 negative reward를 보다 명확하게 주어 해당 generation trajectory를 피해갈 수 있도록 만드는 등 correction이 모델에 전달시킬 수 있는 방법들을 생각해봐야 할 것 같다. contrastive prompting에 대한 논문도 있기에 좀 살펴봐야 할 것 같다.
