오늘은 시계열데이터, 좀 더 정확하게 말하자면 생체 신호 데이터에서 이상치 탐치하는 법에 대해서 공부를 해보았다.
이 글은 개인적인 기록이자 내가 공부한 것에대한 정리용도임을 먼저 밝힌다. 때문에 정확하지 않은 지식이 마구 섞여있을 것이다. 최대한 조심하고 있지만 잘 모르는 입문자 압장에서 너무 많은 고민을 하다가는 한 줄도 정리하지 못 할것 같아 그냥 적기로 했다.
앞으로도 생각나는데로 작성할 생각이라 점차 지식이 쌓여가면 좀 더 정확해 지지 않을까 생각한다. 그러므로 혹시라도 이 글을 읽게 되시는 분들은 그냥 '이런게 있구나' 정도의 참고만 해주면 좋을 것 같다.
anomaly detection
STL Decomposition
시계열 이상치 탐색에서 가장 먼저 볼 수 있는 것은 STL decomposition이다.
Seasonal, Trend, Loss
좀 더 정확히 말하자면
"Seasonal and Trend decomposition using Loess"
사용방법은 간단하다
from statemodels.tsa.seasonal import seasonal
result = seasonal_decompose(temp, model='additive', period=100)
result.plot()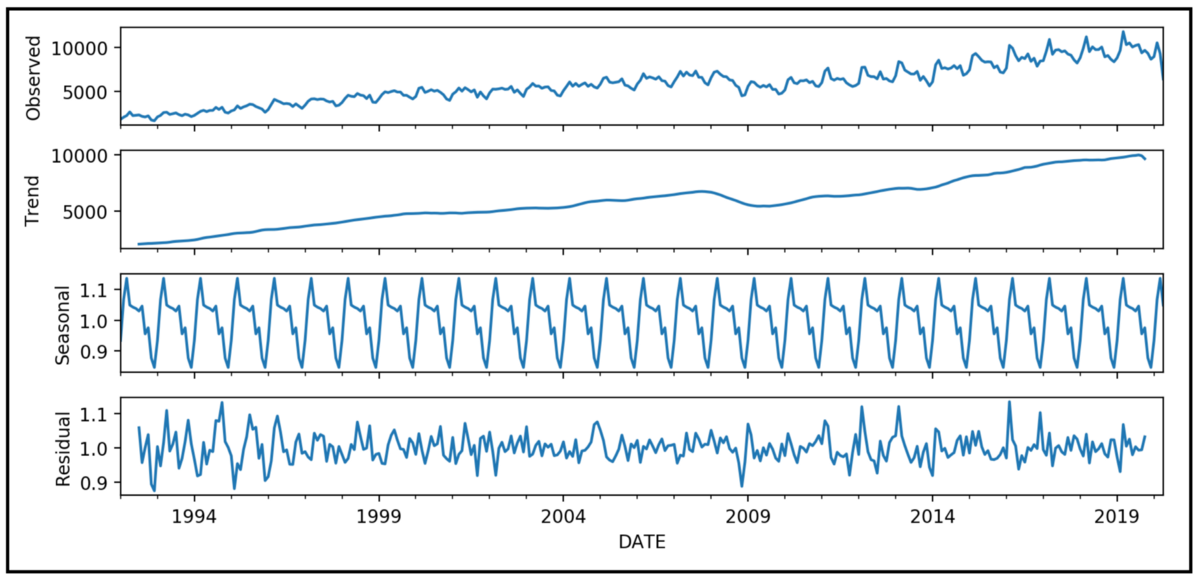
내가 돌린 코드의 결과는 회사 대외비라 공개가 어려워 구글에 돌아다니는 아무 이미지를 첨부하였다.
이처럼 tred와 seasonal, residual 세 가지로 분류가 된다.
- trend
- 반복되는 주기 속에서 점점 올라간다던지 내려간다던지 하는 '추세'를 보여준다.
- seasonal
- 변화하는 과정속에서도 반복되는 '주기성'을 보여준다.
- residual
- 잔차, 규칙성에서 벗어나는 수치만큼을 잔차로 돌린다,
계산하는 방법은(배웠었는데...) 모른다. 개념이 이렇구나 정도로 하고 업무에 활용해 보았다.
분류 및 회귀 트리(CART)
이 방법이 효과가 나쁘지 않았다고 본다.
decision tree 기반의 알고리즘으로 Isolation Forest라고 부른다.
냅다 코드부터 갈겨본다.
from sklearn.preprocessing import StandardScaler
from sklearn.ensemble import IsolationForest
outliers_fraction = float(.01) # 이상치를 얼마나 잡을지에 대한 비율
scaler = StandardScaler()
np_scaled = scaler.fit_transform(x.values.reshape(-1,1))
cast_scaled_df = pd.DataFrame(np_scaled)
model = IsolationForest(contamination=outliers_fraction)
model.fit(cast_scaled_df)
fsr0_c['anomaly'] = model.predict(cast_scaled_df)output을 보여줄 수 없는게 너무 아쉽다.
간단히 이해한 원리를 설명하자면 decision tree의 원리 처럼 데이터들을 분해한다.
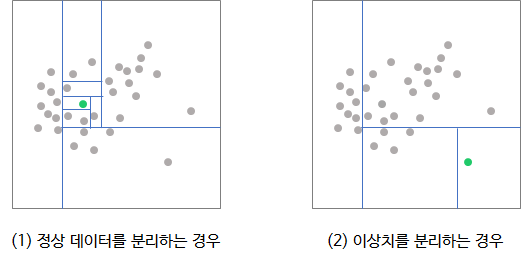
트리모델의 경우 이렇게 분해를 해서 분류를 하는데
isolation forest의 경우 반대로 '얼마나 많이 분리해야하는가' 를 기준으로 이 데이터가 이상치인지 아닌지를 분류한다.
다시 말해서 이름처럼 데이터를 고립시키는 분류 과정을 거치는데 데이터가 단독으로 고립되기 위해서 몇 번을 나눠야 하는가 이 과정이 많을 수록 정상데이터, 쉽게 고립된다면 이 데이터는 이상치라고 볼 수 있는 것이다.
신호처리를 공부하면서 현실 데이터에서 이상치가 많이 발생해서 이를 처리하는 과정이 필수적으로 필요하다. 덕분에 요즘 전에 하지 않았던 공부들을 많이 하게 되는데 앞으로 더 많은 anomaly detection에 대해서 공부를 하게 될것 같다. 계속 생체신호처리 섹션에 업로드 하겠다.
