

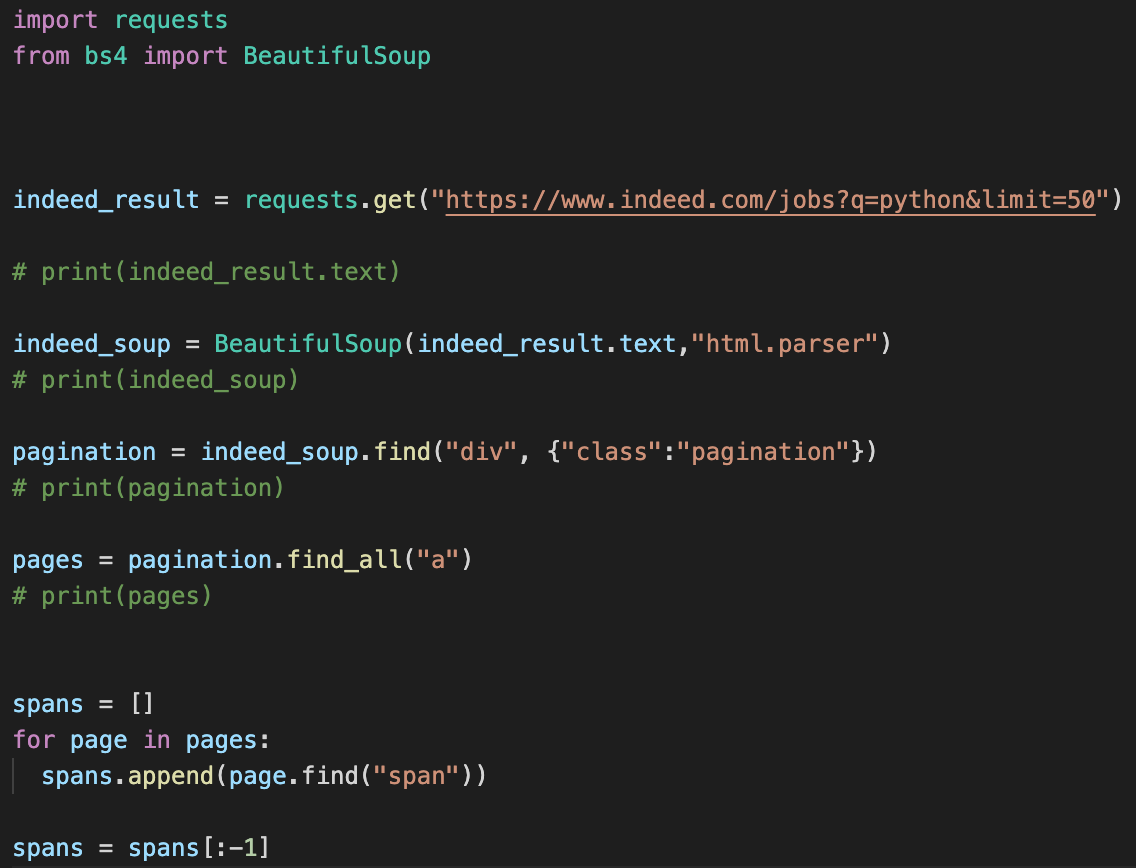
리퀘스트와 bs4를 불러온다
import requests
from bs4 import BeautifulSoup
indeed_result = requests.get("https://www.indeed.com/jobs?q=python&limit=50")
리퀘스트는 url의 정보를 scrap 해오는 것이라고 생각하고
indeed_soup = BeautifulSoup(indeed_result.text,"html.parser")
soup를 통해 받아온 Url의 데이터를 추출한다
pagination = indeed_soup.find("div", {"class":"pagination"})
우리가 찾고자하는 정보가 div 태그안 pagination 클래스에 있었으니 (밑에 페이지숫자버튼) soup.find("div",{"class" : "pagination"})을 통해 세분화하게 안의 정보를 추출한다
pages = pagination.find_all("a")
pagination 데이터한 a 태그를 모두 불러온다
spans = []
for page in pages:
spans.append(page.find("span"))
span 태그안의 정보를 불러올것인데 반복문을 통해 a태그안의 모든 span 태그를 찾을 것이고 (여기서는 페이지 숫자 12345번 값이였음)
spans = spans[:-1]
spans 배열에 모두 담아 둘것인데, 그중 가장 마지막의 정보를 제외 ":-1" 하고 배열에 담을 것이다. spans[0:5] = 12345 5개를 불러옴 spans[:-1] = 뒤에서 마지막 하나를 없애고 불러옴 spans[0:-1] = 처음 0 부터 마지막인 -1 를 없앤부분 까지 불러옴
접속대상
- (https://www.indeed.com/q-python-jobs.html)
- (https://www.indeed.com/jobs?as_and=python&limit=50)
- (https://stackoverflow.com/jobs?q=python)
python으로 URL에서 자료 추출하기
- python 기본 라이브러리 urllib : 사용x, 더 강력한 온라인 라이브러리 사용하기 위해
- Request 사용o
(https://requests.readthedocs.io/projects/3/)
(https://github.com/psf/requests)
HTML에서 정보추출하기
- Beautiful Soup4
(https://www.crummy.com/software/BeautifulSoup/)

순서요약
1) 모듈설치
2) 가져올 페이지의 url요청 (get .text)
3) 원하는 html 파트 가져오기 (Beautiful Soup)
4) pagination 찾기
5-1) pagination 안의 모든 앵커 찾기
5-2) loop를 이용해 각 페이지의 "span" 모두 찾기
6) 불러올 페이지 넘버 지정해주기
#1. Import Packages (모듈설치)
-영상에서 쓰인 모듈 :
ㄴRequest (사이트 정보 가져오기 (text))
ㄴBeautiful Soup (html 내 필요한 부분 추출하기 (html))
#2. 가져올 페이지의 url요청 (request.get)
-페이지.text 가져왕
#3. 원하는 html 파트 가져오기 (Beautiful Soup)
-위 .text에서 HTML 불러왕 (html.parser)
#4. HTML 내에서 내가 원하는 정보의 pagination(페이지 네비게이터)을 찾기(indeed_soup.find)
ㄴ"div" 를 찾아서 "pagination" 클래스 불러옴
#5-1. pagination 안의 모든 앵커('a href' 형태로 되어있는 링크들) 찾아주기
ㄴpagination.find_all('a'))
#5-2. 페이지 링크마다 있는 태그를 각각 모두 불러와줘야 하므로 loop(for-in) 사용
ㄴfor link in links: pages.append(link.find("span"))
#6. 어디서부터 어디까지 불러올건지 페이지 넘버 지정해주기
ㄴpages = pages[0:-1]