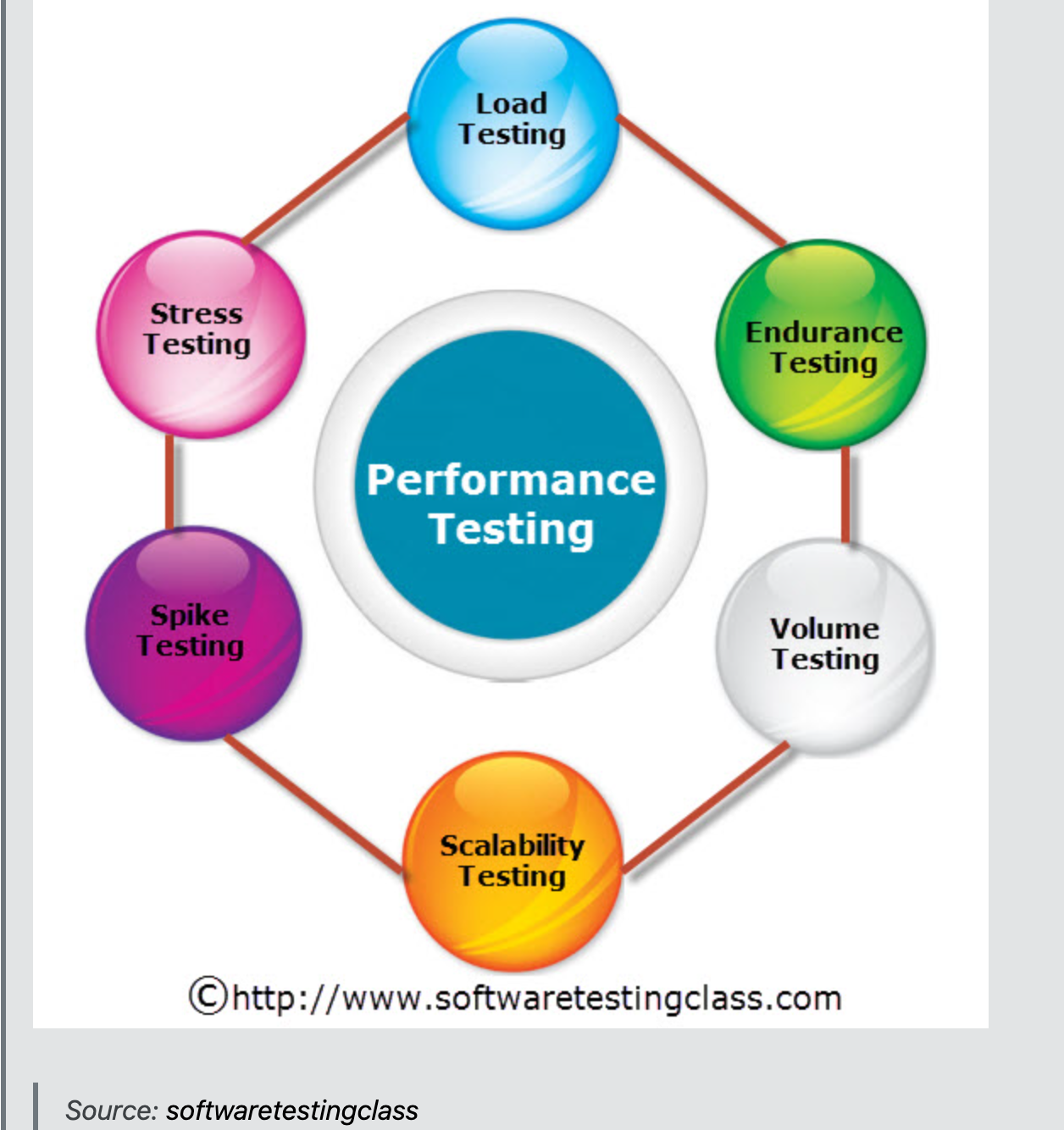
1. Perfomance Test의 종류
- Load Testing
Load Testing은 부하가 임계치(Threshold Value)에 도달할 때까지 시스템의 부하를 지속적으로 증가시키면서 시스템을 확인하는, Performance Testing의 한 유형입니다. 여기서 부하를 증가시킨다는 것은, 동시단말사용자(concurrent users)와 트랜잭션을 증가시키면서 테스트 중인 애플리케이션의 동작을 확인하는 것을 의미합니다. ‘Endurance testing’ 또는 ‘Volume testing’이라고 불리기도 합니다.
Load Testing의 주요 목적은 과부하 상태(under heavy load)에서 시스템이 잘 작동될 때, 응답시간과 애플리케이션의 지구력(staying power)을 모니터링하는 것입니다. Load Testing과 아래에 기술된 테스트들은 모두 비기능 테스트(NFT/ Non Functional Testing)에 속하며, 소프트웨어 애플리케이션의 비기능 요구사항을 테스트하기 위해 설계되었습니다.
Load Testing은 테스트중인 애플리케이션이 견딜 수 있는 부하의 양을 확인하기 위해 수행됩니다. ‘성공적으로 수행된 Load Testing’은 지정된 테스트 케이스가 할당된 시간동안 오류없이 수행된 경우에만 가능합니다.
- Stress Testing
Stress Testing은 CPU, Memory, Disk Space 등과 같은 하드웨어 자원이 충분하지 않을 때, 소프트웨어의 안정성을 확인하는 Performance Testing의 한 유형입니다. Stress Testing의 기본 개념은 시스템의 오류를 확인하고, 어떻게 시스템이 정상적으로 복구되는지를 살펴보는 것입니다.
“To determine or validate an application’s behavior when it is pushed beyond normal or peak load conditions.”
Stress Testing은 시스템 하드웨어 자원에서 처리할 수 없는 많은 수의 동시단말사용자(concurrent users)/프로세스로 소프트웨어에 부하를 주는 Negative Testing입니다. 이 Testing은 피로시험(Fatigue testing)으로도 알려져 있습니다.
Stress Testing의 기본 개념은 시스템의 장애를 확인하고 시스템이 어떻게 정상적으로 복구되는지를 주시하는 것입니다. 이러한 품질 특성을 회복성(recoverability)이라고 합니다.
- Spike testing
Spike testing은 Stress Testing의 Subset입니다. 테스트 대상 시스템에 대해, 상용 운영환경에서 예상되는 부하 이상의 Workload를 짧은 기간동안 반복적으로 증가시킬 때 나타나는 성능 특성을 검증하기 위해 수행합니다.
- Endurance testing
Endurance testing은 시스템의 동작을 확인하기 위해, 장기간에 걸쳐 예상되는 부하량에 기반하여 시스템을 테스트 하는 것을 포함합니다. 예를 들어, 시스템이 3시간동안 작업을 수행하도록 설계되었다면, 동일 시스템이 6시간동안 지속되어도 시스템이 지구력을 유지하는지를 확인하는 것입니다. 가장 일반적인 테스트 케이스는 메모리 누수, 시스템 장애 또는 무작위적인 동작(random behavior)과 같은 시스템의 동작을 확인하기 위해 수행됩니다. 때때로, Endurance testing은 ‘Soak testing’이라고도 합니다.
- Scalability Testing
Scalability Testing은 사용자 부하, 트랜잭션 수, 데이터 볼륨 등과 같은 비기능 측면에서 확장할 수 있는 역량을 판단하기 위한 소프트웨어 애플리케이션 테스트입니다. 이 테스트의 주요 목적은 더이상 확장(Scaling)하지 못하도록 막는 ‘시스템의 Peak’가 무엇인지 확인하는 것입니다.
- Volume testing
Volume testing은 처리해야 할 많은 양의 데이터를 가진 애플리케이션의 효율성을 확인하기 위한 테스트입니다. 이 테스트의 주요 목표는 다양한 Database Volumes 하에서 애플리케이션의 성능을 모니터링 하는 것입니다.
Perfomance Test를 통해 얻고자 하는 것.
위에 있는 내용을 정리하자면 성능 테스트는
- 병목지점
- 시스템의 성능 임계치
- 지구력
- 회복성
등을 미리 확인하기 위해 진행합니다.
필자는 시스템의 성능 임계치, 병목지점을 찾는 Load Testing, Scalability Testing을 해보고자 합니다.
2. JMeter 테스트 시나리오 설정
테스트 시나리오 구성 의도
-
실제 어플리케이션에서는 더 많은 API가 있고 Kafka, In memory구조의 Repository, Redis등 여러 리소스가 사용되지만 테스트 단순화를 위해 RDB만을 사용하는 가장 기본적인 상황을 가정하였다.
-
조회 이외에 락을 사용하는 수정과 생성을 포함하였다.
-
유저들의 행동 패턴의 종류는 다음과 같다.
- 매칭 방 생성
- 매칭 방 조회
- 매칭 방 참여 및 취소
-
유저들의 행동 패턴의 빈도수는 다음과 같다.
- 매칭 방 조회 >> 참여 및 취소 > 생성의 순으로 이루어진다.
- 매칭 방 조회는 대략 참여 및 취소에 비해 10배, 참여 및 취소는 생성보다 3배 더 자주 발생한다고 가정한다.
-
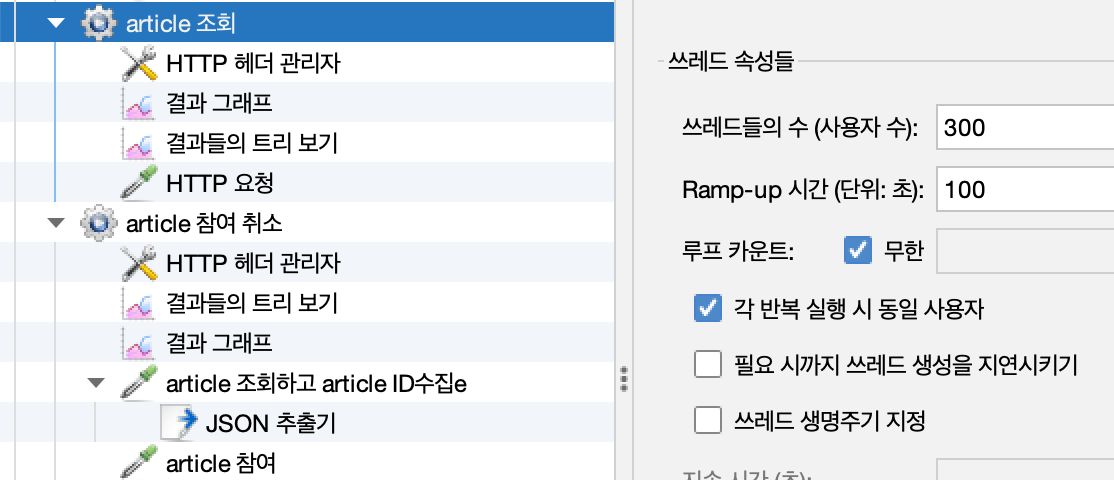
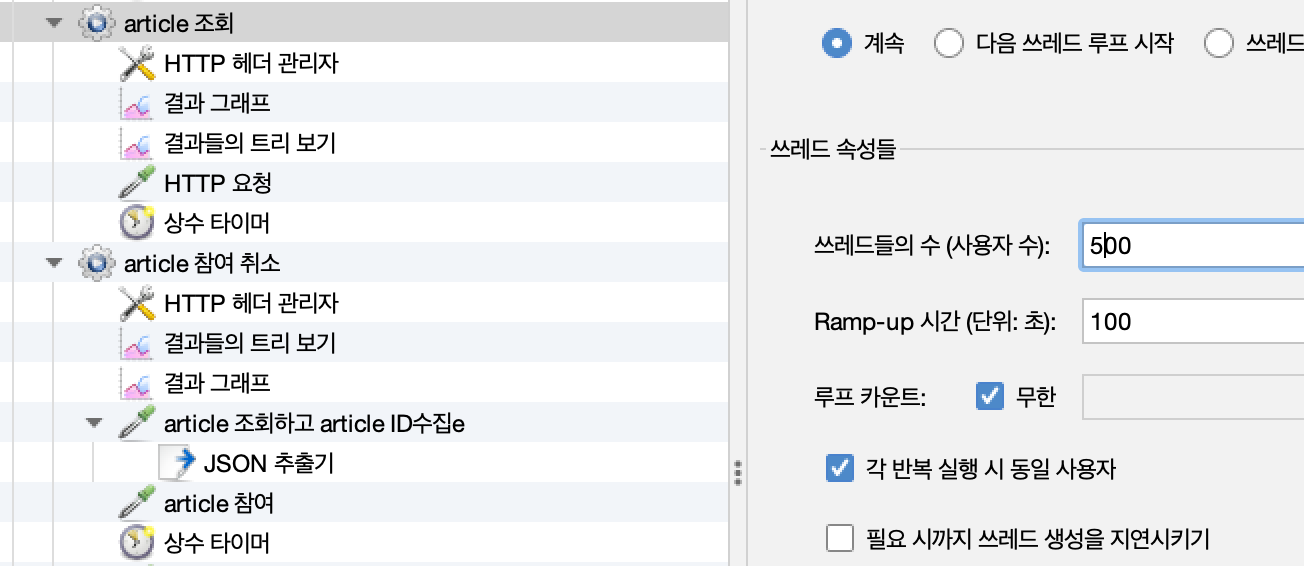
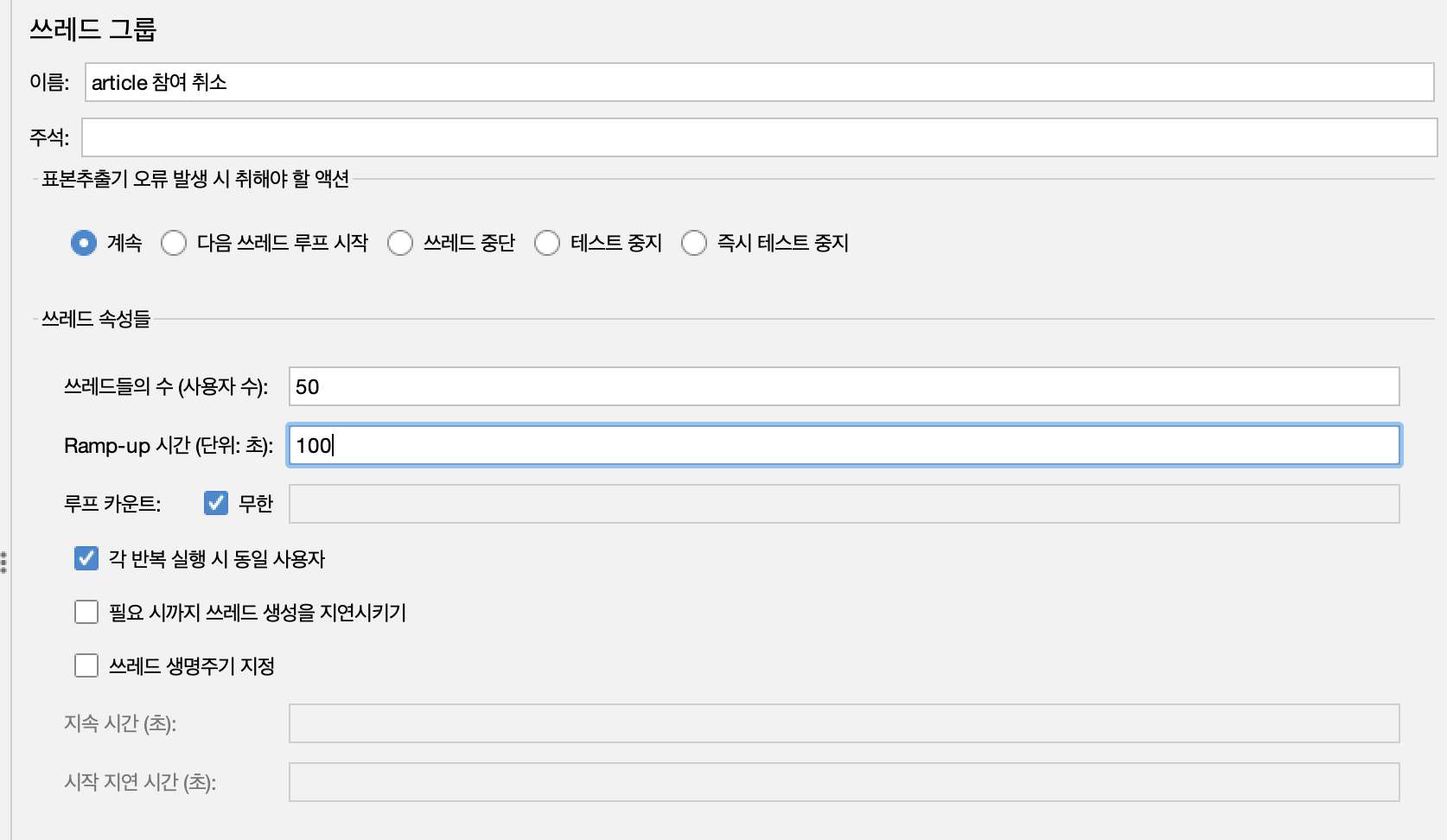
테스트 시간은 100초이다. JMeter의 Ramp-up 시간을 100초 정도로 하여 부하를 점진적으로 증가시킨다.
-
요청 빈도는 쓰레드 수, 상수 타이머를 통해 시간 간격을 조정하여 다르게 구성한다.
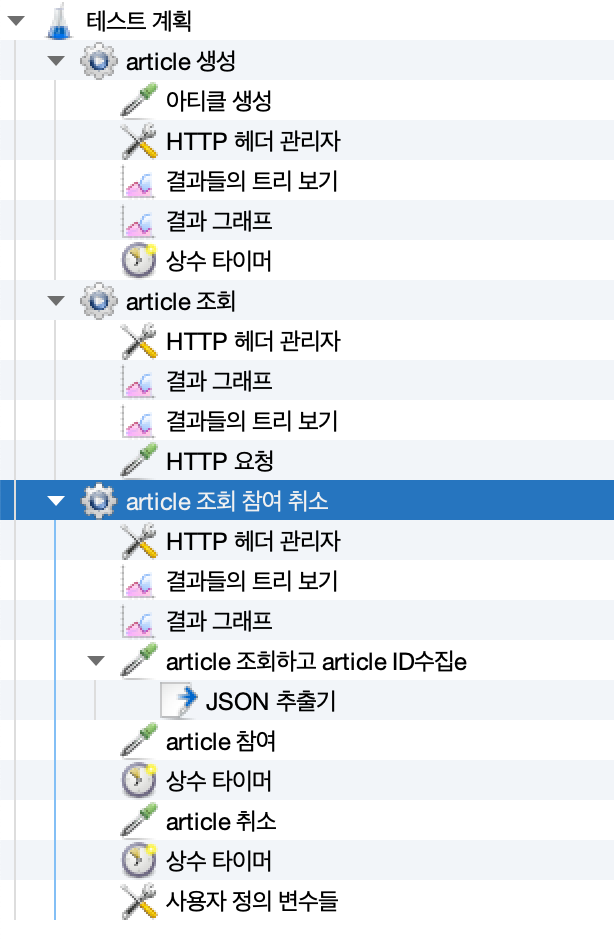
JMeter에서 이전 요청의 응답 데이터를 다음 요청에 포함시키는 법
JSON 추출기
- 응답에 실려있는 Id값을 추출한다.
- '${__threadNum}'은 함수로 스레드의 번호를 가져온다. 이로서 스레드마다 서로다른 방에 참여하고 취소할 수 있다.
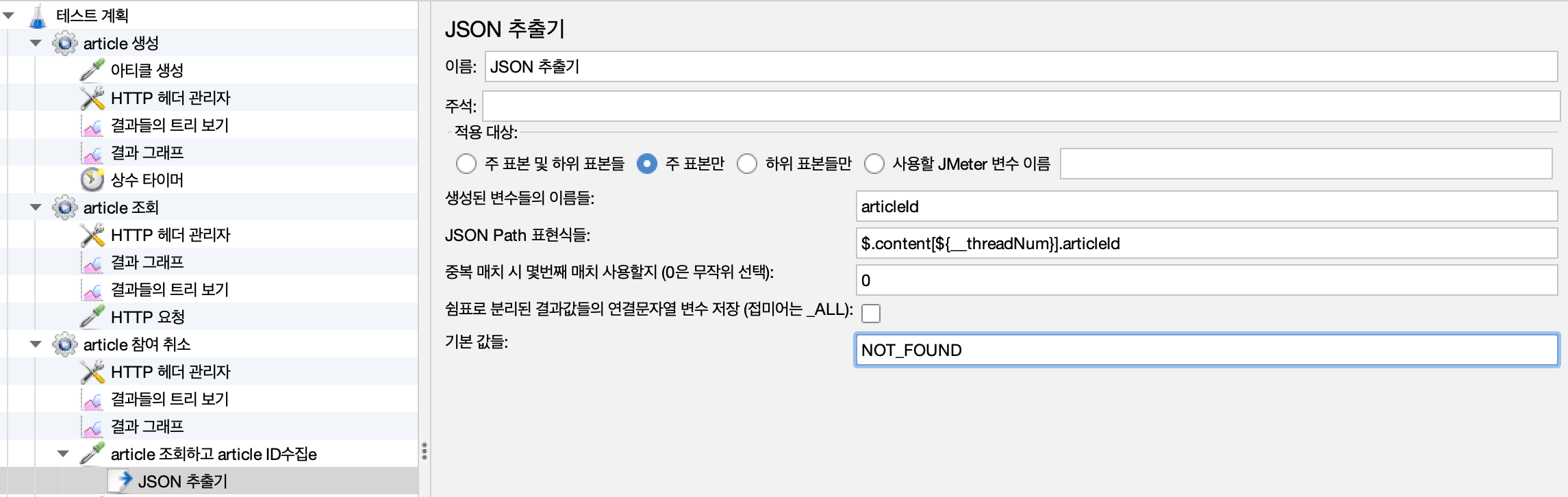
추출된 변수 사용
- 하나의 스레드 그룹에서 요청을 시작하면 해당 스레드 그룹 내의 요청 들은 변수값을 공유하게 된다.
- JMeter는 왼쪽 GUI 위에서 아래로 실행된다. 따라서 article 참여 취소는 article 조회, articleId 변수 생성-> article 참여 요청 -> 상수 타이머 -> article 참여 취소 요청 -> 상수 타이머 순으로 동작한다.
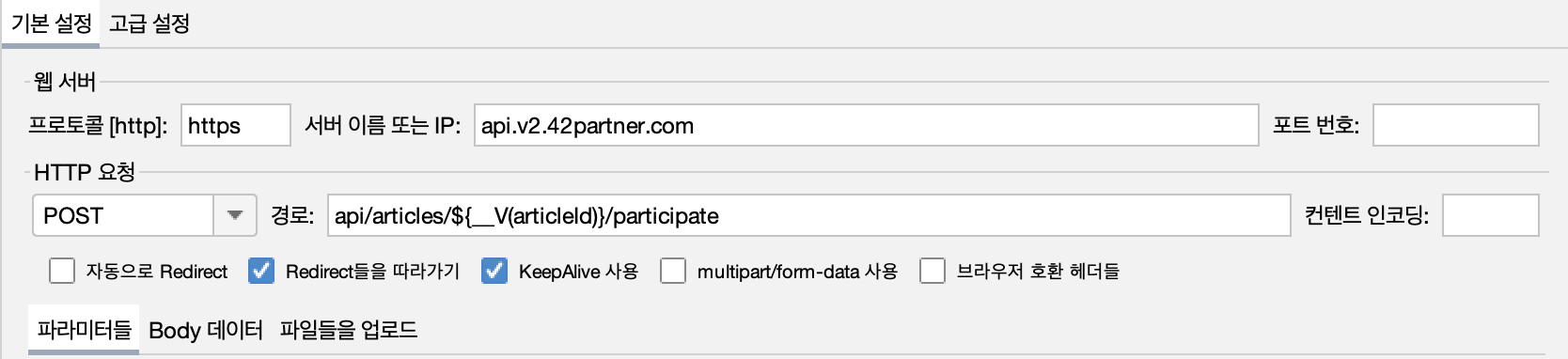
JWT 헤더
- HTTP 헤더 관리자로 JWT를 설정한다.
3. Scalability Test - WAS Default 설정인 상태로 장애 지점까지 테스트.
3-1. 테스트 목적과 유의점
- 네트워크 ELB, Route53, Nginx(Reverse proxy)등에서 먼저 병목이 생기지 않도록 유의하여야합니다.
- WAS Default 설정인 상태로 장애 지점까지 테스트하여 현재 시스템의 임계점을 찾습니다. 추후에 설정값들을 변경하여 개선합니다.
- RDS의 부하를 모니터링 하여 스펙이 제대로 되었는지 등을 점검합니다.
- MSK, ElastiCache등은 해당 테스트 시나리오에서 사용은 되지만 성능 부하가 미비하므로 따로 체크 하지는 않겠습니다.
3-2. 현재 시스템 스펙
EC2
- t3.micro(RAM 1GB, 2VCpu) 총 2대 ASG로 4대까지 증설 가능
JVM
- Thread pool
- maxSize: 제한 하지 않음(무한대로 증가할 수 있는 것으로 보임)
- maxQueueSize: 제한 하지 않음(무한대로 증가할 수 있는 것으로 보임)
- DBCP
- Default 10
RDS
- t3.micro(RAM 1GB, 2VCpu)
- max_connection 동적으로 결정됨. 80
- 대략 16GB인 경우 1300정도라고 함. 따라서 1GB인 현재에서는 80정도.
AWS공식문서 링크

- 대략 16GB인 경우 1300정도라고 함. 따라서 1GB인 현재에서는 80정도.
- Stand By DB 존재
- Replication, Sharding 하지 않음.
3-3. 부하 테스트 결과
테스트 조건
-
조회 api
-
수정및 Redis pub/sub, Kafka 이벤트 produce가 발생하는 api
테스트 결과
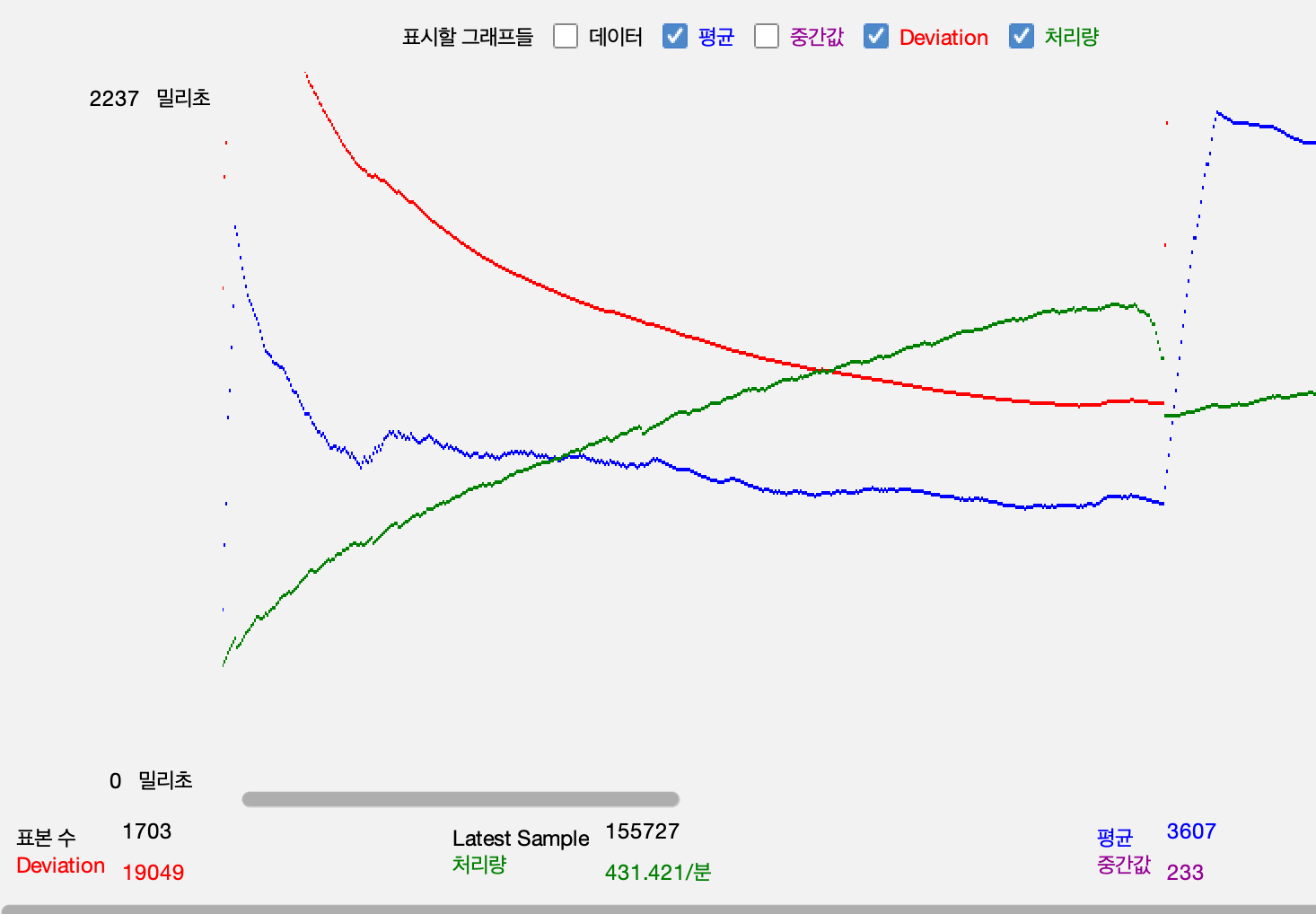
- Throughput, Response time 평균, 표본 편차
- 조회 api
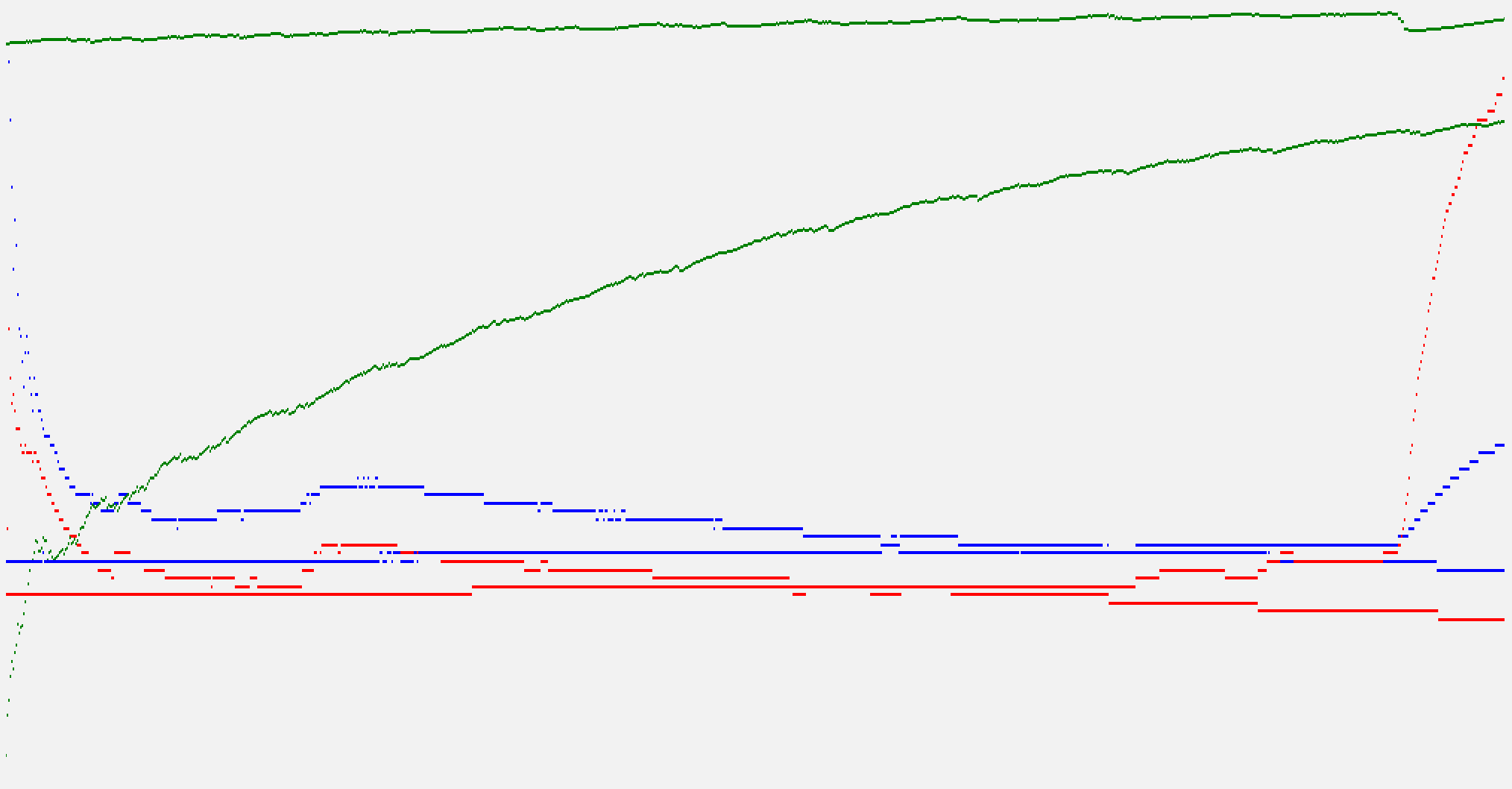

- 조회 api
- 수정및 Redis pub/sub, Kafka 이벤트 produce가 발생하는 api
- 그래프가 끊기는 지점에서 reponse time Deviation이 급격하게 증가하면서 요청이 제대로 처리되지 못함.
Web Application Server
-
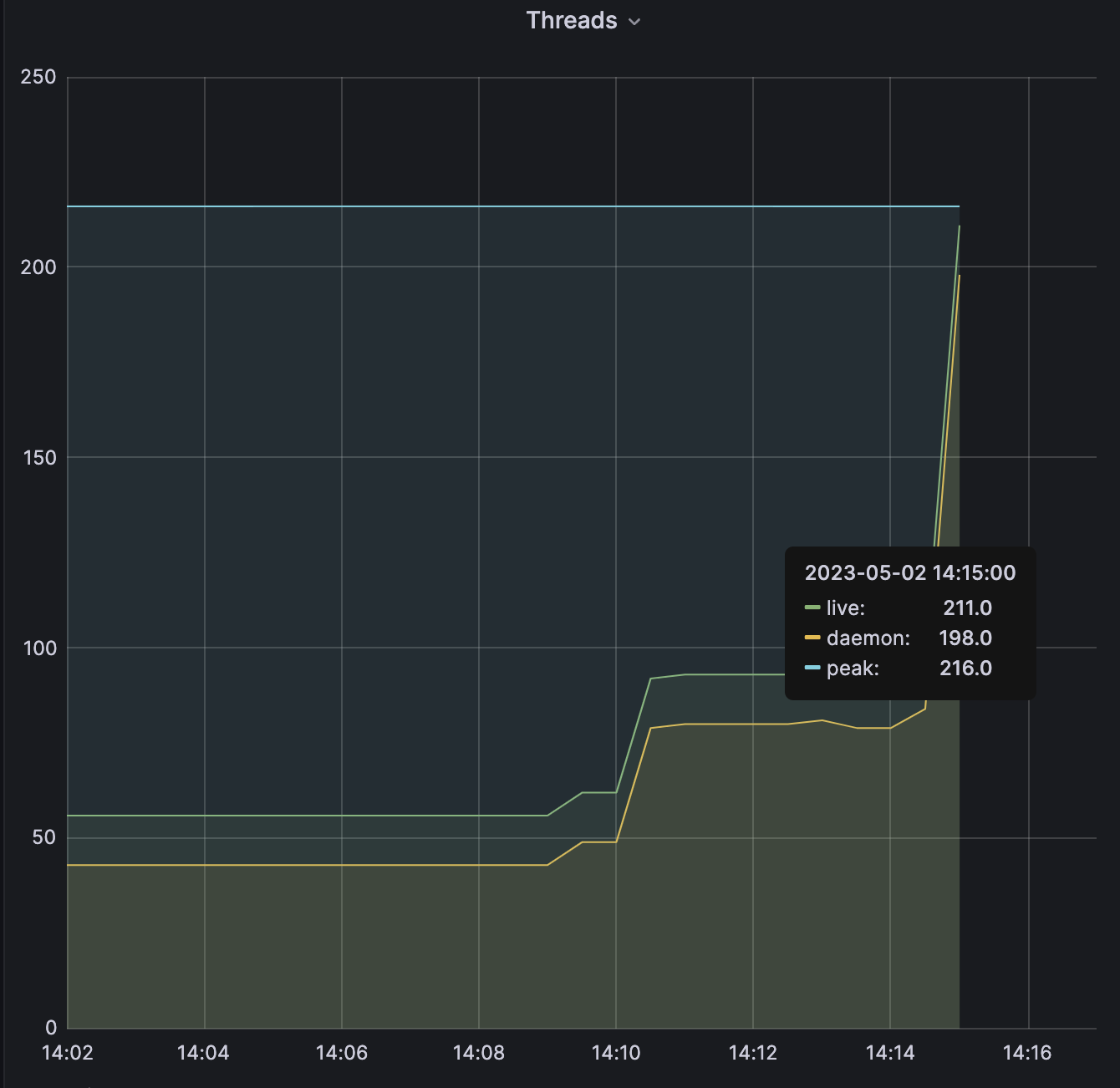
Threads pool
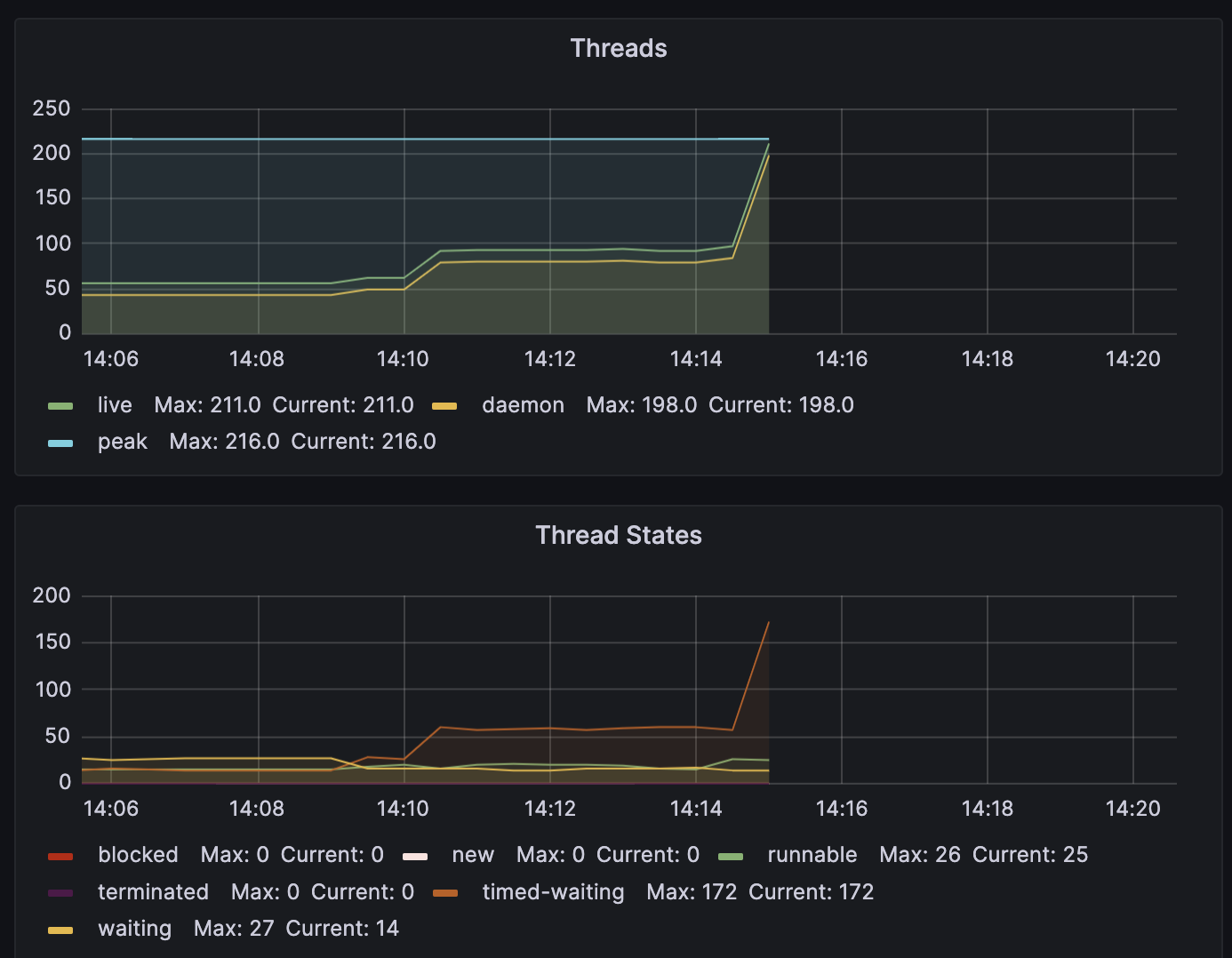
-
DBCP
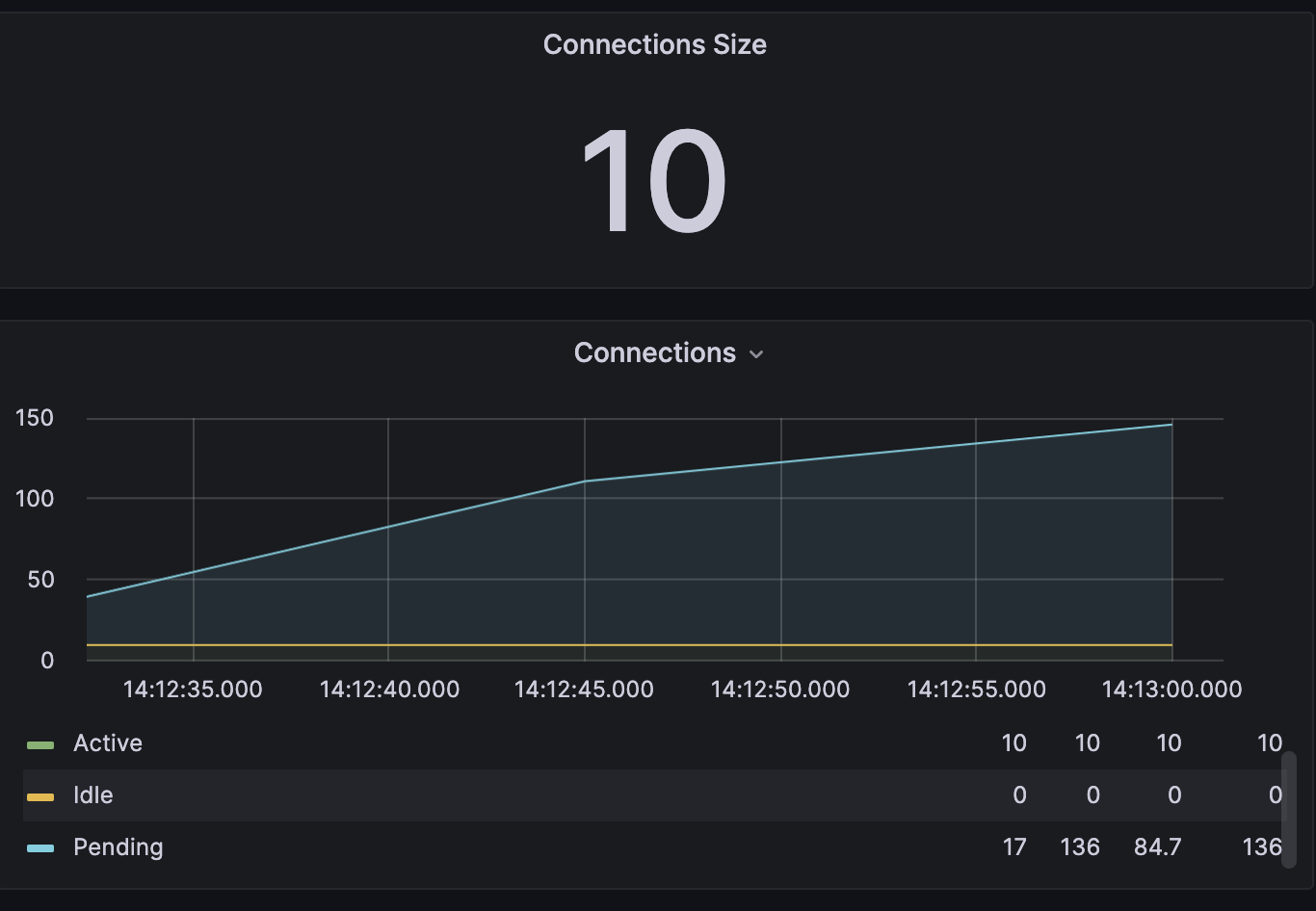
-
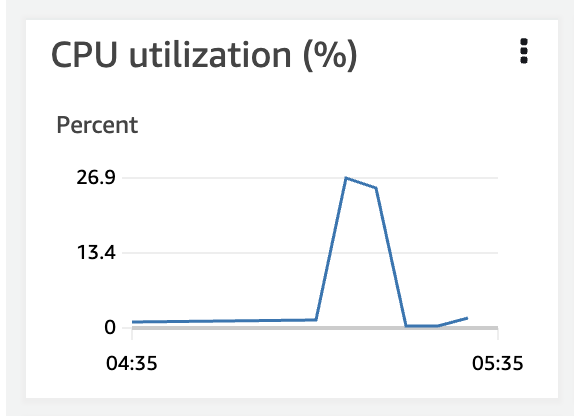
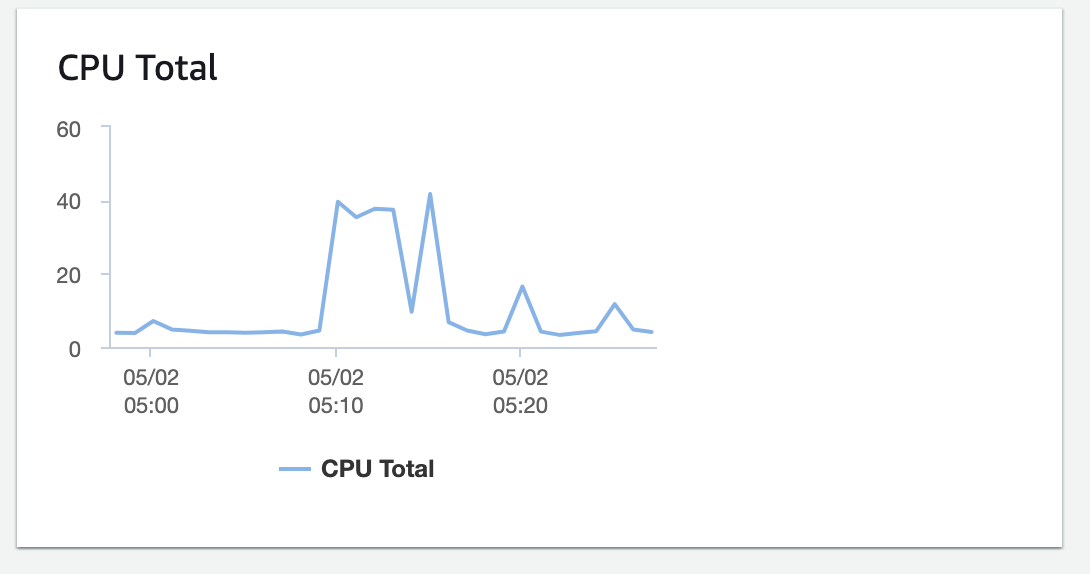
CPU사용률
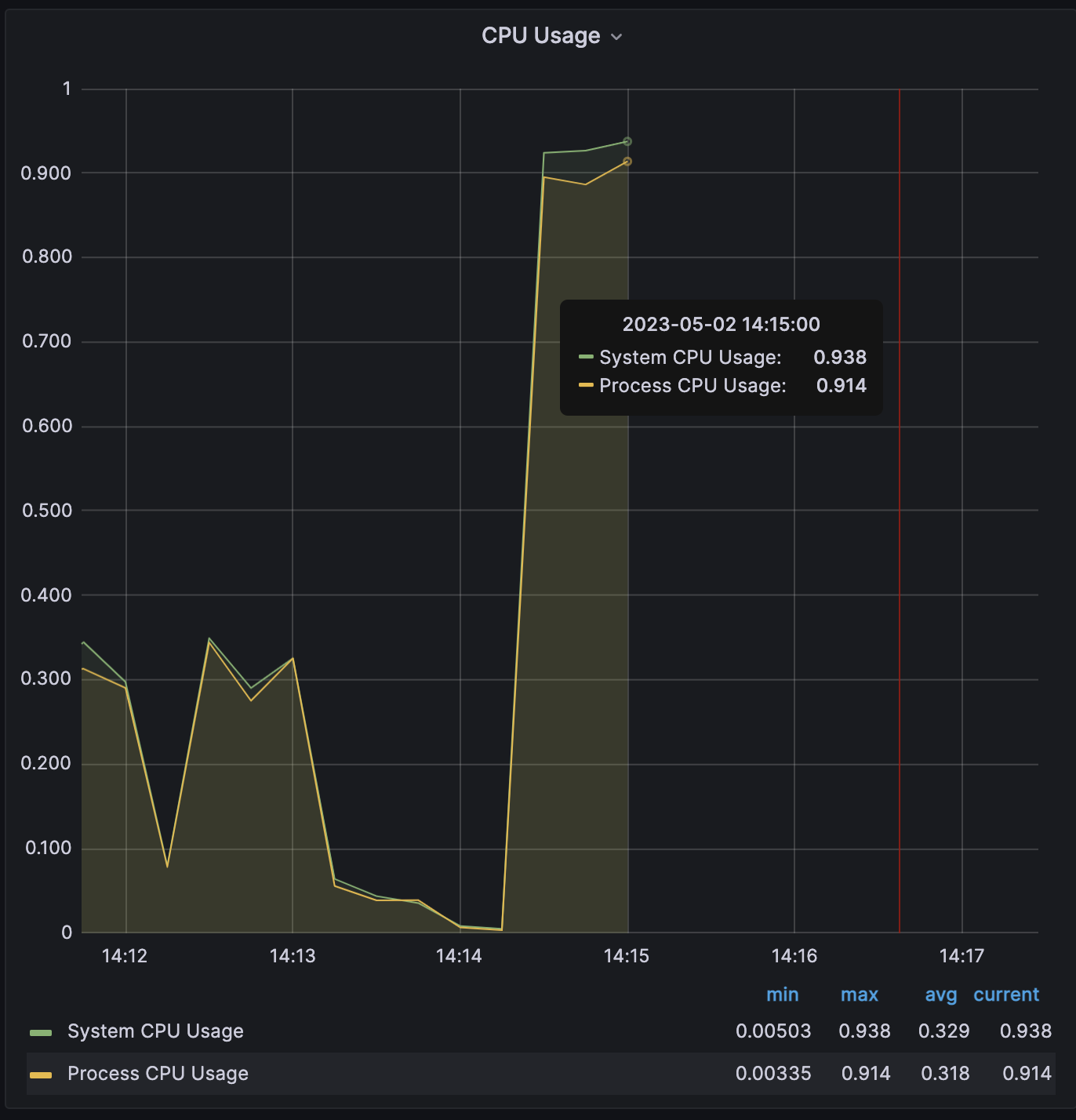
-
Heap
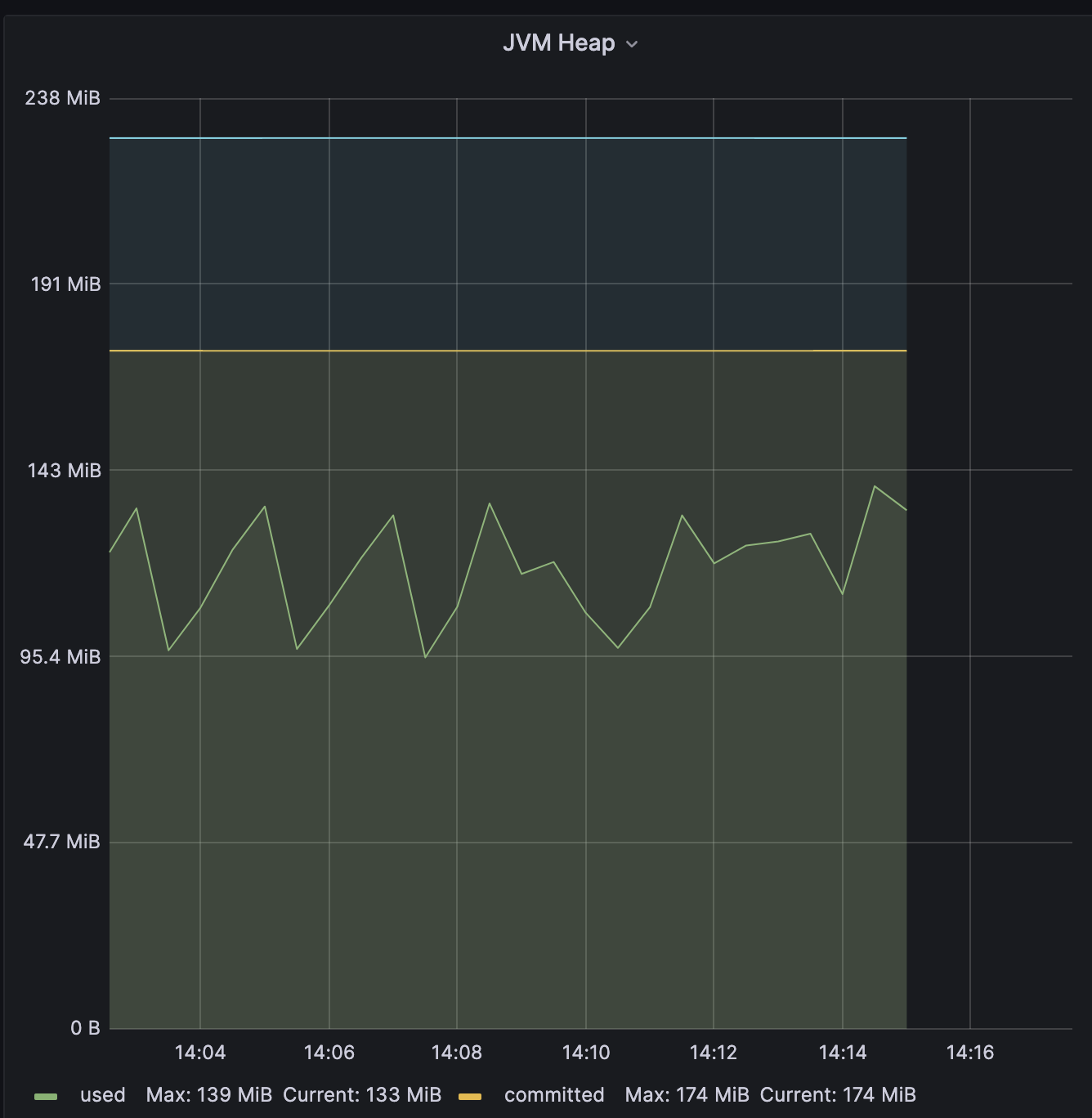
-
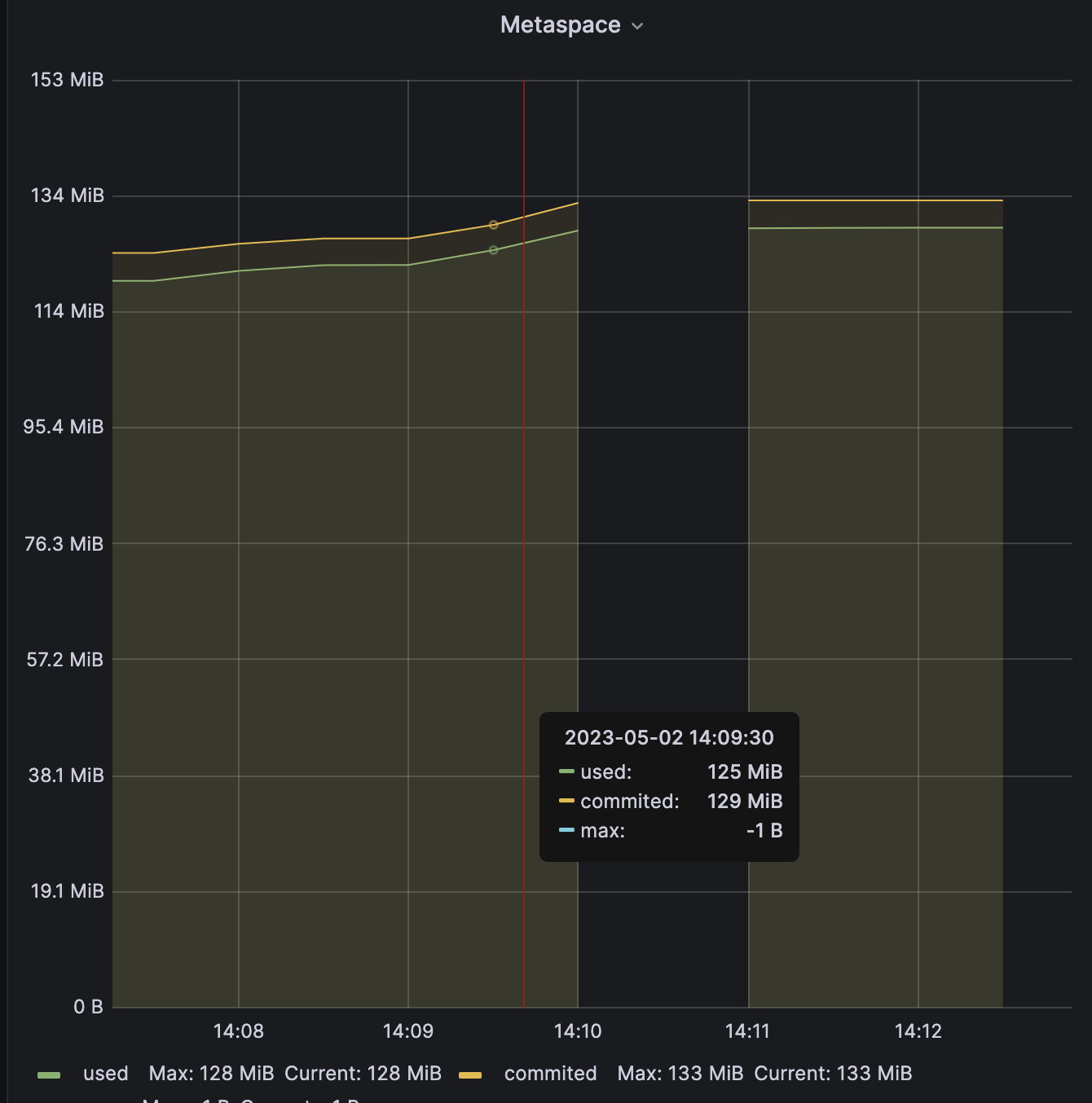
MetaSpace
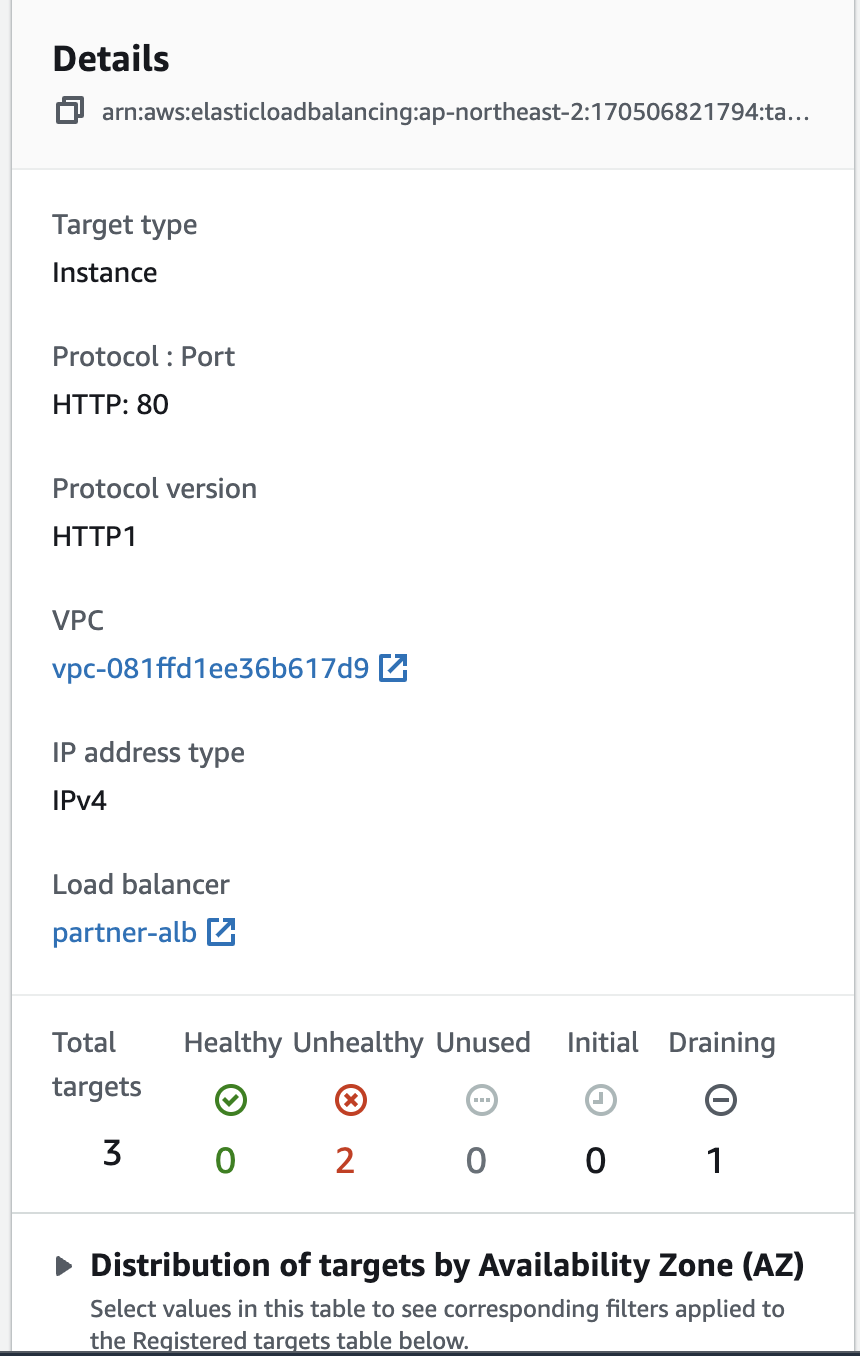
- Health Check
EC2
RDS
-
CPU
-
Read
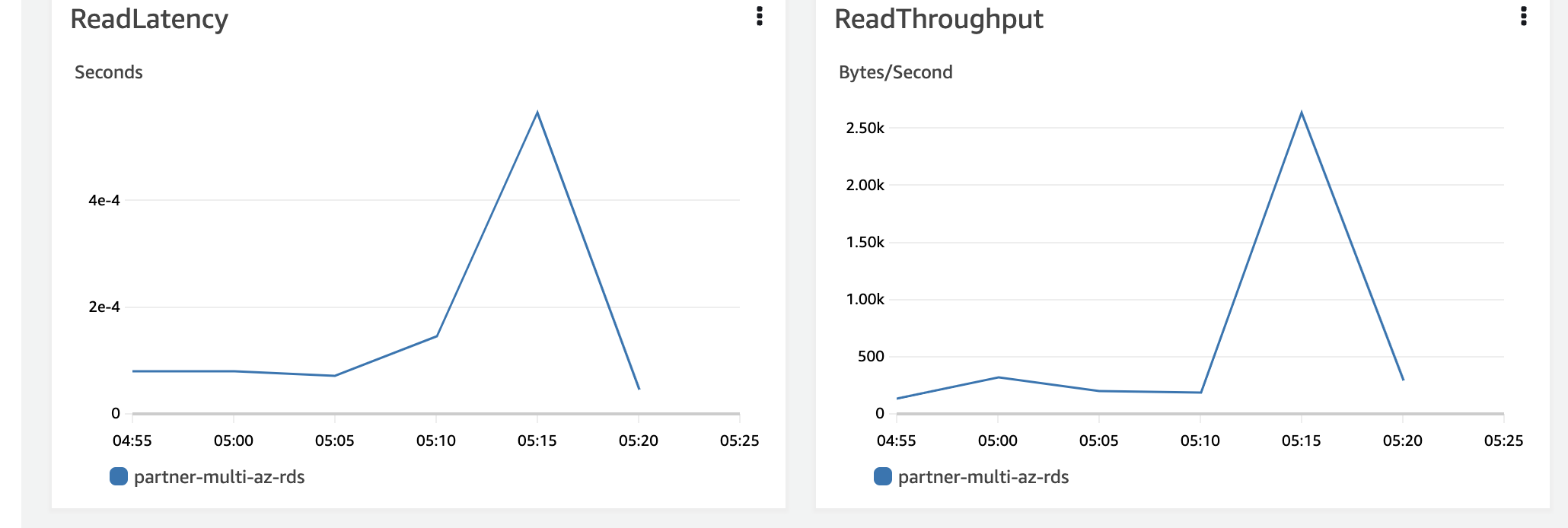
-
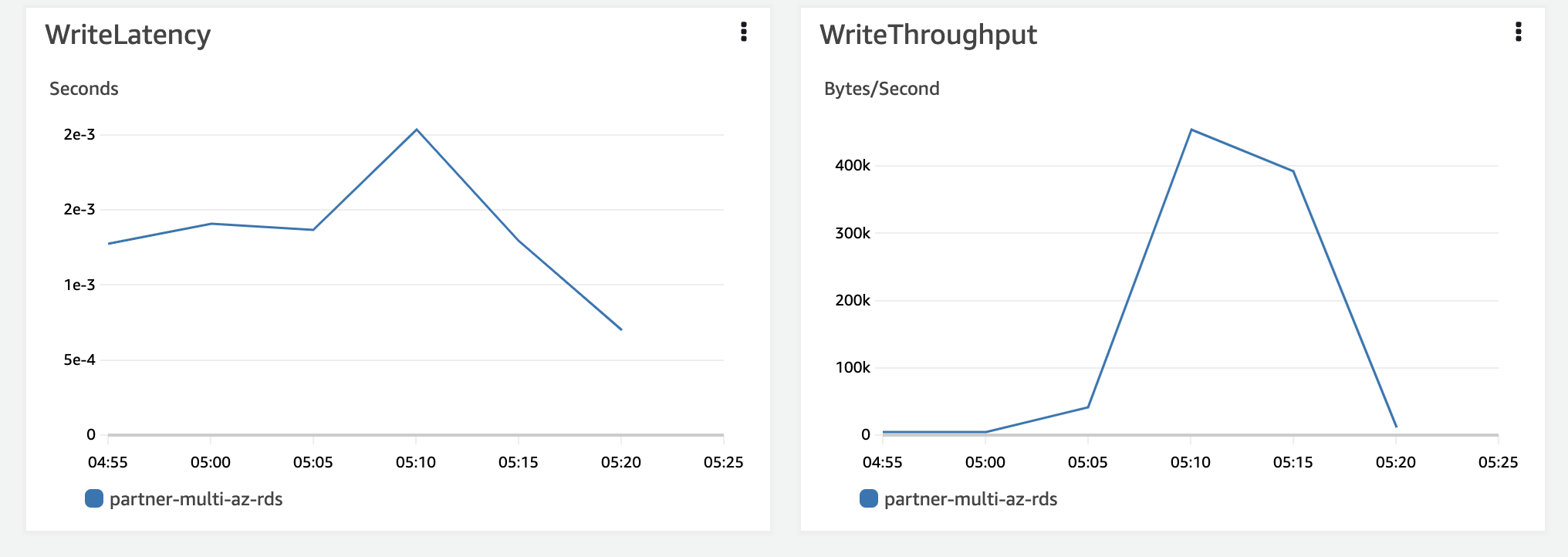
Write
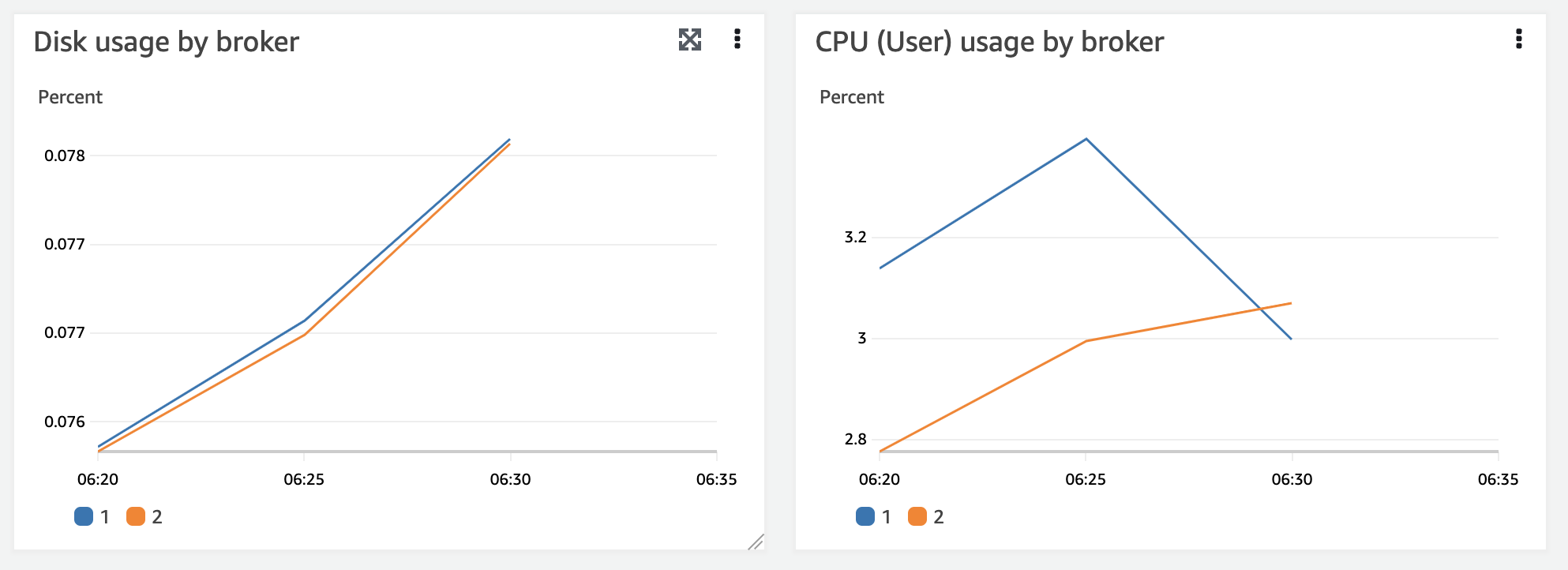
MSK (Kafka)
ElastiCache(Redis)
EC2 종료 직전 WAS 에러 로그
- Out Of Memory에러와 성능 부하로 인한 강제 종류가 가능한 에러는 발견되지 않았다.
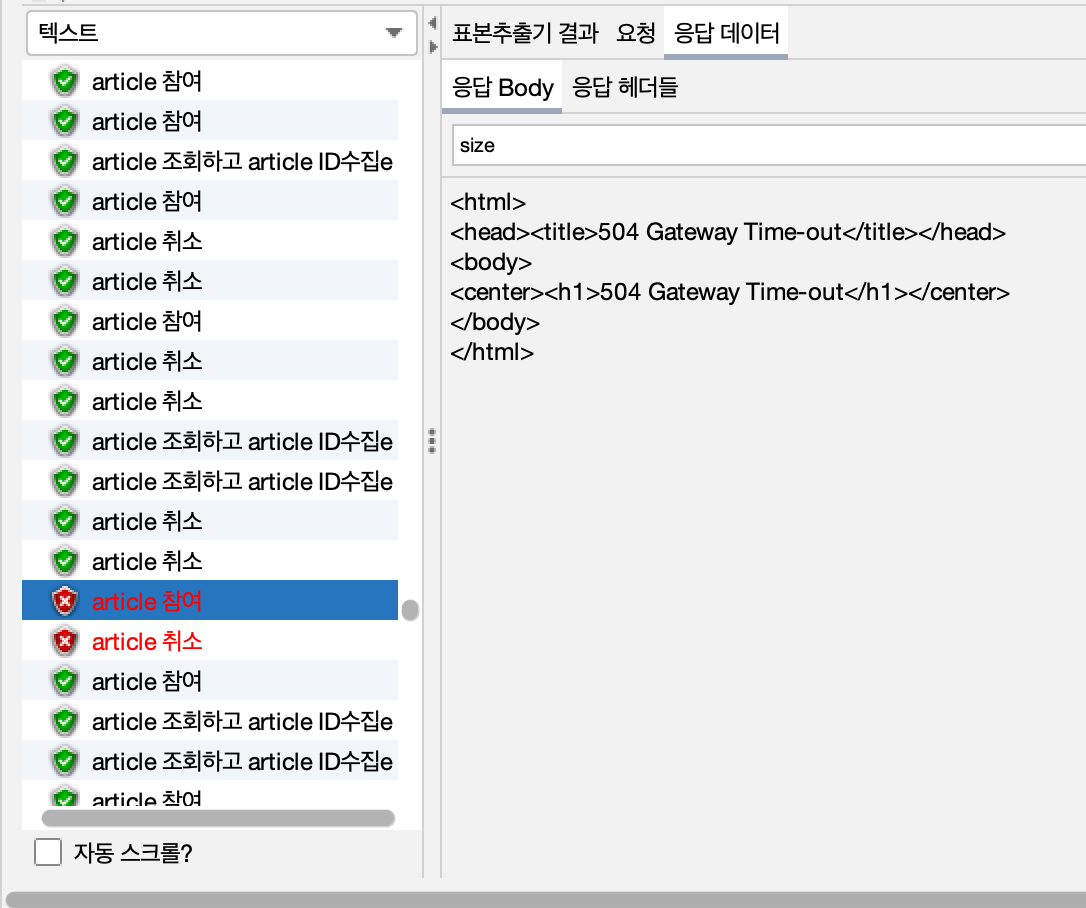
- 해당 로그를 검색해본 결과 JMeter의 응답을 처리할 수 없어 Time out처리되어 서버 측에서 요청을 끊어 버린 내용이다.
- 따라서 WAS종료 이유는 Health Check가 실패하여 ASG에 의해서 종료된 것으로 보는 것이 바람직하다.
org.apache.catalina.connector.ClientAbortException: java.io.IOException: Broken pipe
Caused by: java.io.IOException: Broken pipe3-4. 테스트 결과 분석
50스레드의 유저가 매칭 조회, 참여, 취소를 반복한 결과 100s의 RAMP-UP Time 에 도달하기도 전에 서버 2대가 종료되었습니다.
지표들을 종합해보면 DBCP개수가 부족해 RDS의 성능을 제대로 활용하지 못했고 WAS에서 병목이 발생하여 요청들이 제대로 처리되지 못하게 되었으며 Health Check가 timeout 되어 WAS가 종료된것으로 보입니다.
-
EC2의 CPU 사용량은 27 퍼센트 밖에 되지 않습니다. WAS가 강제 종료된 것에 비해 EC2는 크게 사용되고 있지 않습니다. 현재 api들이 io-bound이기 때문에 cpu 대비 메모리 사용량이 높을 필요가 있고 EC2스펙을 변경해줄 필요가 있어 보입니다. 또한 WAS 실행 시 메모리 관련 옵션을 지정해줄 필요가 있어 보입니다.
-
Thread pool의 max Size, queue Size를 지정하지 않으니 Thread개수가 무한정 늘어나다가 장애 상황을 맞이했습니다. 적정값을 설정해줄 필요가 있습니다. DBCP값 보다 좀더 큰 값으로 수정할 것입니다.
-
DB의 경우 t3.micro의 스펙임에도 오려 Database는 부하에 여유가 있습니다. DBCP개수를 늘려도 부하를 견딜 것으로 보입니다.
-
DBCP의 경우 대기 connection이 150까지 증가하는 것을 볼 수 있다. DBCP의 수를 늘려야합니다.
-
ASG의 Scaling은 느려서 순간적인 부하에는 효과적이지 못한것으로 판단됩니다. 순간적인 부하에 대응해야한다면 ASG설정등을 바꾸거나 미리 대기 WAS를 설정해 두어야 할 것으로 보입니다.
-
heap memory size 등을 보면 WAS자체에 Out Of Memory로 종료될 만한 상황은 아닙니다. WAS의 강제 종료는 load balancer의 health check가 time out 되거나 정상 시간내에 응답이 가지 않는 것이 원인이 되었을 것이다.
3-5. 개선 방향
- Thread pool관련 max size등의 설정을 해야합니다. thread pool이 늘어나도 처리량이 늘어지는 못하므로 thread 생성으로 자원만 낭비됩니다.
- 현재 병목은 DBCP 때문에 발생하고 있습니다. DB의 부하자체는 크지 않은 것으로 보아 RDS의 스펙을 그대로 두더라도 DBCP를 증가시켜야 합니다. 현재 추이로 보면 RDS에 40 Connection까지는 충분할 것으로 보이고 이 이상은 테스트 해봐야합니다.
- 조회의 경우 cache를 활용하여 DB 성능 부하를 줄여야 합니다.
- EC2 낮은 스펙 4대와 높은 스펙 2대중 높은 스펙 2대가 나을 것으로 보입니다. 그 이유는 WAS대기 시 아무 요청을 받지 않더라도 Heap memory의 용량이 너무 크며 cpu성능이 부족해 보이지는 않습니다. 하지만, 테스트 시 조건을 일정하게 유지해야 튜닝을 할 수 있기 때문에 수정하지 않도록 하겠습니다.
