0. 글 작성 배경
분산 시스템에서 Event Queue를 사용할 때 Exactly Once를 만족시켜야 하는 요구사항이 발생했습니다. 이를 나름대로 잘 처리했다고 생각했지만 추가적인 처리가 더 필요하다는 것을 알게 되어 정리하게 되었습니다.
결과적으로 알게 된 내용을 정리하면 kafka자체로 Exactly Once를 만족시킬 수는 있지만, 다른 DataSource들에 대해서도 Exactly Once를 만족 시키는 것은 Kafka의 범위를 넘어서는 것이기 때문에 만족되지 않을 수 있다는 것입니다.
문제 상황
랜던 매칭을 구현하면서 랜덤 매칭 신청 API 호출 시 매칭을 맺어주는 알고리즘을 동작시켜야합니다. 이때 매칭 알고리즘 동작 완료와 무관하게 매칭 신청은 응답을 보낼 수 있어야한다. Kafka를 이용하여 비동기적으로 동작할 수 있도록 하였습니다. 이때 Kafka는 추가적으로 다음 조건들을 만족시키며 동작해야합니다.
- 매칭 알고리즘은 단한번 생성되고 단한번 소비되어야한다.
- 매칭 알고리즘이 실패 시 롤백될 경우 재시도가 보장 되어야 한다. 반대로 성공 시 commit이 완벽하게 되어야한다.
- Event에 따라 매칭 알고리즘 실행 순서가 보장 되어야 한다.
기본 설정만을 한 후 Kafka Producer, Consumer를 활용하는 경우 위의 3가지 조건이 지켜지지 않습니다. Producer, Consumer설정 시 Exactly Once를 위해 주의해야할 점에 대해서 알아보겠습니다.
1. Kafka Producer
Kafka에서 이벤트를 생성할때 성능을 위해서 여러개를 한번에 생성하며 retry시 중복 생성, 순서가 바뀔 수 있습니다. 아래있는 설정들을 적절히 해야 produce배치 성능을 향상 시키고 idempotence를 만족시킬 수 있습니다.
1-1. Partitioner
RR방식보다 Sticky Partitioner가 성능상 나은 이유
Partitioner란 이벤트를 Produce할 때 어떤 파티션에 어떻게 전송할지 선택하는 전략입니다. 관련 설정은 다음 3가지 입니다.
| Configuration | Default | Description |
|---|---|---|
| partitioner.class | org.apache.kafka.clients.producer.internals.DefaultPartitioner | Partitioner 에 대한 전략을 선택 |
| batch.size | 16384 | Producer 가 데이터를 전송할 수 있는 최대 데이터 크기. 참고로 batch size 만큼 무조건적으로 전송하는게 아닌 최대 임계값 |
| linger.ms | 0 | Producer 가 데이터를 전송하는데 대기하는 시간. 대기하는 시간만큼 batch size 만큼 데이터의 용량을 쌓아둘 수 있음 |
- partitioner.class :Partitioner 에 대한 전략을 선택
-
DefaultPartitioner: key 가 존재하면 hash 값을 기반으로 선택, key 가 존재하지 않으면 UniformStickyPartitioner 전략으로 구현되어 있음
-
RoundRobinPartitioner: Partition의 순서대로 하나씩 할당한다(배치 성능 저하가 있을 수 있음.)
-
UniformStickyPartitioner: batch.size 가 꽉차거나 linger.ms 값이 초과되었을 때 쌓아둔 데이터를 하나의 Partition 에게 모두 전송한다
linger.ms를 적절히 설정하는 것이 produce 배치 성능에 크게 영향을 미칩니다.
1-2. Retry
delivery.timeout.ms 까지 retry를 수행함.
| Configuration | Default | Description |
|---|---|---|
| retries | 2147483647 | 오류로 인해 실패한 record 전송 이력에 대해 재시도하는 횟수. 단 무한정으로 재시도하는게 아니라 delivery.timeout.ms 내에서만 재시도. 따라서 client 는 retries 설정값으로 튜닝하는게 아닌 timeout 값으로 튜닝할 것을 권고 |
| delivery.timeout.ms | 120000ms = 2min | Producer 의 send 호출이 성공 또는 실패로 보고하는 최대 시간의 임계값delivery.timeout.ms >= linger.ms + request.timeout.ms 를 준수할 것 |
| linger.ms | 0 | Producer 가 데이터를 전송하는데 대기하는 시간. 대기하는 시간만큼 batch size 만큼 데이터의 용량을 쌓아둘 수 있음 |
| request.timeout.ms | 30000 = 30second | Producer client 가 요청응답을 기다리는 최대시간 |
1-3. Idempotence(Retry로 인한 중복 방지)
| Configuration | Default | Description |
|---|---|---|
| enable.idempotence | false | event 단일 생성을 보장해줌. 이를 위해서는 enable.idempotence true를 위해서는 retry가 1이상, max.in.flight.requests.per.connection 은 5이하여야합니다. |
| max.in.flight.requests.per.connection | 앞전에 실행된 네트워크 요청(batch로 저장된 이벤트를 produce하는 요청)이 응답을 받지 못하더라도 동시에 네트워크 요청을 할 수 있는 개수를 말합니다. 2이상인 경우 순서보장이 되지 않을 수 있습니다. |
Kafka가 Idemportence 설정 Event 하나만 생성 보장하는 방법
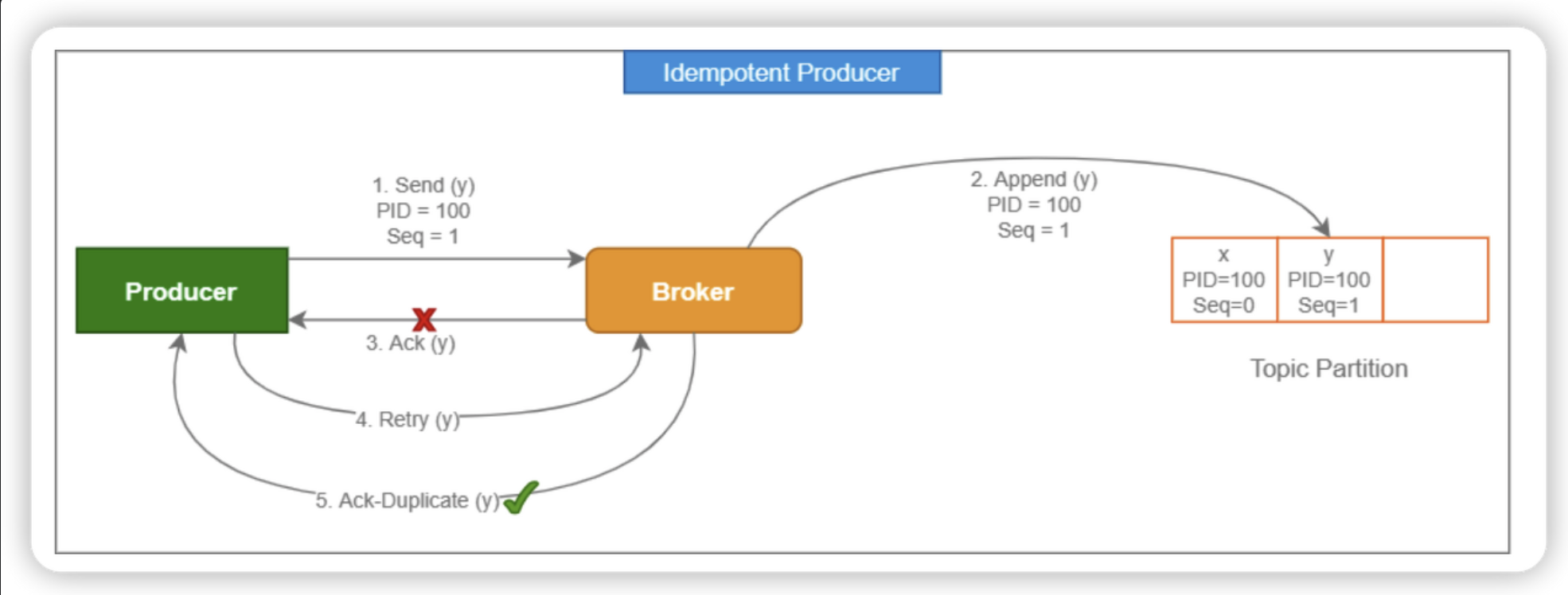
바로 PID 라는 ProducerId 를 통해서 어떤 Producer 가 어떤 record 를 기록하게 되는지 체크하게 됩니다.
Producer 가 PID 를 지정하여 보내게 되면 처리하는 Broker 에서 PID 값을 기반으로 Record 에 대한 쓰기 작업을 단 한번만 하도록 중복 체크할 수 있게 되는 것입니다.
1-4. Acks, min.insync-replicas
| Configuration | Default | Description |
|---|---|---|
| min.insync.replicas | 1 | acks:all시 최소로 보장되어야하는 produce수 2이상으로 하여야 의미가 있음. |
| acks | 0: ack 수신 여부 상관하지 않음, 1: leader에만 보장, all: min.insync.replicas에 보장 |
2. Kafka Exactly Once
https://www.confluent.io/blog/exactly-once-semantics-are-possible-heres-how-apache-kafka-does-it/
https://medium.com/@andy.bryant/processing-guarantees-in-kafka-12dd2e30be0e
produce, consume으로 나누어서 exactly once방법을 알아보겠습니다.
2-1. Exactly Once produce
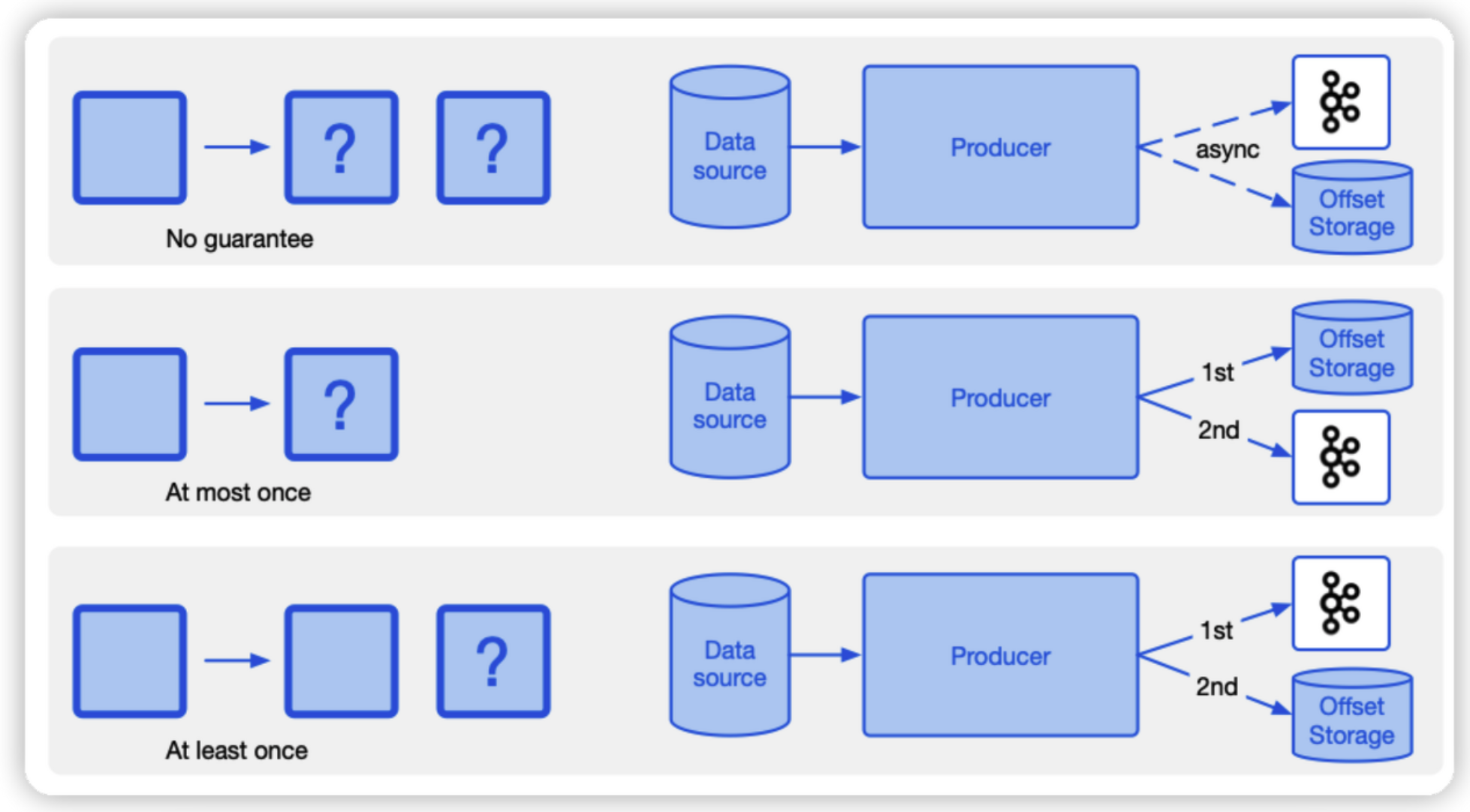
| 전략 | 방법 |
|---|---|
| At most once | Producer 가 재시도 전략을 허용하지 아니하되, 정확하게 한번 전달하는 것을 보장하게 합니다. 아직까지 저는 해당 전략으로 kafka 를 운영해본적은 없어서 모르겠습니다. |
| At least once | Producer 의 설정을 acks = all 로 설정합니다. acks = all 설정은 Leader 가 Follower 들에게 토픽을 잘 전송하였는지 체크하는 option 입니다. |
| Exactly once | Producer 의 설정을 acks = all 로 설정합니다. enable.idempotence = true 로 설정합니다. idempotence 설정은 Broker 에게 ProducerID(PID) 를 전송하여 중복체크를 할 수 있게 전송하게 됩니다. |
2-1-2. Transactions: Atomic writes across multiple partitions
Kafka 에서는 Transaction의 개념을 도입하여 여러 Parition에 produce시 Exactly Once를 보장해줍니다. 프로듀스를 하고 commit까지 완료되는 것을 하나의 트랜잭션으로 보고 원자적으로 실행할 수 있습니다.
- Producer는 Idempotence를 만족하고 Transaction.id를 지정해주어야합니다.이때 transaction.id는 유일성이 보장되어야합니다.
Properties producerProps = new Properties();
producerProps.put("bootstrap.servers", "localhost:9092");
Copy
Additionally, though, we need to specify a transactional.id and enable idempotence:
producerProps.put("enable.idempotence", "true");
producerProps.put("transactional.id", "prod-1");
KafkaProducer<String, String> producer = new KafkaProducer(producerProps);- consumer의 경우 isolation.level을 read_committed로 설정해줍니다. enable.auto.commit.을 false로 해야합니다.
read_committed: 트랜잭션에 속해있던 혹은 속해 있지 않던 commit된 event에 대해서만 읽을 수 있습니다.
read_uncommitted: commit되지 않은 이벤트도 읽을 수 있습니다.
Properties consumerProps = new Properties();
consumerProps.put("bootstrap.servers", "localhost:9092");
consumerProps.put("group.id", "my-group-id");
consumerProps.put("enable.auto.commit", "false");
consumerProps.put("isolation.level", "read_committed");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(consumerProps);
consumer.subscribe(singleton(“sentences”));producer.initTransactions();
try {
producer.beginTransaction();
producer.send(record1);
producer.send(record2);
producer.commitTransaction();
} catch(ProducerFencedException e) {
producer.close();
} catch(KafkaException e) {
producer.abortTransaction();
}2-2. Exactly Once Consume
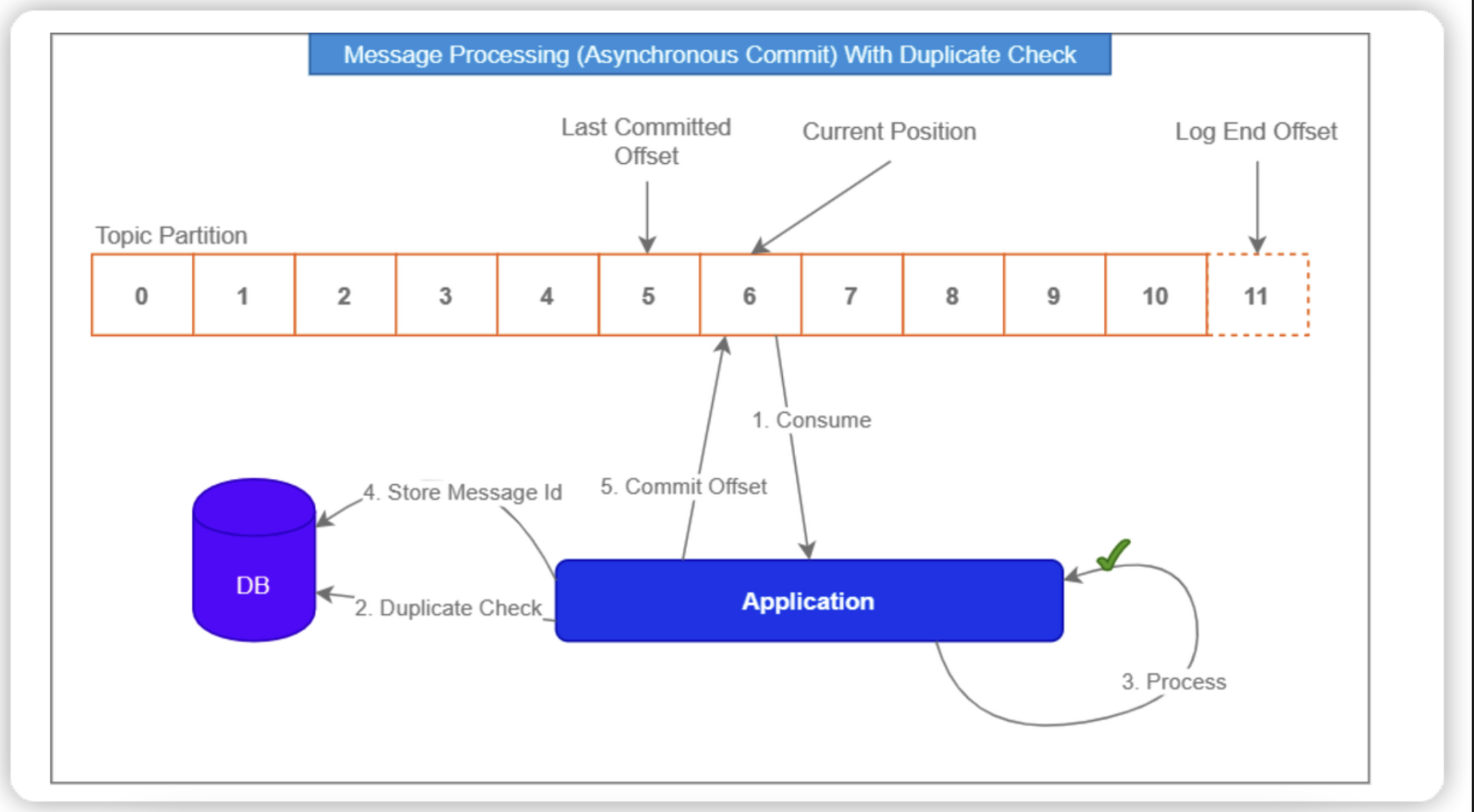
일반적으로 application 구현시 consumer는 다음과 같이 구현합니다. 이때 At Least Once 를 따르게 됩니다.
1. Consumer 가 마지막으로 기억하는 Offset 으로 부터 메세지를 읽습니다.
2. Application 에게 읽은 메세지를 전송하여 Processing 합니다.
3. Processing 이 완료되면 메세지를 Offset 에 commit 합니다
2-2-1. enable.auto.commit
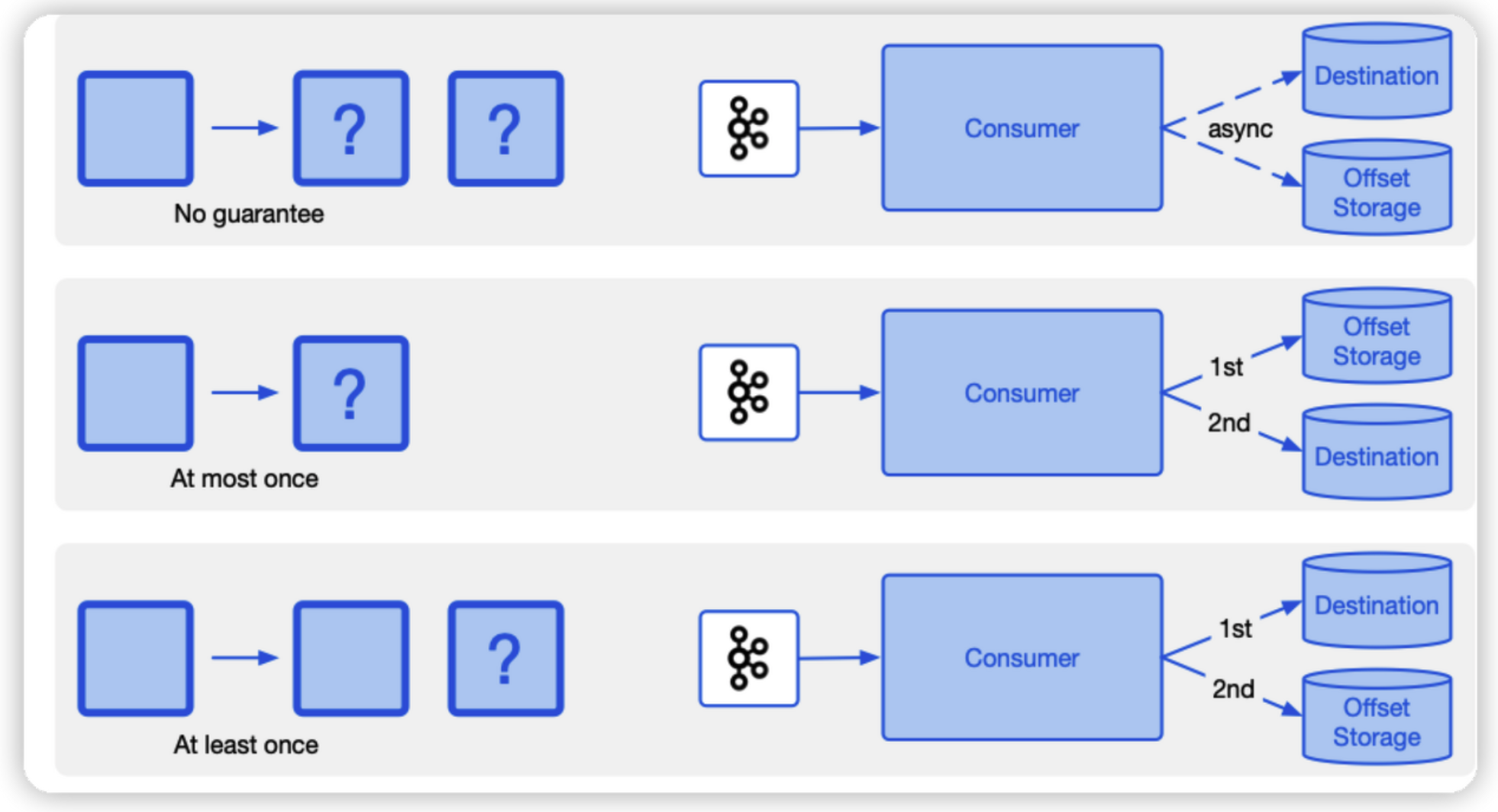
enable.auto.commit을 true로 할 경우 일정 주기(auto.commit.interval.ms, default 5초)마다 poll 한 record 의 offset 을 commit 하기 때문에 At Most Once가 됩니다.
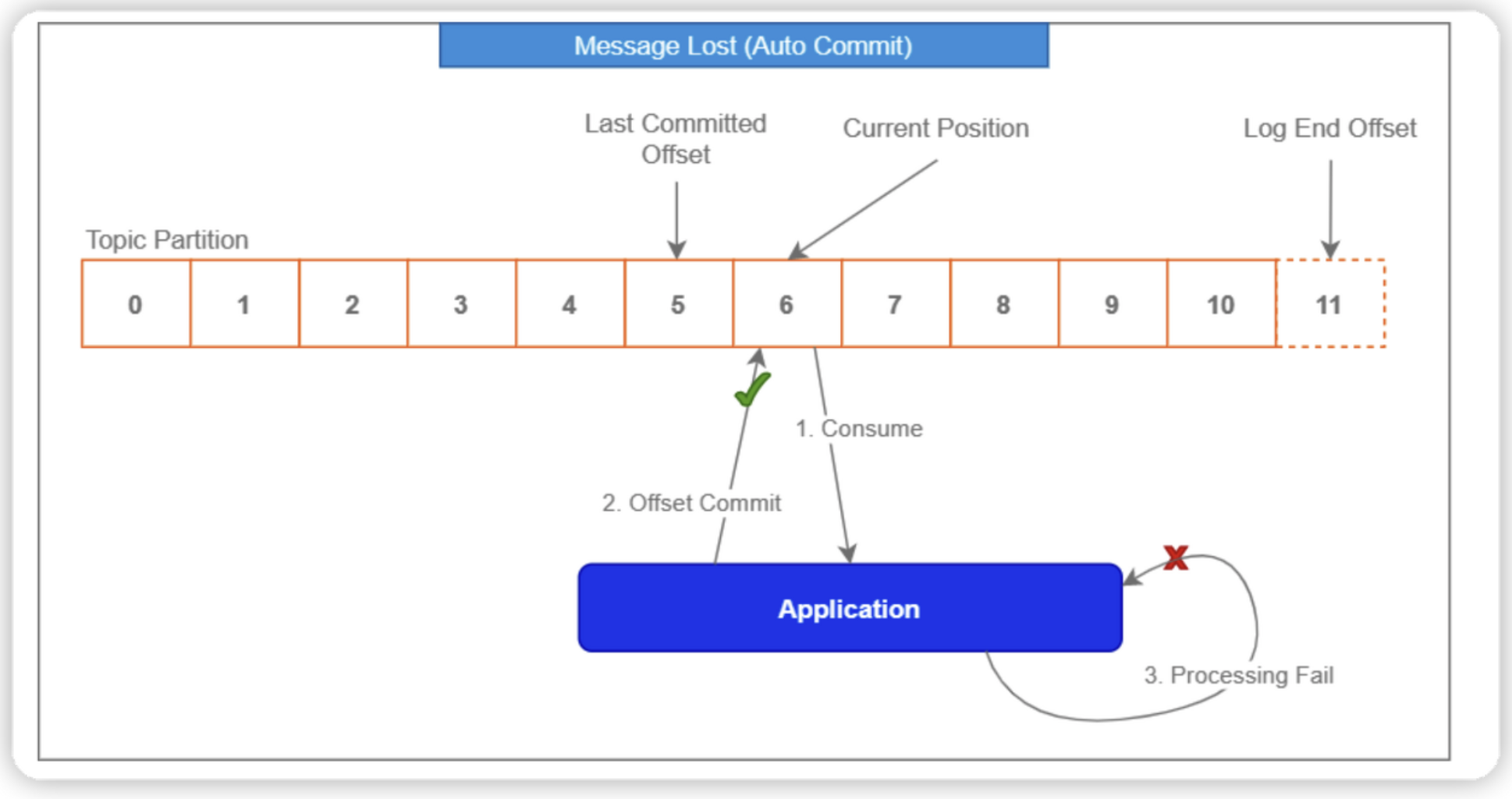
반대로 enable.auto.commit을 false로 할 경우 메시지 중복 처리가능성 때문에(event consume은 하였지만 commit하기 이전에 장애가 발생하는 경우) At Least Once입니다.
2-2-2. Kafka만 생각했을 때 Exactly Once는 가능하지만, 전체 시스템에서 Exactly Once는 매우 만족하기 힘들다.
-> DB 트랜잭션 시작
Entity 저장
-> DB 트랜잭션 종료
(여기에서 장애 발생)
Consumer ack- 다음과 같은 consumer 코드 시나리오에서 Entity는 저장되지만 장애로 인해 ack가 보내지지 않습니다. 이 경우 Kafka자체의 Exactly Once Consume은 잘 이루어진 것이라고 볼 수 있지만, Entity를 저장하는 처리는 다시 수행될 것이며 중복 저장되기 때문에 시스템 전체에서 Exactly Once를 만족했다고 볼 수 없습니다. 즉, Kafka는 ExactlyOnce를 만족하더라도 전체 시스템에서는 만족하지 못할 수 있습니다.
따라서 kafka의 다음과 같은 어플리케이션 로직을 구현하여 해당 Entity를 저장하는 이벤트가 수행되었는지 검증하는 로직을 추가해야합니다.
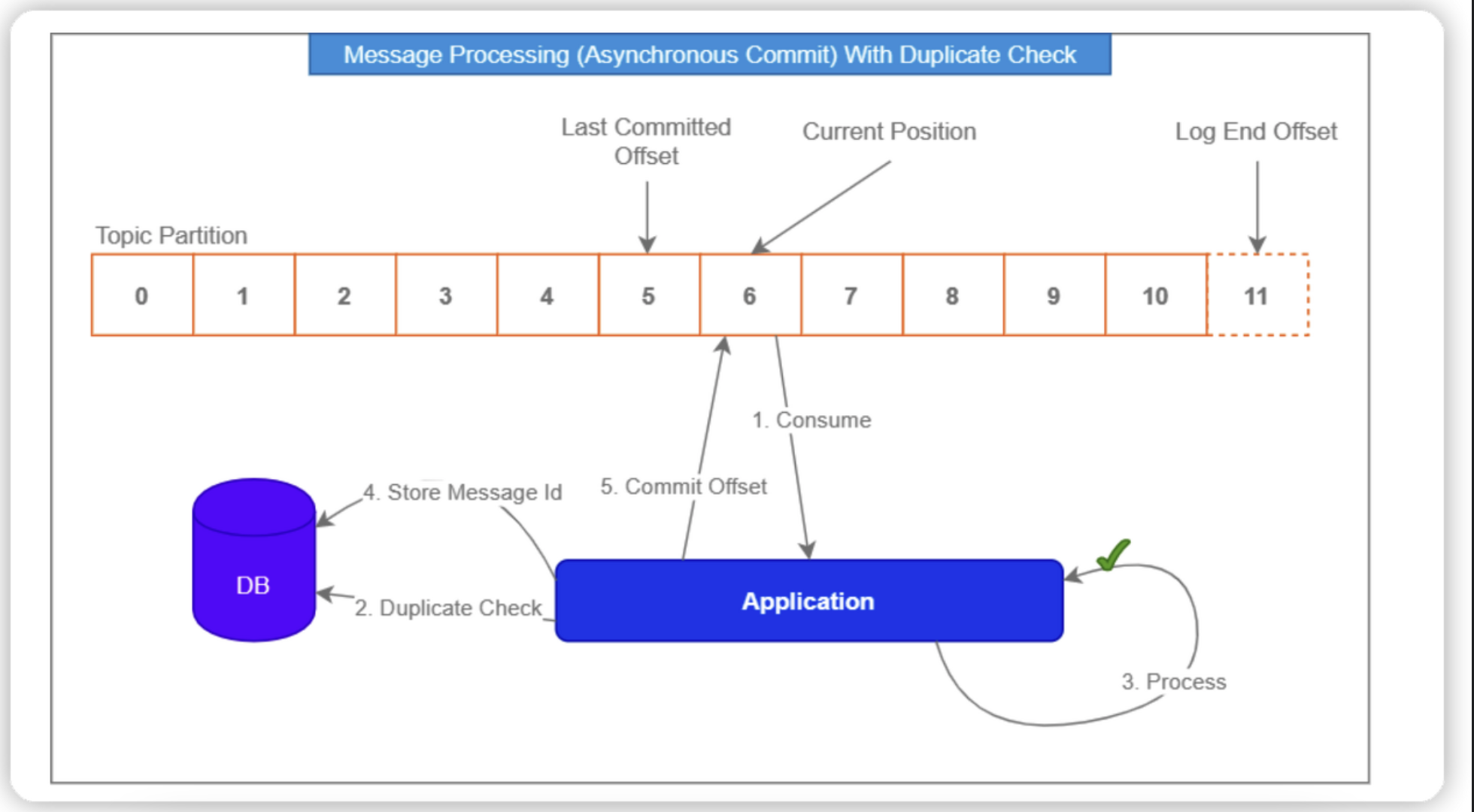
- 만약 Redis를 사용한다면 Exactly Once는 더 어렵습니다. Rollback이 완벽하게 되지 않기 때문입니다.
3. Kafka Streams
- Kafka Streams의 경우 다음 옵션을 지정하면 Exactly Once를 쉽게 이룰 수 있습니다.
processing.guarantee=exactly_once
Kafka streams 에서 어떻게 exactly once 를 지원하는지는 아래링크를 참고하시기 바랍니다.
https://www.confluent.io/blog/enabling-exactly-once-kafka-streams/
4. 정리
Exactly Once Kafka
1. enable.idempotence 통해 produce를 한번만 보장할 수 있다.
2. Consume의 경우에는 Manual commit을 사용해야한다. isolation_level=read_commited
3. transaction을 통해 consume을 하면서 produce를 automic하게 이룰 수 있다.
4. Kafka Streams를 이용하면 쉽게 Exactly Once가 가능하다.
5. 1, 2, 3을 통해 Kafka 내부적으로는 Exactly Once가 가능하지만 다른 Component들과 함께 시스템적으로 Exactly Once를 이루기 위해서는 별도의 처리가 필요하며 성능 저하 트레이드 오프를 고려해야한다.

글 감사합니다. 도움이 많이 되었습니다.
2-2-2 에서 질문이있는데요.
-> DB 트랜잭션 시작
Entity 저장
-> DB 트랜잭션 종료
(여기에서 장애 발생)
Consumer ack
이렇게하지않고 DB 트랜잭션에 Consumer ack 을 묶는다면 exactly once 가 되지않나요?
-> DB 트랜잭션 시작
Entity 저장
Consumer ack
-> DB 트랜잭션 종료