Going deeper with convolutions(Inception-v1) - 2014
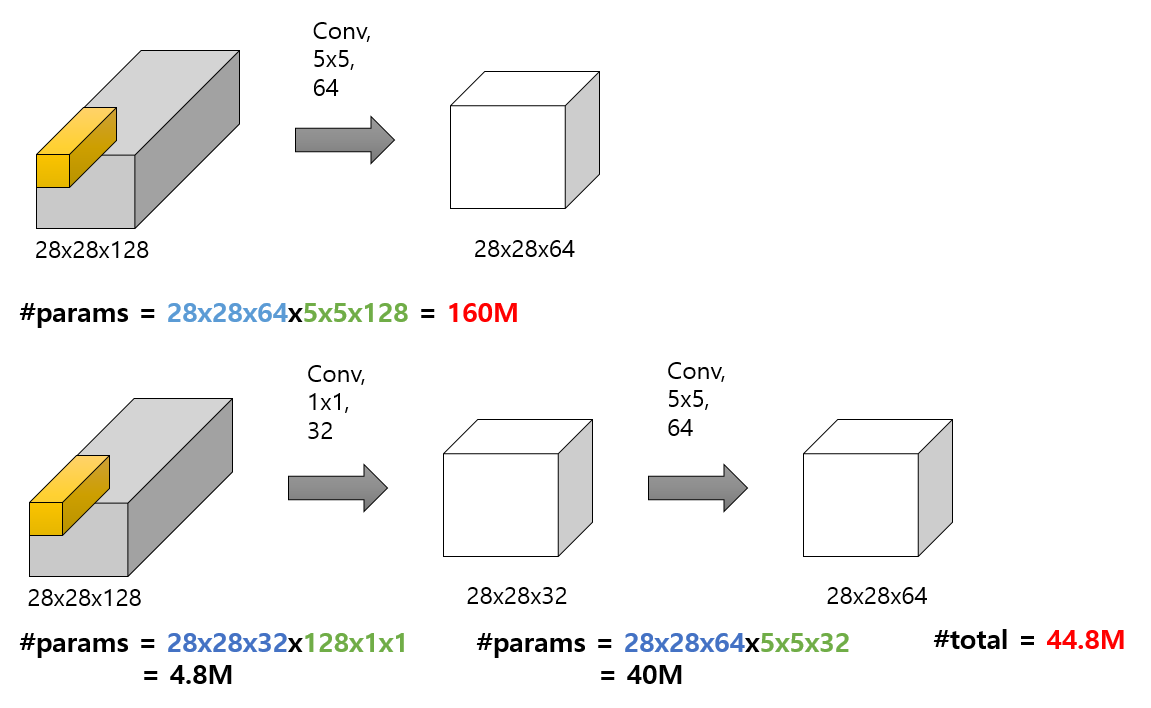
1x1 Convolution
- 장점
- 계산량을 줄일 수 있다.
- 차원 축소가 가능하다.
- 차원 축소로 인해 우리는 보다 핵심적인 데이터만 뽑아낼 수 있게 됨
- 비선형성의 증가
- 더욱 복잡한 패턴을 인식하는 데 더 좋은 효과
- overfitting 방지 가능
- 파라미터 계산량이 작기 때문에, overfitting을 방지
Abstract
- architecture 의 주요 특징은 network 내부의 computing resources의 활용도 향상
- crafted design에 의해 계산 비용을 유지하면서, network 의 depth and width 을 늘림
- architectural decisions 은 Hebbian 와 multi-scale processing의 직관성에 기반
1. Introduction
- 본 논문에서 우리는 컴퓨터 비전을 위한 효율적인 심층 신경망 아키텍처에 초점을 맞출 것
- deep의 의미
- “Inception module” 의 형태로 새로운 수준의 조직을 도입
- 네트워크 깊이를 증가시킨다는 보다 직접적인 의미
2. Related Work
- LeNet-5 를 시작으로, convolutional neural networks (CNN) 은 일반적으로 표준구조를 가지고 있음
- stacked convolutional layers (선택적으로 대비 normalization and max-pooling)에 하나 이상의 fully-connected layers가 따라오는 구조
- ImageNet 과 같은 대용량 데이터에서 최근 trend는 drouput로 overfitting문제를 해결하면서 레이어 수 와 레이어 사이즈를 늘이는 것
- Inception layers은 여러 번 반복되어 GoogLeNet 모델의 경우 22-layer deep model로 이어짐
- 모델에서 network에 1 × 1 convolutional 을 추가되어 그 깊이가 증가
- 1 × 1 convolutions 두가지 목적
- 장 중요한 것은 그것들은 주로 계산 병목 현상을 제거하기 위한 차원 축소 모듈로 사용
- 네트워크의 크기를 제한할 수 있다는 것
- 1 × 1 convolutions 두가지 목적
- 이를 통해 성능을 크게 저하시키지 않으면서 , 네트워크의 depth뿐만 아리라 width도 증가가능
3. Motivation and High Level Considerations
- deep neural networks 의 성능을 향상시키는 가장 간단한 방법은 size를 늘리는 것
- depth의 증가 - the number of network levers (layer)
- width의 증가 - the number of units at each level
- 두가지 단점
- size가 클 수록 parameters의 수가 많아져 확장된 network가 over-fitting되기 쉬움
- 네트워크의 크기를 늘리는 것은 컴퓨터 자원의 사용이 크게 증가 -> 컴퓨터 계산 능력이 크게 요구
- 두 가지 문제를 해결하는 근본적인 방법은 sparsity 을 도입하고 , fully connected layers 를 convolutions내부에서도 layers by the sparse로 대체
- spare connected : 다 연결되는 것이 아님
- fully connected : 다 연결
4. Architectural Details
- Inception architecture의 구성 요소는 1×1, 3×3 and 5×5로 제한
- 계산량이 많은 3x3이나 5x5 convolution 이전에는 reduction을 위한 1x1 convolution이 사용
- Inception network는 위 유형의 모듈들이 서로 겹쳐져 있는 네트워크이며, grid의 해상도를 절반으로 줄이기 위해 stride 2가 있는 max-pooling layers 를 사용
- Inception 구조는 계산 자원을 효율적으로 사용하므로, 성능은 약간 떨어지더라도 저렴한 계산 비용으로 깊고 넓은 네트워크를 구축할 수 있다
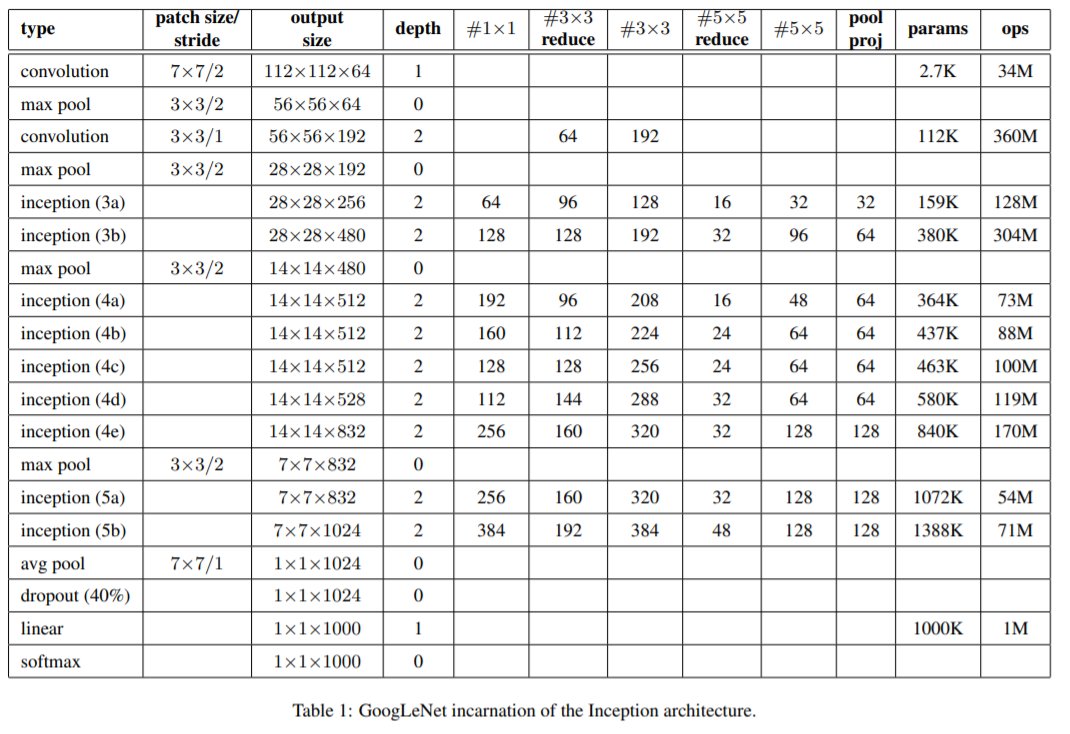
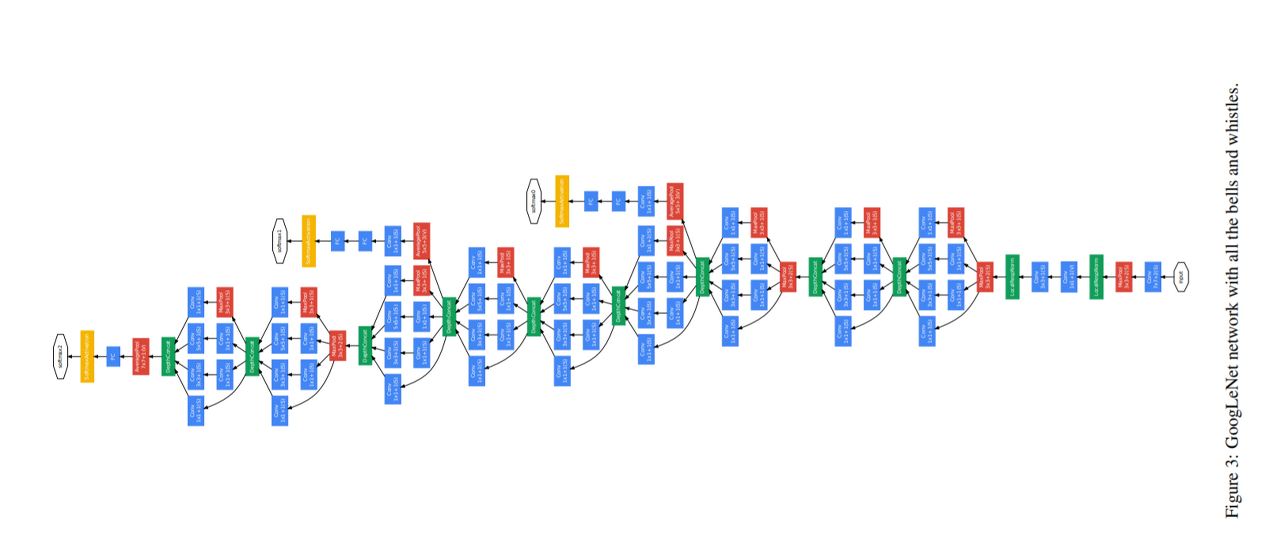
5. GoogLeNet
- Inception modules 내부를 포함한 모든 convolutions은 rectified linear activation를 사용
- receptive field의 크기는 the RGB color space with zero mean에서 224×224
- 이 네트워크는 parameters 가 있는 layer만 셀 때 22 layers deep
pooling까지 계산하면 27 layers - 네트워크 구축에 사용되는 전체 계층(independent building blocks) 수는 약 100개
- fully connected layers에서 average pooling 사용하면 top-1 정확도를 0.6% 정도 증가했으나 dropout의 중요성은 fully connected layers층이 없음에도 중요한 역할을 보임
- auxiliary classifier를 포함한 extra network on the side의 정확한 구조
- filter size 5×5 와 stride 3 인 average pooling layer 출력의 shape은 4×4×512 output for the (4a), and 4×4×528 for the (4d) stage
- dimension reduction을 위한 1×1 convolution with 128 filters및 rectified linear activation
- fully connected layer 1024 units 및 rectified linear activation
- 70% ratio dropout layer
- linear layer 를 사용한 softmax loss as the classifier 1000(predicting the same 1000 classes as the main classifier, but removed at inference time)
6. Training Methodology
- 구글에서 개발 된 대규모 분산 학습 프레임워크로, 적당한 양의 모델과 데이터 병렬성을 이용하여 학습
- 모바일이나 임베디드 시스템 상에서도 inference가 가능하도록 설계하는게 목적이었기 때문으로 생각
- Competition 이후에는, 종횡비를 [3/4, 4/3]로 제한하여 8% ~ 100%의 크기에서 균등 분포로 patch sampling 하는 것이 매우 잘 작동한다는 것을 발견
7. ILSVRC 2014 Classification Challenge Setup and Results
- top-1 accuracy rate는 ground truth를 highest score class와 비교하여 측정
- top-5 error rate는 ground truth을 predicted score 상에서의 최상위 5개 class와 비교하여 측정
- AlexNet보다 더 적극적인 cropping 방식을 적용
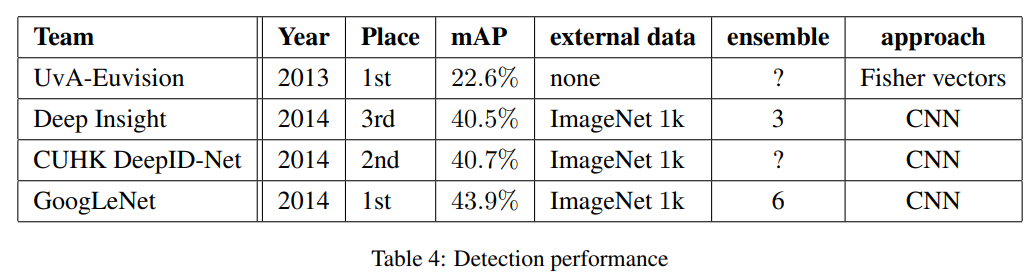
8. ILSVRC 2014 Detection Challenge Setup and
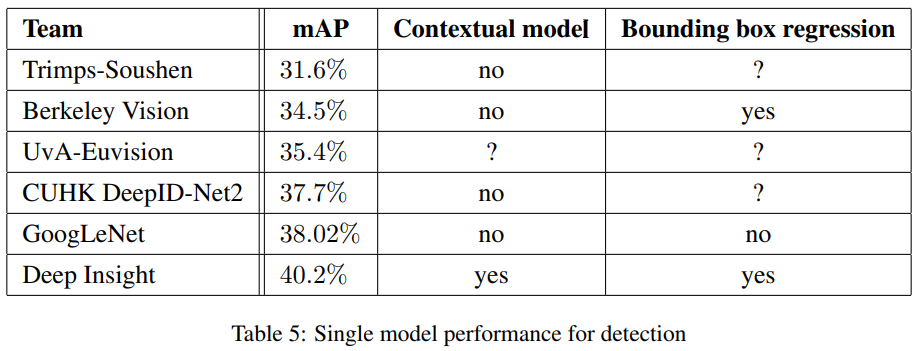
9. Conclusions
- Object detection에서는 context의 활용 / bounding box regression을 수행하지 않아도 경쟁력 있는 성능을 보였으며, 이는 inception architecture의 강점에 대한 또 다른 증거가 된다. 또한, classification과 detection의 결과들은, 유사한 크기의 훨씬 비싼 non-Inception-type 네트워크와 성능이 비슷할 것으로 예상
참조자료
- https://euneestella.github.io/research/2021-10-14-why-we-use-1x1-convolution-at-deep-learning/
- https://kkkkhd.tistory.com/10
- https://leedakyeong.tistory.com/entry/%EB%85%BC%EB%AC%B8-GoogleNet-Inception-%EB%A6%AC%EB%B7%B0-Going-deeper-with-convolutions-1
- https://sike6054.github.io/blog/paper/second-post/
- http://datacrew.tech/inception-v1-2014/
- https://norman3.github.io/papers/docs/google_inception.html
- https://hwiyong.tistory.com/45

일단 저지르자! 그리고 해결하자!