라이브러리 설치
import matplotlib.pyplot as plt import pandas as pd import numpy as np
데이터를 불러오자
data=pd.read_excel('data.xlsx') data
[결과]
성별 나이 연봉 지역 구매제품
0 m 21 3300 서울 핸드폰케이스
1 f 22 5000 경기 마스크
2 f 25 5200 경기 마스크
3 f 32 2000 서울 핸드폰케이스
4 m 27 1800 부산 마스크
... ... ... ... ... ...
194 m 28 3400 경기 노트북
195 f 28 2800 서울 화장품
196 m 27 3500 경기 화장품
197 f 23 1900 경기 노트북
198 m 29 2800 서울 핸드폰케이스
199 rows × 5 columns그래프 패키치 설치
pip install plotly import plotly.express as px
데이터 요약
ex) 성별에서 m이랑 f가 몇개인지 세줘
#성별이 0번째 부터 시작 (python은 항상 0부터 시작) #만약 지역에 관한걸 보고싶으면? .3 으로 하면 된다 data.iloc[:,0].value_counts()
[결과]
m 101
f 98
Name: 성별, dtype: int64분포를 직관적으로 보자
1) 성별에 대한 막대그래프로 파악
#px.bar(x=(),y=()) px.bar(x=data.iloc[:,0].value_counts().index, y=data.iloc[:,0].value_counts().values)
[결과]
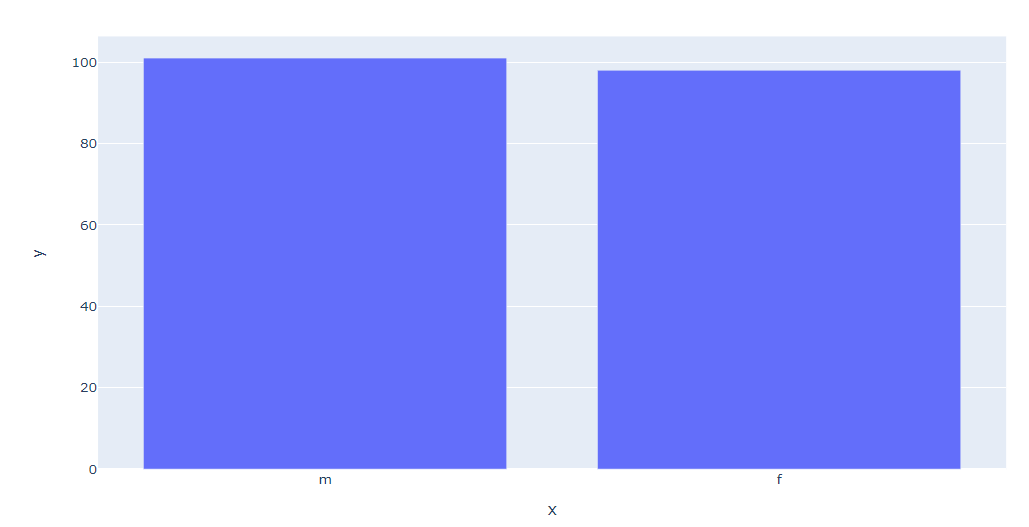
- 쇼핑몰 데이터인데 남여 비율이 같네?
- 여성한테 인기가 없는 쇼핑몰인가?
2) 지역에 대한 막대그래프로 파악
px.bar(x=data.iloc[:,3].value_counts().index, y=data.iloc[:,3].value_counts().values)
[결과]
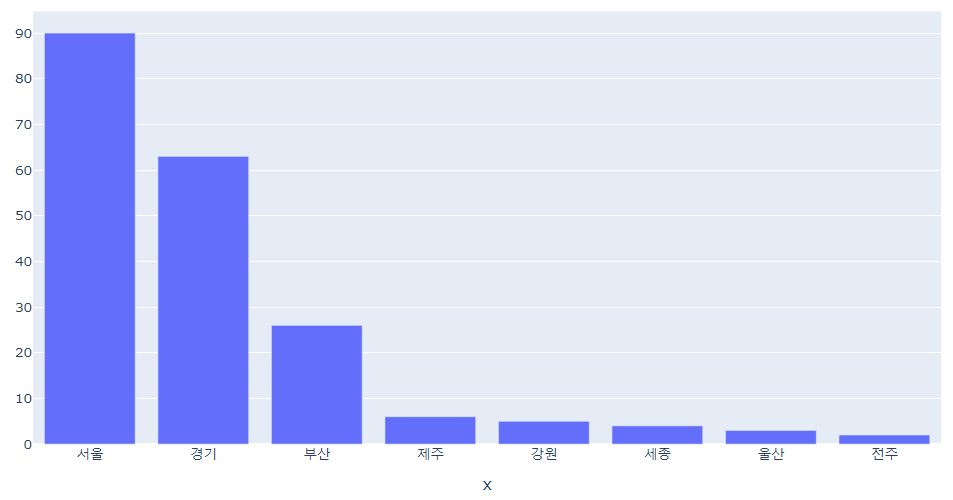
- 서울/경기에 거주하는 고객들이 가장 많음
- 쇼핑사이트를 이용하는 고객들은 수도권에 거주하는 사람들이 대부분임
- 서울/경기에 거주하는 고객들의 쇼핑사이트 이용률이 높다고 할 수 있을까?
3) 연령대에 대한 막대그래프를 그려보자
연령대를 10대, 20-25, 30-35, 40-45로 나누어 조사해보자.
age=[] for i in range(0,len(data)): if data.iloc[i,1]<20 : age.append('10') elif data.iloc[i,1] <25 and data.iloc[i,1] >=20 : age.append('20-25') elif data.iloc[i,1] <30 and data.iloc[i,1] >=25 : age.append('25-30') elif data.iloc[i,1] <35 and data.iloc[i,1] >=30 : age.append('30-35') elif data.iloc[i,1] <40 and data.iloc[i,1] >=35 : age.append('35-40') elif data.iloc[i,1] <45 and data.iloc[i,1] >=40 : ge.append('40-45')data_new=pd.concat([data,pd.DataFrame(age)],axis=1) data_new
[결과]
성별 나이 연봉 지역 구매제품 0
0 m 21 3300 서울 핸드폰케이스 20-25
1 f 22 5000 경기 마스크 20-25
2 f 25 5200 경기 마스크 25-30
3 f 32 2000 서울 핸드폰케이스 30-35
4 m 27 1800 부산 마스크 25-30
... ... ... ... ... ... ...
194 m 28 3400 경기 노트북 25-30
195 f 28 2800 서울 화장품 25-30
196 m 27 3500 경기 화장품 25-30
197 f 23 1900 경기 노트북 20-25
198 m 29 2800 서울 핸드폰케이스 25-30
199 rows × 6 columnspx.bar(x=data_new.iloc[:,5].value_counts().index, y=data_new.iloc[:,5].value_counts().values)
[결과]
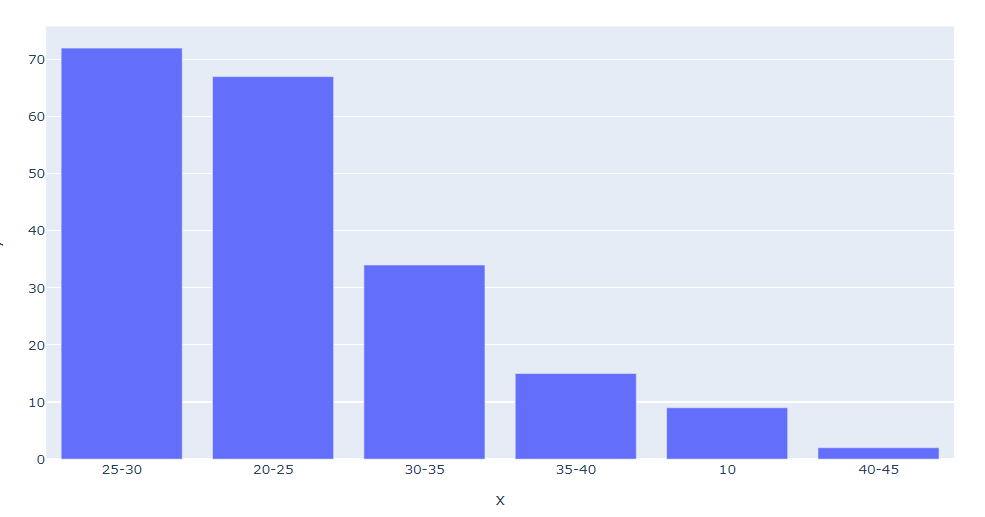
- 20대의 고객들이 쇼핑사이트를 가장 많이 이용
- 위 막대그래프로 20대 고객들에게 쇼핑사이트가 인기가 많다고 할 수 있을까?
- 위의 막대그래프로 20대 고객들이 쇼핑에 관심이 많다고 할 수 있을까?

안녕하세요 공부한 내용을 기록하기 위해서 시작했습니다.