[C813] 마이크로서비스를 구성할 때, 데이터베이스를 꼭 분리해야 하나요? 데이터가 한 곳에 모여있지 않고 중복되어도 괜찮은가요? 모범 사례를 알아보고, 이유를 함께 적어주세요.
📌 정리
배달의민족 기술 블로그에서 통합된 하나의 데이터베이스를 이용하여 서비스를 구축했을때 발생하는 문제점을 볼수 있었다.
빠른 개발과 관리포인트를 집중을 위한 선택이었지만, 시간이 지나면서 모노리틱 아키텍처의 장점이 부메랑이 되어 치명적인 단점으로 돌아왔다.
👉 DB per service 구축시 고려 사항
- 가능한 경우 결과적 일관성을 수용할것
결과적 일관성이란?
일시적으로 양쪽의 합이 맞지 않을 수 있으나 궁극적으로 맞도록 하는 비동기 방식
참조 - https://www.samsungsds.com/kr/insights/mas_data.html - 서비스가 일관적이고 느슨하게 결합되었는지 여부를 고려한다.
- 이벤트 기반 아키텍처 스타일을 사용한다.
- 확장을 위해 데이터베이스를 복제하고 샤딩해야 하는 경우가 있다.
- 서비스마다 데이터 저장 요구 사항이 다르므로 서비스에 맞는 데이터베이스를 선택해서 구축한다
- ...
📌 개요
MSA와 데이터베이스의 관계를 정리하고자 한다.
- MSA를 구축할때 데이터베이스를 서비스별로 구축할때의 장점
- MSA를 구축할때 데이터베이스를 서비스별로 구축할때의 단점
- 데이터베이스를 하나로 관리했을때 발생할 수 있는 문제점
- 모놀리식 DB를 사용하며 문제가 발생했고 이를 극복한 사례
📌 본문
👉 배달의 민족 사례로 보는 MSA 구축시 서비스별 데이터베이스 사용의 필요성
✅ 기존의 배달의 민족 MSA + 모놀리식 데이터베이스 구성도
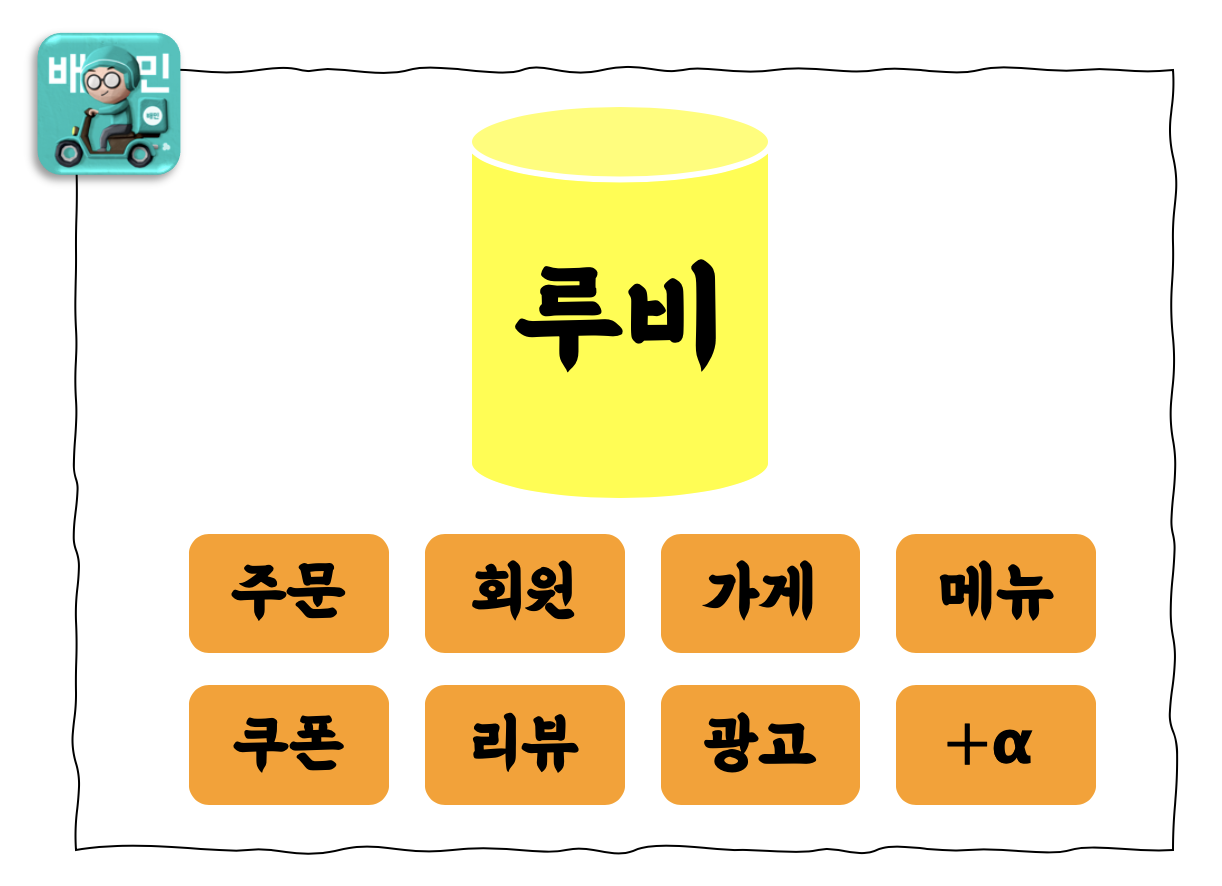
-
소수의 인원이 빠르게 개발할 수 있었던 과거와 달리 여러 서비스가 동시다발적으로 메인 데이터베이스를 사용하면서 예상하지 못한 부작용이 발생했고, 사소한 기능 하나를 추가하는데도 분석하고 수정해야 할 개발 범위는 상상을 초월했습니다.
-
새로운 기술을 도입하거나 새로운 기능을 오픈할 때마다 미처 확인하지 못한 부분이 발목을 잡았고, 복잡한 로직과 구조 때문에 장애 상황에 빠르게 대응하지 못했습니다.
-
메인 데이터베이스에 이슈가 생기면 배달의민족 전체 장애로 확산되기도 했습니다.
이 상황을 타개하기 위해 변화에 유연하지 못한 IDC를 벗어나서 모든 데이터베이스를 클라우드 환경에서 운영하고자 했고 ... (중략) 서비스 영향도가 많이 줄어들었습니다.

✅ 메인 데이터베이스 종료 후 배달의민족 서비스 아키텍쳐
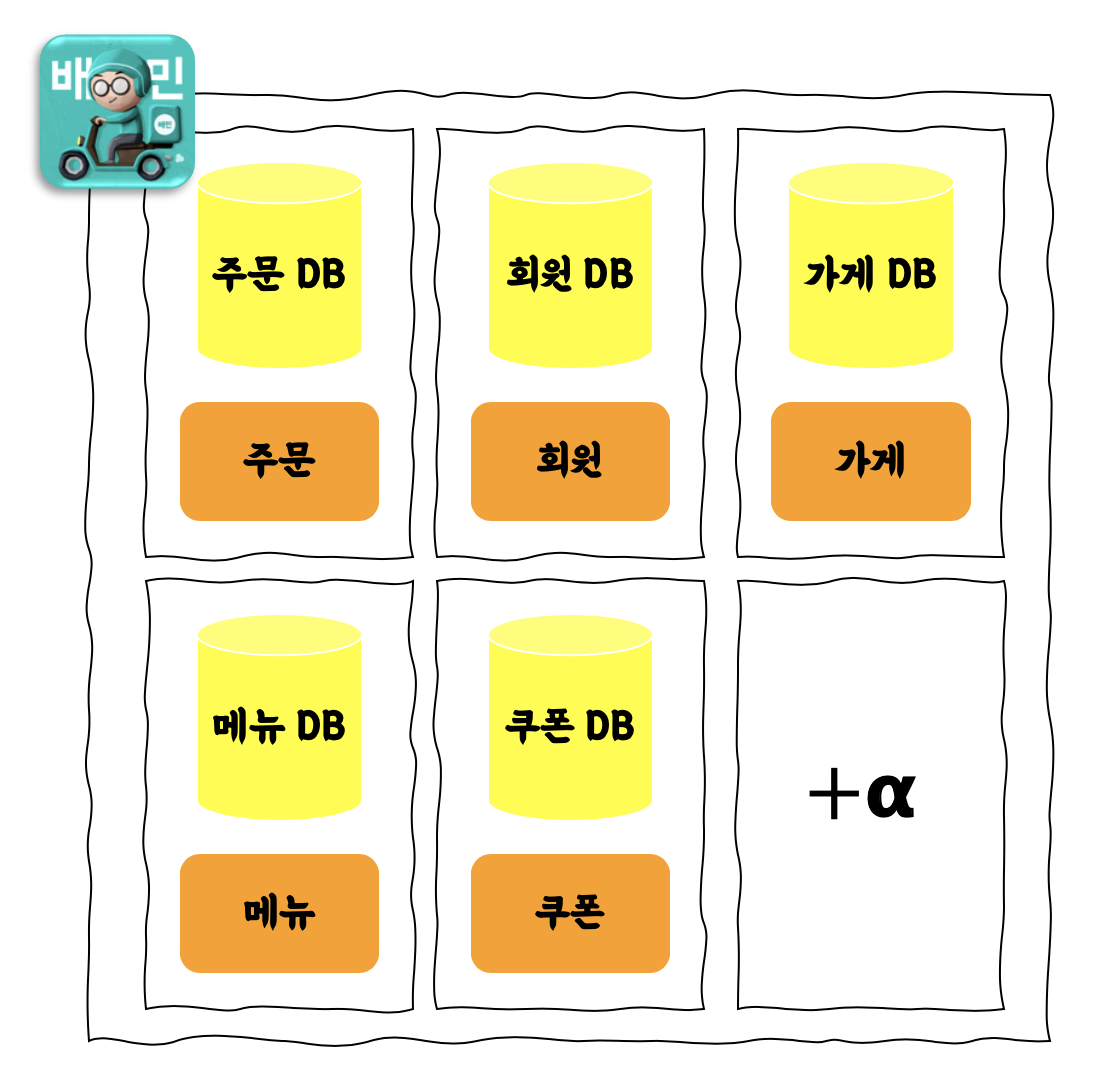
👉 마이크로 서비스에 대한 데이터 고려 사항
마이크로 서비스는 자체 데이터를 관리하기 때문에 데이터 무결성 및 데이터 일관성은 중요한 문제이다.
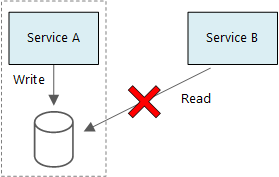
마이크로 서비스의 기본 원리는 각 서비스가 자체 데이터를 관리하는 것입니다. 두 서비스는 데이터 저장소를 공유하면 안 됩니다. 대신 각 서비스는 다른 서비스가 직접 액세스할 수 없는 자체 프라이빗 데이터 저장소에 대한 책임이 있습니다.
서비스에서 동일한 기본 데이터 스키마를 공유하는 경우 발생할 수 있는 서비스 간의 의도하지 않은 결합을 방지하기 위해서입니다. 데이터 스키마에 대한 변경 내용이 있는 경우 해당 데이터베이스를 사용하는 모든 서비스에서 변경 내용이 조정되어야 합니다. 각 서비스의 데이터 저장소를 격리하여 변경의 범위를 제한하고 완전히 독립적인 배포의 민첩성을 유지할 수 있습니다. 다른 이유는 각 마이크로 서비스에 자체 데이터 모델, 쿼리 또는 읽기/쓰기 패턴이 있을 수 있기 때문입니다. 공유 데이터 스토리지를 사용하면 해당 특정 서비스에 대한 데이터 스토리지를 최적화하는 각 팀의 기능을 제한합니다.
-
서비스가 필요한 데이터만 저장합니다. 서비스는 도메인 엔터티에 대한 정보의 하위 집합만 필요할 수 있습니다. 예를 들어 배송 제한된 컨텍스트에서 특정 배달에 연결된 고객을 알아야 합니다. 하지만 계정 바인딩된 컨텍스트에서 관리하는 고객의 청구 주소는 필요하지 않습니다. 도메인에 대해 신중하게 생각하세요. 여기에서는 DDD 방식을 사용하는 것이 도움이 될 수 있습니다.
-
서비스가 일관적이고 느슨하게 결합되었는지 여부를 고려합니다. 두 서비스가 지속적으로 서로 정보를 교환하여 번잡한 API가 되는 경우 두 서비스를 병합하거나 해당 기능을 리팩터링하여 서비스 경계를 다시 그려야 할 수 있습니다.
👉 Database per service
✅ 서비스별로 데이터베이스를 사용하면 다음과 같은 이점이 있습니다.
-
서비스가 느슨하게 결합되었는지 확인하는 데 도움이 됩니다. 한 서비스의 데이터베이스를 변경해도 다른 서비스에는 영향을 미치지 않습니다.
Helps ensure that the services are loosely coupled. Changes to one service’s database does not impact any other services.
-
각 서비스는 필요에 가장 적합한 데이터베이스 유형을 사용할 수 있습니다. 예를 들어 텍스트 검색을 수행하는 서비스는 ElasticSearch를 사용할 수 있습니다. 소셜 그래프를 조작하는 서비스는 Neo4j를 사용할 수 있습니다.
Each service can use the type of database that is best suited to its needs. For example, a service that does text searches could use ElasticSearch. A service that manipulates a social graph could use Neo4j.
✅ 서비스별로 데이터베이스를 사용하면 다음과 같은 단점이 있습니다.
-
여러 서비스에 걸친 비즈니스 트랜잭션을 구현하는 것은 간단하지 않다. 분산 트랜잭션은 CAP 정리 때문에 피하는 것이 가장 좋다. 또한 많은 최신 (NoSQL) 데이터베이스가 이를 지원하지 않는다.
Implementing business transactions that span multiple services is not straightforward. Distributed transactions are best avoided because of the CAP theorem. Moreover, many modern (NoSQL) databases don’t support them.
-
여러 데이터베이스에 있는 데이터를 join하는 쿼리를 구현하는 것이 어렵다.
Implementing queries that join data that is now in multiple databases is challenging.
-
여러 SQL 및 NoSQL 데이터베이스 관리의 복잡성이 발생한다.
Complexity of managing multiple SQL and NoSQL databases
✅ 레퍼런스 참조
- 마이크로 서비스에 대한 데이터 고려 사항 - https://docs.microsoft.com/ko-kr/azure/architecture/microservices/design/data-considerations
- Database per service - https://microservices.io/patterns/data/database-per-service.html
- 배달의민족 기술블로그 - https://techblog.woowahan.com/2656/
