
📌 Notice
Istio Hands-on Study (=Istio)
직접 실습을 통해 Isito를 배포 및 설정하는 내용을 정리한 블로그입니다.
CloudNet@에서 스터디를 진행하고 있습니다.
Gasida님께 다시한번 🙇 감사드립니다.
EKS 관련 이전 스터디 내용은 아래 링크를 통해 확인할 수 있습니다.
📌 Overview
이번 장에서는 Istio의 컨트롤 플레인 성능을 최적화하는 방법에 대해 다룹니다.
앞선 장에서 다뤘던 데이터 플레인 문제 해결은 주로 서비스 프록시 설정 및 디버깅에 초점이 맞춰져 있었습니다.
이번에는 컨트롤 플레인이 어떻게 서비스 프록시를 구성하는지, 그리고 이 구성 과정의 병목을 어떻게 모니터링하고 조정할 수 있는지를 살펴보게 됩니다.
이 장에서 다루는 내용
- 컨트롤 플레인 성능에 영향을 미치는 요소 이해하기
Understanding the factors of control-plane performance- 성능 모니터링 방법 알아보기
How to monitor performance- 주요 성능 메트릭 알아보기
What are the key performance metrics- 성능 최적화 방법 이해하기
Understanding how to optimize performance
📌 컨트롤 플레인 성능 튜닝
이전 블로그에서는 프록시 설정 및 동작 문제를 진단하는 데 사용할 수 있는 다양한 디버깅 도구를 살펴봤습니다.
서비스 프록시 설정을 이해하고 분석할 수 있다면, 예상과 다른 동작이 발생했을 때 문제를 빠르게 해결할 수 있습니다.
이제 시야를 컨트롤 플레인으로 확장합니다.
컨트롤 플레인은 다음과 같은 측면에서 성능 최적화가 필요합니다:
- 서비스 프록시에 구성을 전달하는 과정에서 병목이 발생하지 않도록 해야 합니다.
- 이러한 구성 전달이 느려지는 원인이 무엇인지 파악해야 합니다.
- 이 과정을 어떻게 모니터링할 수 있는지, 그리고
- 성능 향상을 위해 어떤 설정을 조정할 수 있는지를 하나씩 짚어보겠습니다.
👉 Step 01. 컨트롤 플레인의 주요 목표
✅ 들어가며: 유령 워크로드와 대응 방안
이번 장에서는 컨트롤 플레인의 역할과 성능 저하 시 발생할 수 있는 문제 중 하나인 유령 워크로드(phantom workload) 현상에 대해 설명드립니다.
컨트롤 플레인은 서비스 메시의 두뇌 역할을 하며, 서비스 메시 운영자를 위한 API를 외부에 노출합니다.
이를 통해 메시의 동작을 제어하고, 각 워크로드 인스턴스에 함께 배포된 서비스 프록시를 구성할 수 있습니다.
간단하게 설명하면, 메시의 설정은 단순히 운영자의 명시적인 요청에 의해서만 바뀌는 것이 아닙니다.
컨트롤 플레인은 런타임 환경에서 발생하는 다양한 이벤트(서비스 디스커버리, 오토스케일링, 상태 변화 등)를 추상화하여 메시의 동작을 자동으로 조정하게 됩니다.
이스티오의 컨트롤 플레인은 쿠버네티스 이벤트를 수신한 후, 메시가 반영해야 할 새로운 상태를 설정에 반영하는 역할을 합니다.
이러한 상태 조정 절차는 지속적으로 수행되며, 정확하고 시기적절하게 이뤄지는 것이 매우 중요합니다.
하지만 이 과정이 늦어지면, 설정이 바뀐 워크로드와 실제 메시 상태 간의 불일치가 발생하게 됩니다.
그 결과, 사용자는 다음과 같은 문제를 겪을 수 있습니다.
🧟♂️ 유령 워크로드란?
컨트롤 플레인의 성능이 저하되면 흔히 나타나는 증상 중 하나는 유령 워크로드입니다.
이는 이미 종료되거나 존재하지 않는 엔드포인트로 트래픽이 라우팅되어 요청이 실패하는 현상을 의미합니다.
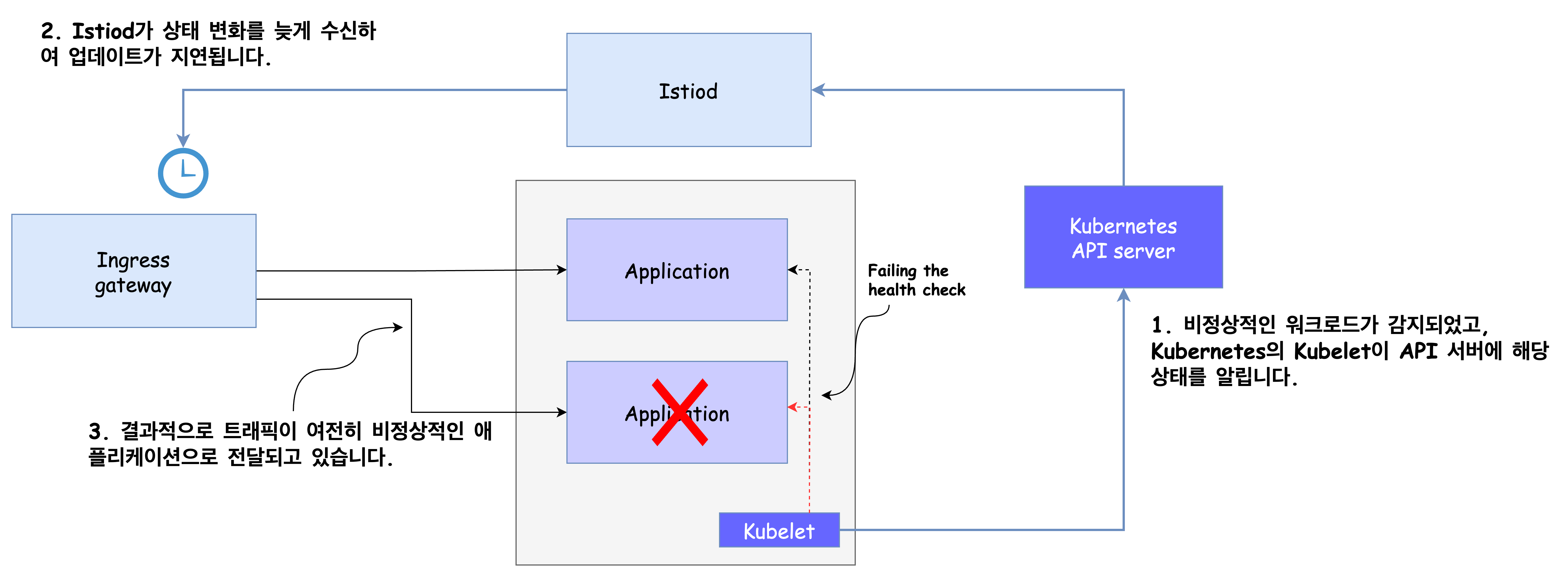
유령 워크로드 발생 절차는 다음과 같습니다.
- 비정상적인 워크로드가 이벤트를 트리거합니다.
- 컨트롤 플레인의 업데이트가 지연되면서, 서비스는 이전 상태의 설정을 유지하게 됩니다.
- 결과적으로 서비스는 더 이상 존재하지 않는 워크로드로 트래픽을 전송하게 되며, 요청이 실패하게 됩니다.
일반적으로 데이터 플레인은 궁극적인 일관성(eventual consistency)을 가지므로, 설정이 잠깐 낡은 상태인 것은 큰 문제가 되지 않을 수 있습니다.
왜냐하면 네트워크 실패 시 요청이 자동으로 재시도되며, 이때는 정상적인 엔드포인트가 처리하게 되는 경우가 많기 때문입니다.
또한, 실패한 요청이 감지되면 이상값 탐지를 통해 해당 엔드포인트를 클러스터에서 배제하는 방식으로도 복구가 가능할 수 있습니다.
하지만 이러한 복구 방식도 몇 초 이상의 지연이 발생하면 사용자 경험에 큰 영향을 미칠 수 있으므로,
이러한 지연을 최소화하는 것이 중요합니다.
이번 장에서는 이러한 유령 워크로드 문제를 예방하고, 컨트롤 플레인의 성능을 개선하기 위한 원인 분석과 대응 방안을 중점적으로 다루고자 합니다.
✅ 데이터 플레인 동기화 단계 이해하기: 디바운스와 스로틀링
Istio에서 컨트롤 플레인이 데이터 플레인을 원하는 상태로 동기화하는 과정은 여러 단계를 거칩니다.
이 흐름을 이해하면 성능 최적화를 위한 세부 설정이나 조정 시 유용한 기준을 마련할 수 있습니다.
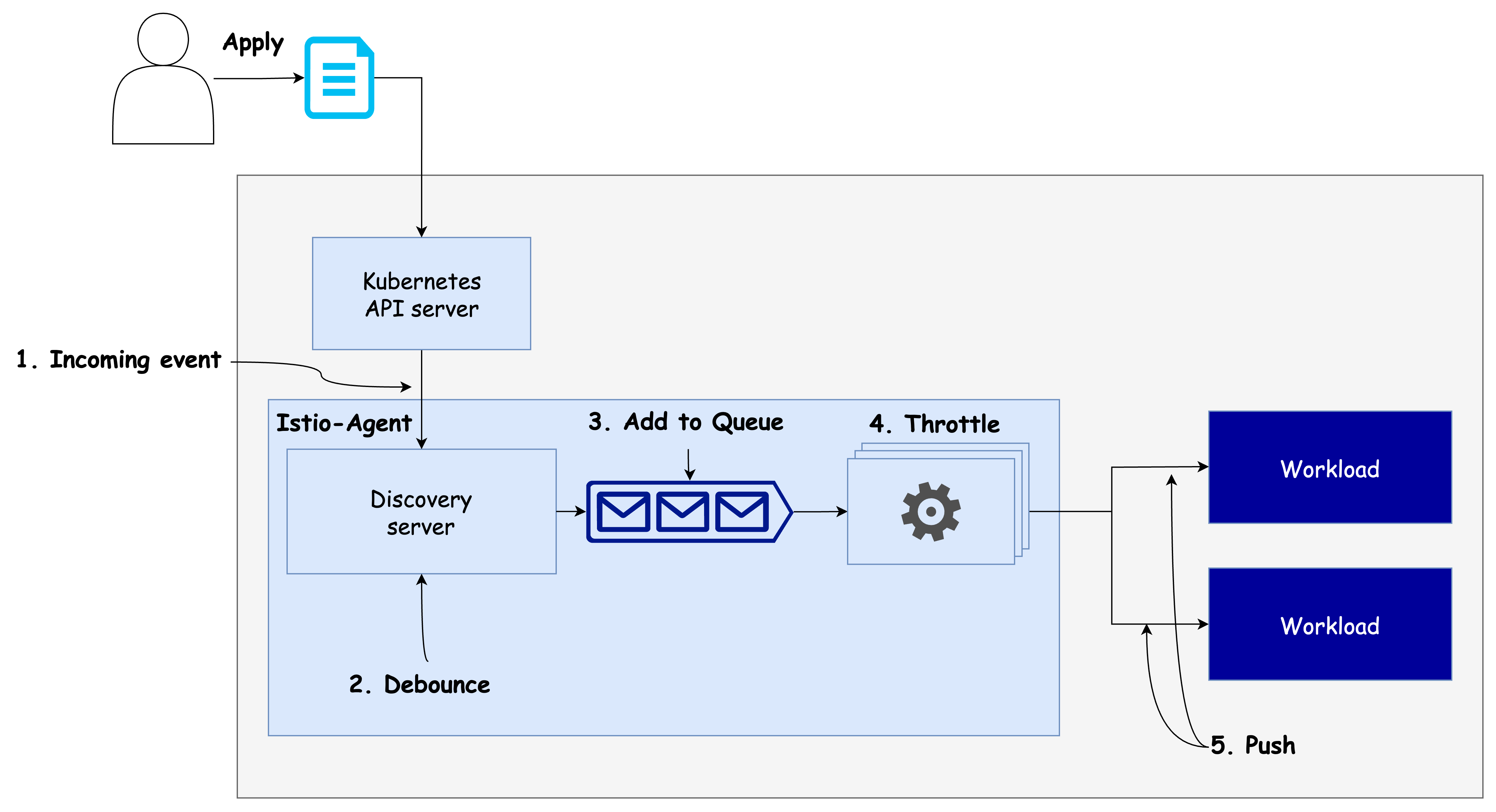
🔄 데이터 플레인 동기화 절차
-
이벤트 수신
컨트롤 플레인은 쿠버네티스에서 발생한 이벤트를 수신합니다. 이 이벤트는 서비스 추가, 삭제, 변경 등 상태 변화를 의미합니다. -
DiscoveryServer가 이벤트 수신
Istiod의 핵심 구성 요소인DiscoveryServer가 이러한 이벤트를 수신합니다.
이때 디바운스(debounce) 전략이 적용됩니다. 즉, 이벤트를 바로 처리하지 않고 잠시 기다리며 추가로 들어올 이벤트를 병합(batch 처리) 합니다.
이렇게 하면 불필요한 중복 처리를 줄이고, 리소스 낭비를 방지할 수 있습니다. -
병합 이벤트 푸시 대기열로 전송
기다리던 시간이 지나면 병합된 이벤트는푸시 대기열(push queue)로 들어갑니다.
이 대기열은 아직 처리되지 않은 푸시 요청들을 관리하는 공간입니다. -
스로틀링(throttling): 동시 처리 제한
Istiod는 동시에 처리되는 푸시 요청의 수를 제한하여 스로틀링을 수행합니다.
이는 각 푸시 요청이 보다 빠르게 처리되도록 하고, CPU가 여러 작업 사이를 오가며 낭비되는 시간을 줄이는 데 도움이 됩니다. -
엔보이 설정으로 변환 및 워크로드에 푸시
최종적으로, 푸시 대기열에서 처리된 항목은 Envoy 구성으로 변환된 뒤 각 워크로드의 프록시에 전달됩니다.
🛡 디바운스와 스로틀링의 역할
Istio는 위 과정을 통해 자신을 과부하로부터 보호합니다.
- 디바운싱은 짧은 시간 내 여러 변경 이벤트를 병합하여 불필요한 작업 반복을 막습니다.
- 스로틀링은 동시 작업 수를 제한하여 리소스 낭비 없이 안정적인 성능을 유지하게 합니다.
이 두 전략은 Istio 설정을 통해 조정이 가능하며, 다음 절에서 성능 최적화를 위한 조정법도 함께 살펴보게 됩니다.
✅ 성능을 결정짓는 요소: 변경 속도, 리소스, 워크로드 수, 설정 크기
앞선 동기화 과정을 이해했다면, 이제는 컨트롤 플레인의 성능에 영향을 주는 주요 요인들을 설명할 수 있습니다.
이러한 요인들을 파악하면, 성능 병목이 어디에서 발생할 수 있는지 예측하고 적절한 최적화를 진행하는 데 큰 도움이 됩니다.
⚙️ 컨트롤 플레인 성능에 영향을 주는 주요 속성들

-
변경 속도 (Rate of Changes)
변경이 자주 발생할수록, Istio는 더 많은 이벤트를 수신하고 이를 처리해야 하므로 데이터 플레인을 일관된 상태로 유지하는 데 필요한 처리량도 증가합니다.
→ 변경 속도가 높을수록 성능 부담이 커집니다. -
할당된 리소스 (Allocated Resources)
istiod에 할당된 CPU 및 메모리 자원이 부족하면, 들어오는 작업을 푸시 대기열에 보관해야 하며, 이로 인해 업데이트 반영 속도가 느려질 수 있습니다.
→ 과도한 요청을 감당할 리소스가 없다면 병목 현상이 발생합니다. -
업데이트할 워크로드 개수 (Number of Workloads to Update)
배포 대상 워크로드가 많아질수록, 더 많은 네트워크 대역폭과 처리 성능이 요구됩니다.
→ 특히 클러스터 규모가 클수록 이 영향은 매우 큽니다. -
설정 크기 (Configuration Size)
Envoy 프록시에 전달되는 설정의 크기가 커질수록, 이를 직렬화 및 전송하는 데 더 많은 처리 시간과 네트워크 자원이 필요합니다.
→ 설정이 복잡해질수록 성능 저하 가능성도 함께 커집니다.
이 네 가지 요소는 서로 독립적이면서도 상호작용할 수 있으므로,
실제 성능 최적화를 수행할 때에는 요소 간 균형과 병목 지점을 함께 고려해야 합니다.
다음 단계에서는 8장에서 구성한 Grafana 대시보드와 Prometheus 메트릭을 활용하여,
이러한 성능 요소들이 실제로 어떤 식으로 병목을 발생시키는지 시각적으로 분석하는 방법을 알아보겠습니다.
👉 Step 02. 컨트롤 플레인 모니터링하기
✅ 들어가며: Monitoring the control plane
Istio의 컨트롤 플레인 구성 요소인 istiod는 다양한 핵심 성능 지표(metrics)를 외부에 노출합니다.
이 지표에는 다음과 같은 항목들이 포함됩니다:
- 리소스 사용률(CPU, 메모리 등)
- 수신/발신 트래픽으로 인한 부하
- 에러 비율 및 실패한 요청 처리 횟수
이러한 메트릭은 현재 컨트롤 플레인이 잘 작동하고 있는지, 향후 문제가 발생할 가능성은 없는지,
또는 이미 이상 상태에 도달한 원인을 어떻게 진단할 수 있을지에 대해 통찰을 제공합니다.
Istio 공식 문서에서도 수많은 메트릭 항목이 정리되어 있습니다.
자세한 항목은 아래 공식 링크에서 확인하실 수 있습니다:
👉 Istio Pilot Discovery Metrics Reference
하지만 메트릭의 수가 방대하기 때문에, 이 장에서는 중요도에 따라 핵심 메트릭을 식별하고,
이를 SRE 관점에서 자주 사용하는 ‘네 가지 황금 신호’(Golden Signals) 기준에 따라 분류해볼 예정입니다.
이를 통해 보다 효과적으로 컨트롤 플레인의 상태를 모니터링하고,
트러블슈팅 시 어떤 지표에 주목해야 할지를 체계적으로 파악할 수 있습니다.
✅ 컨트롤 플레인의 네 가지 황금 신호
SRE Handbook에서 정의된 네 가지 황금 신호(Golden Signals)는 시스템 상태를 외부 시각에서 효과적으로 파악하기 위한 핵심 지표입니다.
이 네 가지 신호는 다음과 같습니다:
- Latency (지연 시간)
- Saturation (포화도)
- Traffic (트래픽)
- Errors (오류)
이 장에서는 Istio의 컨트롤 플레인 istiod가 노출하는 메트릭을 기반으로
각 항목을 실습과 함께 살펴보고 그라파나 대시보드에서 시각화 및 알림 조건 설정까지 다루게 됩니다.
🧪 실습 환경 초기화
컨트롤 플레인의 메트릭을 수집하고 시각화하기 위해 아래 명령어로 실습 환경을 구성합니다.
# 실습 환경 구성
kubectl -n istioinaction apply -f services/catalog/kubernetes/catalog.yaml
kubectl -n istioinaction apply -f ch11/catalog-virtualservice.yaml
kubectl -n istioinaction apply -f ch11/catalog-gateway.yaml
# 상태 확인
kubectl get deploy,gw,vs -n istioinaction
# 반복 요청 전송
while true; do curl -s http://catalog.istioinaction.io:30000/items ; date "+%Y-%m-%d %H:%M:%S" ; sleep 1; echo; done
# istiod 메트릭 확인
kubectl exec -it -n istio-system deploy/istiod -- curl localhost:15014/metrics
⏱️ 지연 시간: 데이터 플레인을 업데이트하는 데 필요한 시간
지연 시간은 서비스 외부, 즉 최종 사용자 관점에서 서비스가 얼마나 빠르게 반응하는지를 보여주는 가장 직관적인 지표입니다.
지연 시간이 길어진다는 것은 서비스 성능이 저하되고 있다는 신호이지만, 정확한 원인을 파악하려면 추가적인 지표 분석이 필요합니다.
컨트롤 플레인의 관점에서 지연 시간은 프록시 업데이트 요청이 큐에 도달한 시점부터, 워크로드에 반영되기까지의 전체 과정 소요 시간을 의미합니다.
📊 주요 메트릭
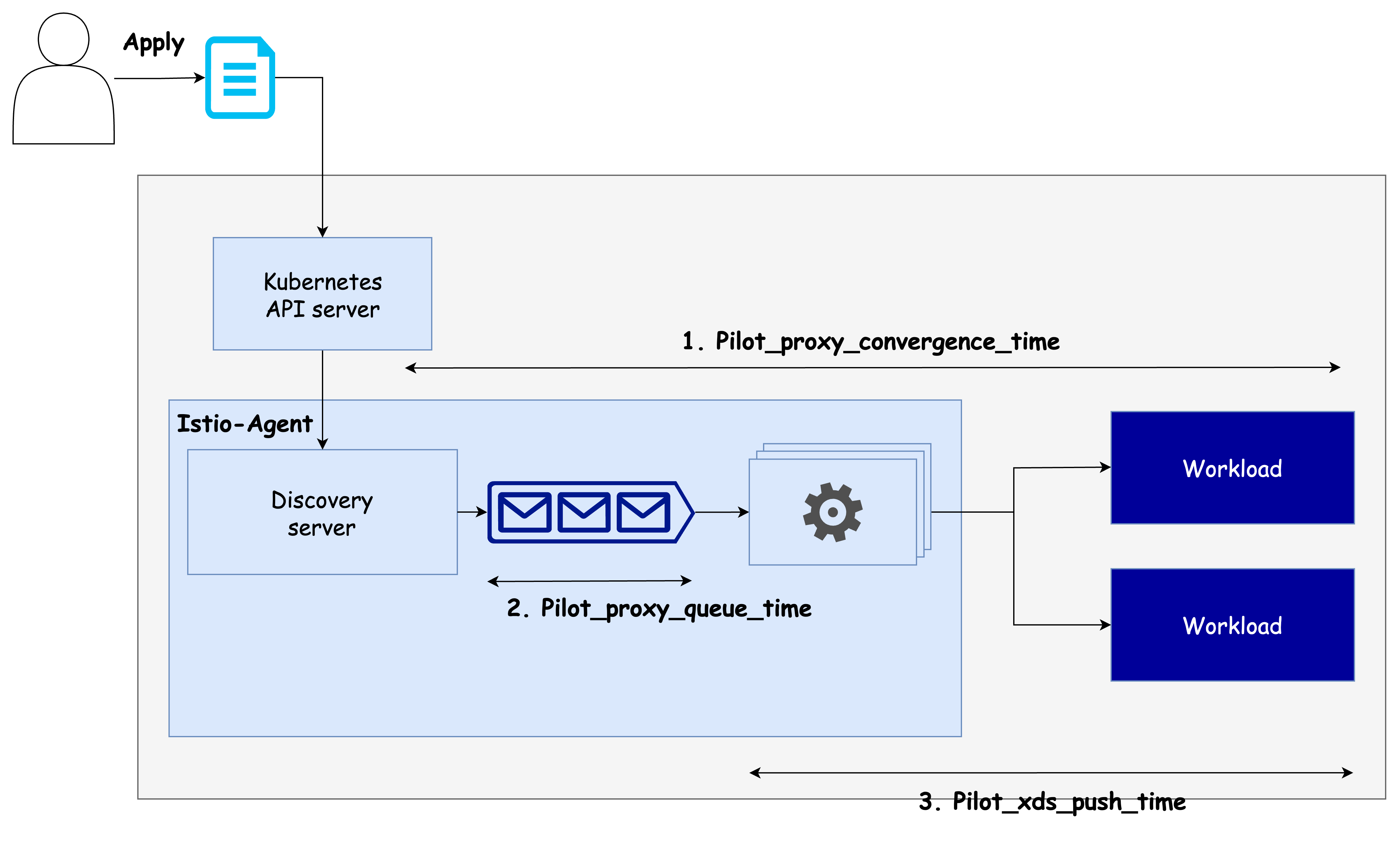
-
pilot_proxy_convergence_time
→ 푸시 요청이 큐에 들어간 순간부터 워크로드에 배포될 때까지 전체 시간 측정 -
pilot_proxy_queue_time
→ 푸시 요청이 워커에 의해 처리되기 전까지 큐에서 기다린 시간 측정
→ 이 값이 높다면istiod의 수직 확장을 고려해야 합니다. -
pilot_xds_push_time
→ Envoy 설정을 워크로드로 전송하는 데 걸리는 시간
→ 네트워크 대역폭 부족 또는 설정 크기 과다로 인한 문제를 나타냅니다.
📈 그라파나 대시보드 시각화
pilot_proxy_convergence_time은 Istio Control Plane 대시보드의 Proxy Push Time 패널에서 확인할 수 있습니다.- 기본적으로 대부분의 푸시가 100ms 이내에 완료되며, 이는 이상적인 상태입니다.
# PromQL 예시
histogram_quantile(0.5, sum(rate(pilot_proxy_convergence_time_bucket[1m])) by (le))
histogram_quantile(0.9, sum(rate(pilot_proxy_convergence_time_bucket[1m])) by (le))
histogram_quantile(0.99, sum(rate(pilot_proxy_convergence_time_bucket[1m])) by (le))
histogram_quantile(0.999, sum(rate(pilot_proxy_convergence_time_bucket[1m])) by (le))동일한 방식으로 다음 패널을 추가해 확인할 수 있습니다:
- Proxy Queue Time: pilot_proxy_queue_time_bucket
- XDS Push Time: pilot_xds_push_time_bucket
# Proxy Queue Time
histogram_quantile(0.99, sum(rate(pilot_proxy_queue_time_bucket[1m])) by (le))
# XDS Push Time
histogram_quantile(0.99, sum(rate(pilot_xds_push_time_bucket[1m])) by (le))패널은 기존 Proxy Push Time을 복제해 커스터마이징하면 되고,
시각적으로 세 단계의 동기화 병목 위치를 확인할 수 있도록 배치하는 것이 좋습니다
⚠️ 임계값 설정 및 알림 기준
메시에 워크로드가 늘어나면 자연스럽게 지연 시간도 증가할 수 있으나,
지나치게 증가하는 경우 경고 또는 치명적 상태로 간주해야 합니다.
- Warning: 10초 이상 동안 지연 시간이 1초 초과
- Critical: 10초 이상 동안 지연 시간이 2초 초과
첫 경고 알림이 오더라도 당황할 필요는 없습니다.
이는 단순히 성능 최적화가 필요함을 알리는 신호이며,
장기간 방치할 경우 최종 사용자 경험에 영향을 줄 수 있으므로 조치가 필요합니다.
지연 시간 메트릭은 성능 저하의 시작을 감지하는 데 매우 효과적이지만,
실제 원인을 파악하기 위해서는 다음에 설명할 포화도, 트래픽, 오류와 같은 신호를 함께 분석해야 합니다.
🔋 포화도: 컨트롤 플레인이 얼마나(CPU, MEM 리소스) 가득 차 있는가?
포화도(Saturation)는 컨트롤 플레인의 자원이 얼마나 사용 중인지,
즉 얼마나 과부하 상태에 가까운지를 보여주는 중요한 지표입니다.
포화 상태가 되면 성능 저하가 발생하고,
푸시 요청이 대기열에 쌓이면서 데이터 플레인으로의 설정 반영 속도가 느려질 수 있습니다.
📊 주요 개념 및 메트릭
-
포화도 메트릭은 리소스 사용량을 나타냅니다.
- 일반적으로 90% 이상 사용되면 포화되었거나 곧 포화될 가능성이 큽니다.
-
Istio의 컨트롤 플레인인
istiod는 CPU 중심적인 워크로드입니다.
따라서 대부분의 경우 CPU 사용률을 가장 먼저 모니터링해야 합니다.
🧪 주요 CPU 사용 메트릭
container_cpu_usage_seconds_total
→ 쿠버네티스에서 보고되는 컨테이너 기준 CPU 사용량
sum(irate(container_cpu_usage_seconds_total{
container="discovery",
pod=~"istiod-.*|istio-pilot-.*"
}[1m]))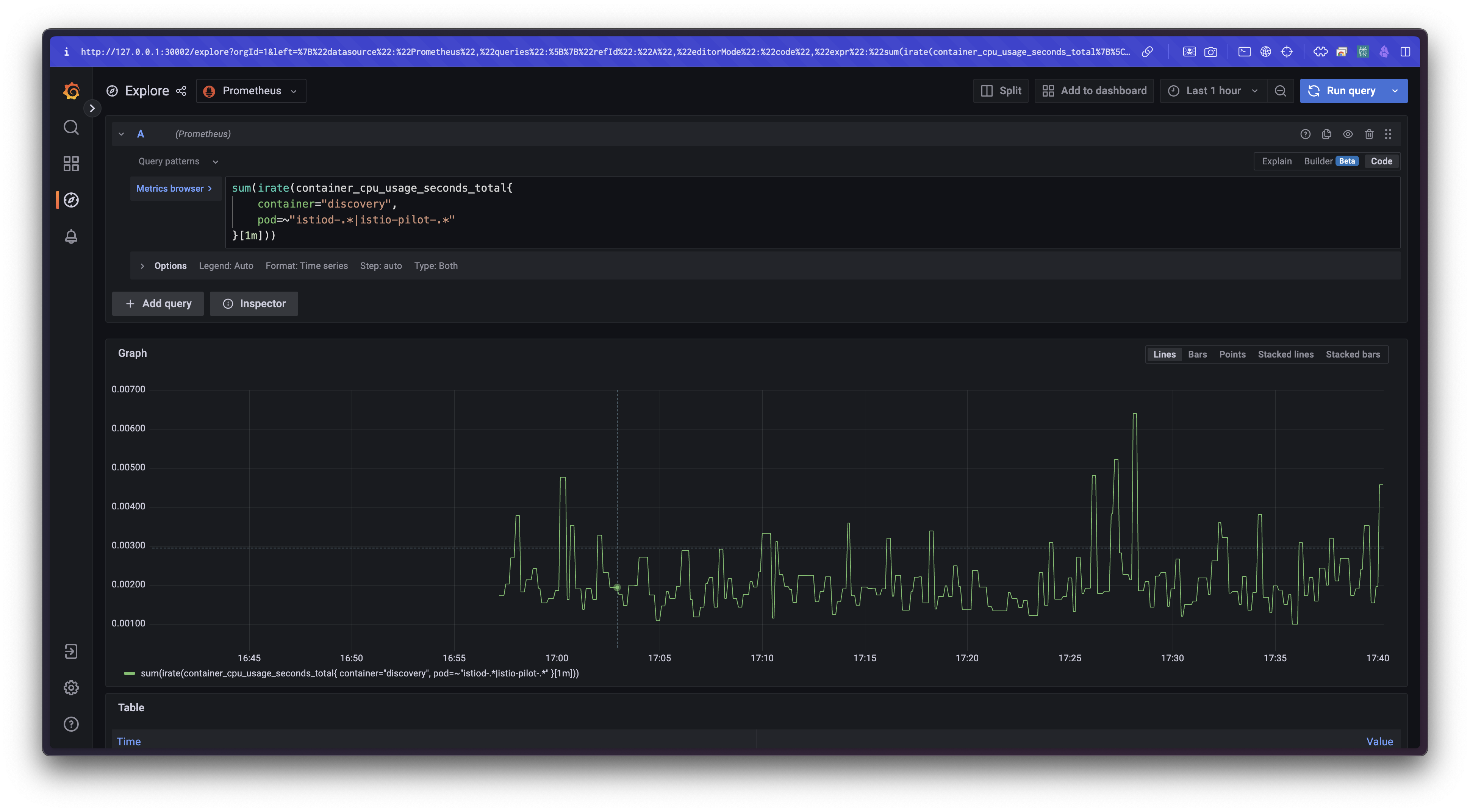
process_cpu_seconds_total
→istiod프로세스에서 직접 측정하는 CPU 시간
irate(process_cpu_seconds_total{app="istiod"}[1m])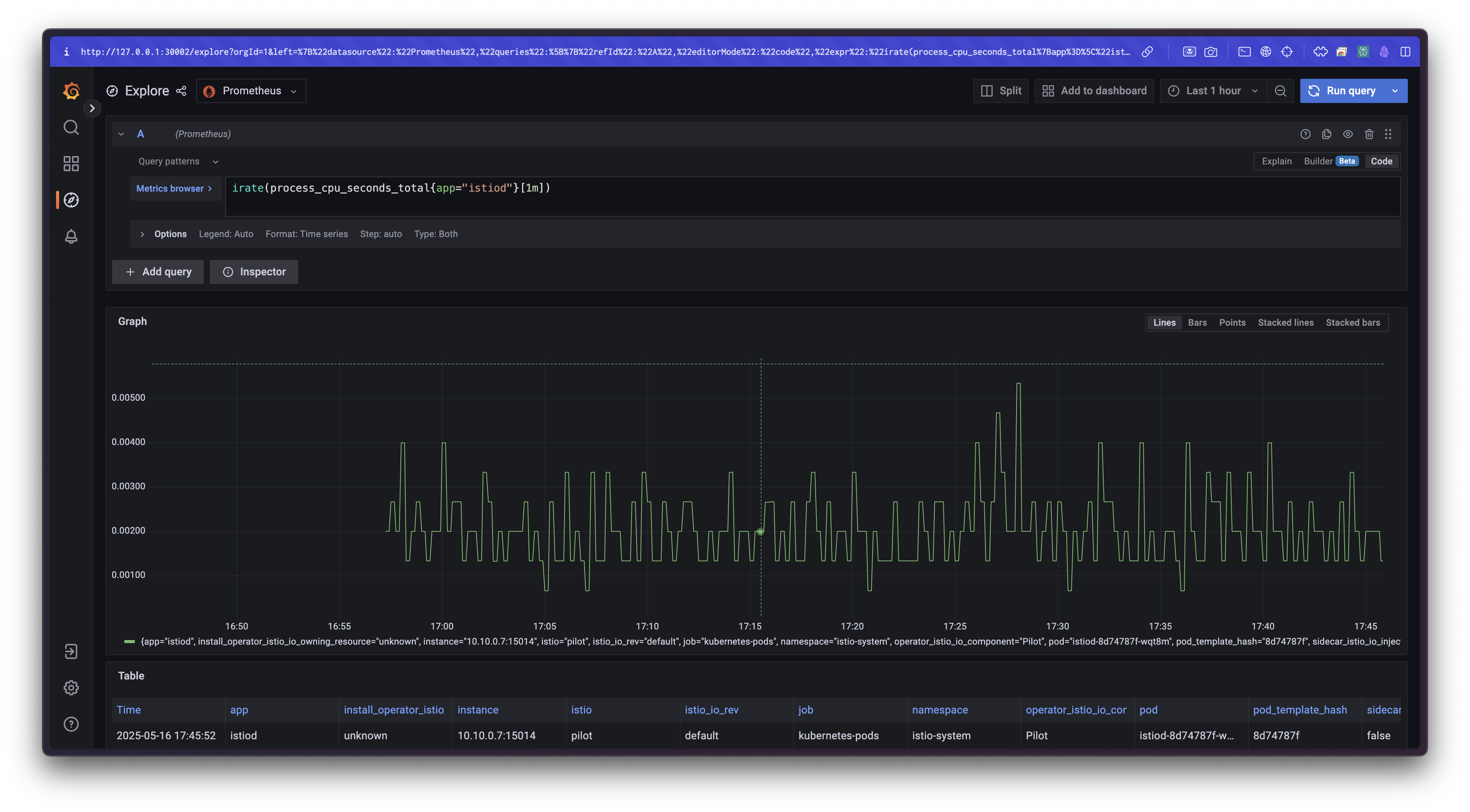
💡 두 메트릭 모두 Grafana에서 시각화 가능하며,
CPU 포화 상태 여부를 빠르게 파악할 수 있습니다.
🛠 실습 명령어 예시
# istiod 컨테이너 CPU/MEM 사용률 확인
kubectl top pod -n istio-system -l app=istiod --containers=true
# 네임스페이스 전체 리소스 사용량 확인
kubectl resource-capacity -n istio-system -c -u -l istio.io/rev=default
kubectl resource-capacity는 요청/제한 및 실제 사용률을 함께 보여주기 때문에
예상 대비 실제 리소스 사용 수준을 파악하는 데 유용합니다.
📈 Grafana 대시보드 예시
컨트롤 플레인의 CPU 사용률은 Grafana에서 다음과 같은 형태로 시각화됩니다:
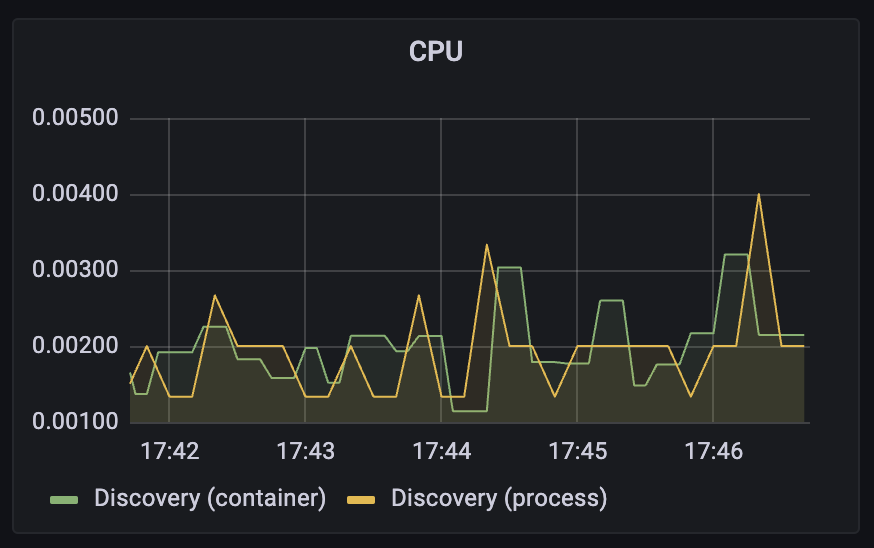
- 일반적으로
istiod는 대부분의 시간을 유휴(idle) 상태로 유지합니다. - 하지만 서비스가 배포되거나 설정 변경이 발생할 때 CPU 사용량이 급격히 증가합니다.
- 이 시점에서 포화 상태가 발생하면 푸시 지연이 생기며 성능 저하로 이어질 수 있습니다.
✅ 대응 방안 및 고려사항
-
다음과 같은 조건이라면 컨트롤 플레인이 포화 상태에 도달했을 수 있습니다:
- CPU 사용률이 90% 이상 지속
- 푸시 요청이 대기열에서 오래 대기
-
이 경우 고려할 수 있는 대응 방안은 다음과 같습니다:
istiod에 할당된 CPU/Memory 요청 및 제한 리소스 상향 조정- 수직 확장(vertical scaling): 더 높은 리소스 노드에 재배치
- 수평 확장(horizontal scaling):
istiod인스턴스를 늘려 분산 처리
포화도는 컨트롤 플레인의 성능 저하를 초래하는 가장 흔한 원인 중 하나입니다.
따라서 지속적인 모니터링과 사전 조치 체계가 매우 중요합니다.
📡 트래픽: 컨트롤 플레인의 부하는 어느 정도인가?
트래픽(Traffic)은 컨트롤 플레인이 얼마나 많은 요청을 받고 처리하는지를 보여주는 핵심 지표입니다.
이는 곧 시스템이 현재 감당하고 있는 부하의 크기를 나타내며,
성능 병목이 발생할 수 있는 지점을 식별하는 데 매우 유용합니다.
Istio의 컨트롤 플레인에서는 다음과 같이 두 가지 종류의 트래픽이 존재합니다:
- 수신 트래픽: 설정 변경, 리소스 이벤트 등 컨트롤 플레인이 처리해야 하는 외부 이벤트
- 송신 트래픽: 데이터 플레인(Envoy 프록시)으로의 구성 푸시, xDS 업데이트 등
이 양방향 트래픽을 모두 측정함으로써, 전체적인 부하를 정확히 이해하고 병목 요인을 식별할 수 있습니다.
📨 수신 트래픽 메트릭
pilot_inbound_updates
→ 각 istiod 인스턴스가 수신한 설정 변경 요청의 횟수를 측정합니다.
pilot_push_triggers
→ 푸시를 유발한 전체 이벤트 수를 측정합니다.
이벤트는 서비스, 엔드포인트, VirtualService 등 다양한 리소스 변경에 의해 발생합니다.
pilot_services
→ 파일럿(Pilot)이 인지하고 있는 전체 Kubernetes 서비스 수를 나타냅니다.
서비스 수가 많을수록 푸시 이벤트 발생 시 처리해야 할 범위가 넓어져 부하가 커집니다.
avg(pilot_virt_services{app="istiod"}) # Istio VirtualService 개수
avg(pilot_services{app="istiod"}) # Kubernetes 서비스 개수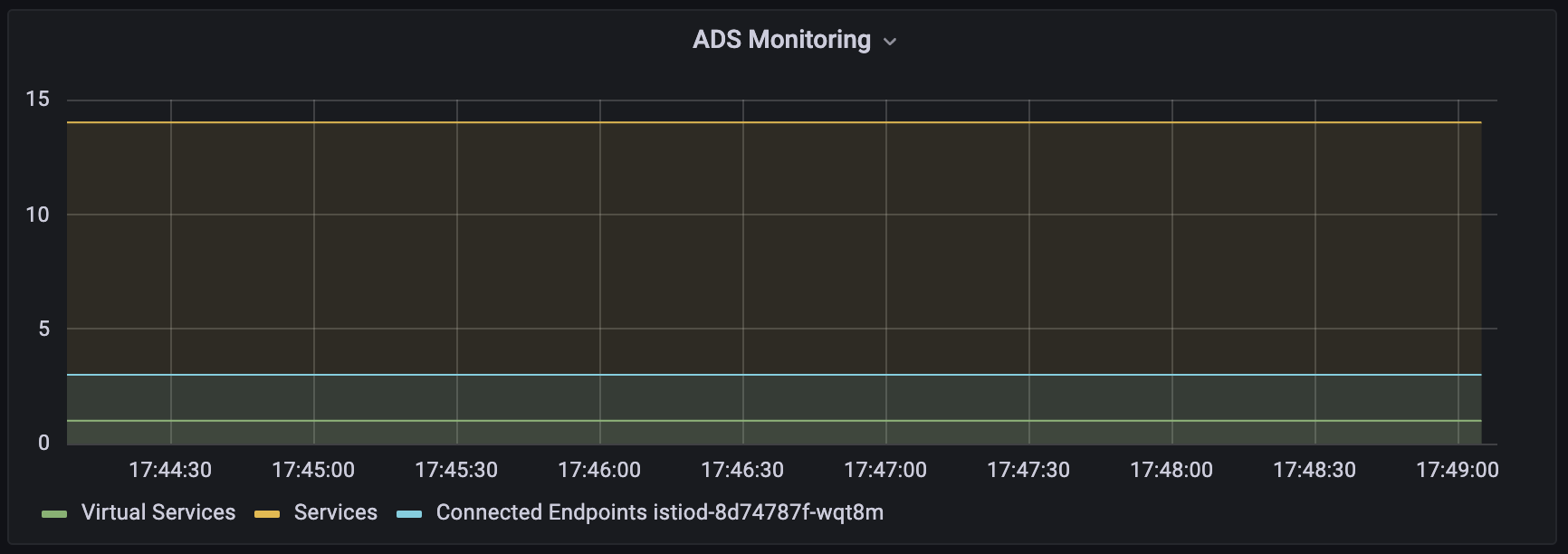
📤 송신 트래픽 메트릭
pilot_xds_pushes
→ xDS API (CDS, EDS, RDS, LDS) 기반으로 얼마나 자주 구성 푸시가 발생했는지를 측정합니다.
Grafana 대시보드의 Pilot Pushes 패널에서 시각화됩니다.
sum(irate(pilot_xds_pushes{type="cds"}[1m]))
sum(irate(pilot_xds_pushes{type="eds"}[1m]))
sum(irate(pilot_xds_pushes{type="lds"}[1m]))
sum(irate(pilot_xds_pushes{type="rds"}[1m]))pilot_xds
→ 컨트롤 플레인이 관리 중인 워크로드와의 연결 수를 나타냅니다.
즉, 얼마나 많은 프록시와 xDS 커넥션이 유지되고 있는지를 보여줍니다.
ADS Monitoring 패널에서 시각화됩니다.
sum(pilot_xds{app="istiod"}) by (pod)envoy_cluster_upstream_cx_tx_bytes_total
→ 네트워크를 통해 전송된 설정 크기(Byte)를 측정합니다.
xDS 통신에 사용된 실제 트래픽 양을 나타내며, 설정 변경이 많거나 구성 크기가 크면 이 수치도 증가합니다.
quantile(0.5, rate(envoy_cluster_upstream_cx_tx_bytes_total{cluster_name="xds-grpc"}[1m]))대시보드에 XDS Requests Size 패널에 Legend: XDS Request Bytes Average
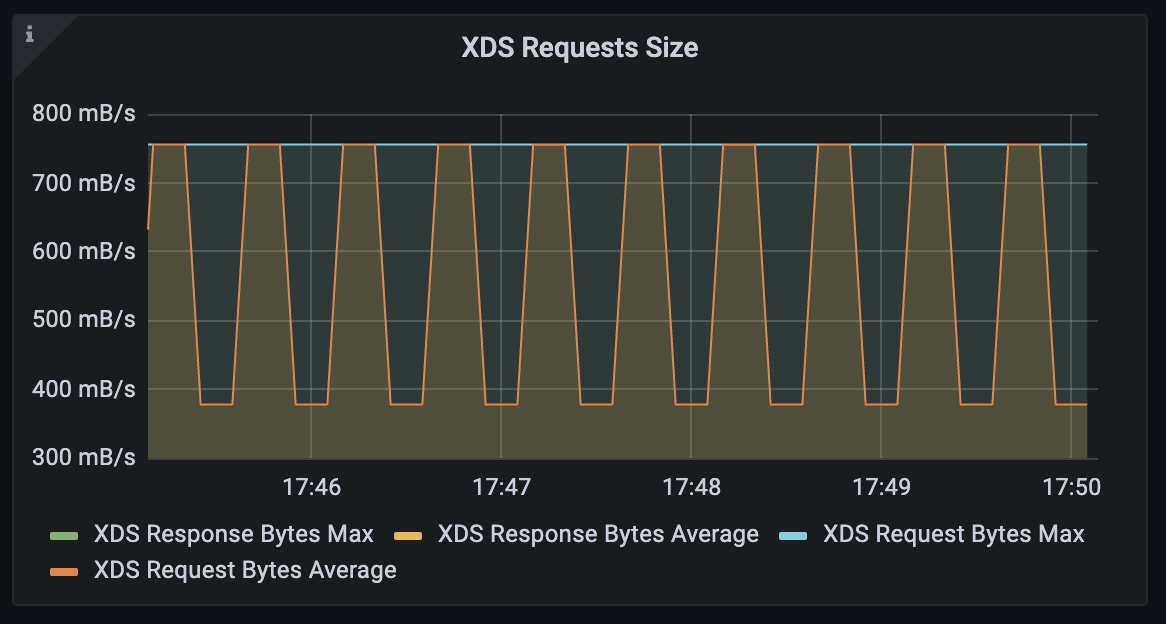
🔍 해석 및 대응 전략
수신 트래픽이 원인인 경우
→ 설정 변경이 잦고 이벤트 처리량이 많아 istiod가 과부하됨
→ 해결책: 이벤트 병합 시간 조정, istiod 수직 확장
송신 트래픽이 원인인 경우
→ 설정 변경이 자주 발생하거나 워크로드 수가 많아 푸시 비용이 커짐
→ 해결책:
- 사이드카 리소스 최적화 (변경 범위 축소)
- 컨트롤 플레인 수평 확장 (다수의
istiod인스턴스 운영)
트래픽은 단순히 “양”이 아니라,
어떤 방향에서 부하가 집중되고 있는지 파악하고 이에 맞춰 대응하는 것이 핵심입니다.
❗ 오류: 컨트롤 플레인의 실패율은 어떻게 되는가?
오류(Errors)는 컨트롤 플레인, 특히 istiod에서 발생한 실패율을 보여주는 지표입니다.
일반적으로 서비스가 포화 상태에 이르렀거나, 내부 처리 중 문제가 생겼을 때 오류가 증가하게 됩니다.
오류 메트릭은 단일 이벤트만으로는 판단이 어렵지만,
성능 병목이나 구성 충돌의 징후를 나타내는 중요한 경고 신호입니다.
📊 주요 오류 메트릭
다음은 Istio Control Plane 대시보드에서 Pilot Errors 패널에 시각화되는 핵심 메트릭입니다.
# 각 오류 유형에 대한 PromQL 예시
sum(pilot_xds_cds_reject{app="istiod"}) or (absent(pilot_xds_cds_reject{app="istiod"}) - 1)
sum(pilot_xds_eds_reject{app="istiod"}) or (absent(pilot_xds_eds_reject{app="istiod"}) - 1)
sum(pilot_xds_rds_reject{app="istiod"}) or (absent(pilot_xds_rds_reject{app="istiod"}) - 1)
sum(pilot_xds_lds_reject{app="istiod"}) or (absent(pilot_xds_lds_reject{app="istiod"}) - 1)
sum(rate(pilot_xds_write_timeout{app="istiod"}[1m]))
sum(rate(pilot_total_xds_internal_errors{app="istiod"}[1m]))
sum(rate(pilot_total_xds_rejects{app="istiod"}[1m]))
sum(rate(pilot_xds_push_context_errors{app="istiod"}[1m]))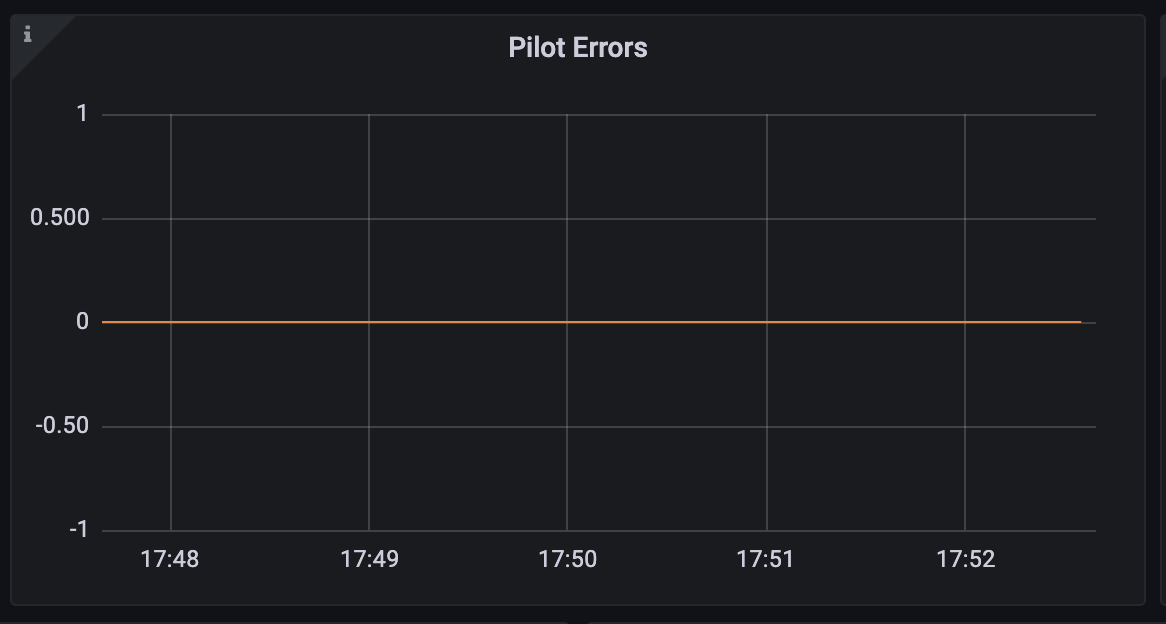
🧾 메트릭 상세 설명
| 메트릭 | 설명 |
|---|---|
| pilot_total_xds_rejects | 전체 xDS 푸시 중 거부된 설정의 총 횟수 |
| pilotxds{cds/eds/rds/lds}_reject | 특정 API 유형의 설정 거부 횟수 (CDS, EDS, RDS, LDS) |
| pilot_xds_write_timeout | 구성 푸시 중 발생한 타임아웃 수 |
| pilot_xds_push_context_errors | Envoy 설정 생성 중 내부 오류 발생 횟수 (주로 버그 또는 비정상 상태) |
| pilot_total_xds_internal_errors | 내부 처리 중 발생한 예외/오류의 총량 |
🛠 해석 및 활용 전략
-
총 거부 수(
pilot_total_xds_rejects)가 증가하고 있다면,
구성 충돌이나 잘못된 VirtualService 등의 리소스 문제가 의심됩니다. -
Context 오류나 Internal Error가 반복된다면,
이는istiod의 버그 또는 비정상적인 리소스 상태로 인한 문제일 수 있습니다. -
푸시 타임아웃이 잦다면,
컨트롤 플레인의 성능 포화 또는 워크로드 수 과다에 의한 처리 지연이 원인일 수 있습니다.
이러한 오류 메트릭은 단순히 실패 건수만을 나타내는 것이 아니라,
컨트롤 플레인의 동작이 얼마나 안정적으로 유지되고 있는지를 평가할 수 있는 중요한 기준이 됩니다.
또한, 각 오류 유형별로 원인을 세분화할 수 있기 때문에, 트러블슈팅 시 빠르게 수사망을 좁히는 데 효과적입니다.
👉 Step 03. 성능 튜닝하기
✅ 들어가며: 컨트롤 플레인 성능의 변수
컨트롤 플레인의 성능에 영향을 주는 요인을 다시 정리해 보면 다음과 같습니다:
- 변경 속도: 클러스터 및 환경에서 얼마나 자주 리소스가 생성, 수정, 삭제되는지
- 리소스 할당량:
istiod에 부여된 CPU 및 메모리 자원 - 관리 중인 워크로드 수: 클러스터에 존재하는 프록시 수
- 설정 크기: 각 프록시에 푸시되는 Envoy 설정의 복잡도 및 용량
이들 중 하나라도 병목이 되면 성능 저하로 이어질 수 있으며,
이러한 병목을 완화하기 위한 다양한 조정 방법(knobs)은 아래 그림과 같이 존재합니다.
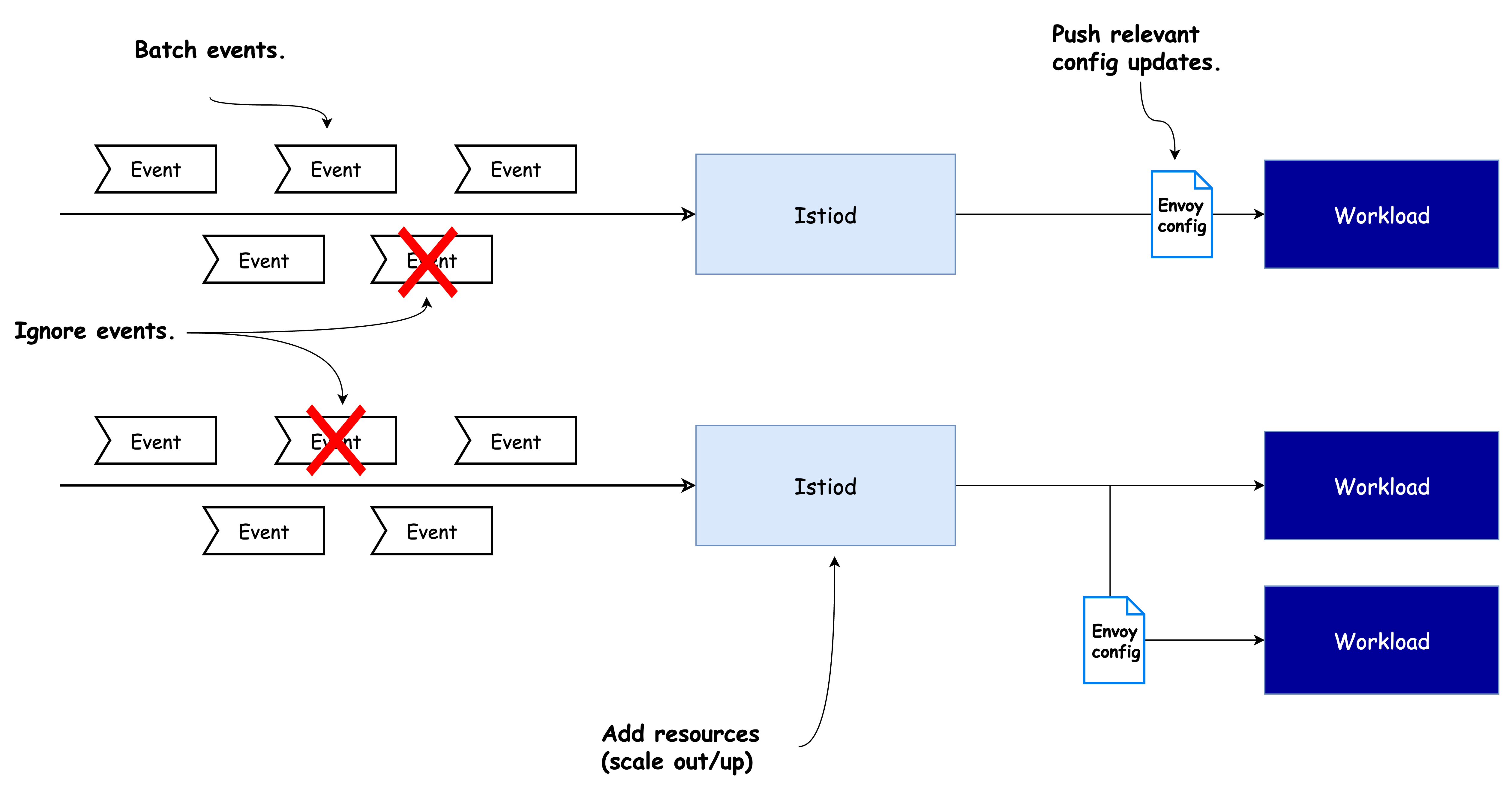
🛠 컨트롤 플레인 성능 향상을 위한 튜닝 포인트
1. 서비스 메시와 관련 없는 이벤트 무시하기
- 예를 들어, Istio와 무관한 네임스페이스의 서비스나 엔드포인트 변경 이벤트는 무시함으로써
이벤트 수신 자체를 줄일 수 있습니다.
2. 이벤트 배치 처리 기간 늘리기
- 디바운스 설정을 조정해 더 많은 변경을 한 번에 묶어서 처리함으로써
푸시 횟수를 줄이고, 불필요한 처리 비용을 줄일 수 있습니다.
3. 리소스 할당량 증가하기
- 스케일 아웃:
istiod디플로이먼트를 수평 확장하여
여러 인스턴스가 워크로드를 나눠 처리하도록 합니다. - 스케일 업: 단일
istiod인스턴스에 더 많은 CPU/메모리를 할당하여
더 빠르게 Envoy 설정을 생성하고 더 많은 요청을 동시에 처리할 수 있도록 합니다.
4. 사이드카 리소스 설정 정의하기
- 각 워크로드가 필요한 리소스만 수신하도록 제한하는
Sidecar리소스를 정의합니다. - 주요 이점:
- 설정 크기 축소: 서비스 프록시로 전달되는 설정이 간결해져 성능이 향상됩니다.
- 푸시 대상 감소: 특정 이벤트 발생 시 영향을 받는 프록시 수가 줄어듭니다.
이러한 조정 방법들을 실습으로 직접 검증하기 위해, 다음 단계에서는 클러스터에 테스트용 서비스를 배포하고 성능 변화 관찰을 위한 테스트 시나리오를 구성해보겠습니다.
✅ 워크스페이스 준비하기: 실습 환경 구성
컨트롤 플레인의 성능을 테스트하고 비교하기 위해,
워크로드 수를 늘리고, 엔보이 설정의 복잡도를 증가시켜
istiod가 처리해야 할 부하를 인위적으로 증가시키는 실험 환경을 구성합니다.
🔧 Step 1: 기본 카탈로그 서비스 및 반복 호출 구성
catalog워크로드와 Gateway, VirtualService 등을 배포합니다.
kubectl -n istioinaction apply -f services/catalog/kubernetes/catalog.yaml
kubectl -n istioinaction apply -f ch11/catalog-virtualservice.yaml
kubectl -n istioinaction apply -f ch11/catalog-gateway.yaml
kubectl get deploy,gw,vs -n istioinactioncatalog서비스를 반복 호출하여 부하를 생성합니다.
while true; do curl -s http://catalog.istioinaction.io:30000/items ; date "+%Y-%m-%d %H:%M:%S" ; sleep 1; echo; doneistiod의 리소스 사용량을 실시간 모니터링합니다.
while true; do kubectl top pod -n istio-system -l app=istiod --containers=true ; date "+%Y-%m-%d %H:%M:%S" ; sleep 1; echo; done💤 Step 2: 더미 워크로드 10개 생성
sleep이라는 이름의 더미 워크로드 10개를 포함한 YAML을 배포합니다.
kubectl -n istioinaction apply -f ch11/sleep-dummy-workloads.yaml- 상태 확인
kubectl get deploy,svc,pod -n istioinaction
docker exec -it myk8s-control-plane istioctl proxy-status
docker exec -it myk8s-control-plane istioctl proxy-config endpoint deploy/catalog.istioinactioncatalog서비스에서sleep서비스의 엔드포인트가 정상 연결(HEALTHY) 상태인지 확인
📈 Step 3: 엔보이 설정 부풀리기 (600 리소스 추가)
Gateway, VirtualService, Service 각각 200개씩 포함된 리소스를 적용해 설정 복잡도를 인위적으로 증가시킵니다.
kubectl -n istioinaction apply -f ch11/resources-600.yaml
# 리소스 개수 확인
kubectl get svc -n istioinaction --no-headers=true | wc -l # → 202개
kubectl get gw,vs -n istioinaction # → 각 200개
# 프록시 설정 정보 상세 확인
docker exec -it myk8s-control-plane istioctl proxy-config listener deploy/catalog.istioinaction
docker exec -it myk8s-control-plane istioctl proxy-config route deploy/catalog.istioinaction
docker exec -it myk8s-control-plane istioctl proxy-config cluster deploy/catalog.istioinaction
docker exec -it myk8s-control-plane istioctl proxy-config endpoint deploy/catalog.istioinaction
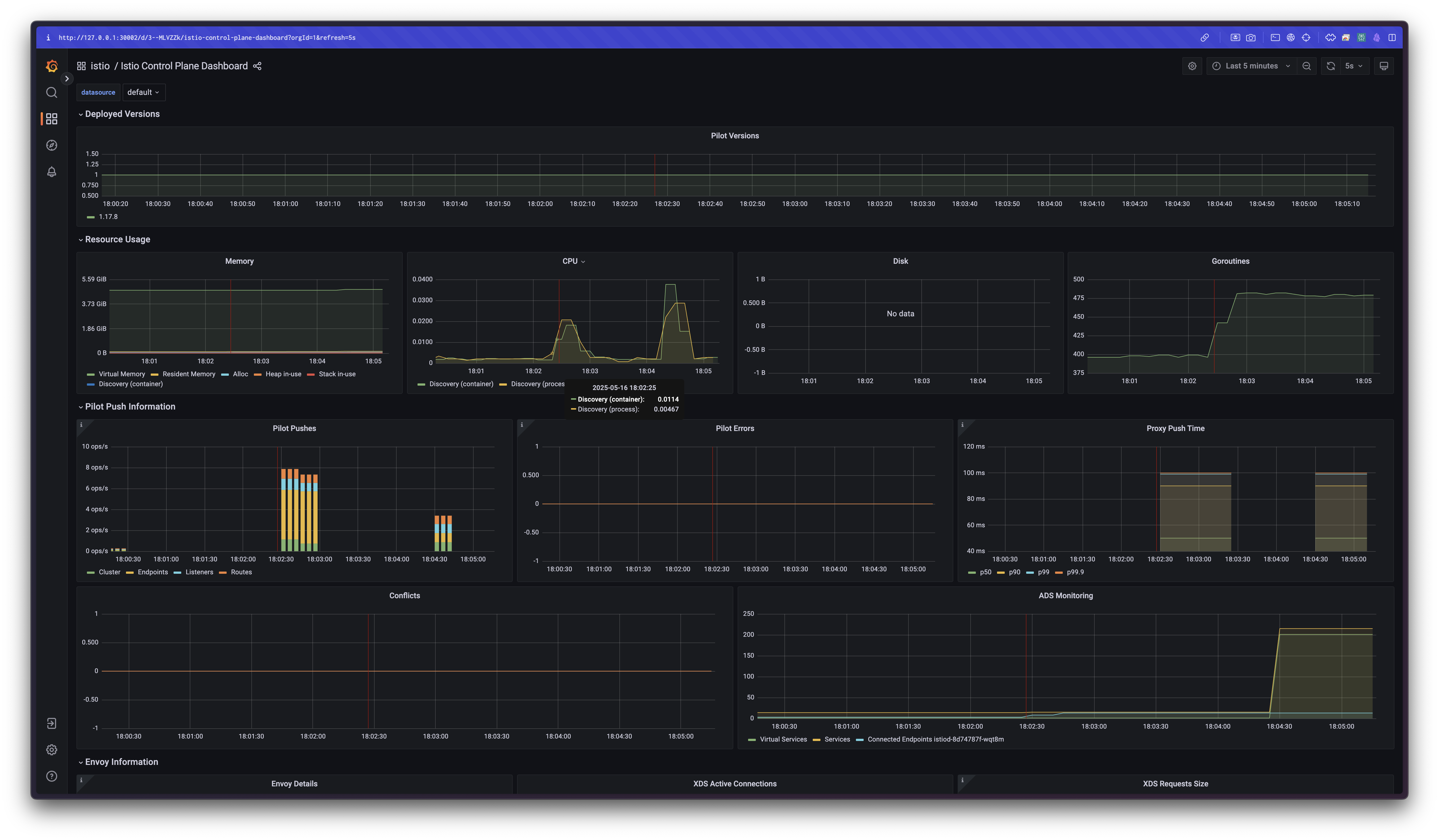
📊 관측 결과
- 그라파나 대시보드의 Last 5 minutes / Last 15 minutes 뷰를 통해
리소스 증가에 따라istiod의 CPU 사용량, 지연 시간, 푸시 횟수 증가를 확인할 수 있습니다.
📌 현재 상태 요약
- 단일
istiod인스턴스가 다음을 관리하고 있습니다:- 13개 워크로드 (Ingress, Egress 포함)
- 600개의 리소스 (Service, VirtualService, Gateway 포함)
이로 인해 istiod는 더 많은 엔보이 설정을 생성해야 하며,
각 워크로드에 푸시하는 설정의 크기 또한 크게 증가합니다.
이는 컨트롤 플레인의 리소스 소모 및 반응 속도에 직접적인 영향을 주는 실험 조건입니다.
✅ 최적화 전 성능 측정하기: Sidecar 적용 전 테스트
🔍 들어가며: 컨트롤 플레인 성능을 평가하는 방법
성능 측정은 다음 요소를 기준으로 합니다:
- 반복적인 서비스 생성을 통해 부하 발생
- 프록시 설정을 업데이트할 때의 Push 횟수
- P99 수렴 지연 시간 (pilot_proxy_convergence_time)
P99란?
P99는 전체 요청 중 99%가 얼마나 빠르게 처리됐는지를 나타냅니다.
예: P99 = 0.45초 → 요청 중 99%는 450ms 이하로 처리됨.
🧪 성능 측정 스크립트: bin/performance-test.sh
해당 스크립트는 다음 기능을 수행합니다:
N개의 랜덤한 Gateway + Service + VirtualService 리소스를 생성- Prometheus를 통해
pilot_proxy_convergence_time메트릭 쿼리 pilot_xds_pushes메트릭 전후 차이로 Push 횟수 계산
스크립트 주요 호출 방식:
./bin/performance-test.sh --reps 10 --delay 2.5 --prom-url prometheus.istio-system.svc.cluster.local:9090🧭 테스트 결과 ①: 기본 설정, 딜레이 포함
# (참고) 호출
curl -H "Host: catalog.istioinaction.io" localhost:30000/items
# 확인
kubectl get svc -n istioinaction --no-headers=true | wc -l
kubectl get gw -n istioinaction --no-headers=true | wc -l
kubectl get vs -n istioinaction --no-headers=true | wc -l
# :30000 포트 정보 추가해둘것!
cat bin/performance-test.sh
...
Poor Man's Performance Test creates Services, Gateways and VirtualServices and measures Latency and Push Count needed to distribute the updates to the data plane.
--reps The number of services that will be created. E.g. --reps 20 creates services [0..19]. Default '20'
--delay The time to wait prior to proceeding with another repetition. Default '0'
--gateway URL of the ingress gateway. Defaults to 'localhost'
--namespace Namespace in which to create the resources. Default 'istioinaction'
--prom-url Prometheus URL to query metrics. Defaults to 'prom-kube-prometheus-stack-prometheus.prometheus:9090'
...
# 성능 테스트 스크립트 실행!
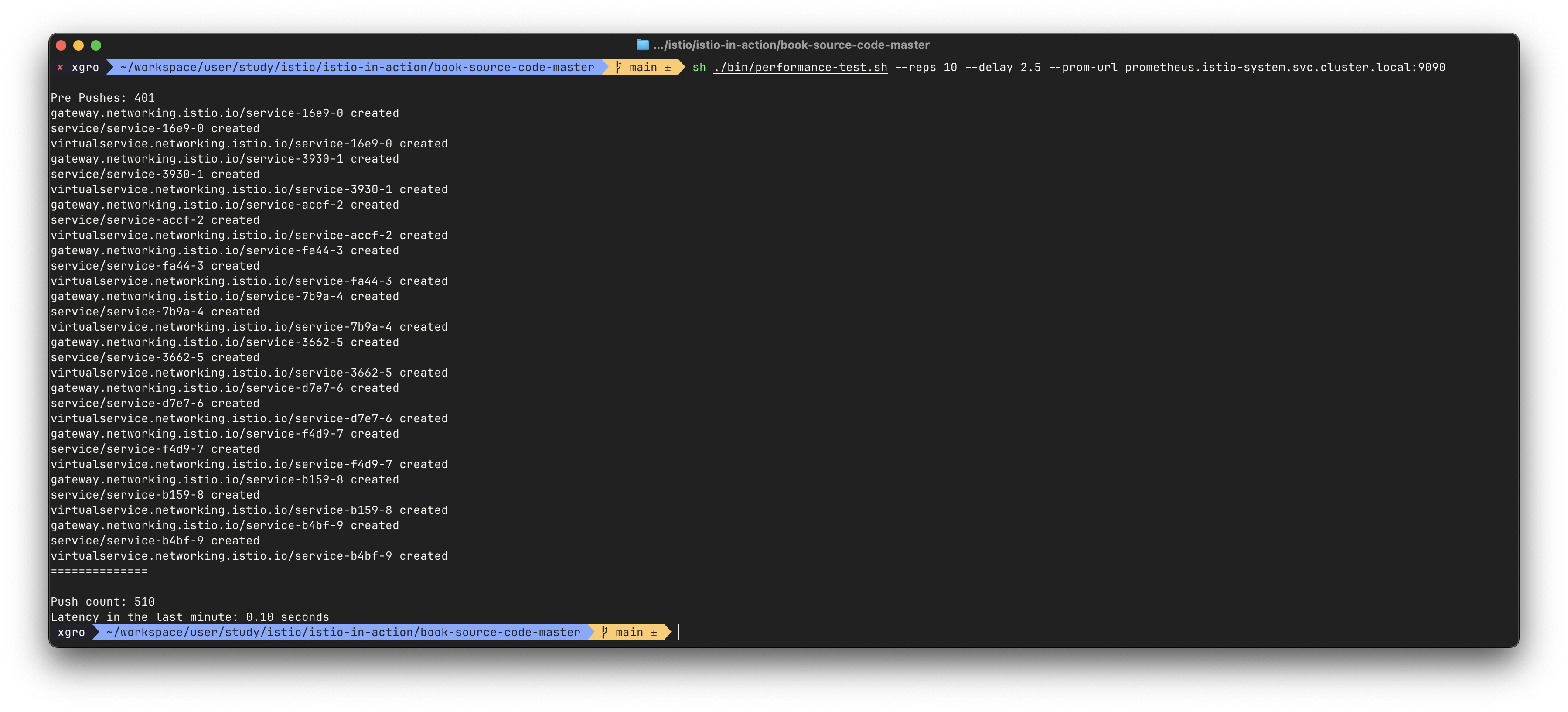
./bin/performance-test.sh --reps 10 --delay 2.5 --prom-url prometheus.istio-system.svc.cluster.local:9090
Pre Pushes: 335
...
ateway.networking.istio.io/service-00a9-9 created
service/service-00a9-9 created
virtualservice.networking.istio.io/service-00a9-9 created
==============
Push count: 510 # 변경 사항을 적용하기 위한 푸시 함수
Latency in the last minute: 0.45 seconds # 마지막 1분 동안의 지연 시간
# 확인
kubectl get svc -n istioinaction --no-headers=true | wc -l
kubectl get gw -n istioinaction --no-headers=true | wc -l
kubectl get vs -n istioinaction --no-headers=true | wc -l-
실행:
--reps 10 --delay 2.5 -
결과:
- Push count: 510
- P99 Latency: 0.1초
그래프 관찰 결과:
- xDS Push 및 Proxy Push Time 증가
- 전체적으로 컨트롤 플레인에 과도한 작업량이 발생함

🧭 테스트 결과 ②: 딜레이 없이 실행
# 성능 테스트 스크립트 실행 : 딜레이 없이
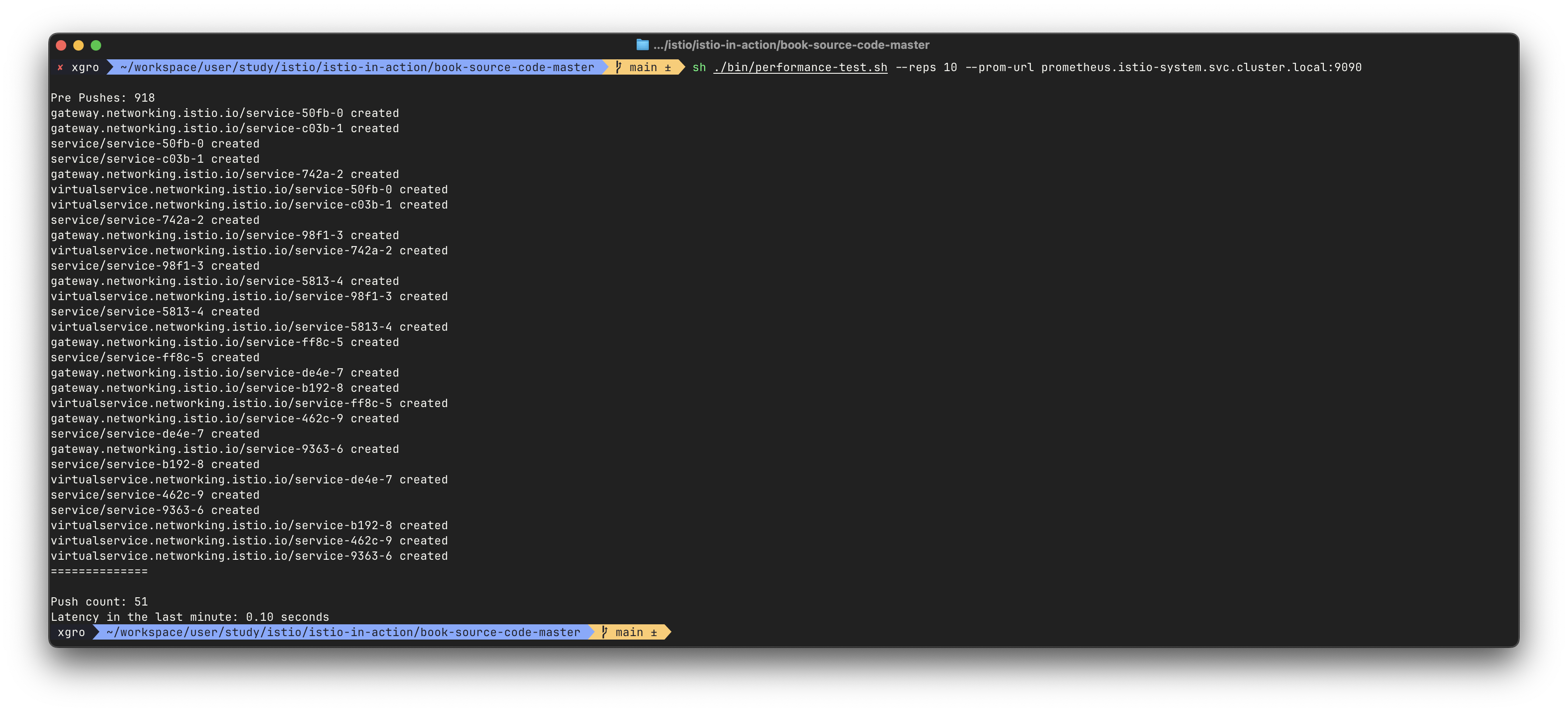
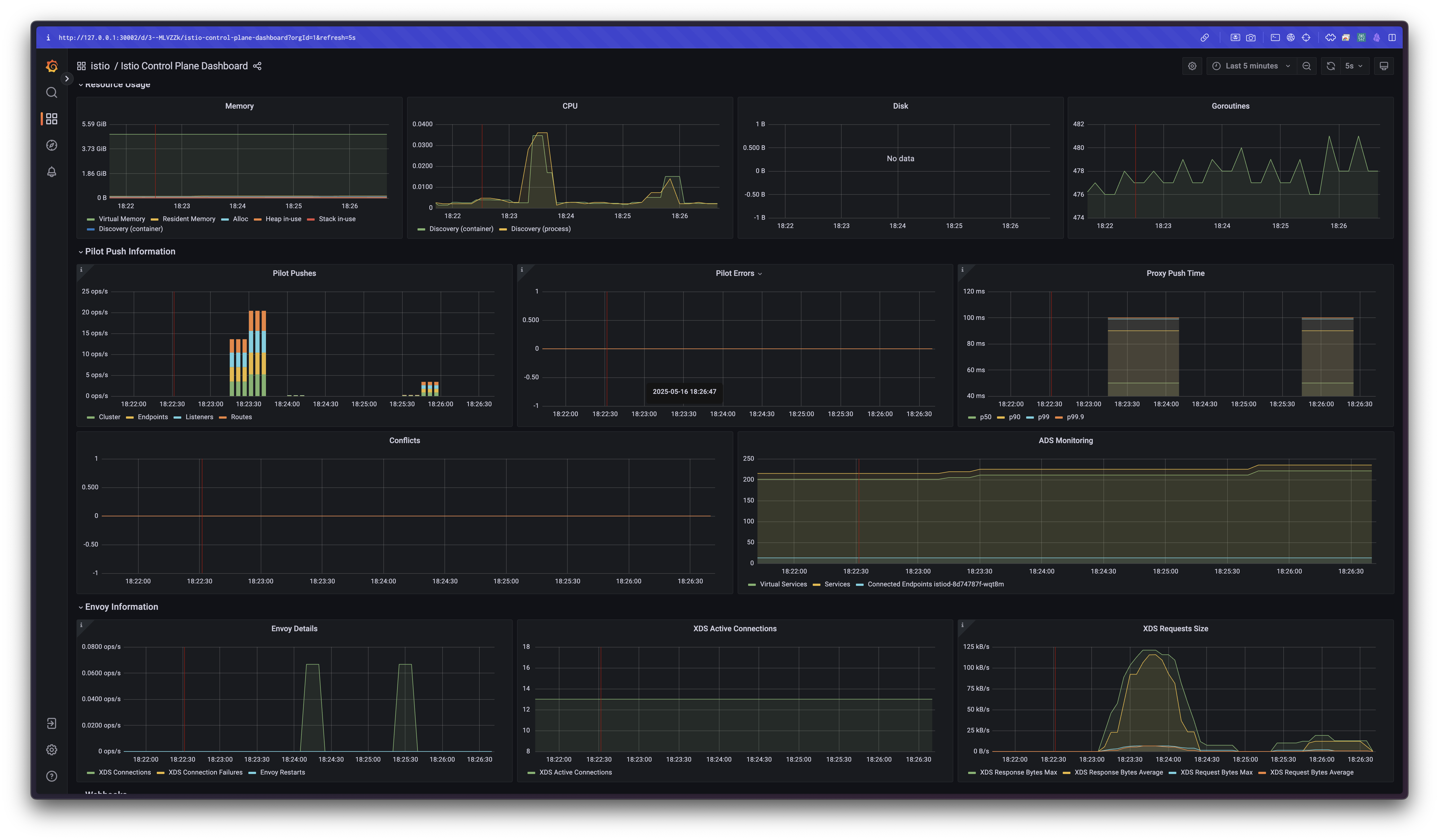
./bin/performance-test.sh --reps 10 --prom-url prometheus.istio-system.svc.cluster.local:9090
Push count: 51
Latency in the last minute: 0.47 seconds
# 확인
kubectl get svc -n istioinaction --no-headers=true | wc -l
kubectl get gw -n istioinaction --no-headers=true | wc -l
kubectl get vs -n istioinaction --no-headers=true | wc -l-
실행:
--reps 10 -
결과:
- Push count: 51
- P99 Latency: 0.1초
배치 처리가 발생하며 Push 수는 감소했으나,
지연 시간은 약간 증가할 수 있습니다.
🧭 테스트 결과 ③: 딜레이 5초로 증가
# 성능 테스트 스크립트 실행 : 딜레이 없이
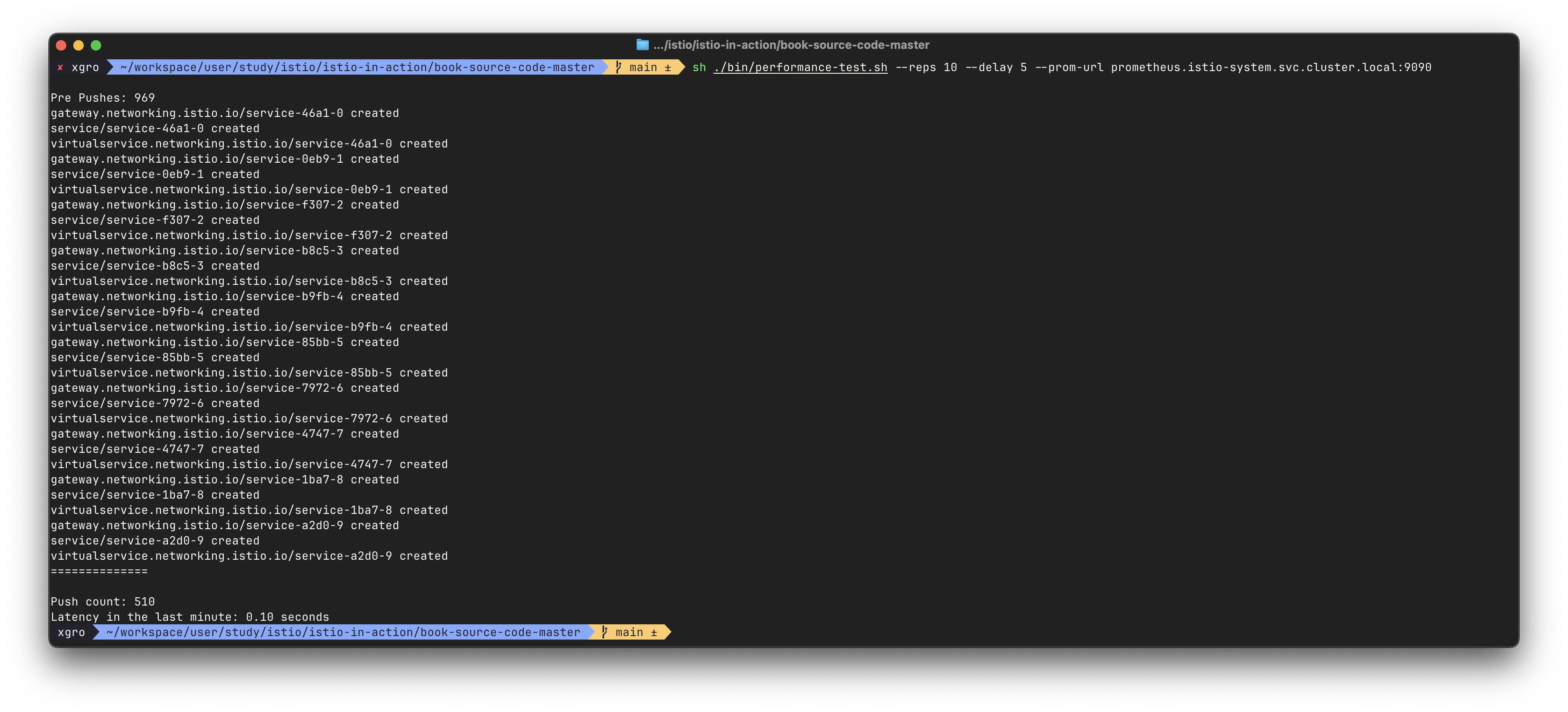
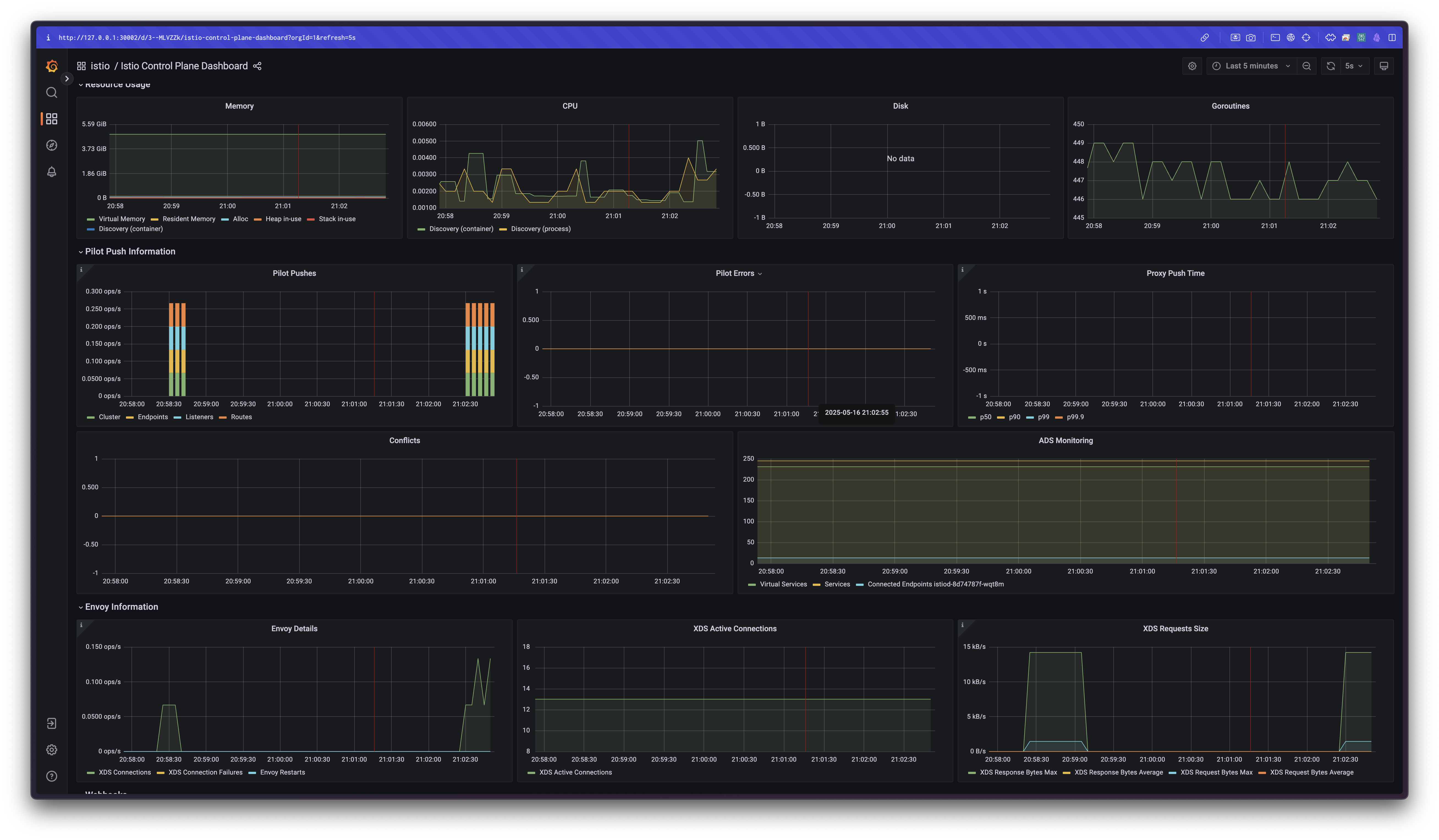
./bin/performance-test.sh --reps 10 --delay 5 --prom-url prometheus.istio-system.svc.cluster.local:9090
Push count: 510
Latency in the last minute: 0.1 seconds-
실행:
--reps 10 --delay 5 -
결과:
- Push count: 510
- P99 Latency: 0.1초
📊 실험 요약
| 조건 | Push 횟수 | P99 지연 시간 |
|---|---|---|
| 딜레이 2.5초 | 510 | 0.45초 |
| 딜레이 없음 | 51 | 0.47초 |
| 딜레이 5초 | 510 | 0.43초 |
- 결론: Push 수는 줄었지만, 설정 복잡도 및 대상 워크로드 수 증가로 인해 성능은 쉽게 저하될 수 있음
✅ 사이드카 리소스를 활용한 최적화
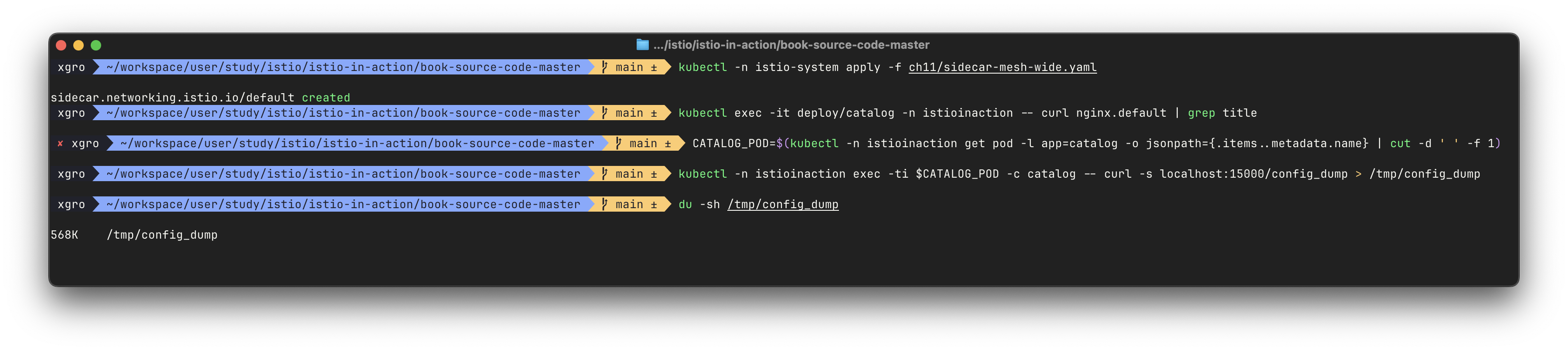
📦 catalog 프록시 설정 크기 확인
CATALOG_POD=$(kubectl -n istioinaction get pod -l app=catalog -o jsonpath={.items..metadata.name} | cut -d ' ' -f 1)
kubectl -n istioinaction exec -ti $CATALOG_POD -c catalog -- curl -s localhost:15000/config_dump > /tmp/config_dump
du -sh /tmp/config_dump
# 결과: 약 1.8MB
#
docker exec -it myk8s-control-plane istioctl proxy-config listener deploy/catalog.istioinaction
docker exec -it myk8s-control-plane istioctl proxy-config route deploy/catalog.istioinaction
docker exec -it myk8s-control-plane istioctl proxy-config cluster deploy/catalog.istioinaction
#
docker exec -it myk8s-control-plane istioctl proxy-config endpoint deploy/catalog.istioinaction
docker exec -it myk8s-control-plane istioctl proxy-config endpoint deploy/catalog.istioinaction | wc -l
275엔드포인트 수: 약 275개
🧰 Sidecar 리소스 예시
apiVersion: networking.istio.io/v1beta1
kind: Sidecar
metadata:
name: default
namespace: istioinaction
spec:
workloadSelector:
labels:
app: foo
egress:
- hosts:
- "./bar.istioinaction.svc.cluster.local"
- "istio-system/*"
outboundTrafficPolicy:
mode: REGISTRY_ONLY🧰 메시 범위 Sidecar 리소스 적용
apiVersion: networking.istio.io/v1beta1
kind: Sidecar
metadata:
name: default
namespace: istio-system
spec:
egress:
- hosts:
- "istio-system/*"
- "prometheus/*"
outboundTrafficPolicy:
mode: REGISTRY_ONLY주의: 메시 전체에 적용되므로 프로덕션에서는 적용 전 협의 필수!
🔍 Sidecar 적용 후 catalog 설정 크기 재확인
모든 서비스 프록시로 전송되는 엔보이 설정을 줄여 컨트롤 플레인 성능을 개선할 수 있는 가장 쉬운 방법은 트래픽 송신을 istio-system 네임스페이스의 서비스로만 허용하는 사이드카 설정을 메시 범위로 정의하는 방법입니다.
기본값을 이렇게 정의하면, 최소 설정으로 메시 내 모든 프록시가 컨트롤 플레인에만 연결하도록 하고 다른 서비스로의 연결 설정은 모두 삭제할 수 있습니다.
다음 사이드카 정의를 사용하면, 메시 내 모든 서비스 사이트가가 istio-system 네임스페이스에 있는 이스티오 서비스로만 연결하도록 설정할 수 있습니다. (메트릭을 수집할 수 있드록 프로메테우스 네임스페이스도 연결한다)
- 이제 컨트롤 플레인은 서비스 프록시가 istio-system / prometheus 네임스페이스의 서비스로 연결할 수 있는 최소한의 설정만 갖도록 업데이트 합니다.
- 우리의 가설이 맞다면, catalog 워크로드의 엔보이 설정 크기는 현저히 줄어야 합니다. 확인해보겠습니다.
# 테스트를 위해 샘플 nginx 배포
cat << EOF | kubectl apply -f -
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
labels:
app: nginx
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:alpine
ports:
- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: nginx
spec:
selector:
app: nginx
ports:
- protocol: TCP
port: 80
targetPort: 80
type: ClusterIP
EOF
# catalog 에서 nginx 서비스 접속 확인
docker exec -it myk8s-control-plane istioctl proxy-config route deploy/catalog.istioinaction | grep nginx
docker exec -it myk8s-control-plane istioctl proxy-config cluster deploy/catalog.istioinaction | grep nginx
docker exec -it myk8s-control-plane istioctl proxy-config endpoint deploy/catalog.istioinaction | grep nginx
10.10.0.26:80 HEALTHY OK outbound|80||nginx.default.svc.cluster.local
kubectl exec -it deploy/catalog -n istioinaction -- curl nginx.default | grep title
<title>Welcome to nginx!</title>
# istio-system, prometheus 네임스페이스만 egress 허용 설정
kubectl -n istio-system apply -f ch11/sidecar-mesh-wide.yaml
kubectl get sidecars -A
# catalog 에서 nginx 서비스 접속 확인
docker exec -it myk8s-control-plane istioctl proxy-config route deploy/catalog.istioinaction | grep nginx
docker exec -it myk8s-control-plane istioctl proxy-config cluster deploy/catalog.istioinaction | grep nginx
docker exec -it myk8s-control-plane istioctl proxy-config endpoint deploy/catalog.istioinaction | grep nginx
kubectl exec -it deploy/catalog -n istioinaction -- curl nginx.default | grep title
# envoy config 크기 다시 확인!
CATALOG_POD=$(kubectl -n istioinaction get pod -l app=catalog -o jsonpath={.items..metadata.name} | cut -d ' ' -f 1)
kubectl -n istioinaction exec -ti $CATALOG_POD -c catalog -- curl -s localhost:15000/config_dump > /tmp/config_dump
du -sh /tmp/config_dump
520K /tmp/config_dump설정 크기 1.8MB → 568KB 로 대폭 감소
✅ 성능 테스트 재실행
./bin/performance-test.sh --reps 10 --delay 2.5 --prom-url prometheus.istio-system.svc.cluster.local:9090
# 결과:
# Push count: 70
# Latency: 0.10초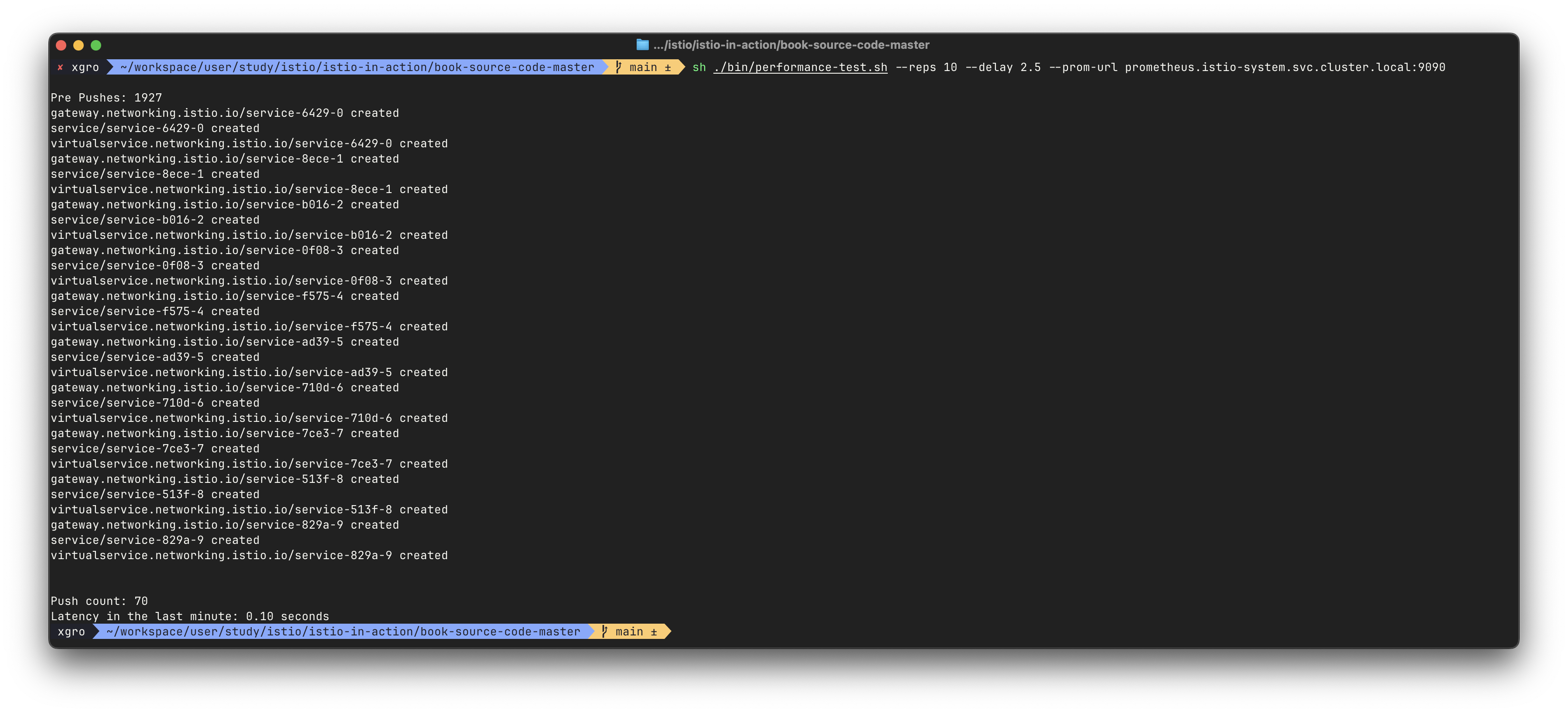
🏁 최종 정리
| 조건 | Push 횟수 | P99 지연 시간 | 설정 크기 |
|---|---|---|---|
| 최적화 전 (딜레이 2.5초) | 510 | 0.10초 | 1.8MB |
| 메시 범위 Sidecar 적용 후 | 70 | 0.10초 | 520KB |
- Push 횟수 및 설정 크기 대폭 감소
- 컨트롤 플레인 부하 감소
- 성능 최적화 입증 완료
📌 참고: 사이드카 리소스 범위
| 범위 | 네임스페이스 | 설명 | 우선순위 |
|---|---|---|---|
| mesh-wide | istio-system | 메시 전체 기본값 지정 | 낮음 |
| namespace-wide | 사용자 정의 네임스페이스 | 해당 네임스페이스에 적용 | 중간 |
| workload-specific | workloadSelector 사용 | 특정 워크로드 대상 설정 | 높음 |
✅ 이벤트 무시하기: 디스커버리 셀렉터로 디스커버리 범위 줄이기 (meshConfig.discoverySelectors)
🔍 기본 동작: 모든 네임스페이스 이벤트 감시
Istio 컨트롤 플레인은 기본적으로 클러스터의 모든 네임스페이스에 존재하는 파드, 서비스 등 리소스의 생성 이벤트를 감시합니다.
이는 대규모 클러스터일수록 불필요한 오버헤드로 작용하며, 모든 이벤트마다 Envoy 설정을 다시 생성해야 하므로 컨트롤 플레인 부하가 증가합니다.
🛠 디스커버리 셀렉터(Discovery Selector)의 도입
-
Istio 1.10부터는
discoverySelectors기능이 도입되어,
컨트롤 플레인이 감시할 네임스페이스를 선택적으로 제한할 수 있습니다. -
이 기능은 다음과 같은 상황에서 유용합니다:
-
메시가 절대 라우팅하지 않을 불필요한 워크로드
-
Spark job처럼 반복적으로 생성/종료되는 워크로드
-
✅ 사용 방법 ①: 특정 네임스페이스에만 포함 (matchLabels)
apiVersion: install.istio.io/v1alpha1
kind: IstioOperator
metadata:
namespace: istio-system
spec:
meshConfig:
discoverySelectors:
- matchLabels:
istio-discovery: enabledistio-discovery: enabled레이블이 있는 네임스페이스만 포함됩니다.- 그 외 네임스페이스는 자동으로 무시됩니다.
✅ 사용 방법 ②: 일부 네임스페이스만 제외 (matchExpressions)
apiVersion: install.istio.io/v1alpha1
kind: IstioOperator
metadata:
namespace: istio-system
spec:
meshConfig:
discoverySelectors:
- matchExpressions:
- key: istio-exclude
operator: NotIn
values:
- "true"istio-exclude=true레이블이 있는 네임스페이스는 제외- 나머지 네임스페이스는 포함
공식 문서 참고: discoverySelectors - Istio MeshConfig
🧪 실습 예시
- 새로운 네임스페이스 생성 및 사이드카 주입 활성화
kubectl create ns new-ns
kubectl label namespace new-ns istio-injection=enabled
kubectl get ns --show-labels- Nginx 워크로드 배포
cat << EOF | kubectl apply -n new-ns -f -
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
labels:
app: nginx
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:alpine
ports:
- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: nginx
spec:
selector:
app: nginx
ports:
- protocol: TCP
port: 80
targetPort: 80
type: ClusterIP
EOF- Istio Ingress에서 Nginx 인지 여부 확인
docker exec -it myk8s-control-plane istioctl proxy-config endpoint deploy/istio-ingressgateway.istio-system | grep nginx
# nginx.new-ns.svc.cluster.local이 보이면 감시되고 있는 상태istio-exclude: true레이블 추가 후 다시 확인
kubectl label ns new-ns istio-exclude=true
kubectl get ns --show-labels
# 다시 확인 (이제 nginx.new-ns는 보이지 않아야 함)
docker exec -it myk8s-control-plane istioctl proxy-config endpoint deploy/istio-ingressgateway.istio-system | grep nginx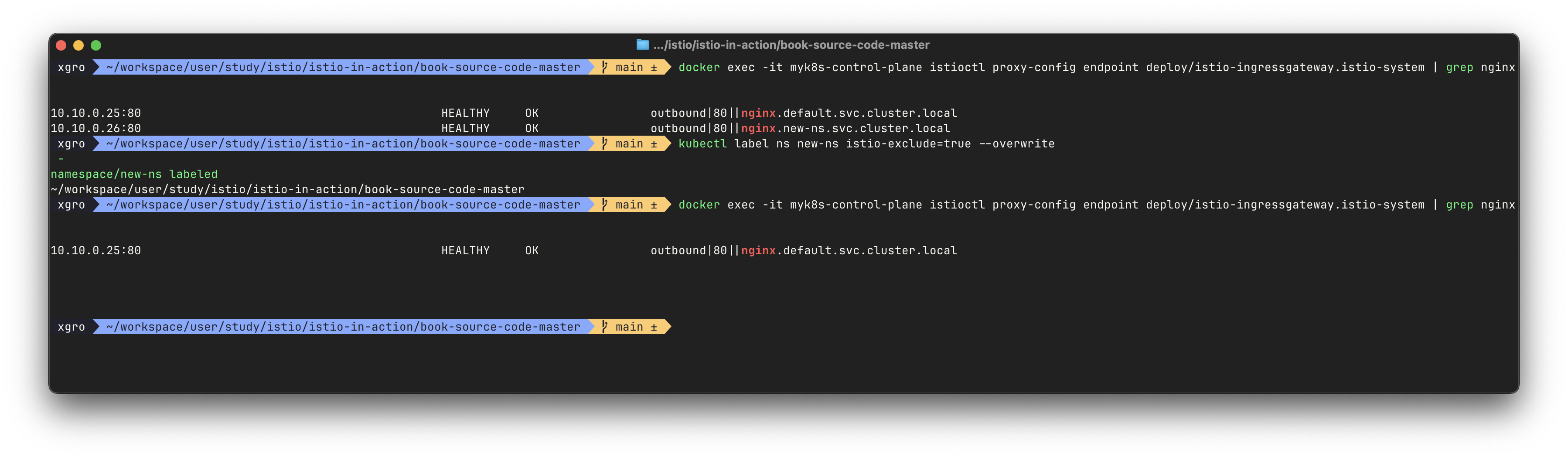
discoverySelectors를 통해 디스커버리 범위를 효과적으로 줄이면, 컨트롤 플레인의 부하를 줄일 수 있습니다.
그럼에도 여전히 포화 상태라면 이벤트를 개별적으로 처리하는 대신, 배치 처리(batch processing) 하는 방식을 고려해야 합니다.
✅ 이벤트 배치 처리 및 푸시 스로틀링 속성
Event-batching and push-throttling properties
데이터 플레인 설정 변경을 유발하는 이벤트는 대부분 운영자가 직접 제어할 수 없습니다.
예: 새로운 서비스의 생성, 복제본 스케일 아웃, 서비스 비정상 상태 전이 등
Istio 컨트롤 플레인은 이러한 이벤트들을 감지하고 데이터 플레인 프록시에 반영합니다.
하지만 이벤트가 감지된 후 얼마만큼 지연시켜 배치 처리할지는 제어할 수 있습니다. 이는 업데이트 효율성과 컨트롤 플레인 부하를 조절하는 중요한 수단이 됩니다.
📦 이벤트 배치 처리의 장점
-
이벤트를 묶음(batch)으로 처리하면,
- 한 번의 Envoy 설정 생성을 통해
- 여러 이벤트를 동시에 데이터 플레인 프록시에 반영할 수 있습니다.
-
아래 그림은 이벤트 수신 이후 디바운스(debounce) 로직에 따라
푸시 시점이 어떻게 조정되는지를 시각화한 순서도입니다.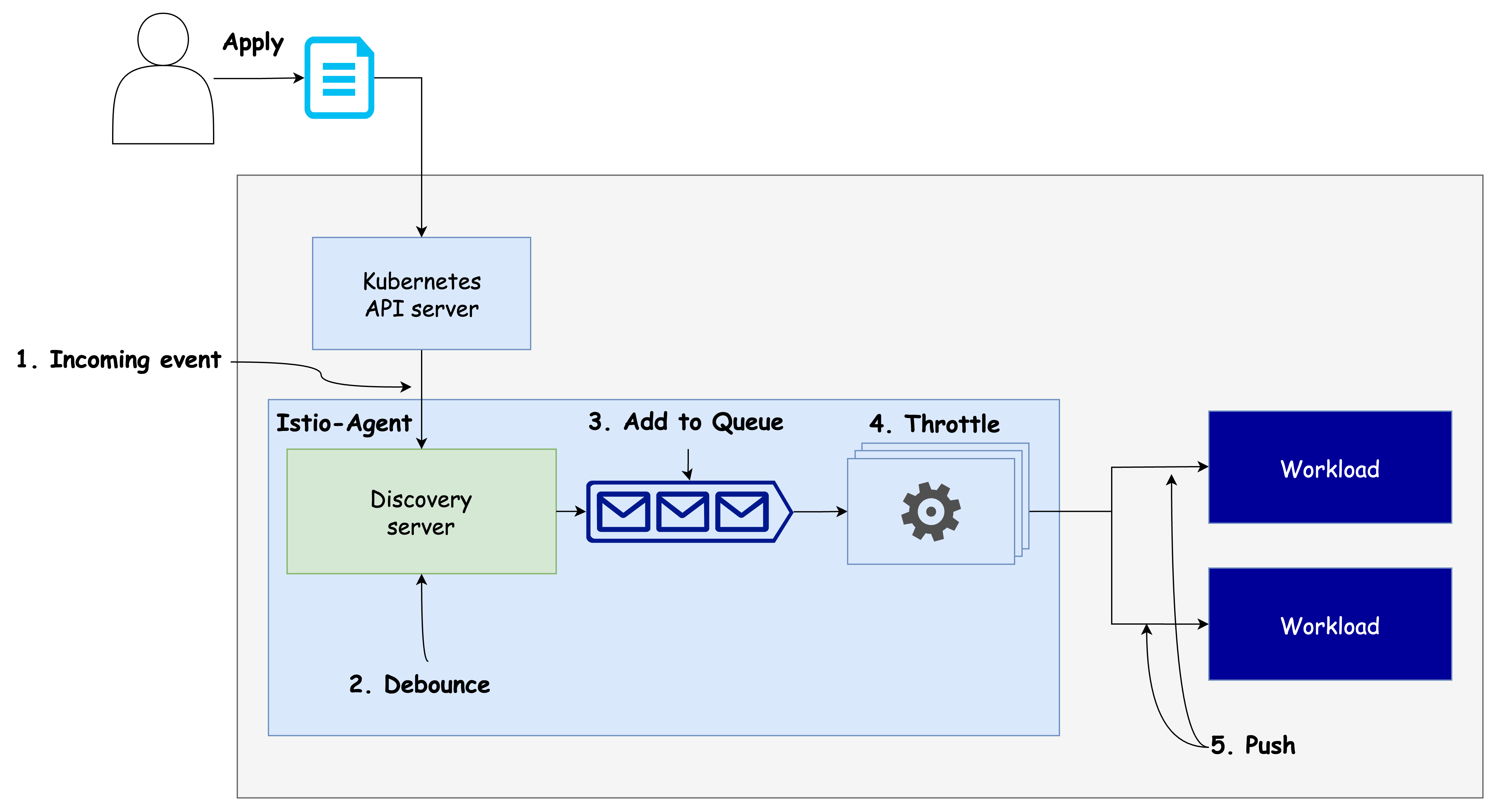
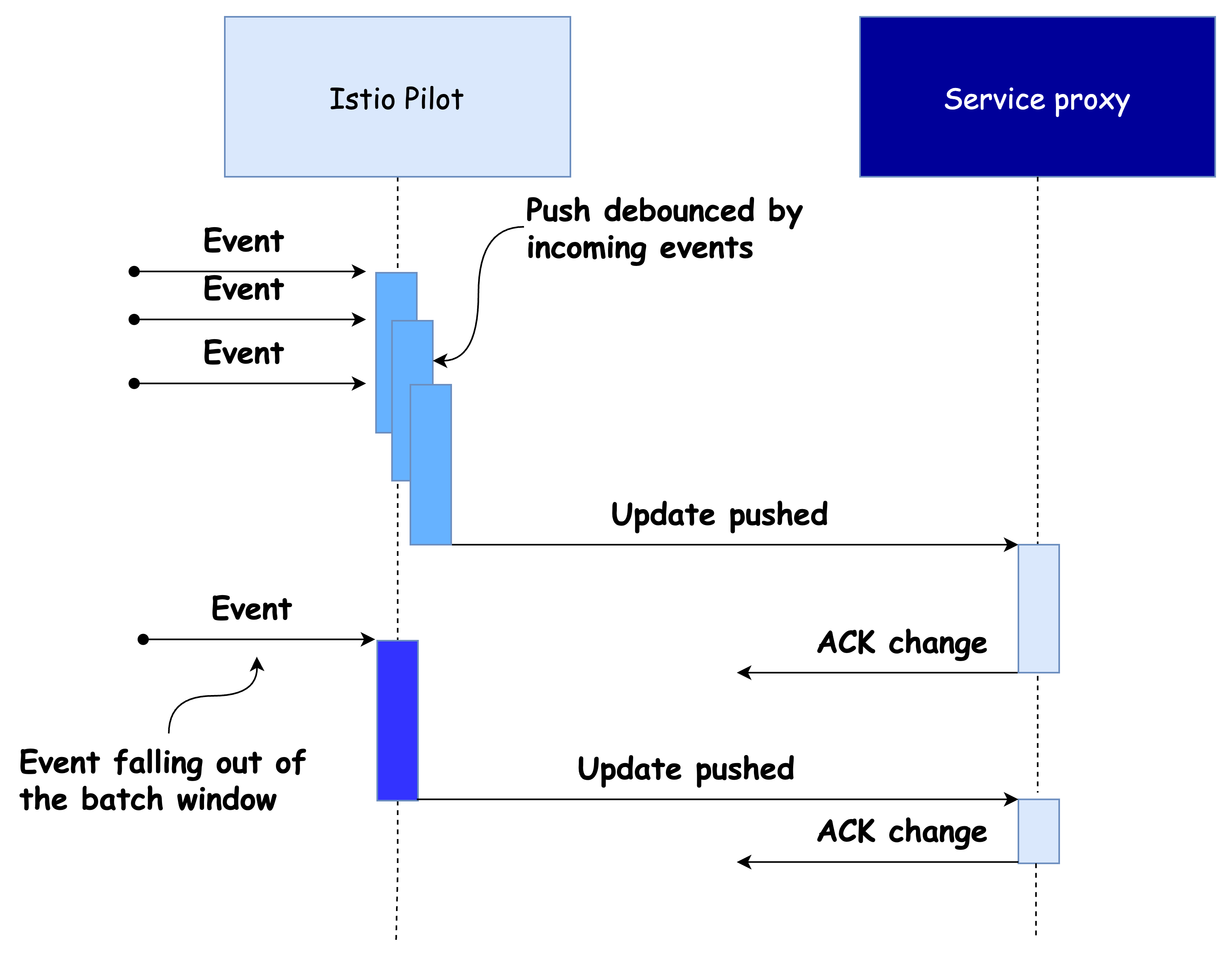
⚖️ 디바운스 기간 조절의 트레이드오프
-
디바운스 기간을 늘리면
- 마지막 이벤트까지 모든 이벤트를 하나의 배치로 합칠 수 있어 푸시 횟수를 줄일 수 있음.
- 결과적으로 컨트롤 플레인 효율성 증가.
-
디바운스 기간을 너무 길게 설정하면
- 프록시가 오래된 설정을 유지하게 되어 데이터 플레인 상태가 불일치할 수 있음.
-
디바운스 기간을 줄이면
- 최신 상태를 더 빠르게 반영할 수 있으나,
- 푸시 요청이 많아지면서 컨트롤 플레인 대기열이 길어지고 스로틀링이 발생함.
🧠 결론
- 이벤트 배치 처리와 푸시 스로틀링은 컨트롤 플레인 성능을 조정하는 중요한 속성입니다.
- 클러스터 규모, 이벤트 발생률, 실시간성 요구사항을 바탕으로 디바운스 타이밍을 전략적으로 조정하는 것이 중요합니다.
✅ 배치 기간과 푸시 스로틀링을 정의하는 환경 변수
ENVIRONMENT VARIABLES THAT DEFINE THE BATCHING PERIOD AND PUSH THROTTLING
🔧 주요 환경 변수 목록
-
PILOT_DEBOUNCE_AFTER
- 이벤트를 푸시 대기열에 추가하기 전 디바운스할 시간을 정의합니다.
- 기본값은 100ms로, 이벤트 발생 후 100ms 동안 추가 이벤트가 없을 경우 푸시 대기열에 등록됩니다.
- 만약 그 사이 또 다른 이벤트가 발생하면, 해당 이벤트는 기존 배치에 병합되며 디바운스 타이머가 다시 시작됩니다.
-
PILOT_DEBOUNCE_MAX
- 디바운스가 허용되는 최대 시간을 지정합니다.
- 기본값은 10초이며, 이 시간이 지나면 이벤트 병합 여부와 무관하게 대기열에 강제로 푸시됩니다.
-
PILOT_ENABLE_EDS_DEBOUNCE
- 엔드포인트 업데이트도 디바운스 대상에 포함할지 여부를 설정합니다.
- 기본값은
true이며, 엔드포인트 업데이트도 디바운스 규칙을 따릅니다. false로 설정하면, 엔드포인트 이벤트는 즉시 푸시 대기열에 등록됩니다.
-
PILOT_PUSH_THROTTLE
- istiod가 동시에 처리할 수 있는 푸시 요청의 최대 개수를 정의합니다.
- 기본값은
100이며, 이 값을 줄이면 컨트롤 플레인의 동시성 부담을 줄일 수 있고, 높이면 업데이트 전파 속도는 향상됩니다.
📌 일반적인 설정 가이드
| 상황 | 조정 지침 |
|---|---|
| 컨트롤 플레인이 포화 상태이고 수신 트래픽이 병목의 원인일 때 | 이벤트 배치 처리 시간(PILOT_DEBOUNCE_AFTER)을 늘려라 |
| 업데이트 전파 속도가 중요한 상황 | 배치 처리 시간을 줄이고, 동시 푸시 개수(PILOT_PUSH_THROTTLE)는 늘려라 단, 컨트롤 플레인이 포화 상태가 아닐 때에만 |
| 컨트롤 플레인이 포화 상태이고 송신 트래픽이 병목의 원인일 때 | 동시 푸시 개수를 줄여라 |
| 컨트롤 플레인이 포화 상태가 아니거나, 이미 스케일 업한 경우 | 업데이트 반영을 빠르게 하기 위해 동시 푸시 개수를 늘려라 |
✅ 배치 기간 늘리기
INCREASING THE BATCHING PERIOD
배치의 효과를 확인하기 위해 PILOT_DEBOUNCE_AFTER 값을 기본값인 100ms(0.1초) 에서 2.5초(2500ms) 로 말도 안 되게 높게 설정합니다.
※ 이는 운영 환경에서 절대 권장되지 않는 실습용 설정입니다.
# myk8s-control-plane 컨트롤 노드에 진입 후 실행
docker exec -it myk8s-control-plane bash
# Istio 컨트롤 플레인 재설치 (demo 프로파일 사용, 디바운스 시간 2.5초 지정)
istioctl install \
--set profile=demo \
--set values.pilot.env.PILOT_DEBOUNCE_AFTER="2500ms" \
--set values.global.proxy.privileged=true \
--set meshConfig.accessLogEncoding=JSON \
-y
exit- 정상 반영 여부 확인
kubectl get deploy/istiod -n istio-system -o yaml
# 결과 예시
...
- name: PILOT_DEBOUNCE_AFTER
value: "2500ms"
...🎯 성능 테스트 실행
# 기존 성능 테스트 스크립트를 그대로 실행
./bin/performance-test.sh --reps 10 --delay 2.5 --prom-url prometheus.istio-system.svc.cluster.local:9090
# 결과 예시
Push count: 28
Latency in the last minute: 0.10 seconds- 배치 기간이 늘어나면서 이벤트 병합 효과가 커져 푸시 횟수가 줄었습니다.
PILOT_DEBOUNCE_MAX설정값을 초과하지 않는 한 모든 이벤트는 병합되어 푸시 큐에 추가됩니다.- 덕분에 단 28회의 푸시만으로도 모든 리소스 변경 사항이 반영되었으며,
Envoy 설정 생성과 전송 과정이 줄어들어 CPU와 네트워크 리소스도 절약되었습니다.
🧠 유의사항
이 예시는 디바운스 효과의 원리를 설명하기 위한 실험적 구성입니다.
운영 환경에서는 2.5초와 같은 긴 디바운스 설정은 지양해야 합니다.
Istio 컨트롤 플레인의 설정은 반드시 관찰 가능한 메트릭과 실제 트래픽 특성에 맞춰 미세하게 조정해야 하며, 대규모 변경보다는 점진적인 튜닝이 바람직합니다.
✅ 지연 시간 메트릭은 디바운스 기간을 고려하지 않는다!
LATENCY METRICS DO NOT ACCOUNT FOR THE DEBOUNCE PERIOD!
디바운스 기간을 늘리면 실제 업데이트 전파 시간은 늘어나지만 지연 시간 메트릭(latency metric)에는 그 효과가 반영되지 않습니다.
이는 지연 시간 메트릭이 푸시 요청이 푸시 대기열에 추가된 시점부터의 시간만 측정하기 때문입니다.
즉, 디바운스 시간은 측정에 포함되지 않습니다.
✔️ 푸시 대기열에 들어간 이후의 작업만 latency 메트릭으로 측정된다.
❌ 디바운스 중 대기한 시간은 latency 지표에 포함되지 않는다.따라서 지연 시간 메트릭만 보고 성능이 좋은 줄 착각할 수 있습니다.
예시: 푸시가 실제로는 2초 뒤에 수행됐지만 지표 상에는 10ms로 나타남
이처럼 디바운스 시간이 지나치게 길어지면 엔보이 설정이 낡고(stale), 서비스 최신 상태와 불일치하는 문제가 발생할 수 있습니다.
이는 결과적으로 낮은 성능 상태에서의 푸시 지연과 동일한 문제를 야기합니다.
디바운스 관련 설정 변경은 점진적으로 수행하는 것이 권장됩니다.
💡 참고: 데이터 플레인은 일반적으로 늦은 엔드포인트 업데이트에 영향을 받기 쉽습니다.
# 환경 변수 설정
PILOT_ENABLE_EDS_DEBOUNCE=false위 설정은 엔드포인트 업데이트에 대해서는 디바운스 기간을 무시하도록 강제합니다.
즉시 푸시가 수행되어, 엔드포인트 상태 반영이 지연되지 않도록 보장할 수 있습니다.
✅ 컨트롤 플레인에 리소스 추가 할당하기
ALLOCATING ADDITIONAL RESOURCES TO THE CONTROL PLANE
Sidecar 리소스를 정의하고, discoverySelectors를 설정하고, 이벤트 배치를 조정한 이후 성능을 더 개선하려면 컨트롤 플레인에 리소스를 더 할당해야 합니다.
리소스를 더 할당하는 방식은 두 가지입니다:
- 스케일 아웃 (Scale Out): istiod 인스턴스를 여러 개로 늘려서 부하 분산
- 스케일 업 (Scale Up): 각 인스턴스의 CPU, Memory 리소스를 증가
병목에 따라 리소스 할당 전략
-
송신 트래픽이 병목일 때 → 스케일 아웃
- 워크로드가 너무 많아 istiod 한 인스턴스당 과부하일 때 발생
- 여러 인스턴스로 나눠 관리하면 푸시 대상 분산 가능
-
수신 트래픽이 병목일 때 → 스케일 업
- 엔보이 설정을 만들 때 처리해야 할 리소스(Service, VS 등)가 너무 많을 때
- istiod의 처리 능력 자체를 향상시켜야 함
리소스 할당 명령 예시
# 현재 istiod 리소스 확인
kubectl get pod -n istio-system -l app=istiod
kubectl describe pod -n istio-system -l app=istiod
# CPU/MEM 사용률 체크
kubectl resource-capacity -n istio-system -u -l app=istiod
# 예시 출력 (스케일 전)
Requests:
cpu: 10m
memory: 100Mi
# istio 설치 시, 리소스 요청 및 replica 수 지정
docker exec -it myk8s-control-plane bash
-----------------------------------
istioctl install --set profile=demo \
--set values.pilot.resources.requests.cpu=1000m \
--set values.pilot.resources.requests.memory=1Gi \
--set values.pilot.replicaCount=2 -y
exit
-----------------------------------
# 결과 확인
kubectl get pod -n istio-system -l app=istiod
kubectl describe pod -n istio-system -l app=istiod
kubectl resource-capacity -n istio-system -u -l app=istiod최적화 요약 가이드
-
✅ 항상 Sidecar 리소스를 정의하라
→ 대부분의 설정 크기 감소 효과는 여기서 온다 -
✅ 이벤트 배치 설정은 마지막 수단
→ 이미 리소스를 충분히 줬는데도 성능이 안 나올 때만 조정 -
✅ 송신 트래픽 병목 시 → 스케일 아웃
→ istiod가 너무 많은 프록시에 푸시를 하느라 느릴 경우 -
✅ 수신 트래픽 병목 시 → 스케일 업
→ 설정 생성 연산 자체가 무거운 경우
🔁 스케일 아웃 = istiod 인스턴스 늘리기
⏫ 스케일 업 = 각 인스턴스의 리소스(CPU/MEM) 올리기👉 Step 04. 성능 튜닝 가이드라인
이스티오는 기본 성능이 매우 뛰어난 서비스 메시입니다.
이스티오 팀은 다음과 같은 기준으로 성능을 테스트합니다:
- Kubernetes 서비스 1,000개 → Envoy 설정 부풀림
- 워크로드 2,000개 → 동기화 대상
- 초당 요청 70,000개 → 메시 전체 요청량
이 정도 부하에서도 단일 이스티오 파일럿 인스턴스는 vCPU 1개, 메모리 1.5GB만 사용합니다.
일반적인 운영 환경에서는 replica 3개, vCPU 2개 / Mem 2GB 정도면 충분합니다.
✅ 컨트롤 플레인 성능 튜닝 가이드라인
성능 문제인지 먼저 확인하기
지연이 발생하는 원인이 Istio 때문인지 아니면 다른 플랫폼(예: K8S API Server) 때문인지 확인합니다.
다음 항목을 먼저 체크:
- 데이터 플레인에서 컨트롤 플레인으로 연결이 정상인가?
- 플랫폼 문제는 아닌가?
- Sidecar 리소스를 정의했는가?
성능 병목 지점 파악하기
지연 시간, 포화도, 트래픽 메트릭을 기준으로 판단 합니다.
예시 시나리오와 대응:
- 컨트롤 플레인이 포화 상태가 아닌데 지연 시간이 증가함
→ 리소스가 최적으로 사용되지 않음
→ 동시 푸시 수를 늘려보자- 낮은 사용률인데 갑자기 포화
→ 짧은 시간에 폭발적인 변경 발생
→ replica 수를 늘리거나, 배치 속성 조정- 변경은 반드시 점진적으로
→ 한 번에 10~30% 정도만 변경
→ 변경 후 수일 동안 모니터링 후 재조정
안정성 최우선
Pilot는 메시 전체 네트워크를 관리하므로 다운 시 전체 중단 가능성 존재합니다.
운영 시 가이드라인:
- 리소스는 관대하게 할당
- replica는 항상 2개 이상
- 설정 변경은 스테이징 환경에서 먼저 검증
버스트 가능한 인스턴스 고려하기
istiod는 지속적인 고성능이 아닌 일시적 처리량을 요구합니다.
burstable VM을 사용하면 자원 효율적으로 운영 가능 합니다.
📌 Conclusion
이번 블로그에서는 Istio 컨트롤 플레인의 성능을 측정, 분석, 개선하는 전 과정을 실습 중심으로 정리해보았습니다.
단순히 메트릭을 보는 것을 넘어서, 실제로 시스템을 부하시키고 이를 기준으로 성능 병목을 진단하고, Sidecar 설정, 디스커버리 셀렉터, 이벤트 배치, 푸시 스로틀링, 리소스 재할당과 같은 구체적인 개선 전략까지 실행해보았습니다.
특히 다음과 같은 인사이트는 많은 메시 운영자에게 도움이 될 수 있습니다:
- 모든 설정을 모든 프록시에 전달하는 기본 동작은 성능 낭비로 이어질 수 있다.
- Sidecar 리소스를 통해 관련 설정만 푸시하게 만들면 푸시 횟수, 설정 크기 모두 줄어든다.
- 지연 시간 메트릭만 보고 판단하면 안 된다. 디바운스 지연은 측정 대상이 아니기 때문이다.
- 디버깅에는 그라파나 대시보드와 Prometheus 쿼리 메트릭이 핵심 도구다.
- 튜닝은 단순히 성능 최적화 목적이 아니라, 운영 비용 절감과 안정성을 위한 필수 과정이다.
Istio는 기본 성능이 매우 우수하지만, 메시 규모가 커지고 다양한 워크로드가 동시 운영되는 복잡한 환경에서는 적극적인 튜닝이 필요합니다.
이번 실습을 통해 실제 운영 중인 메시에서 컨트롤 플레인을 어떻게 효율적으로 다룰지 감을 잡을 수 있길 바랍니다.
