
Abstract
- context와 응답 후보 몇개를 주면, 모델은 context에 가장 적합한 응답을 찾아준다.
- 멀티턴 응답 선택을 위해 RCMN이라는 기존 딥 러닝 모델을 발전시켜 사용한다.
- SMN과 변형시킨 RCMN 모델 두개를 앙상블했다.
Model
만약 모델이 두 문장 사이에 관련성에 대해 생각하지 않는다면, 관련성은 강한 context와 응답은 답변으로 선택하지만 관련성이 낮은 context와 응답은 답변으로 선택하지 못한다.
따라서 이 문제를 해결하기 위해 위 그림의 RCMN모델의 self-matching 정보를 사용한다.
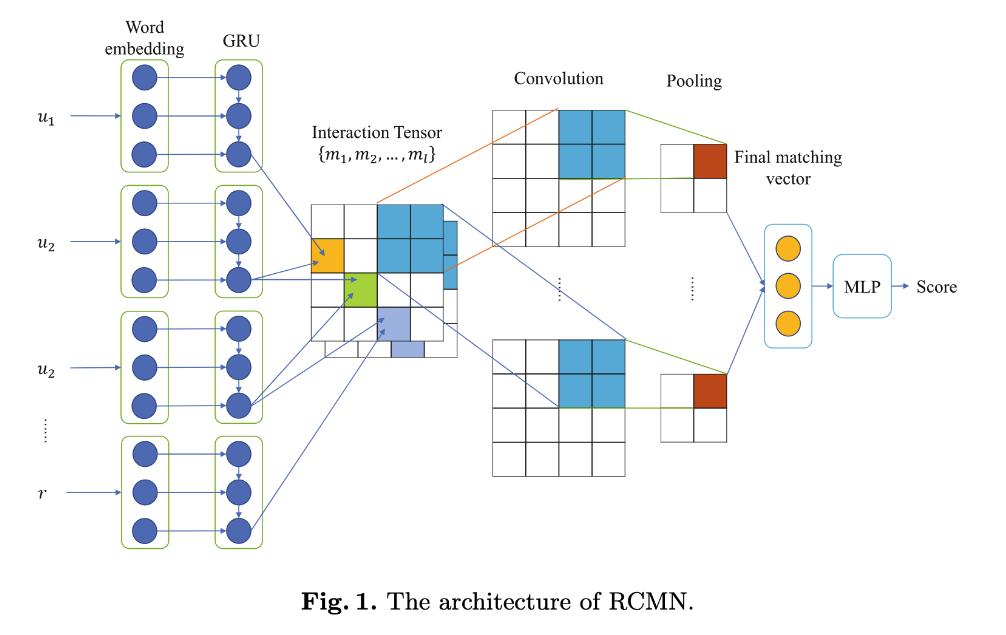
모델은 4개의 레이어로 이루어져 있다.
제일 처음 RNN은 문장 레벨의 정보와 문장 사이의 상호작용을 얻기 위해 사용한다. 여기서 상호작용이 관련성을 의미한다.
여기서 각각의 문장을 하나의 벡터로 변경해준다. GRU를 사용하는데 여기서 마지막 state 값을 output으로 다음 레이어에서 사용한다.
다음은 Interaction Tensor인데, 여기서는 weight값을 이용하여 CNN의 입력값으로 사용할 matrix를 만들게 된다.
S = RNN layer output, w = interaction weight, m = matrix
그 후 CNN을 사용하는데, CNN은 주로 이미지나 패턴 인식에서 좋은 성능을 보이나, 여기서는 특징을 추출하기 위해 사용한다.
두번째 모델은 SMN을 사용한다.
이 모델을 각각의 context와 응답 사이의 관계를 단어 레벨과 문장 레벨에서 잘 모델링 하기 위해 사용했다.
이 모델은 3개의 부분으로 이루어져 있는데, Utterance-Response matching Layer, Matching Accumulation Layer, Matching Prediction Layer
첫번째 Utterance-Response Matching Layer는 각각의 context와 응답을 단어 레벨과 문장 레벨의 매칭 정보에 관련된 레이어이다.
이 레이어에서는 RNN과 CNN이 사용된다.
Matchong Accumulation Layer는 각각의 context와 응답 쌍에 대해 single-turn 매칭 벡터를 만든다.
GRU를 이용해서 전체 대화의 매칭 정보를 모델링한다.
마지막 Matching Predction Layer는 위 레이어의 벡터값을 dense layer를 이용하여 degree값으로 변환해준다.
Ensemble
우리는 앙상블 결과로 각 모델의 결과의 가중 평균을 사용했다.
ER = ensemble result,
L = number of model(2),
H = number of validation datasets,
= on sample q when use for training.
느낀점
- 새로운 모델에 대해 알게되었다.
- RNN과 CNN으로만으로도 성능이 괜찮은 모델을 만들 수 있다.
- 이 모델을 사용해서 챗봇을 만들고자 한다면, 10개의 후보를 고를 수 있는 모델이 필요하다.
위 깃헙에 코드와 논문이 모두 있다
