0. Intro
Q1. 왜 회고글을 쓰게 되었는가
방향을 정한 상태로 확신을 가지고 달리다보니, 지친다는 느낌은 눈에 띄게 줄어들게 되었다. 요즘은 혹여나 방향이 조금 틀어지지 않았나 걱정만 조금 되는 편이다.
또한 방향을 설정했다면, 이제는 나아가는 속도 또한 개선이 필요하다고 생각한다.
다시 한번 더 회고글을 쓰면서, 방향에 대해서 돌이켜보고, 개선할 것들을 찾아보자.
Q2. 이전 회고글 돌아보기
- 방향은 Data Engineering(DE)으로. ML은 추후에 생각해보자.
- DE Roadmap에 따라 기본기부터 갖추자.
- "더 이상 의심하지 말고, 협상하지 말고, 가고자 하는 대로 쭉 밀고 나가자!"
1. AS-IS
Q1. 여태까지 무엇을 공부해왔는가?
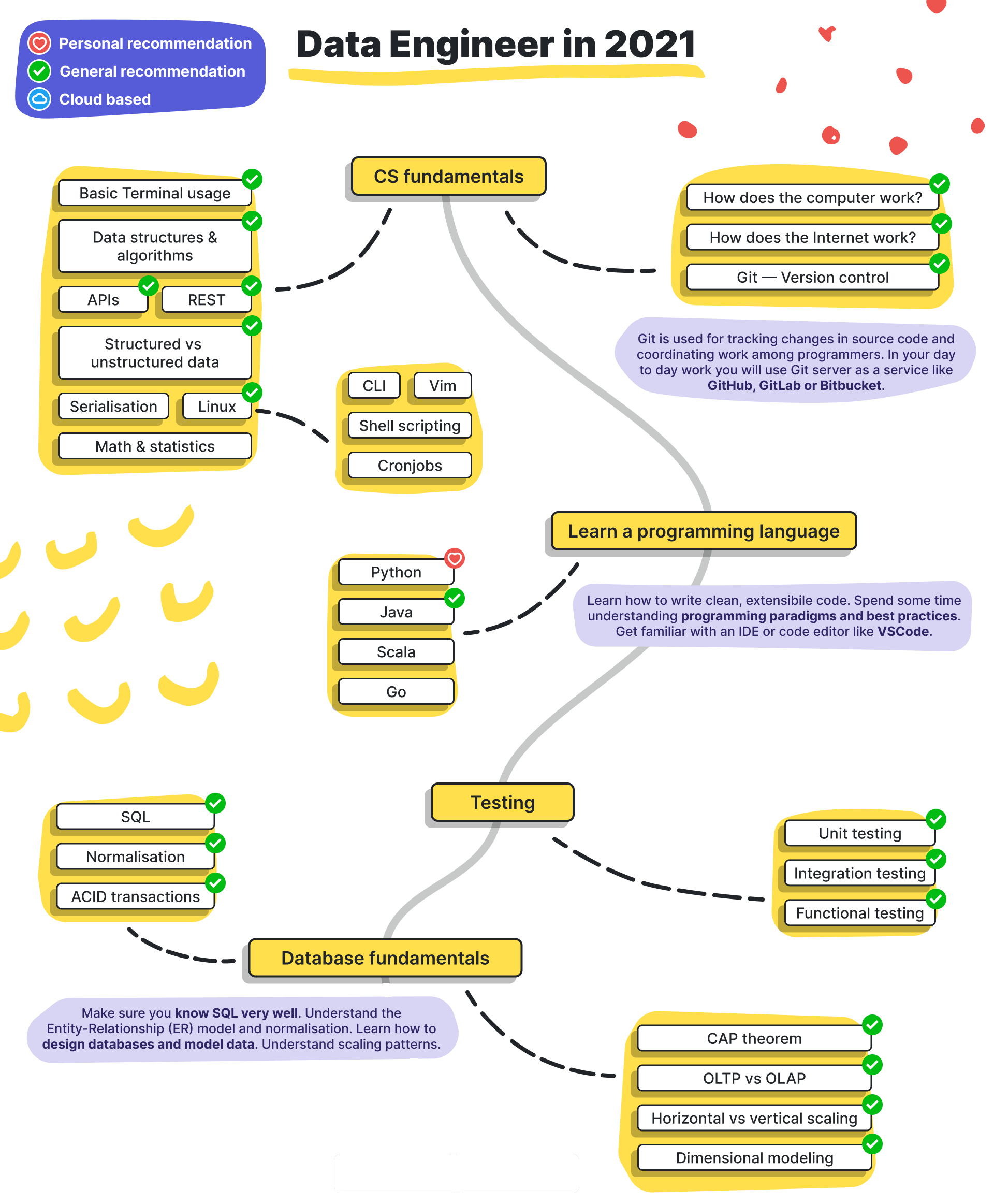
- CS (DB, OS, 자료구조)
- 학습 방법: '면접을 위한 CS 전공지식노트'을 보면서 기본적인 CS(OS, DB, 자료구조) 틀을 잡아놓았다. 어떠한 것을 알아야하는지 파악하고, 쓰이는 용어 및 이론에 대해서 이해하는 것에 집중했다.
- DB: 'Database 기본기' 라는 이름으로 글을 작성하였다. 용어 정리한 후, Transaction, 관계와 키, NoSQL vs RDBMS에 대해서 알아보았다.
- OS: 운영체제의 역할과 메모리 관리, 프로세스에 대해 공부했다. 정리가 되어 있지 않아 금방 잊어버린다.
- 자료구조: 선형, 비선형 자료 구조 종류에 대해서 공부하고 원리와 시간복잡도에 대해서 알아보았다.
- 알고리즘 문제는 잘 푸는 편이지만, 자료구조와 연계된 알고리즘 지식은 조금 부족한 편이다.
- Network
- 학습 방법: 'TCP/IP 쉽게, 더 쉽게' 라는 책을 중심으로 공부했으며, 이해가 더 필요한 부분은 Youtube의 우아한테크의 테코톡 강의를 듣거나, Header를 직접 검색해서 찾아보았다.
- TCP/IP: TCP/IP updated 5계층에 대해서 알아보았다. 각 계층이 어떤 역할을 하며 알아둬야할 header는 어떤 것이 있는지 살펴보았다.
- 지식은 있지만, 소켓 통신이나 어떠한 프로토콜을 만져본 경험이 없어서 응용 계층의 커스텀 프로토콜이 필요한 경우, 이를 해낼 수 있을지 모르겠다. Python에서 transport 계층의 프로토콜을 손대는 방법을 찾아보는 건 어떨까?
-
FastAPI를 이용한 RESTful API
- 다른 Python BE Framework 간의 차이점 및 장단점을 파악하고, 공식 문서를 읽어보며 기본 API 제작 방법을 익혀보았다.
- fastapi(uvicorn)의 특징인 ASGI와 async 비동기 모듈에 대해 익숙하지 않은 편이다. 후에 fastapi 서버를 사용하면서, 트래픽과 같이 운영 이슈를 해결할 때 필요할 것 같다.
-
SQL
- '초보자를 위한 SQL 200제'를 보면서 단순 문제 풀이 및 기능 이해하는 방식으로 SQL을 익혀나갔다.
- 후에 안 사실은... 이 책에서 알려주는 SQL은 Oracle SQL 기반이었다는 것
- 여러 SQL 문법들을 공부했지만, 막상 써보지 않아 금방 잊어버릴 것 같다.
- sql 파일에 주석으로 정리가 되어 있어, 나중에 복습할 때 한꺼번에 꺼내보기 어렵다. 정리할 필요가 있어보인다.
-
Spark
- 학습 방법: Udemy에서 Spark 강의를 듣으면서 공부 중에 있다.
- Hadoop의 MapReducer와의 차이점을 파악하고, RDD와 Dataframe 구조에 대해 학습했다.
- GCP 상에서 인스턴스를 만들어 연습용으로 사용하고 있다. 하지만, 부가 요금에 대한 부담이 있어 더 이상 진행하지 못하고 있는 상황이다.
-
Ray
- 채용 과제를 수행하면서 공부하게된 Python 모듈이다.
- 정형화된 데이터를 다루는 Spark와는 달리, 비정형 데이터 또한 다룰 수 있으며, 병렬 및 분산 처리가 가능하다. 아주 간단한 코드를 통해 구현 가능하며, ML 학습 가속화를 위한 라이브러리를 지원한다.
- Task를 이용하여 병렬 처리 코드를 작성하고 실험해보았다.
- Ray Cluster를 이용하여 Task 단순 병렬 처리 코드를 분산 처리 범위까지 넓혀서 실행해보았다.
- Actor에 대해 익숙하지 않다.
- HDFS 상에서 이미지 데이터를 불러와 Ray로 분산 처리할 수 있는 걸까?
-
Docker
- 기존에는 이미지를 가져와 컨테이너를 만들고 run하는 정도 밖에 모르고 있었다. docker-compose는 yaml 파일을 조작하여 사용하는 정도였다.
- 이미지를 생성하는 것을 배우기 위해 기본 Ubuntu 이미지에 FastAPI서버를 올리고 commit하는 방식으로 서버 이미지를 생성해보았다.
- Kubernetes를 사용하면 어떻게 orchestration 되는 걸까?
-
NLP
- 채용 과제 진행 중에 도메인 지식 공부 겸 공부하게 되었다.
- 전처리 과정과 간단한 모델 학습 과정 및 응용 방법에 대해서 알아보았다.
- 필요하지 않을 수 있으니 당장 공부할 필요는 없을 것 같다...
Q2. 어떤 세미나 & 워크숍을 들었고 무엇을 느꼈는가?
-
Introduction to Analytics on AWS
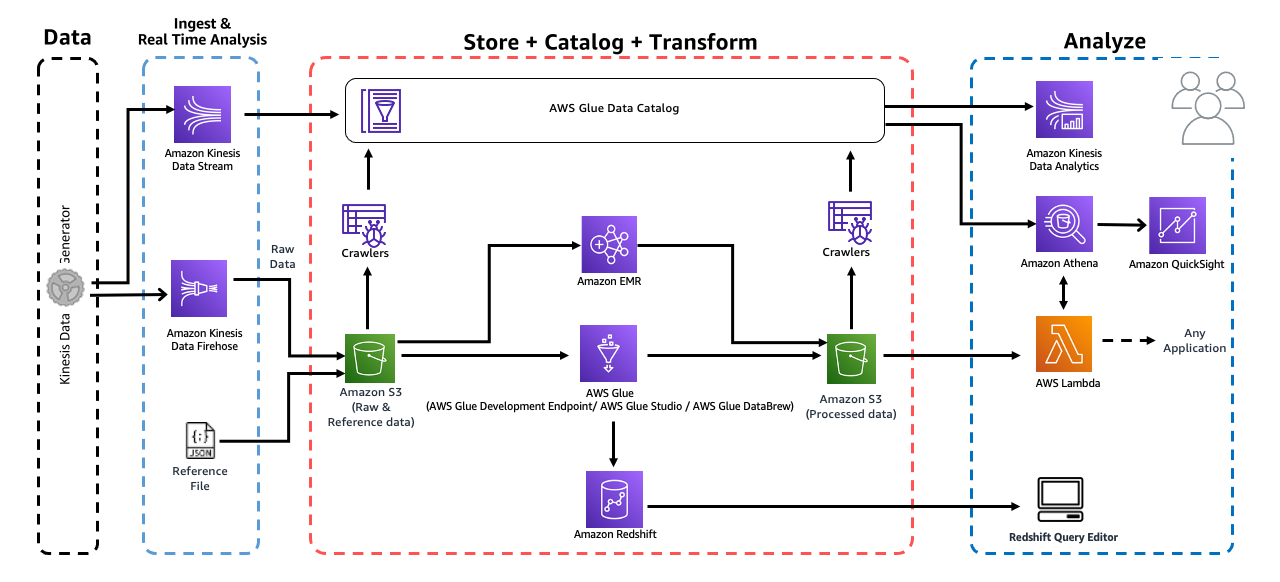
- Online Workshop Link
- AWS에서 빅데이터(+스트리밍 데이터)를 다뤄보고, 분석을 위한 ETL 파이프라인을 제작해보았다.
-
Data Career Class
- Notion Note Link
- 커리어에 대해 방향은 잡아놓았지만, 이후 커리어를 어떻게 쌓아갈 수 있을지 고민이 많았고 멘토링이 필요한 상황이었다.
- 주니어는 성장을 목표로 해야하며, 주요 기술 스택은 Pyton, SQL, BE(API), Spark, Kafka 정도다. 시니어가 되면 스페셜리티를 필요해지고, 비용을 설계해야한다. 그 후에는 전문가로써 회사의 이익에 대해 더 집중해야한다.
- 데이터 분야에서는 데이터를 모으고 관리하는 것이 가장 먼저 이루어져야 한다.
Q3. 어떻게 커리어 관리를 하고 있으며, 지금까지의 면접 경험은 어땠는가?
-
github
- SQL을 연습하고 주석을 달아놓은 쿼리들을 github에 올리는 형식으로만 관리하고 있다.
- 단순히 add, commit, push 기능만을 사용하고 있다.
- stage area와 remote repo 공간이 왜 필요한지 이해할 필요가 있어보인다.
-
velog
- 글을 쓰는 목적
- 배운 것들을 정리하고 복습할 수 있다.
- 커리어 증명에 도움이 된다.
- 3주에 2번 정도로 작성하고 있다.
- 점점 글을 쓰는 것에 익숙해지고 있다.
- 공부는 자주하는 편이지만, 배운 것들을 모두 적지는 못하고 있다.
- velog를 사용할 때 일부 버그가 있어 신경쓰이는 편이다. 또한 단축키가 없어 불편하다.
- 글을 쓰는 목적
-
취업 준비
- 한달에 4~7곳씩 지원했고, 개인 공부 보다는 채용 과정에 집중했다.
- 잘 작성한 포트폴리오와 이력서 덕분인지 서류에는 어렵지 않게 통과할 수 있었다.
* 대부분 지원한 곳은 DE였지만, 금전적인 이유로 마음이 급했기에 Data Manager로도 지원했고, 결국엔 내 커리어 로드맵과 맞지 않아 모두 최종에서 탈락했다. (Data Manager로 최종까지 간 회사 중에는 정말 가고 싶은 회사가 많이 있었다.) - 이력서를 보고 ML 엔지니어 권유도 들어왔지만, 능력 부족으로 모두 기술 면접에서 탈락하였다. 욕심내서 ML 분야도 공부하면서 시간을 보냈기에, 이 때문에 DE에 집중하지 못했다.
- 7월에는 마음을 다 잡고, DE 작업을 할 수 있는 곳에 다시 지원했고, AI 회사에 합격할 수 있게 되었다.
- 앞으로 이력서와 포트폴리오 작성에 신경쓰면서 프로젝트를 수행할 필요가 있을 것 같다.
-
이력서와 포트폴리오
- 이력서는 Google 문서로 관리하고 있다. pdf로 export했을 때, 종종 그림이 깨지는 경우가 있고, 폰트가 예쁘지 않다.
- 포트폴리오는 Notion으로 관리하고 있다. 링크를 타고 다른 문서까지 들어갈 수 있으며, 보기에도 깔끔해서 잘 관리되고 있는 편이다.
Q4. 내 생활은 어떻고 이에 만족하고 있는가?
- 생활비 문제
- 공부하면서 생활비를 버는 것이 쉽지 않다.
- 돈걱정에 취업을 서두르게 된다.
- 공부량
- 몰입할 때는 하루 종일 열심히 하는 편이지만, 그렇지 않을 때는 정말 아주 잠깐 의자에 앉아있는 정도다.
- 하나를 모두 끝내지도 않고 계속 다른 것을 시작하려고 한다.
- 취업에 대한 불안감
- 서류 평가 과정에서는 통과한 경험이 많았기에 큰 걱정은 없었다.
- 계속 피드백을 거쳐서 개선점을 찾았고, 이러한 과정을 통해 성공할 수 있으리라 믿고 있었기에 큰 불안감이 들진 않았다.
2. TO-BE
이어서 공부해야할 것들
-
DB
- NoSQL과 RDBMS의 종류와 특징들을 알아보고, 많이 쓰이는 DB끼리 비교해볼 필요가 있을 것 같다. (MySQL, PostgreSQL, DynamoDB, Redshift, Google Bigtable, Redis, MongoDB)
- 스키마를 설계해보면서 무엇이 중요하고, 어떠한 것들을 고려해야하는지 노하우를 익혀보자.
- CAP 이론, 다차원 모델링, OLTP, OLAP에 대해 알아보자
-
OS, 자료구조
- CS 책을 기준으로 글을 쓰면서 정리해보자.
-
Network
- 복습이 필요하다.
- Python 내에서 TCP/UDP 프로토콜을 사용해보자.
- VPN이나 SSL/TLS, SSH, 방화벽 등 보안에 대해 더 알아보자. 서버 접속이나 네트워크 설정, 클라우드 설정 부분에서 많이 막힌 경험이 있다.
-
FastAPI & REST API
- REST API에 대해 자세하게 설명할 수 있을 정도로 공부하자.
- uvicorn과 함께 ASGI에 대해 알아보자.
- Python에서 자주 쓰이는 asyncio 비동기 모듈에 익숙해지자
* 시간이 된다면, Github Action을 이용하여 서버를 돌려보는 건 어떨까?
-
SQL
- 지금처럼 하루에 조금씩이라도 익혀보자
- sql 문제 풀이 사이트(해커랭크, 리트코드)를 통해 문제를 풀며 SQL에 익숙해지자.
- 헷갈리는 용법은 복습할 수 있도록 Notion에 정리해두자.
-
Spark
- 강의에서는 spark 단순 사용 경험만을 쌓을 수 있다. 하지만 실전에서는 메모리 리소스, 계산량에 따라 적절하게 방법을 바꾸거나 튜닝을 해야하는 경우가 생긴다. spark 관련 도서를 사서 쭉 읽어보는 것도 좋을 것 같다.
- spark에서는 image를 dataframe으로 변형하여 처리할 수 있도록한다. 이에 대한 이점은 어떤 것이 있을지, 그리고 ray cluster와 어떠한 차이점이 있을지 비교해보면 더더욱 좋을 것 같다.
-
Docker & Kubernetes
- Docker는 현업에서 노하우를 더 익혀보는 게 좋을 것 같다.
- Kubernetes와 함께 어떻게 쓰이는지 파악할 필요가 있을 것 같다.
-
Python
- GIL과 Multiprocessing에 대해 꼬리물기식으로 공부해보자.
- 특수 메소드의 종류
- 데코레이터
- asyncnio 모듈을 이용한 비동기 처리 및 TCP/UDP 프로토콜 메소드
-
Github
- stage area와 remote repo 공간이 왜 필요한지 이해하자
- 다양한 사용 노하우를 익혀보는 것도 좋을 것 같다.
-
Airflow
- 회사에서는 어떻게 사용되는지 익히면서 배우자
- 더 필요하다면 책을 구매해서 더 깊이 공부해보자
-
Hadoop HDFS
- 설치와 분산 저장 튜닝, Kubernetes와의 연계
- DataLake로 사용했을 때, Ray와 어떻게 연계할 수 있을까?
- cmd 인터페이스, http 등 다양한 사용 방법
-
Data Pipeline 책은 꼭 완독하고 노하우는 기록하자!
-
그 외로 MongoDB, MySQL, DataLake, DataWarehouse, Kafka, ML, Computer Vision 등등...
어떻게 커리어를 관리하는 게 좋을까?
- 대부분의 글들을 Notion에서 관리하자. 다양한 단축키와 깔끔한 디자인, export와 API 사용 가능하다는 장점이 있다.
- Github는 사용을 덜 하더라도 깔끔하게 보일 수 있도록 정리할 필요가 있을 것 같다. 코드 저장소로 사용하면서, 나만의 util을 만들어보는 것도 좋은 방법일 것 같다.
- 이력서 또한 Notion으로 이전해야겠다. Notion이 보기에도 깔끔하고, Viewer URL을 제공을 하며, 폰트 또한 예쁘다. PDF 형식으로도 export가 가능해서 pdf 형식으로 제출해야할 때 문제없이 사용가능할 것으로 보인다. 이미지 에딧 기능은 살펴봐야할 것 같다.
- 회사 프로젝트를 기록하면서 포트폴리오를 한줄 한줄 조금씩 작성해보자.
- 커리어에 대해서 느낀 점들은 LinkedIn에 기록하는 것도 좋은 방법일 것 같다.
- 아주 만약에 시간이 된다면 영어 커뮤니케이션 스킬도 올려두자.
- 정리하자면...
- 배운 것과 프로젝트들을 Notion에 기록하고 정리해두자.
- 배운 것들을 정리하는 목적은 복습하기 쉽도록 하는 것이다. 괜찮은 글은 velog로 노출 시키는 것도 좋을 것 같다.(또는 notion자체에서)
- 프로젝트는 깔끔하게 보기 좋게 정리하자. 포트폴리오에 옮겨서 작성하는 것을 목표로 한다. 그림이 있다면 넣는 게 더 좋을 것 같다.
- 완료된 프로젝트나 어느 스킬의 목표 성취도를 달성했다면 이력서에 내용을 넣고 업데이트하자.
생활에도 개선이 필요하다
- 잘하고 있다고 생각하는 점은 내 능력에 대해서 부끄럼없이 대한다는 것이다. 부족한 부분은 인정해야하고, 잘하는 점에 대해서는 자신감을 갖자. 너무 자존심을 세우는 것은 좋지 않다.
- 충분히 살펴보고 시작하는 것은 정말 좋은 점이라고 생각한다. 하지만 끝을 보는 습관을 들이는 게 좋을 것 같다. 중간 목표를 만들고 계획해서 수행하는 습관을 길러보자.
- 충분히 능력이 있음에도 불구하고, 목표를 낮추는 식으로 내 가치를 깎아내리지 말자.
- 몰두해서 일할 수 있다는 것은 큰 장점이다. 하지만, 일에 너무 빠져서 인간 관계나 건강, 일상 생활에 까지 지장이 가지 않도록 하자. 일에 벗어나서도 계속 일 생각 뿐이라면... 심리 상담 도움을 청해보자.
- 수익을 관리하는 방법도 천천히 고민해보자.
- 할 일 목록을 만들고, 우선 순위를 정해보자. 시간을 효율적으로 쓸 줄 알아야한다.

정리하고 복습하고 일기도 쓰고