0. Intro
지난번에는 Ray를 이용하여 컴퓨터 한대(4개의 CPU)로 병렬 처리를 해보았다. 속도는 빨라졌다고 하지만, 수만개의 데이터를 처리하는 데에 턱없이 부족해보인다. 그래서 이번에는 GCP 내에서 Ray의 Cluster 분산 처리를 해보기로 하였다.
1. Python Code
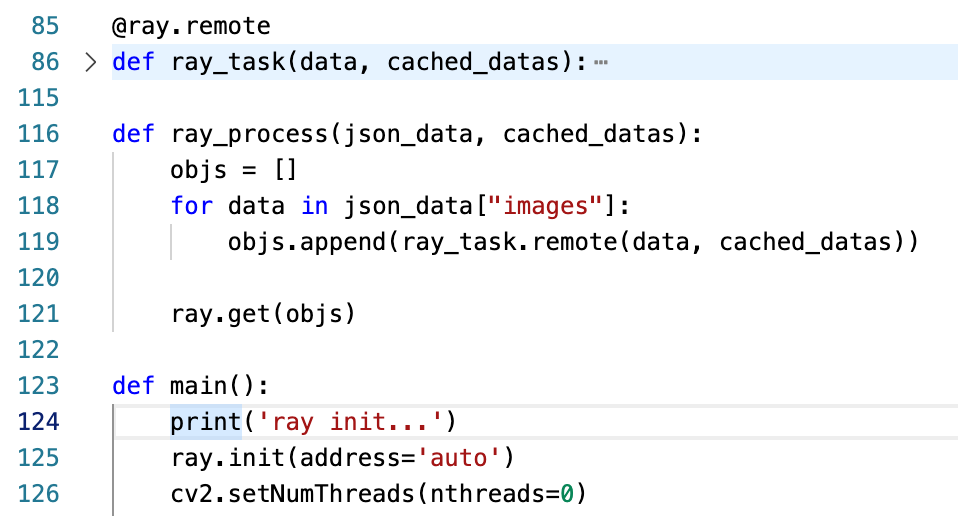
다음은 분산 처리를 위한 코드다. 'ray_task'는 한 개의 데이터를 처리하는 코드가 담겨있다. 그리고 @ray.remote를 통해 함수를 감싸고, 'ray_process' 함수 내에서 for문을 통해 remote 함수를 실행시켜 obj_ref들을 만들어낸다. 마지막으로는 get을 통해 'ray_task'코드들을 작동시킨다.
병렬 처리와 다른 점은 ray.init(address='auto')로 설정한다는 것이다. 이를 통해 ray가 자동으로 cluster를 찾아 연결한다. 그리고, OpenCV의 경우, 'setNumTreads(nthreads=0)'을 통해 쓰레드를 사용하지 않도록 한다.
2. GCP 설정
Provider는 ray 명령어를 통해 실행할 코드를 cluster에 넘겨주는 역할을 하는 node를 뜻하는데, gcp region 리소스가 몰리는 경우, 실행이 안 될 수 있기 때문에 인스턴스 만들 때 미국 지역은 추천하지 않는다...
Ray Cluster는 GCP의 Cloud API를 통해 사용된다. 'google-api-python-client'를 설치하고, 'GOOGLE_APPLICATION_CREDENTIALS' 환경변수를 설정해야 한다.
이 부분에서는 GCP 내에서 프로젝트 권한 설정을 해야할 게 많았다. ray cluster는 autoscaler를 통해 자동으로 gcp 인스턴스를 만들기 때문에, 인스턴스 생성 및 설정 권한을 ray에게 넘겨줘야한다.
참고: https://cloud.google.com/docs/authentication/getting-started
3. config.yaml
# A unique identifier for the head node and workers of this cluster.
cluster_name: minimal
max_workers: 6
# Cloud-provider specific configuration.
provider:
type: gcp
region: asia-northeast3
project_id: rsp-game-pnoa
availability_zone: asia-northeast3-a
file_mounts:
{
"annotations":"/home/xcellentbird/annotations/"
}
auth:
ssh_user: xcellentbird
head_setup_commands:
- pip3 install opencv-python
- pip3 install numba
worker_setup_commands:
- pip3 install opencv-python
- pip3 install numbayaml 파일을 통해 cluster 설정을 해줘야한다. cluster를 구분할 수 있는 이름을 설정하고, max_workers를 통해 autoscaler가 몇개의 worker까지 사용할 수 있도록하는지 설정할 수 있다.
provider 정보를 적고, file_mounts를 통해 provider의 어떤 경로의 파일들을 cluster에 공유할 지 적어준다. auth를 통해 ssh 권한을 설정해주고, setup_commands를 통해 head와 worker에서 먼저 실행할 명령어들을 적어준다. 본 설정에서는 코드에서 사용할 opencv와 numba를 설치하도록 하였다.
위의 설정 yaml을 작성하고, provider 노드에서 'ray up -y config.yaml' 명령어를 통해 cluster를 생성해준다.
4. 실행 결과
xcellentbird@ray-node1:~$ ray submit config.yaml annotation_editor.py
ray init...
This cluster consists of
9 nodes in total
14.0 CPU resources in total
ray process start...
elapsed time: 125.24751261738281다음은 여러 노드를 사용했을 때 실행결과다. 14개의 CPU를 사용하였고 코드가 실행되는 데에 약 125초가 소요됐다. (node가 9개로 측정되는 것은 왜일까...)
처음에는 코드가 실행되면서 autoscaler에 의해 노드가 확장되는데, 이 때 시간이 오래걸리는 경우가 있다. 한번에 노드를 여러개 생성하는 것이 아닌 점진적으로 노드를 생성하기 때문이다. 두번째 코드를 실행하게 될 때에는 바로 이전에 만들어둔 모든 노드를 사용하기 때문에 시간이 훨씬 단축된다.
그리고 비교를 위해 cluster를 사용하지 않고, provider에서 병렬 처리만 실행해보았다.
xcellentbird@ray-node1:~$ python3 annotation_editor.py
ray init...
2022-06-28 21:50:25,673 INFO services.py:1476 -- View the Ray dashboard at http://127.0.0.1:8265
This cluster consists of
1 nodes in total
2.0 CPU resources in total
ray process start...
elapsed time: 1557.8823921680451557초로 역시나 훨씬 오래걸리는 것을 볼 수 있었다.
