
배경
기존의 ITS 팀에서는 모든 데이터를 NAS와 GCP의 File System에 저장하고 있었습니다. 데이터 저장 경로와 파일 이름 형식이 데이터마다 달라 모델 학습에 필요한 데이터를 찾기도 힘들었고, 어떤 데이터가 얼마나 존재하는 지 파악하기 어려웠던 경험이 있었습니다.
왜 Elasticsearch & Kibana 인가?
이러한 이슈를 해결하고자 Elasticsearch & Kibana 기술을 도입하기로 결정했습니다. 도입하게 된 이유는 다음과 같습니다.
- Elasticsearch(ES)는 분산 저장 시스템을 지원합니다.
- 역인덱싱 기술을 통해 빠른 검색 기능을 제공합니다.
- ITS 팀에서 저장하고 있는 데이터는 대부분 JSON 형태로 되어있고, ES는 JSON 형태로 입출력이 가능합니다. 기존의 데이터를 약간의 가공을 통해 넣거나 빼서 사용할 수 있습니다.
- 라벨링 데이터의 경우, class가 매우 다양하고, sub-class가 존재하는 경우가 많이 있었습니다.(ex. car, blurred_car, pedestrian, pedestrian_child, ...) 이 때문에 class field는 유연할 필요가 있으며, 그에 맞춰서 검색 기능 또한 다양한 조건으로 검색이 가능해야 합니다.
- CRUD http method를 제공하며, Python에서 requests 모듈을 사용하여, 자동화 코드 작성이 가능합니다.
- Kibana에서는 Dashboard를 통해 데이터를 집계 및 시각화 할 수 있으며, 간단한 KQL(Kibana Query Language)을 통해 다른 엔지니어 분들도 쉽게 데이터를 검색할 수 있습니다.
아쉬운 부분은 파일 크기가 큰 딥러닝 모델이나 동영상, 이미지 데이터를 저장할 수 없다는 점이었습니다(binary 형태로 저장 가능 하지만, 분산 저장 성능 이슈로 추천하지 않는다고 합니다...). 그래서 NAS를 그대로 사용하면서, 라벨링 데이터만 백업용으로 ES에 저장하기로 결정했습니다.
도입기
데이터 표준화
앞서 설명한 대로, ITS 데이터는 데이터 저장 경로와 파일 이름 형식이 모두 제각각인 상태였습니다. ES에서 mapping 설정한 대로 데이터를 읽을 수 있도록 field 이름과 그에 해당하는 값을 표준화하고, 후에 자동화를 위해 파일 이름, 경로, 형식 등 정해둘 필요성이 있었습니다.
데이터 표준화 관련 자료는 notion 링크를 통해 확인할 수 있습니다!
Elasticsearch & Kibana 설치
ITS 팀에서는 GCP를 사용하고 있습니다. GCP에서 따로 인스턴스를 만들어 도커 이미지를 통해 Elasticsearch와 Kibana를 설치하였습니다.
ES setting/mapping 설정
ES에서는 입력으로 들어온 데이터를 어떻게 해석하고 어떻게 검색할 수 있게 할 것인지 setting/mapping에서 설정 가능합니다. 설정 사항은 다음과 같습니다.
PUT traffic { "settings": { "index": { "analysis": { "analyzer": { "class_analyzer": { "tokenizer": "keyword", "filter": ["custom_word_delimiter"] } }, "filter": { "custom_word_delimiter": { "type": "word_delimiter", "type_table": ["_ => ALPHA", "' => ALPHA"], "preserve_original": true } } } } }, "mappings": { "properties": { "dtype": { "type": "keyword" }, "img_name": { "type": "text" }, "img_size": { "properties": { "width": { "type": "short" }, "height": { "type": "short" } } }, "objects": { "properties": { "class": { "type": "text", "analyzer": "class_analyzer", "fielddata": true }, "bbox": { "properties": { "x_min": { "type": "short" }, "y_min": { "type": "short" }, "x_max": { "type": "short" }, "y_max": { "type": "short" } } }, "bbox_size": { "properties": { "width": { "type": "short" }, "height": { "type": "short" } } } } }, "object_cnt": { "type": "short" }, "country": { "type": "keyword" }, "dataset": { "type": "keyword" }, "site": { "type": "keyword" }, "date": { "type": "date", "format": "basic_date_time_no_millis||basic_date" }, "light": { "type": "keyword" }, "weather": { "type": "keyword" }, "labeled_date": { "type": "date", "format": "basic_date" }, "README": { "type": "keyword" }, "example_img": { "type": "binary" } } } }
-
objects의 class field의 경우엔, subclass를 처리할 수 있도록 text 유형의 field로 지정하고, 구분자에서 "_"(밑줄)과 "'"을 제외시키고,'-'(하이픈)을 구분자로 인식하도록 설정하여 sub-class 또한 토큰화되도록 지정하였습니다.
-
날짜 및 시간 field의 경우, 시간 데이터가 없는 이미지 데이터도 있기 때문에 날짜 또는 날짜+시간 ISO 표준 형태의 데이터(ex. "20211124" 또는 20211124T165121+0900")를 인식하도록 설정하였습니다.
Kibana Dashboard 제작
Kibana Dashboard는 KQL을 이용하여 데이터를 검색할 수 있고, 카드를 통해 검색된 데이터를 시각화하여 한눈에 살펴볼 수 있도록 합니다. 아래 이미지와 같이 카드를 제작하였고, 상단의 KQL 입력창을 통해 데이터를 검색할 수 있습니다.
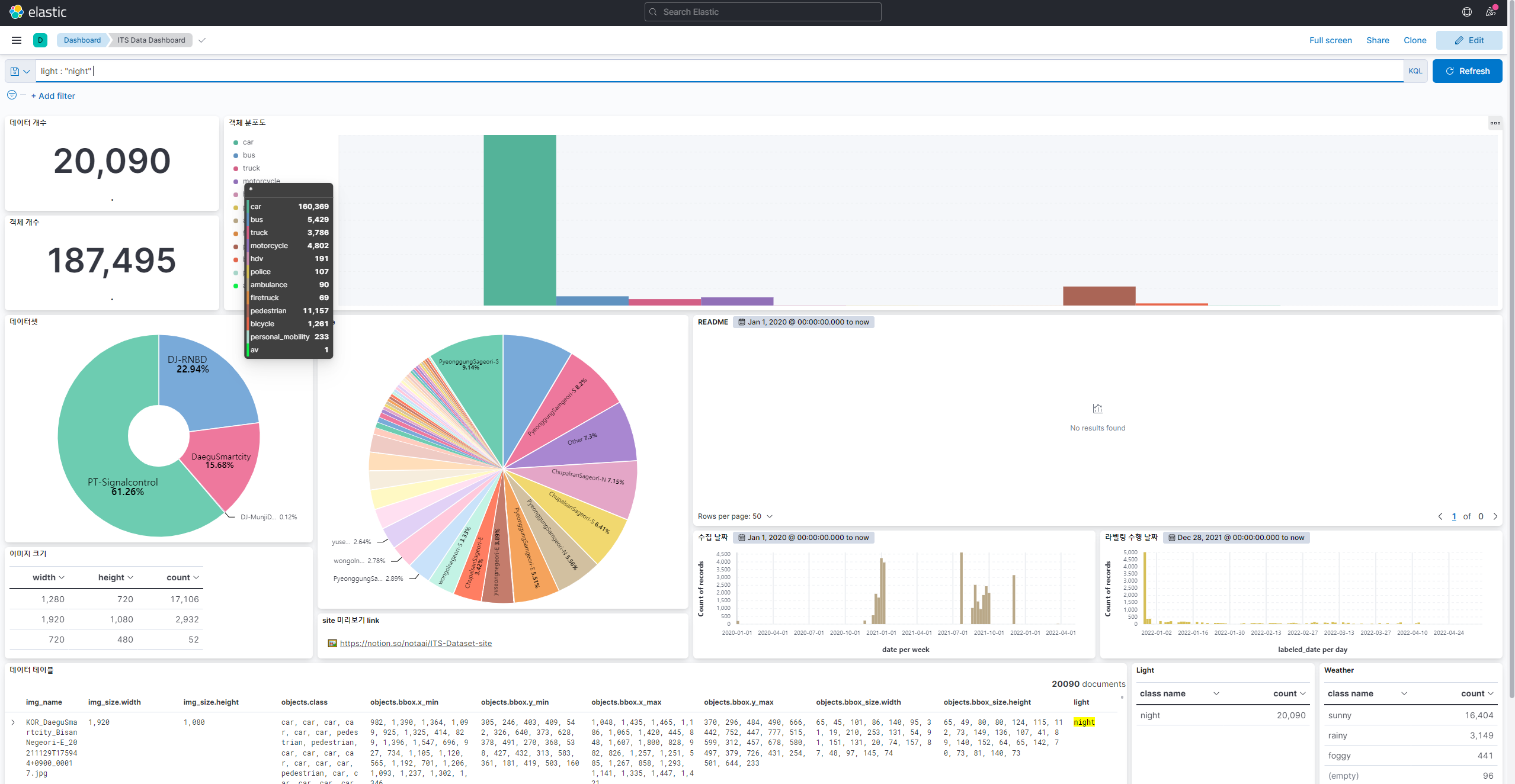
데이터 테스트
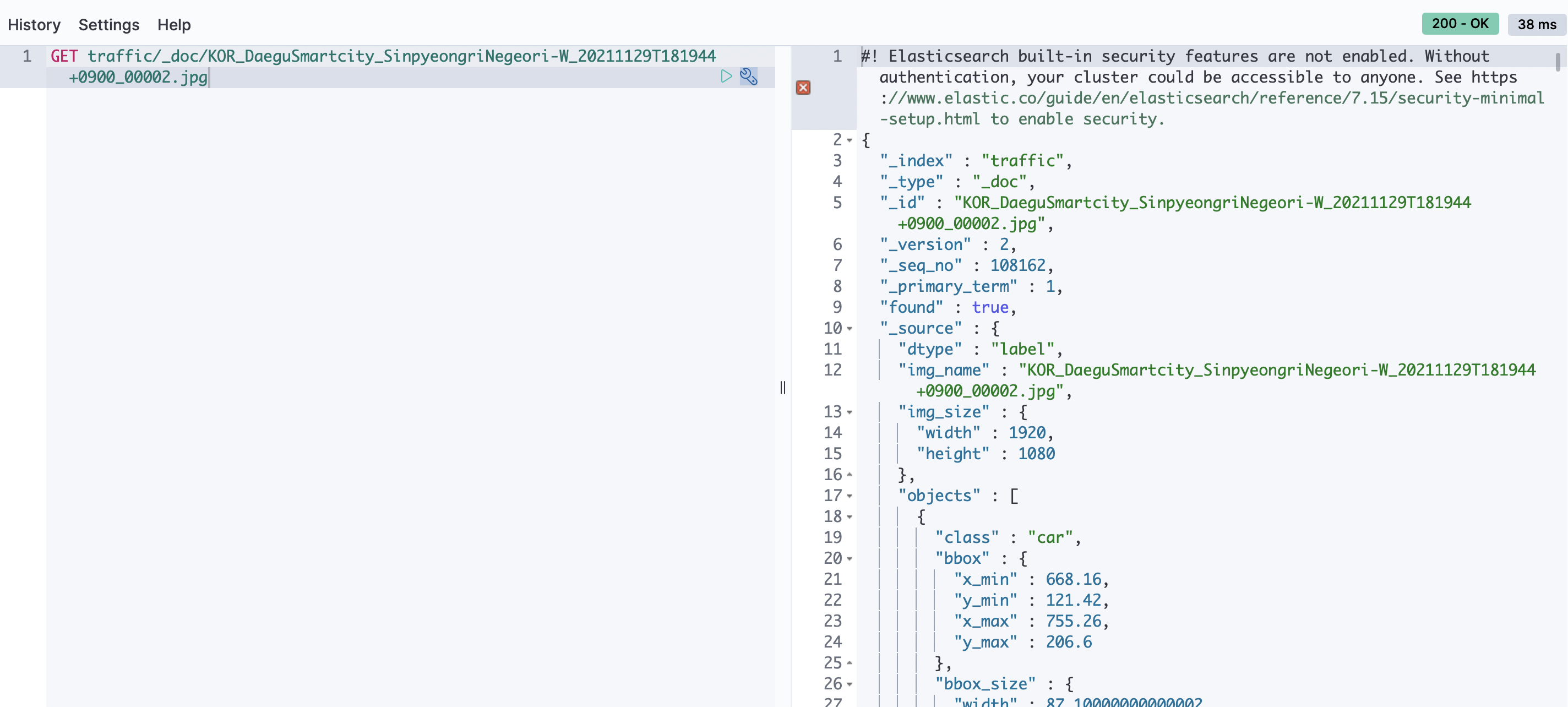
위와 같이 설정한 후, python 코드를 통해 표준화된 NAS의 라벨링 데이터를 ES에 입력했습니다. 그리고 임의의 데이터를 GET 했을 때 성공적으로 데이터를 가져오는 것을 확인할 수 있었습니다!
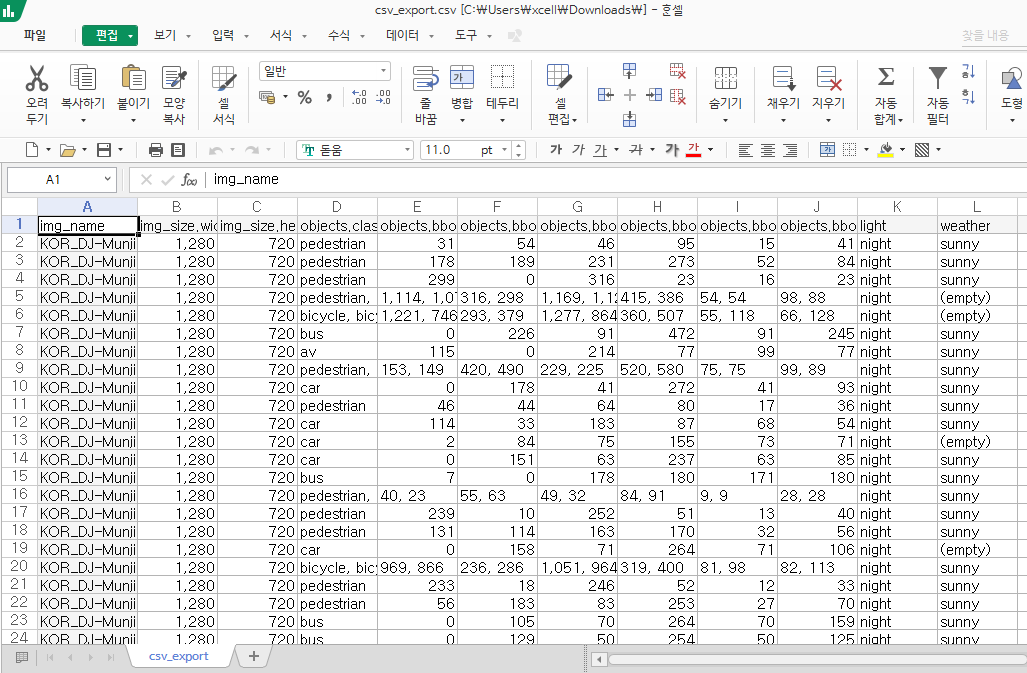
Kibana CSV export를 이용한 데이터 서빙 및 버전 관리
Kibanad를 사용하면서 추가적으로 유용한 기능을 발견해낼 수 있었습니다! csv export 기능은 검색한 데이터를 csv 테이블 형태로 다운로드 할 수 있도록 합니다. 저는 이 csv 파일을 데이터 주문서와 같은 역할을 하여, 서빙 및 버젼 관리가 가능하도록 프로세스를 구축하였습니다.
- csv 데이터 주문서는 이미지를 포함하지 않은 라벨링 데이터로 크기가 상대적으로 작은 편입니다.
- 이미지 이름 정보를 이용하면 NAS에서의 데이터 경로 추적 가능하기 때문에, 데이터 주문서를 이용하여 이미지 데이터를 불러올 수 있습니다. 이미지 데이터를 불러오는 코드와 이 데이터 주문서만 가지고 있다면, 이미지 데이터를 불러와 원하는 형태로 데이터를 서빙 받을 수 있습니다.
- 해당 데이터 주문서와 모델을 함께 저장 및 관리하여, 해당 모델이 어떤 데이터로 학습됐는지 알 수 있습니다. 이와 같은 방식으로 모델과 함께 학습 데이터 버전 관리가 가능합니다.
인턴 과정을 회고하면서
현재 프로세스에서 문제점과 요구 사항을 파악하고, 기술 서치를 통해 필요한 툴을 도입하였습니다. 이러한 경험은 기술 중심의 문제 해결 방식에서 벗어나게 해주었고, 동시에 다른 기술을 사용하는 데에 할 수 있다는 자신감을 갖도록 만들어주었습니다.
문제 해결 방식
1. 현 상황(AS-IS)과 요구 사항(TO-BE, Goal) 파악
2. 요구 사항에 맞는 기술 서치
3. 기술 도입 및 테스트
4. 업무 문서화위의 프로세스를 관리하면서 csv export 크기 제한이나, kibana dashboard의 정적인 image 팝업, 데이터셋에 대한 메타 정보 입력, 등 자잘한 이슈가 있었는데 이러한 것들을 해결하지 못하고 계약 만료로 프로젝트를 마감한 점이 너무 아쉬웠습니다.
기회가 된다면, ES 뿐만 아니라 RDBMS, Hadoop(with HBase), MongoDB 등 다양한 데이터 관리 툴을 공부해보고 써보고 싶다는 생각이 드네요. 시간상 한계점이 있겠지만, 역시 단순히 기술을 공부하는 것보다 써보는 게 백배 더 많은 인사이트를 갖도록 하는 것 같습니다!
