선택 정렬
- 처리되지 않은 데이터 중에서 가장 작은 데이터를 선택해 맨 앞에 있는 데이터와 바꾸는 것을 반복하는 정렬
코드 예시)

2중 for문을 통하여 앞의 인덱스와 뒤 인덱스를 비교하여 스와프 해주면 된다.
선택 정렬의 시간 복잡도는 한개씩 비교하며 범위값이 줄어들기 때문에
n + (n-1) + (n-2) .... + 2 이므로
(n^2 + n-2)/2 로 표현 가능하다. 빅오 표기법에 따라 O(n^2) 이다.
삽입 정렬
- 처리되지 않은 데이터를 하나씩 골라 적절한 위치에 삽입 합니다.
선택 정렬보다 난이도는 높지만 더 효율적임.
코드 예시)
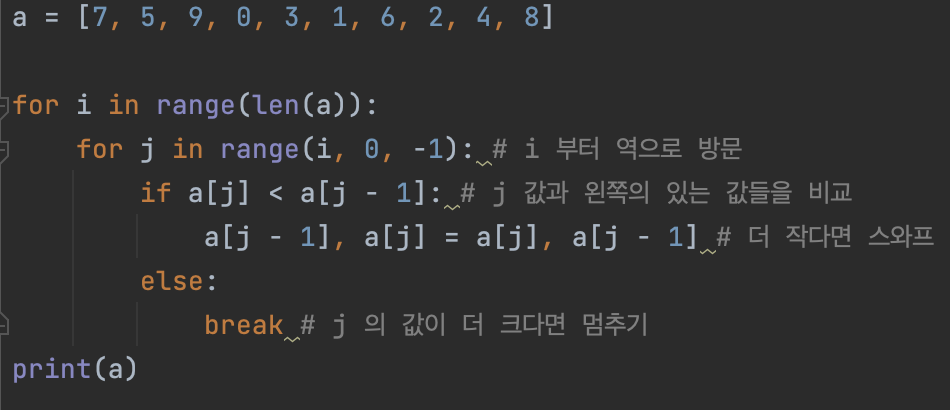
삽입 정렬의 시간 복잡도는 O(n^2) 이며 선택정렬과 마찬가지로 반복문이 두번 중첩되어 사용 된다. 최선의 경우 O(n)의 시간 복잡도를 가짐.
퀵 정렬
- 기준 데이터를 설정하고 그 기준보다 큰 데이터와 작은 데이터의 위치를 바꾸는 방법이다.
코드 예시)
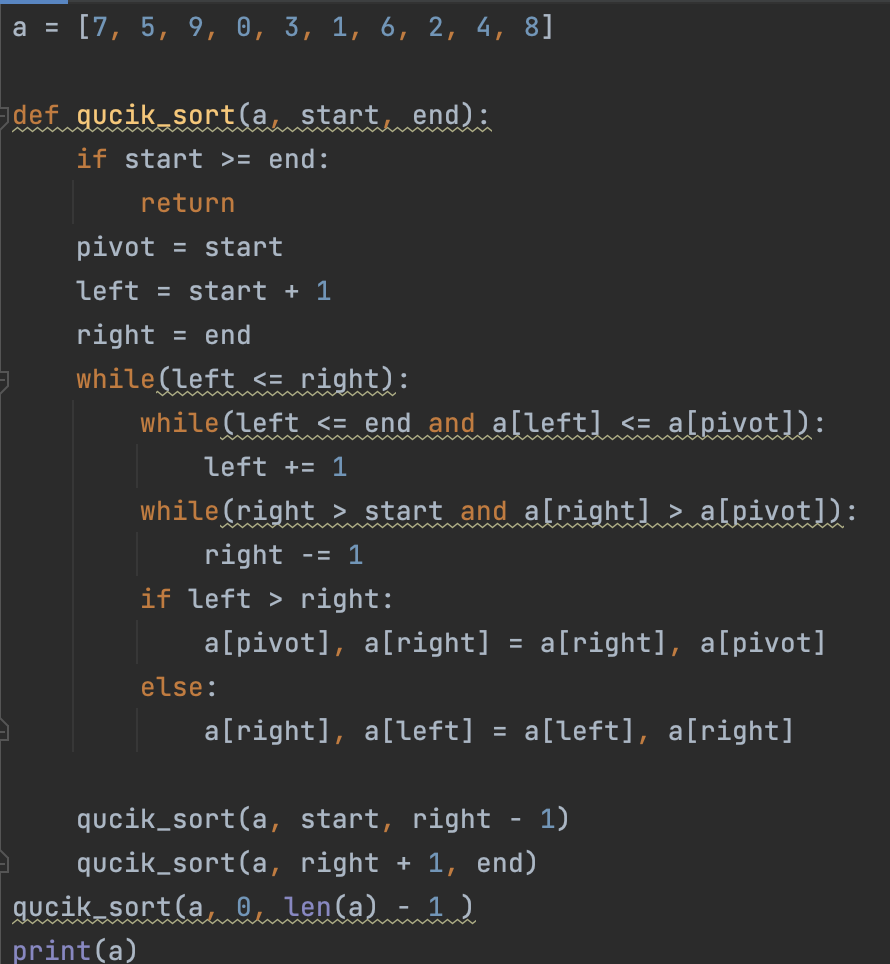
퀵 정렬은 평균의 경우 O(nlogn)의 시간 복잡도를 가진다.
하지만 최악의 경우 O(n^2)의 시간 복잡도를 가진다.
간결한 퀵 정렬 코드예시)

이 처럼 퀵 정렬은 재귀적으로 반복수행 하는것을 알 수 있다.
계수 정렬
- 특정한 조건이 부합할 때만 사용할 수 있지만 매우 빠르게 동작하는 정렬이다.
- 계수 정렬은 데이터의 크기 범위가 제한되어 정수 형태로 표현할수 있을때 사용가능.
코드 예시)
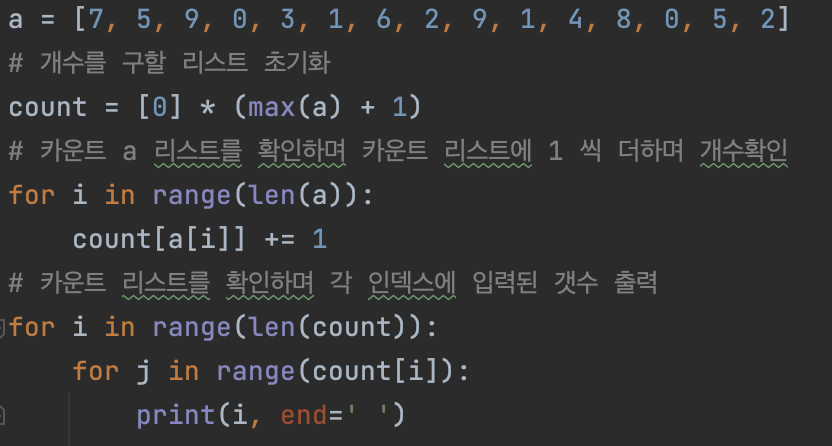
데이터 개수가 n, 데이터 중 최댓값이 k 일때 최악의 경우에도 O(N+K)수행시간을 보장.
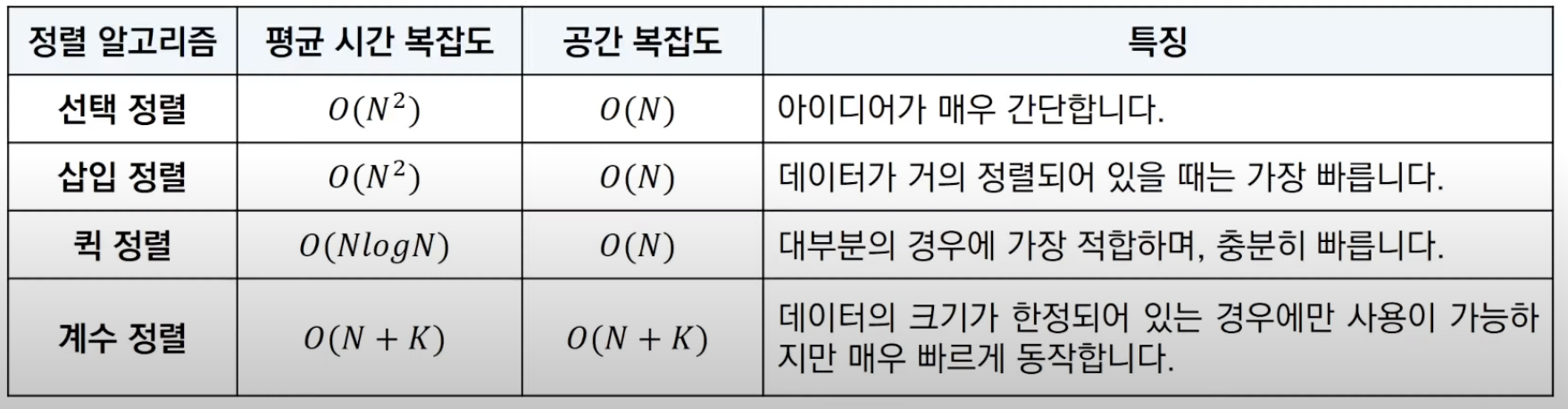
마치며
각 정렬들의 비교 표 이다.

:)