이전게시물 에 프로젝트에 도입할 필요성을 못느껴 간단하게 정리하려했으나 도입하게 되어 공식문서를 참조하여 변경사항을 정리하고 공식문서에 있는 예시를 확인하며 사용법을 익히고자 새로 게시물로 옮겼습니다. 주요 사용법이 deprecated 되어 이전버전과 비교하며 공부하고자 합니다.
Spring batch 란?
Spring batch
아키텍처
Spring batch는 계층형 이고 다음 사진과 같다.
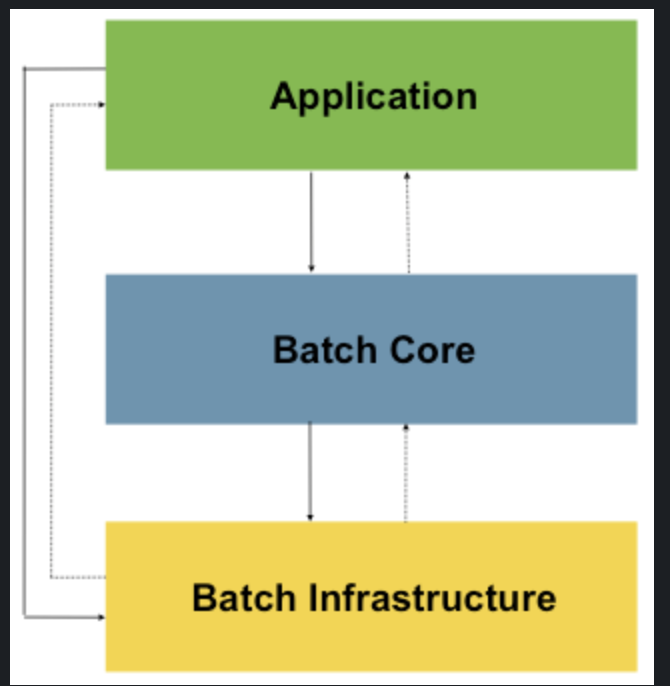
-
Application
Spring Batch를 사용하여 개발자가 작성한 모든 배치 작업과 사용자 정의 코드를 포함합니다. -
Batch Core
배치 작업을 시작하고 제어하는데 필요한 핵심 런타임 클래스를 포함하고 있습니다.
구성: JobLauncher, Job, Step
애플리케이션과 코어 모두 공통 인프라스트럭처 위에 구축됩니다
- Batch Infrastructure
Job의 흐름과 처리를 위한 틀을 제공하며 Reader, Processor, Writer 등이 속합니다.
동작과정
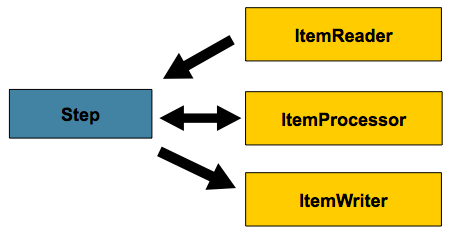
spring batch는 job 1-1..m step - (reader, processor,writer)
혹은 job 1-1..m step - tasklet 으로 구성됩니다.
tasklet은 단순한 작업을 수행합니다. 밑에 제가 프로젝트코드 작성한것처럼 규모가 크지않은 작업에 사용하면 될것같습니다.
Chunk Oriented Processing 은 위/아래 사진처럼 구현됩니다.
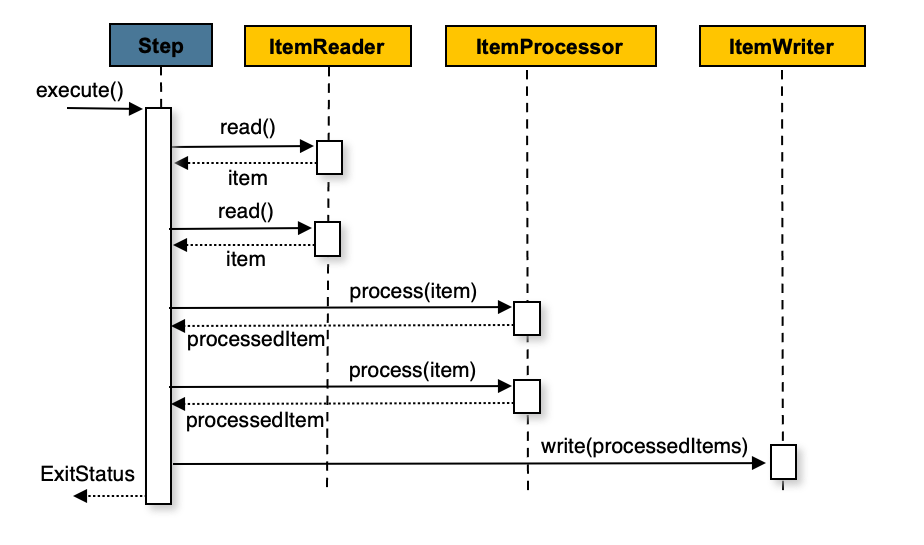
위 사진은 Chunk Oriented Processing 의 진행 방식입니다. 코드는 아래의 튜토리얼을 통해 확인하시면 되겠습니다.
궁금한점
- Transaction 은 어디에서 걸리는걸까??
Job, Step, Tasklet 을 확인해봤을때 Transaction 을확인하진 못했지만 Step내에서 Exception이나 실패를할 경우 전부 Rollback이 되는것을 확인했습니다.
Job은 동일한내용에 대해 실행하지 않습니다.
deprecated 목록
이전 버전에서 자주 사용하는 것중 deprecated 되는것 입니다.
- JobBuilderFactory
- StepBuilderFactory
기존에 JobBuilderFactory.get 으로만 하던걸 JobRepository를 추가 해야합니다.
StepBuilderFactory 도 동일합니다. 좀 더 자세한 사항은 아래에 정리해놨습니다.
5.0 이후 변경 사항
@EnableBatchProcessing 를 사용해 작업 저장소에서 Spring Batch가 어떤 데이터 소스와 트랜잭션 매니저를 설정해야 하는지 다음과 같이 지정할 수 있습니다
@Configuration
@EnableBatchProcessing(dataSourceRef = "batchDataSource", transactionManagerRef = "batchTransactionManager")
public class MyJobConfiguration {
@Bean
public Job job(JobRepository jobRepository) {
return new JobBuilder("myJob", jobRepository)
//define job flow as needed
.build();
}
}- BatchConfigurer를 정의할 필요가 없어짐
이 예시에서, batchDataSource와 batchTransactionManager는 애플리케이션 컨텍스트의 빈들을 참조함.
빈의 설정을 위해 @EnableBatchProcessing을 사용하는 대안으로 DefaultBatchConfiguration이라는 새로운 설정 클래스를 사용할 수 있습니다. 이 클래스는 필요에 따라 사용자 정의할 수 있는 기본 설정의 인프라스트럭처 빈을 제공합니다.
@Configuration
class MyJobConfiguration extends DefaultBatchConfiguration {
@Bean
public Job job(JobRepository jobRepository) {
return new JobBuilder("myJob", jobRepository)
//define job flow as needed
.build();
}
}사용자 정의 매개변수는 해당 getter를 오버라이딩하여 지정할 수 있습니다. 예를 들어, 다음 예시는 작업 저장소와 작업 탐색기에서 사용하는 기본 문자 인코딩을 어떻게 오버라이드하는지 보여줍니다
@Configuration
class MyJobConfiguration extends DefaultBatchConfiguration {
@Bean
public Job job(JobRepository jobRepository) {
return new JobBuilder("job", jobRepository)
// define job flow as needed
.build();
}
@Override
protected Charset getCharset() {
return StandardCharsets.ISO_8859_1;
}
}요약
- 이번 릴리스에서는 JUnit5 로 마이그레이션 됨
- EnableBatchProcessing으로 JobOperator 자동 등록
- Java 17, spring framework 6 기반
Spring batch tutorial(
배치 듀토리얼 을 참고한 배치 v5 의 튜토리얼 입니다.
- Person : 이름 과 성의 필드값을 가짐
- PersonItemProcessor : 이름 과 성을 대문자로 치환
- BatchConfiguration : reader, process, writer, Job, step 을 bean에 등록하고 어떤것을 어떻게 실행할지 작성
- JobCompletionNotificationListener: Job 이 완료되면 모든 Person 객체를 조회하고 콘솔에 출력합니다.JdbcTemplate 을 활용
- sample-data: reader가 읽을 init-data 입니다.
- schema-all: tabel 생성하는 sql script 입니다.
Person Entity
public class Person {
private String lastName;
private String firstName;
public Person() {
}
public Person(String firstName, String lastName) {
this.firstName = firstName;
this.lastName = lastName;
}
public void setFirstName(String firstName) {
this.firstName = firstName;
}
public String getFirstName() {
return firstName;
}
public String getLastName() {
return lastName;
}
public void setLastName(String lastName) {
this.lastName = lastName;
}
@Override
public String toString() {
return "firstName: " + firstName + ", lastName: " + lastName;
}
}엔티티와 비슷한 의미를 가지는 엔티티입니다. 이름과 성의 필드 값을 가집니다.
ItemProcessor를 구현하는 PersonItemProcessor
public class PersonItemProcessor implements ItemProcessor<Person, Person> {
private static final Logger log = LoggerFactory.getLogger(PersonItemProcessor.class);
@Override
public Person process(final Person person) throws Exception {
System.out.println("process");
final String firstName = person.getFirstName().toUpperCase();
final String lastName = person.getLastName().toUpperCase();
final Person transformedPerson = new Person(firstName, lastName);
log.info("Converting (" + person + ") into (" + transformedPerson + ")");
return transformedPerson;
}
}입력받은 Person 객체의 필드값(이름, 성) 을 대문자로 치환 하는프로세스 입니다.
BatchConfiguration @EnableBatchProcessing생략
@Configuration
public class BatchConfiguration {
@Bean
public FlatFileItemReader<Person> reader() {
System.out.println("reader 실행");
return new FlatFileItemReaderBuilder<Person>()
.name("personItemReader")
.resource(new ClassPathResource("sample-data.csv"))
.delimited() // .delimited().delimiter("|")
.names(new String[]{"firstName", "lastName"})
.fieldSetMapper(new BeanWrapperFieldSetMapper<Person>() {{
setTargetType(Person.class);
}})
.build();
}
@Bean
public PersonItemProcessor processor() {
System.out.println("processor 실행");
return new PersonItemProcessor();
}
@Bean
public JdbcBatchItemWriter<Person> writer(DataSource dataSource) {
System.out.println("writer 실행");
return new JdbcBatchItemWriterBuilder<Person>()
.itemSqlParameterSourceProvider(new BeanPropertyItemSqlParameterSourceProvider<>())
.sql("INSERT INTO people (first_name, last_name) VALUES (:firstName, :lastName)")
.dataSource(dataSource)
.build();
}
@Bean
public Job importUserJob(JobRepository jobRepository,
JobCompletionNotificationListener listener, Step step1) {
System.out.println("importUserJob");
return new JobBuilder("importUserJob", jobRepository)
.incrementer(new RunIdIncrementer())
.listener(listener)
.flow(step1)
.end()
.build();
}
@Bean
public Step step1(JobRepository jobRepository,
PlatformTransactionManager transactionManager, JdbcBatchItemWriter<Person> writer) {
System.out.println("Step1");
return new StepBuilder("step1", jobRepository)
.<Person, Person> chunk(10, transactionManager)
.reader(reader())
.processor(processor())
.writer(writer)
.build();
}
}동작 순서를 확인하기 위해 println 을 추가했습니다.
Reader
- FlatFileItemReader<> 를 사용합니다 DB가 아닌 Reasouce에서 데이터를 읽어올 수 있도록 구현된 구현체
- Resource 종류가 많지만 자주 사용되는것들을 추려보면
여기서는 ClassPathResource 를 사용하여 sample-data.csv 에있는 정보를 read합니다.-ClassPathResource: 클래스 경로에서 리소스를 로드합니다.이는 주로 애플리케이션의 클래스 경로에 있는 설정 파일에 액세스하는 데 사용됩니다. -FileSystemResource: 파일 시스템에서 리소스를 로드합니다. 이는 일반적으로 애플리케이션 외부에서 리소스에 액세스할 필요가 있을 때 사용됩니다. -UrlResource: Java의 java.net.URL을 기반으로 하는 리소스로, 파일 시스템 리소스, HTTP 리소스, FTP 리소스 등을 로드할 수 있습니다. -ServletContextResource: 웹 애플리케이션의 서블릿 컨텍스트를 기반으로 한 리소스로, 웹 애플리케이션 루트에서 상대 경로를 사용하여 리소스를 로드합니다. - delimited / delimiter
delimited 을 사용하면 한 라인에서 각각의 컬럼을 어떤 구분자로 구분할 것임을 나타낸다.
기본 구분자는 ,(comma) 이며 다른 구분자를 사용하고 싶을 경우 delimiter로 지정해 준다. 주석처리된 예시는 | 로 구분 할때 사용 - names
파일 내 각각의 컬럼명 지정.
String 배열이나, 여러개의 String 파라미터를 컬럼 순서대로 넘겨줄 수 있다. - targetType
targetType 을 통해, 매핑되서 반환될 dto를 지정한다.
각각의 컬럼명에 맞게 데이터가 들어가서, 파일을 읽은 결과가 해당 dto로 반환된다.
// fieldSetMapper 정리 추가 해야함
Processor
작성했던 PersonItemProcessor 를 사용하기 위해 bean에 등록
writer
튜토리얼에서는 ORM 을 사용하지 않기때문에 JdbcBatchItemWriterBuilder 를 빌드 해줍니다.
JobExecutionListener를 구현하는 JobCompletionNotificationListener
@Component
public class JobCompletionNotificationListener implements JobExecutionListener {
private static final Logger log = LoggerFactory.getLogger(JobCompletionNotificationListener.class);
private final JdbcTemplate jdbcTemplate;
@Autowired
public JobCompletionNotificationListener(JdbcTemplate jdbcTemplate) {
this.jdbcTemplate = jdbcTemplate;
}
@Override
public void afterJob(JobExecution jobExecution) {
if(jobExecution.getStatus() == BatchStatus.COMPLETED) {
log.info("!!! JOB FINISHED! Time to verify the results");
jdbcTemplate.query("SELECT first_name, last_name FROM people",
(rs, row) -> new Person(
rs.getString(1),
rs.getString(2))
).forEach(person -> log.info("Found <{{}}> in the database.", person));
}
}
}sample-data.csv
Jill,Doe
Joe,Doe
Justin,Doe
Jane,Doe
John,Doeschema-all.sql
DROP TABLE people IF EXISTS;
CREATE TABLE people (
person_id BIGINT IDENTITY NOT NULL PRIMARY KEY,
first_name VARCHAR(20),
last_name VARCHAR(20)
);프로젝트에 적용하기(Monolithic)
이번엔 모놀리식 환경에서 Mysql을 사용하여 연동하고자 합니다. spring batch에서는
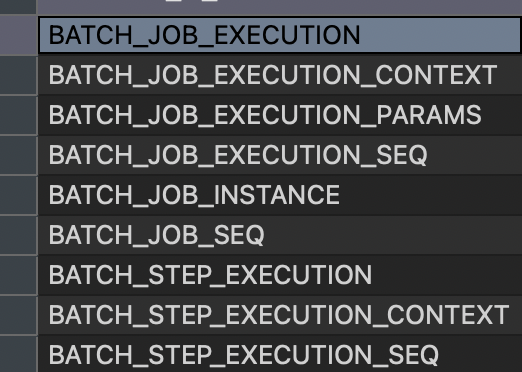
다음과 같은 테이블들을 자동으로 만들어줍니다.
application.yml에 아래와 같이 작성해줍니다.
spring:
batch:
jdbc:
initialize-schema: alwaysalways - 스키마를 자동으로 생성
never - 비활성화,
embedded - 내장DB일때만 실행
프로젝트 코드
BatchConfiguration
@Configuration
@Slf4j
@RequiredArgsConstructor
public class BatchConfiguration {
private final SolvedApiService solvedApiService;
private final MemberService memberService;
private final ApplicationEventPublisher publisher;
@Bean
public Job testJob(JobRepository jobRepository, Step step) {
return new JobBuilder("solved", jobRepository)
.start(step)
.build();
}
@Bean
public Step testStep(JobRepository jobRepository, Tasklet tasklet, PlatformTransactionManager transactionManager) {
return new StepBuilder("step1", jobRepository)
.tasklet(tasklet, transactionManager).build();
}
@Bean
public Tasklet tasklet() {
return ((contribution, chunkContext) -> {
System.out.println("멤버별 solved count 테스크렛");
RsData<List<Member>> memberList = memberService.getAll();
for (Member member : memberList.getData()) {
try {
Long memberId = member.getId();
System.out.println(member.getBaekJoonName());
Optional<Integer> Bronze = solvedApiService.getSolvedCount(memberId, 1, 6);
if (Bronze.get() == -1) {
continue;
}
int bronze = Bronze.get() - member.getBronze();
Thread.sleep(1000);
int Silver = solvedApiService.getSolvedCount(memberId, 6, 11).get() - member.getSliver();
Thread.sleep(1000);
int Gold = solvedApiService.getSolvedCount(memberId, 11, 16).get() - member.getGold();
Thread.sleep(1000);
int Platinum = solvedApiService.getSolvedCount(memberId, 16, 21).get() - member.getPlatinum();
Thread.sleep(1000);
int Diamond = solvedApiService.getSolvedCount(memberId, 21, 26).get() - member.getDiamond();
Thread.sleep(1000);
int Ruby = solvedApiService.getSolvedCount(memberId, 26, 31).get() - member.getRuby();
Thread.sleep(1000);
BaekJoonDto dto = new BaekJoonDto(Bronze.get(), Silver, Gold, Platinum, Diamond, Ruby);
publisher.publishEvent(new BaekJoonEvent(this, member, dto));
} catch (NullPointerException e) {
log.info("###############" + e + "###############");
e.printStackTrace();
}
}
return RepeatStatus.FINISHED;
} );
}
}Read, process, write 로 나누고 step을 여러개 해보고싶지만 단계별로 적용하고자 합니다. tasklet 에 기존 scheduler 메서드 내용을 그대로 넣었고 실행 해봤습니다.
BatchScheduler
@Configuration
@RequiredArgsConstructor
public class BatchScheduler {
private final JobLauncher jobLauncher;
private final BatchConfiguration batchConfiguration;
private final JobRepository jobRepository;
private final PlatformTransactionManager transactionManager;
private final Tasklet tasklet;
@Scheduled(cron = "${scheduler.cron.member}")
public void runJob() throws JobParametersInvalidException, JobExecutionAlreadyRunningException, JobRestartException, JobInstanceAlreadyCompleteException, ParseException {
JobParameters jobParameters = new JobParameters();
System.out.println("스케줄링 하는중임");
jobLauncher.run(batchConfiguration.testJob(jobRepository, batchConfiguration.testStep(jobRepository,tasklet , transactionManager)),
new JobParametersBuilder().addDate("date", new Date()).toJobParameters());
}
}배치 프로그램에 스케줄러 기능을 추가하기위하 클래스 입니다.
chunk vs tasklet
성능비교 는 여기에 정리했습니다.
추가 정리 필요:
- fieldSetMapper
참고
https://docs.spring.io/spring-batch/docs/current/reference/html/index.html
