현 상황과 개선방향
AS-IS
Service 마다 database 를 구성하고 싶었지만 컴퓨터 리소스가 부족해 2개의 database 만 사용하고 있었습니다.

👿 문제 상황
- 2개의 DB 가 있지만 모종의 이유로 둘중 1개가 사용이 불가 하다면 서비스가 중단되어 버리는 문제
하지만 서비스마다 DB를 구성하고, 이중화를 한다면 최소 n * 2 를 관리해줘야 하는데 서버가 증설되어도 부담 스럽고 secondary storage 가 분리되어 있는것이 아니라면 현재 상태에서 유의미한 다중화가 아니라고 판단 하였습니다. 현재 물리적인 서버는 2개이기 때문이죠 따라서 2개의 Database 를 구성하고 Active-Standby(hot) 으로 이중화 및 장애 대응을 해보고자 합니다.
이중화 구성
Standby Database 구성
먼저 2개로 운용중인 Database 를 통합 하겠습니다.
- Database 데이터 동기화
많은 데이터도 아니고 같은 인스턴스에 있기에 docker volume 을 복사 해도 되고 mysqldump 를 해도 문제가 없었지만 저는 mysqldump 로 복제를 하겠습니다.
mysqldump
mysqldump -u -p --databases findmypet > dump.sql
dump 파일 옮기기
docker cp dump.sql target:/dump.sql
dump 파일 실행
mysql -u -p < /dump.sql
데이터가 많거나 운영중인 서비스에선 다음과 같은 명령어는 조심해야 합니다. MySQL 에서 제공하는 --single-transaction 과 같은 다양한 옵션들을 고려하는걸 권장합니다.
-
connection 수 조절
참고자료
Database transaction 의 tps 와 client 의 수에 맞춰 max_connection 을 설정하고 그 이상의 연결을 제한 하는것을 권장하고 있습니다. -
gtid 구성
MySQL 5.7.6 이후 버전은 online 으로 언제든지 gtid 가 사용 가능 해졌습니다.
물론 offline 에서 절차도 여전히 유효합니다. 절차는 다음과 같습니다.
- 모든 쓰기 작업을 비활성화합니다.
- 모든 트랜잭션이 마스터에서 모든 슬레이브로 전파될 때까지 기다립니다.
- 모든 서버를 중지합니다.
- 각 서버에서 구성 파일에서 gtid-mode=ON을 설정합니다.
- 모든 서버를 시작합니다.
- 쓰기 작업을 활성화합니다.
기존 방식의 문제점은 gtid 로전환할때 downtime 이 존재한다는 것 인데요.
💡사전조건
모든 mysql 이 5.7.6 이후 버전을 사용해야 합니다.
기존 사용중인 Database 를 gtid를 사용하기 위해선 3가지를 확인 해야합니다.
✅ check 1. 워크로드가 GTID와 호환되는지 확인
호환 되는지 확인 후 my.cnf 에서
SET @@GLOBAL.ENFORCE_GTID_CONSISTENCY = ON, and set enforce-gtid-consistency=ON
를 다시 시작하더라도 유지되도록 합니다.
✅ check 2. 모든 서버가 GTID를 생성하도록 합니다
SET @@GLOBAL.GTID_MODE = OFF_PERMISSIVE, and set gtid-mode=OFF_PERMISSIVE
SET @@GLOBAL.GTID_MODE = ON_PERMISSIVE, and set gtid-mode=ON_PERMISSIVE
여기서 중요한 점은 OFF_PERMISSIVE 를 먼저 선행하고 ON_PERMISSIVE 을 설정해줘야 합니다.
✅ check 3. 모든 서버를 GTID 전용으로 설정합니다
- Step1
SHOW STATUS LIKE ‘ONGOING_ANONYMOUS_TRANSACTION_COUNT’;가 0 이 될때까지 기다립니다. - Step2
이후에 존재했던 모든 트랜잭션이 모든 서버에 복제될 때까지 기다립니다 - Step3
지금까지 존재하는 binlog 에는 gtid 가 없는 트랜잭션이 포함될 수 있습니다.
기존 binlog 가 만료될때까지 기다립니다. (필요가 없다면 삭제 합니다. 하지만 올바른 백업 프로세스를 기다리는게 더 좋습니다.) - Step4
각 서버에서 FLUSH LOGS를 실행한 다음 SHOW MASTER STATUS를 실행합니다. 각 서버에서 SHOW MASTER STATUS가 보고한 파일 이름을 확인 후, 이보다 오래된 바이너리 로그가 모두 제거되거나 만료될 때까지 기다립니다 - Step5
SET @@GLOBAL.GTID_MODE = ON, and set gtid-mode=ON를 통해 gtid mode 를 실행 합니다. - Step6
슬레이브가 GTID를 사용하여 복제 위치를 추적하도록 자동 위치 지정 프로토콜을 사용하려는 경우 지금 바로 사용할 수 있도록 합니다.
STOP SLAVE;
CHANGE MASTER TO MASTER_AUTO_POSITION = 1;
START SLAVE;만약 다중 multi-source replication 이라면 아래 명령어를 채널 만큼 반복해줍니다.
STOP SLAVE FOR CHANNEL 'ch';
CHANGE MASTER TO MASTER_AUTO_POSITION = 1 FOR CHANNEL 'ch';
START SLAVE FOR CHANNEL 'ch';Application 수준에서 failover 대응
Application 에서 DB 장애 대응은 Exception 을 식별하고 Connection 을 사용 가능한 database로 변경해줘야 합니다. 제가 알고있는 Connection 을 변경하는 방법은 3가지가 있습니다.
1️⃣ 데이터베이스 드라이버의 Failover 기능 활용
참조: mysql docs
2️⃣. 애플리케이션 레벨에서 동적 데이터 소스 전환 구현
3️⃣ 외부 로드 밸런서/프록시 솔루션 활용
HAProxy 와 같은 외부 프록시/로드밸런서를 활용하면, 애플리케이션은 단일 접속 엔드포인트를 사용하고, 프록시가 백엔드의 여러 데이터베이스 인스턴스 중에서 헬스 체크에 따라 정상 인스턴스로 트래픽을 분산시킬 수 있습니다.
TO-BE

가장 이상적인 그림은 동시성 문제가 나지 않으며 Application 에서의 수정은 최소화 되며 Write, read 가 확장 가능한 구조가 이상적이라고 생각합니다.
Mysql 의 group replication 이나 InnoDB Cluster 과 같은 솔루션들이 있지만 모든 문제를 해결해주지도 않을 뿐더러 현 상황에선 리소스를 절약해야 하는 상황이기에 서비스 규모가 점차 커진다면 점진적으로 개선해 나갈 예정입니다.
GAP
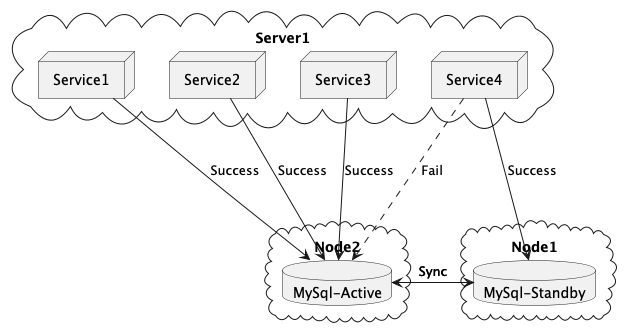
저는 현재 Database 를 사용하는 서비스는 모두 Spring 으로 구성되어 있으며, 공통으로 관리하는 모듈로 인해 간단히 추가 할 수 있습니다. 또한 추가될 예정인 Webosocket 서버는 MySQL을 사용하지 않아 빠르게 전환이 가능하며 downtime 을 최소화 하고 구성이 좀 더 간단하며 보다 유연하게 수정 할 수 있는 Application 수준에서 관리를 선택했습니다.
