개요
현재, 운영 중인 서비스(잡다)에서는 타 서비스와의 통신을 Kafka 메시지 큐를 사용하여 통신 중이다.
타 서비스와 연동된 기능에 이슈가 있을 경우 원본 Topic 데이터가 필요할 때가 있고
이슈 파악을 위해 타 서비스에서 프로듀싱이 실제 되었고 운영 중인 서비스에 잘 컨슈밍 되었는지에 대한 여부가 필요한 케이스가 존재한다.
운영 중인 서비스에서는 아래와 같은 이슈가 있었다.
첫번째 이슈
올해 초 운영 중인 서비스에서는 신입 공채 운영을 하여 첫 매칭 프로세스를 진행하였는데 사용자들에게탈락, 합격 메시지가 중복으로 4번씩 보내지게 된 이슈가 있었다.
해당 이슈를 보고 잡다 쪽에서 여러 번 소비가 된 건지, 로직 상의 문제가 있는지 체크 후 정상적으로 보여 잡다 쪽은 conumer 성공에 대한 로그를 찍고 있지 않았기 때문에 타 서비스(ATS) 쪽으로 프로듀싱이 정확히 1번 이루어진 건지 확인 요청을 드렸으나 1번만 발행되었다고 이야기를 전달받았다.
하지만, 그 이후에도 지속적으로 원인 파악이 안 되어 Devops에 토픽 데이터 요청하여 분석해보니 실제 4번 발행되었던 내역이 있었다.
위처럼, 어느 서비스에서 문제가 발생한 것인지 정확하게 판단이 어렵고 개발자 간의 소통으로 데이터 유무를 판단하게 되면 잘못된 정보를 받아 이슈 해결에 난항을 겪을 수 있다.
이러한 데이터 확인을 위해 로깅 데이터 적재가 필요해 보이고
변경은 자주 안일어나고 조회가 많은 로그 데이터 특성상 NoSQL 의 도입이 필요해보이고 특정 주기로 DB에서 삭제하고 특정 기간이 지난 로깅 데이터는 S3에 저장하는 등의 처리가 필요해보인다.
이 부분의 니즈를 충족시켜줄 수 있는 것이 ELK 스택이다.
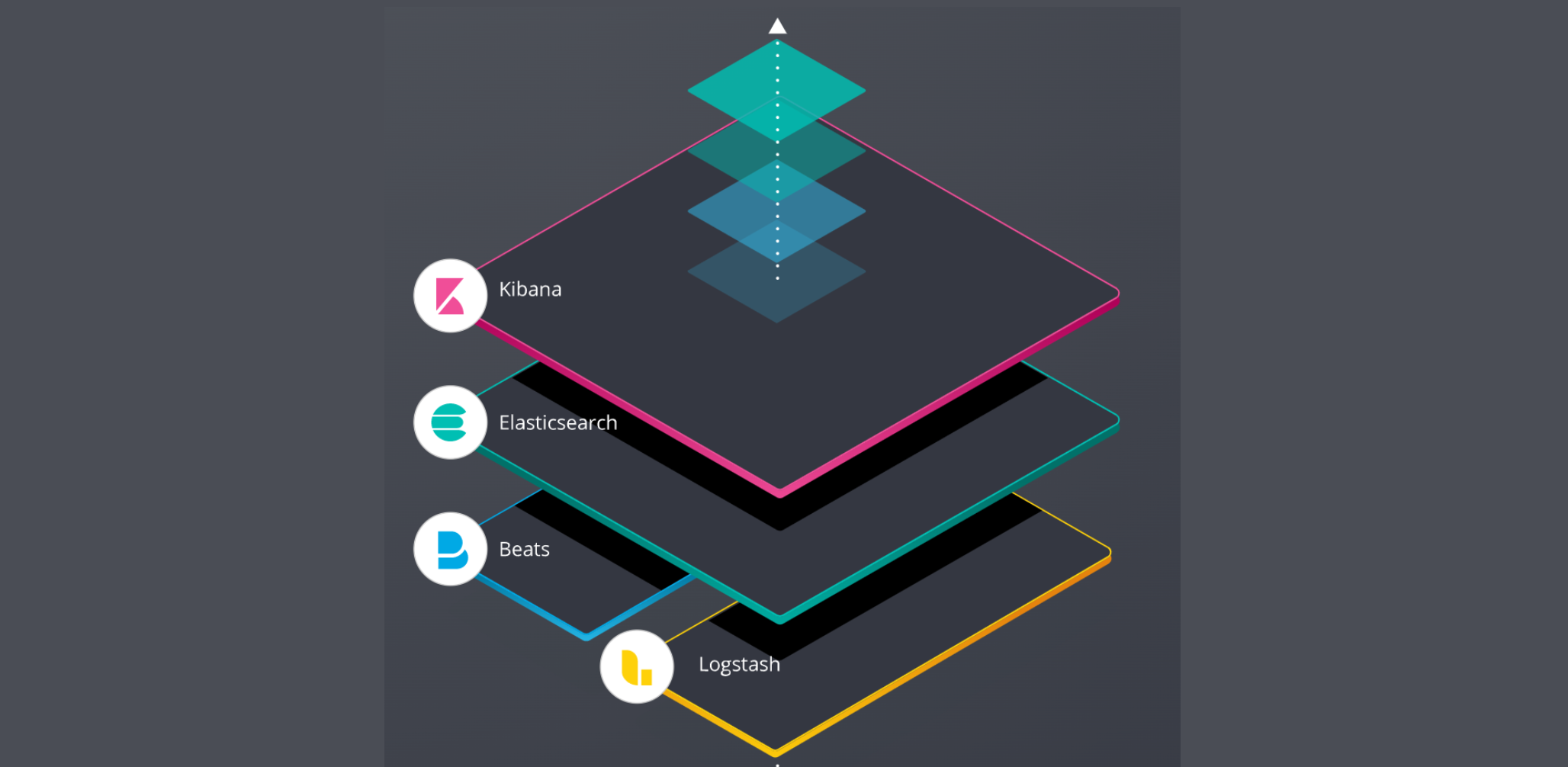
ELK란 무엇인가?
ELK 는 3가지 오픈 소스 소프트웨어인 분석 및 저장 기능을 담당하는 ElasticSearch, 수집 기능을 하는 Logstash, 시각화 도구인 Kibana의 각각의 앞글자를 따서 만든 단어로 각 제품이 연동되어 데이터 수집 및 분석 툴로 활용된다.
각 소프트웨어의 주요 역할
Logstash
Logstash 는 크게 다음과 같은 과정을 수행한다.
💡 입력(Inputs) ➡️ 필터(Filters) ➡️ 출력(Outputs)
입력(Inputs) 에서는 다양한 데이터 저장소로부터 데이터를 입력받는 작업
필터(Filters) 을 통해 데이터를 확장, 변경, 필터링 및 삭제 처리하는 가공 작업
출력(Outputs) 을 통해 다양한 데이터 저장소로 데이터를 전송하는 작업
다양한 데이터 저장소란?
File, Redis, ElasticSearch, RDB, Kafka 등등
ElasticSearch
ElasticSearch 는 Lucene 기반으로 개발된 분산 검색 엔진이다.
ELK 구조에서의 역할은 Logstash를 통해 수신된 데이터를 ElasticSearch에 저장하는 데이터 저장소 역할을 수행한다.
NoSQL 기반 데이터베이스이며 RDB와 다르게 트랜잭션 Rollback을 지원하지 않으나 검색 및 분석 성능이 뛰어나다.
kibana
Kibana 는 사용자에게 분석 결과를 시각화 해주는 소프트웨어로 ElasticSearch에 저장된 데이터들을 시각화하여 차트, 그래프화 또는 로그 데이터를 한번에 모아서 볼 수 있다.
Beats
Beats 는 Logstash의 동작 과정은 거의 유사하고 Logstash에 비해 기능이 제한적이나 리소스가 적게드는 Logstash의 경량화 버전이다.
적은 메모리 사용으로 리소스 절감이 가장 큰 장점이고 각각의 서버에 설치 되어 로그를 수집한 뒤 ElasticSearch나 Logstash로 전송해주는 역할
로그 수집 구성도
이제 운영중인 서비스에 어떻게 적용시킬지 고민해보자.
현재 구조는 컨슈밍이 실패한다거나 프로듀싱이 실패했을 경우에 RDB에 직접 접근하여 저장하고 있다.
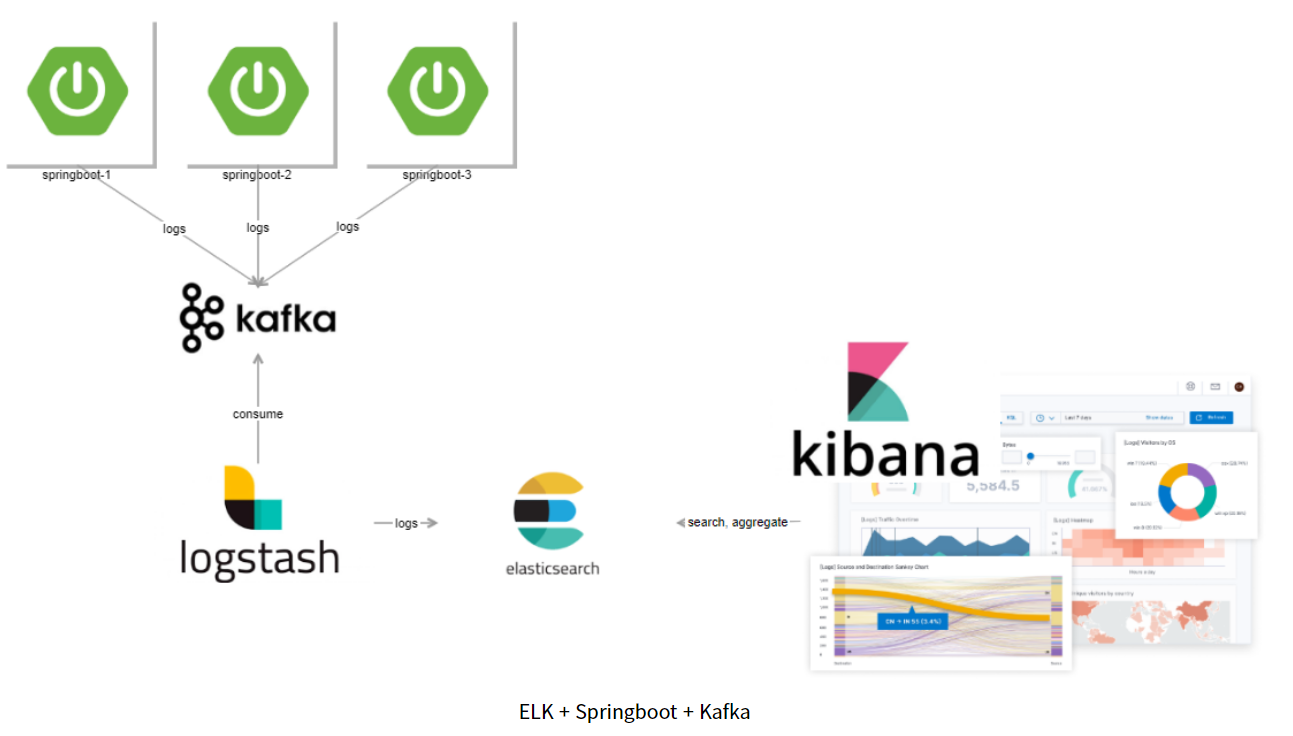
단순히 생각해 보았을 때, ‘RDB에 저장하던 것을 ElasticSearch에 저장하면 되겠다.’ 싶어서 적용하려다가 여러 자료를 찾아보니 과도한 트래픽이 몰렸을 경우에 ELK 스택의 문제로 인해 로그가 손실되는 일이 없도록 Kafka와 같은 이벤트 브로커를 앞단에 두어 사용하는 케이스가 많았다.
- https://www.elastic.co/guide/en/logstash/current/deploying-and-scaling.html
- https://investment-engineer.tistory.com/6?category=979835
- https://aws.amazon.com/ko/opensearch-service/resources/the-benefits-of-the-elk-stack/
처음에 생각하던 구조 (MariaDB를 ElasticSearch로 대체하는 방식)
- Spring WAS 1, Spring WAS 2, … > ElasticSearch > Kibana
높은 고가용성을 생각한 구조 (Kafka와 Logstash)
- Spring WAS 1, Spring WAS 2, … > Kafka > Logstash > ElasticSearch > Kibana
- 카프카는 장애가 발생하면 안되는
SPOF(단일장애점)지점 역할 수행
- 카프카는 장애가 발생하면 안되는
운영중인 서비스는 RDB 또는 ELK 스택이 중단될 만큼 트래픽이 많은 편도 아니라고 생각이 들기도 해서 오버 스펙이 아닌가 생각이 들었지만 이왕 써보는거 가용성까지 고려해서 Kafka까지 도입한 구조로 써보는 것도 좋다고 생각이 들어서 위의 구조로 진행하였다.
- MSK Kafka의 비용이 늘어나는 것은 안 비밀,,
결론
ELK 스택에 대해서 간략하게 알아보았는데
다음 글에서는 실제 ELK 스택을 적용해본 내용을 담아보겠습니다.
