
메시지 압축 도입 개요
다음은 현재 운영하고 있는 서비스(잡다)에서 제공하고 있는 카프카 토픽의 일부입니다.
-
프로필 업데이트 토픽 메시지
{ "profileSn": 0, "id": "string", "user": { "name": "string", "mobile": "string", // ... }, "jobSearch": { "profileImage": { "fileUid": "string", // ... }, "careerType": "NEW", "military": { "status": "NONE", "type": "ARMY", "militaryClass": "PRIVATE", // ... }, "disability": { "grade": "MILD", "type": "LIVER" }, "veteran": { "reason": "string" }, "profileType": "GENERAL", "jobGroups": [ { "jobGroupCode": 1, "jobTitleCodes": [ 0 ] } ], "locations": [ 0 ] }, "education": { "educationLevel": "HIGHSCHOOL", "educations": [ { // ... "schoolCode": 203141, "schoolName": "가곡고등학교", "profileMajors": [ { "majorType": "MAJOR", "majorCode": 1010101, "majorName": "건설산업과", // ... } ], "profileResearches": [ { "attachFiles": [ { "fileUid": "string", // ... } ], "description": "설명" } ] } ] }, // ... 생략 }
신규 배포된 버전에서는 병역&우대사항 , 경력&경험 부분의 프로필 데이터가 추가되면서 메시지 크기가 계속 커져 메시지 압축에 대한 니즈 가 생겼고
그동안은 압축할 만큼 비용이 큰 메시지가 없었다고 판단되었고, 추후 연구 과제로 생각하고 있었지만 앞으로 더 커질 메시지를 대비하여 도입해야 할 시기이어서 메시지 압축 도입을 고려하게 되었습니다.
카프카는 저장 기간(Retention Period)도 존재하고, 레플리카 기능도 제공하기 때문에 디스크 공간을 많이 쓰게 됩니다.
- replication factor가 3개면, 복제본이 2개기 때문에 동일 메시지가 2개씩 더 생겨서 저장
압축을 적용하면, 이 디스크 저장 공간을 효율적으로 쓰고 네트워크 통신 비용, 복제 비용을 낮출 수 있습니다.
- 단, 프로듀서 서버, 컨슈머 서버의 CPU 사용량이 늘어납니다. (자세한 수치는 뒤에)
메시지 압축은 언제 사용하면 좋은가?
사용하면 좋은 경우
- 압축을 활성화하면, 약간의 발송 지연 시간이 생기는데, 이를 허용할 수 있는 경우
- 전송하는 데이터 형식이 서버 로그, XML, JSON 같은 메시지인 경우
- XML, JSON 같이 반복되는 구조
- 서버 로그처럼 정형화된 구조
- XML, JSON 같이 반복되는 구조
- CPU 주기를 더 사용하면서, Disk 와 Network 대역폭 사용량을 절약하기 위한 경우
사용하면 안좋은 경우
- 데이터의 양이 많지 않은 경우
- 빈도가 낮은 데이터는 Batch 처리가 되지 않을 수 있어, 압축 비율이 높지 않음
- 단순 텍스트 데이터인 경우
- 인코딩된 문자열, Base64 문자열인 경우
- 이러한 경우, 고유한 문자 시퀀스를 포함하기 때문에 압축 비율이 높지 않음
- 인코딩된 문자열, Base64 문자열인 경우
- 시간이 매우 중요하여 발송 지연을 허용할 수 없는 경우
프로듀서 ~ 브로커까지 메시지 전달 과정
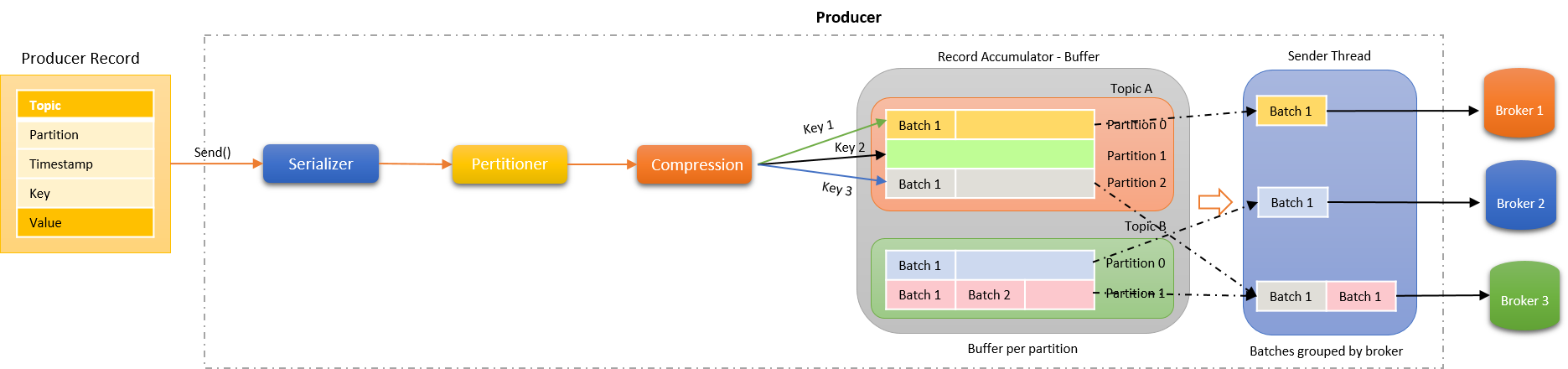
메시지가 발행된 이후 브로커로 전달되는 과정
프로듀서는 다음과 같은 과정을 통해서 메시지를 브로커로 전달
- 직렬화 (Serializer)
- 파티셔닝 (Partitioner)
- 압축 (Compression)
- 메시지 배치 (Record Accumulator)
- 전달 (Sender)
현재, 잡다 서비스와 타 서비스 간의 통신은 3번 압축 과정이 생략되어 있는 구조라고 보면 될 것 같습니다.
뒤에 나올 옵션을 설명하기 위해 이미지에 보이는 Record Accumulator의 기능에 대해 잠깐 알아봅시다.
사용자가 KafkaProducer의 send()를 호출하면 Record가 바로 Broker로 전송되는 것이 아니라 지정된(RecordBatch)만큼 메시지를 RecordAccumulator에 저장한 후 Broker로 전송합니다.
- 메시지를 브로커로 전달하기 전에 동일 partition으로 보낼 메시지들을 배치로 관리하여 Sender로 전달해주는 Buffer 같은 역할입니다.
- 실제로 메시지를 브로커로 요청하여 전달하는 역할은 Sender Thread가 담당합니다.
메시지 압축 종류
카프카의 메시지 압축 종류는 총 4가지입니다.
- Gzip
- Snappy
- Lz4
- Zstd
각각을 비교하여 알아봅시다.
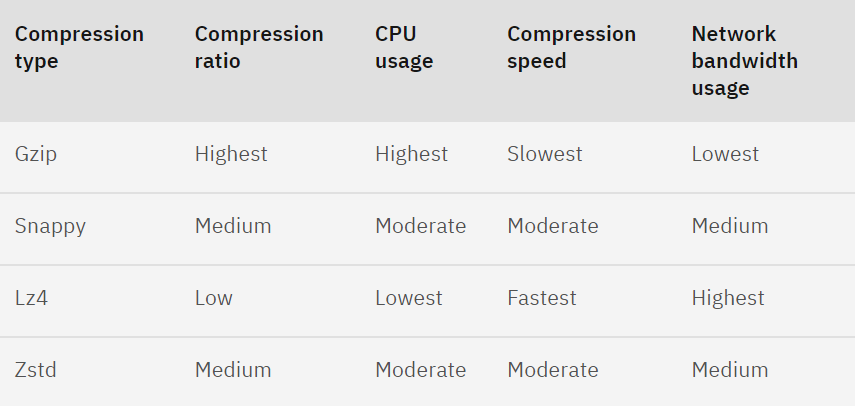
Compression ratio(압축 비율)
압축 비율이 높을 수록 압축 속도가 느리고, 디스크, 네트워크 대역폭 사용량을 줄일 수 있습니다.
Apache Kafka 글로벌 커뮤니티에서 제공한 결과 자료
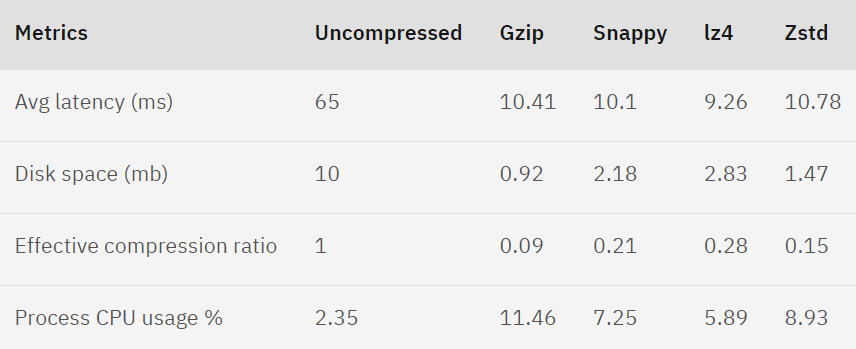
JSON 메시지를 이용하고 있다면, Snappy와 Lz4 와 같은 entropy-less 엔코더를 사용하길 권장하고 있습니다.
Zstd는 Kafka 2.1.0 버전에 등장한 엔코더로 Facebook에서 개발한 압축 알고리즘이고 Snappy 유사하지만 더 많은 압축률과 CPU 사용률로 보입니다.
또한, Lz4처럼 압축률이 가장 낮은 엔코더를 사용하더라도 사용하지 않을 때보다 70% 절약 가능하니 상황에 맞게 적절한 압축 엔코더를 정해서 써야 할 듯합니다.
메시지 압축 적용
메시지 압축 적용은 2가지 방안이 있는데, Topic, Broker 레벨에 압축 옵션을 적용하는 방법도 있고, Producer 쪽에 압축 옵션을 적용하는 방법이 있습니다.
- Producer 레벨에 적용하려면, Topic, Broker 레벨에서
compression.type = producer를 설정해주어야 합니다.- 해당 옵션의 의미는 producer가 보내는 압축 형태를 유지하라는 옵션
- Producer config에
compression.type을 설정합니다.- 컨슈머 설정은 필요 없음(auto detecting)
- https://www.conduktor.io/kafka/kafka-message-compression#Apache-Kafka-Message-Compression-0
@Bean public ProducerFactory<String, String> producerFactory() { Map<String, Object> configs = basicFactoryConfigs(); return new DefaultKafkaProducerFactory<>(configs); } @Bean public KafkaTemplate<String, String> kafkaTemplate() { return new KafkaTemplate<>(producerFactory()); } @Bean public ProducerFactory<String, String> compressionProducerFactory() { Map<String, Object> configs = basicFactoryConfigs(); configs.put(ProducerConfig.COMPRESSION_TYPE_CONFIG, CompressionType.LZ4.name); configs.put(ProducerConfig.LINGER_MS_CONFIG, 5); return new DefaultKafkaProducerFactory<>(configs); } @Bean public KafkaTemplate<String, String> kafkaCompressionTemplate() { return new KafkaTemplate<>(compressionProducerFactory()); }
- https://www.conduktor.io/kafka/kafka-message-compression#Apache-Kafka-Message-Compression-0
- 컨슈머 설정은 필요 없음(auto detecting)
고려해야 할 것
메시지 압축시 고려해야할 프로듀서 옵션은 다음과 같습니다.
compression.type: 프로듀서가 메시지 전송 시 선택할 수 있는 압축 타입batch.size: 레코드 배치의 크기에 관한 설정(bytes) (default is 16384)linger.ms: 레코드 배치의 최대 전송 대기 시간 설정(ms) (default is 0)-
linger.ms가 0인 경우에는 메시지를 바로바로 브로커로 전송할 수 있는 상황에서는 배치가 쌓일 때까지 기다리지 않고 전송
-
이 옵션을 설정해주어야 브로커로 발송하기 전에
Record Accumulator의 레코드 배치를 지연 시간 만큼 대기 후 가져옴- 이유는 부하 상황에 브로커 요청 수를 줄이기 위함 (다음 메시지를 바로 보내지 않고 딜레이 시간을 주는 것)
-
RecordBatch 생성 시 사용하는 Buffer Size는
batch.size설정값과 저장할 Record Size 중에서 큰 값으로 결정됩니다.
- 한 파티션에batch.size만큼의 레코드가 있으면,linger.ms값을 무시하고 발송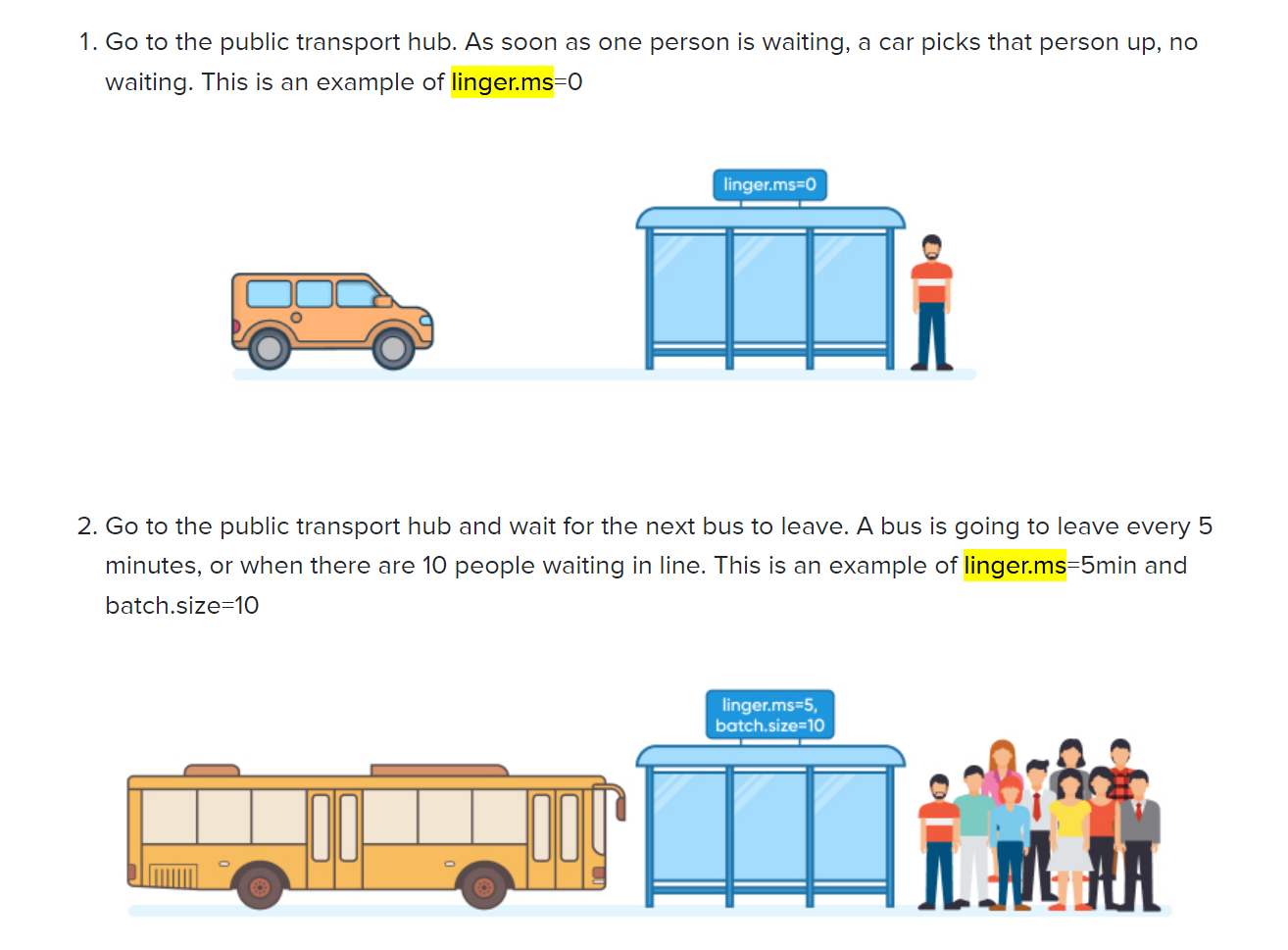
-
테스트

데이터는 총 2개
- 첫번째 데이터는 압축 설정 안하고 토픽에 데이터 넣음
- 두번째 데이터는 Snappy 압축 설정한 뒤 토픽에 데이터 넣은 상태
압축된 데이터를 포함한 토픽을 이대로 컨슈밍하여, 데이터를 쌓아보면 정상적으로 데이터가 확인됩니다.

그럼 뭐 압축이 제대로 된건가..?
의아한데 제대로 압축이 된건지 로컬에서 검증해보면 다음과 같습니다.
해당 파일에 카프카 스토리지의 세그먼트 로그가 저장됩니다.
아래 저장된 경로의 파일에 kafka-run-class 명령어를 입력하면 결과를 확인할 수 있습니다.
./kafka-run-class.bat kafka.tools.DumpLogSegments --files /c/tmp/kafka-logs/jobda.v1.test-0/00000000000000000000.log --print-data-log | grep compresscodec
그런데, 압축한 데이터의 size가 더 크다?
- 데이터가 워낙 작다보니 암호화 정보를 담는게 원본보다 더 커지는 듯합니다.
운영 중인 프로필 업데이트 토픽의 Json 데이터를 넣어서 테스트 해보았을때는 원본의 40% 수준으로 압축

반복되는 Json 데이터 크기를 조금 늘려서 테스트 해보니 다음처럼 암호화 적용 시킨 데이터가 원본의 10% 수준으로 압축된 것을 볼 수 있습니다. (반복되는 데이터를 넣었더니 압축률이 매우 높다)

레퍼런스
메시지 전달 과정
Naver D2 카프카 Client 구조 분석
메시지 압축 정리
- https://developer.ibm.com/articles/benefits-compression-kafka-messaging/
- https://hardenkim.tistory.com/72
메시지 압축률 안나와서 고생한 글
linger.ms batch.size 관련 글
