
🙄 데이터 클리닝 (완결성)
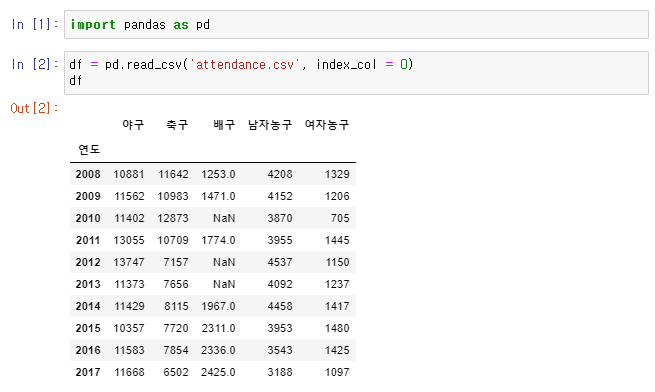
👉 결측값이 존재하는 배구 Column
👉
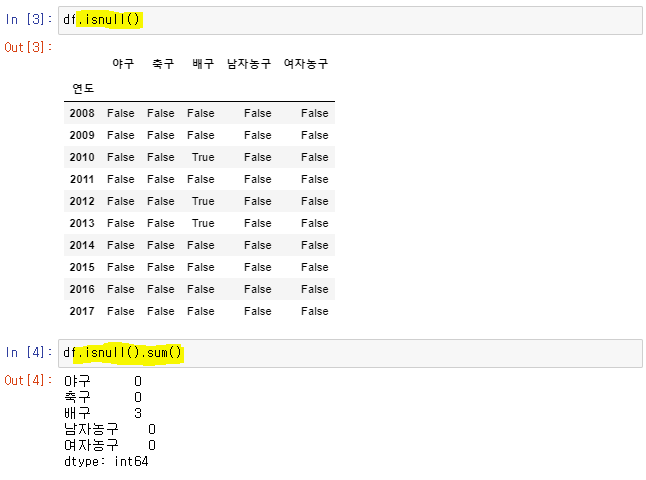
df.isnull(): 결측값은 True로 반환
👉df.isnull().sum(): 결측값의 총 개수 출력
👉
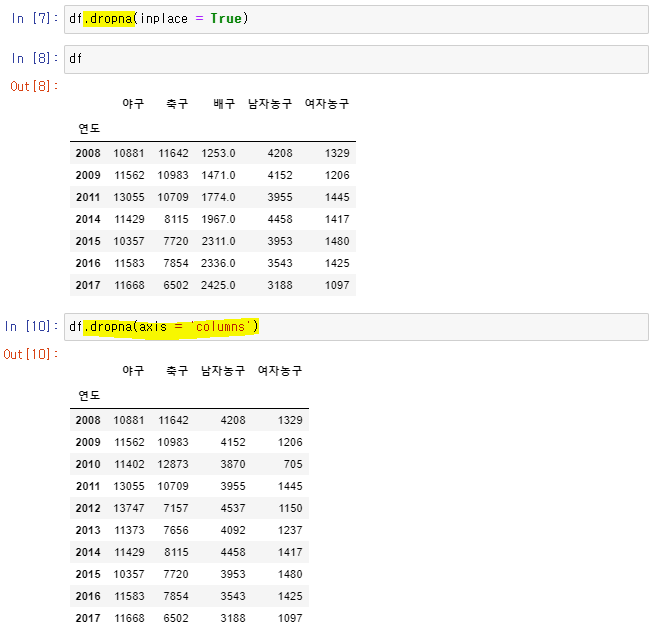
df.dropna(inplace = True): 결측값이 있는 row 삭제
👉df.dropna(axis = 'columns'): 결측값이 있는 column 삭제
👉
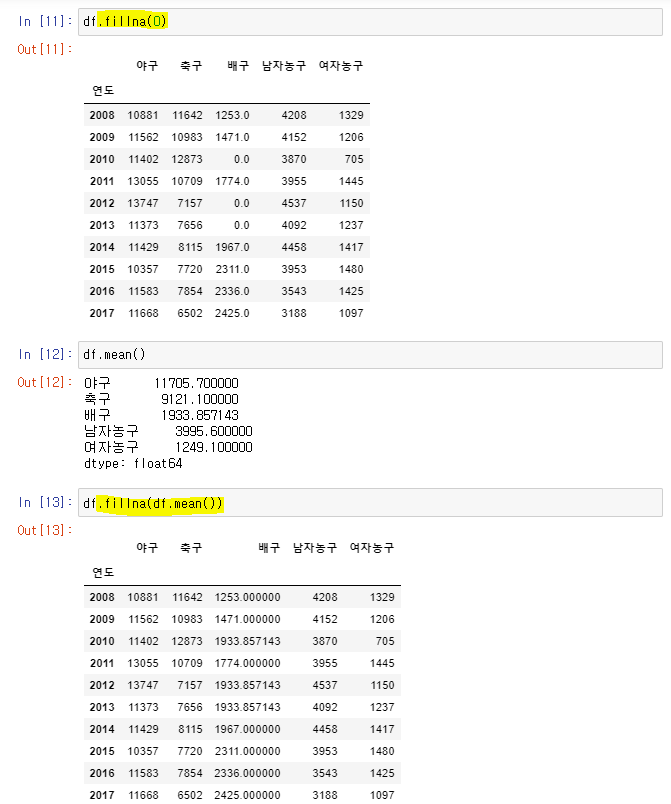
df.fillna(0): 결측값을 모두 0으로 변경
👉df.fillna(df.mean()): 결측값은 보통 중간값이나 평균으로 변경한다.
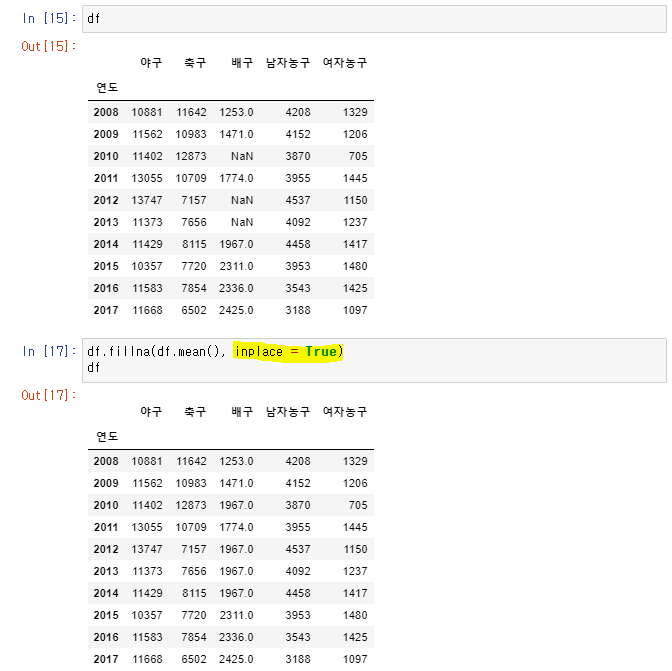
👉 결측값 삭제, 변경은 모두 새로운 DF로 원본 변경은 inplace = True
🙄 데이터 클리닝 (유일성)
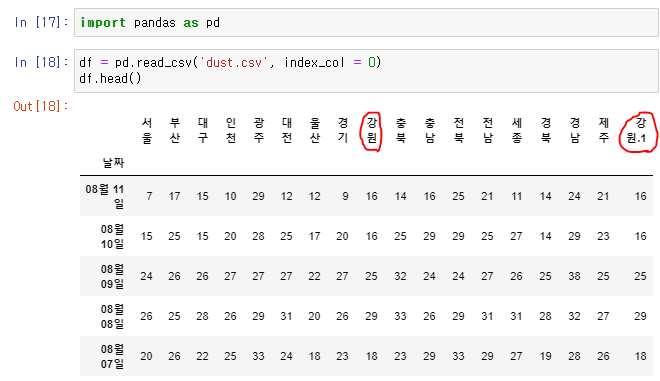
👉 수치가 같은 강원의 중복 데이터
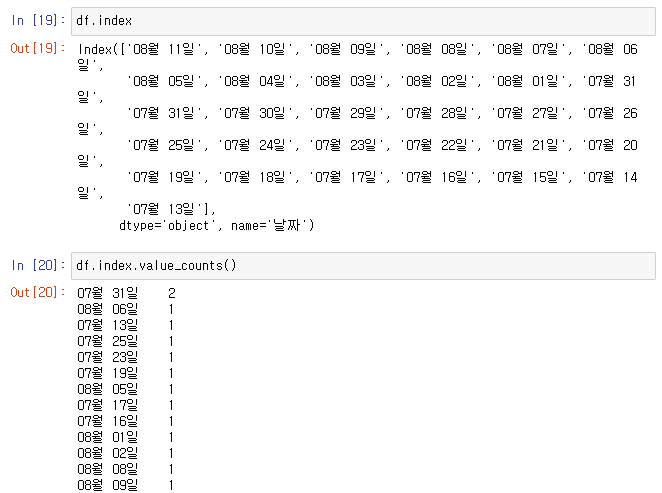
👉 인덱스에도 7월 31일 데이터가 중복되어있다.

👉
df.drop_duplicates(inplace = True): 중복 인덱스 삭제
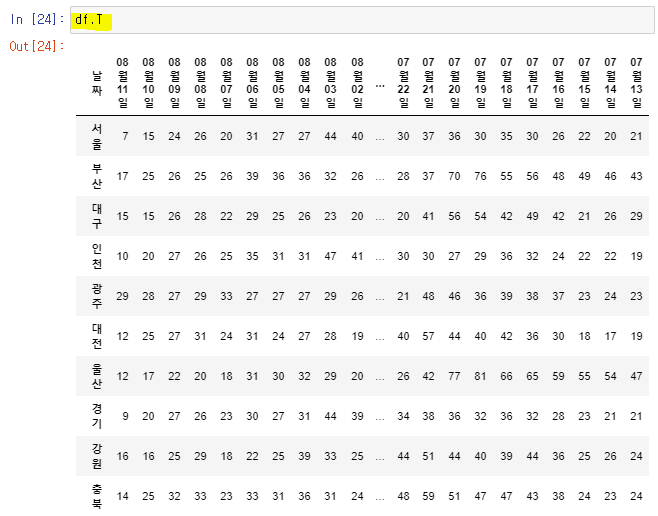
👉
df.T: 행/열 전환
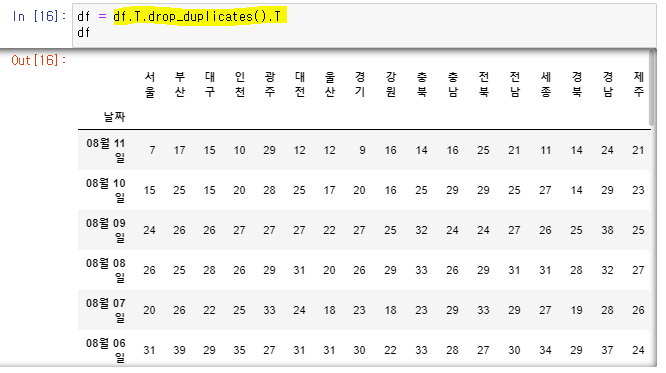
df.T.drop_duplicates().T: 행/열 전환 >>> 중복 행 삭제 >>> 행/열 전환
🙄 데이터 클리닝 (정확성)
- 이상점 (Outlier)이란?
다른 값들과 너무 동떨어져 있는 데이터
이상점을 판단하는 기준은 여러가지
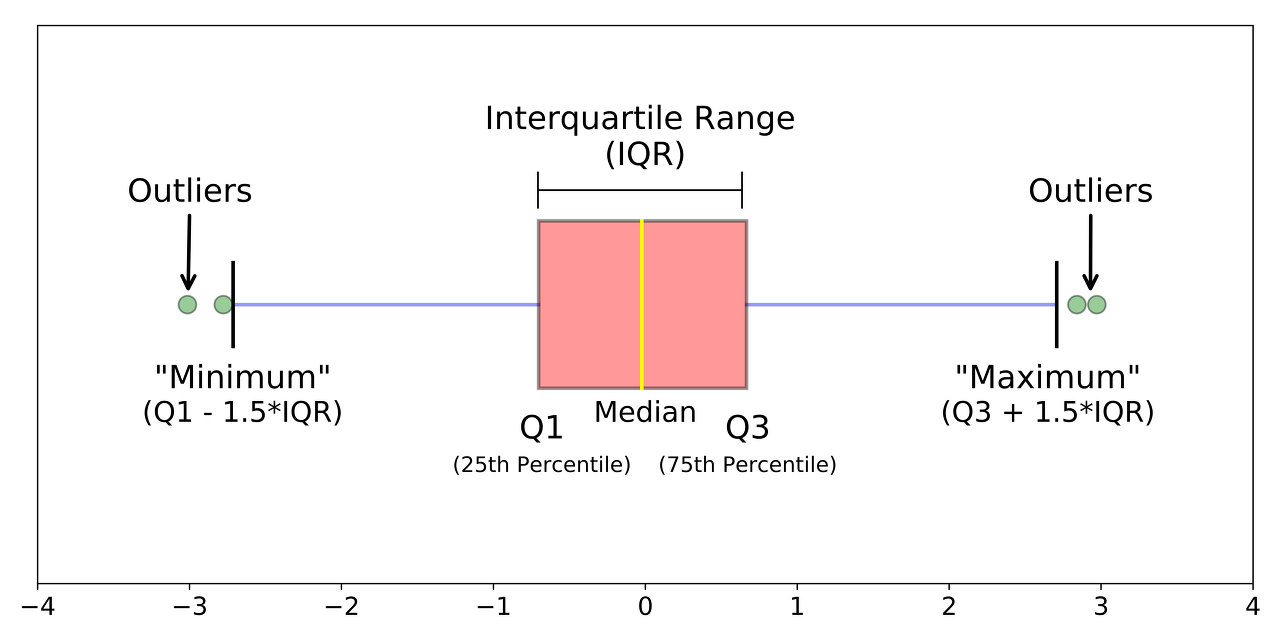
👉 그 중 하나로 Q1, Q3 값으로부터 1.5 * IQR 이상 떨어진 값들을 이상점이라 한다.
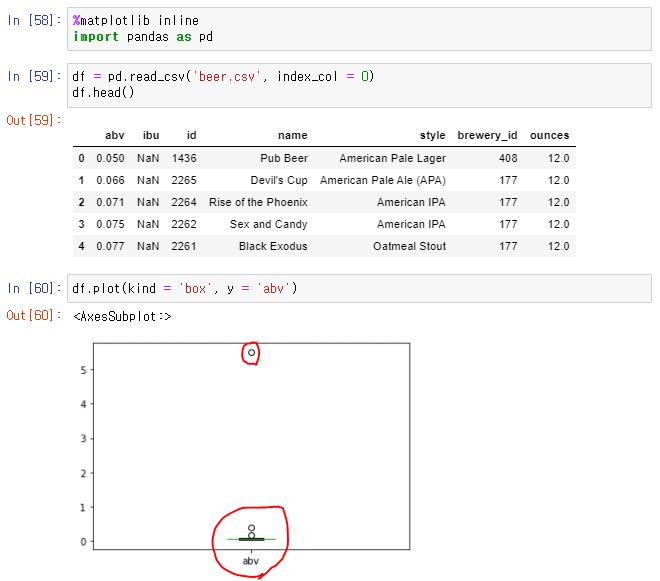
👉 3개의 이상점으로 박스플롯이 제대로 출력되지 않는 상황
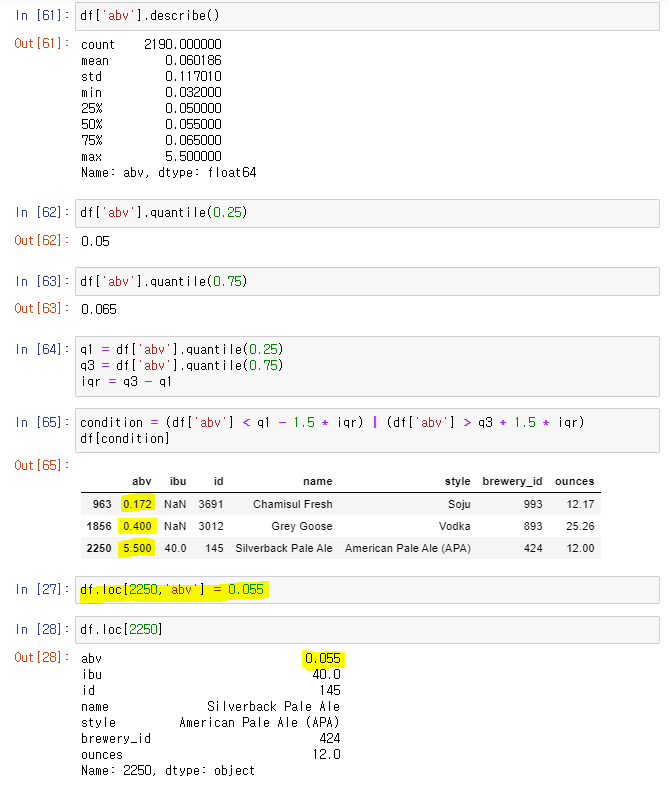
👉 이상점 데이터를 출력하자 index 2250은 입력이 잘못된 것으로 보여 맞게 수정
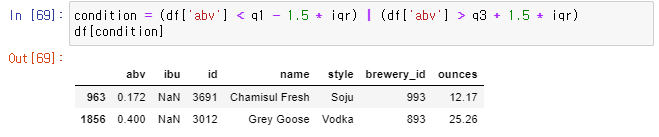
👉 다시 이상점을 출력하자 사라진 2250, 나머지 둘은 삭제하기로 결정
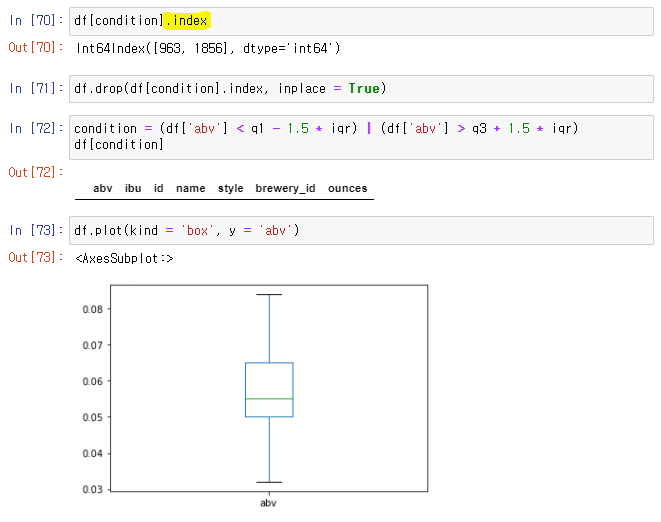
👉 두 데이터의 index를 뽑아내 삭제 후, 잘 출력되는 박스플롯
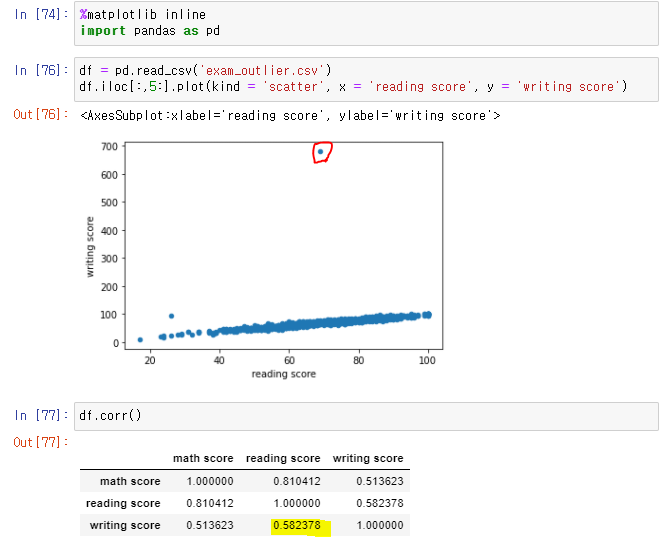
👉 writing score가 100이 넘는 이상점 발견 이 때문에 상관계수도 낮음
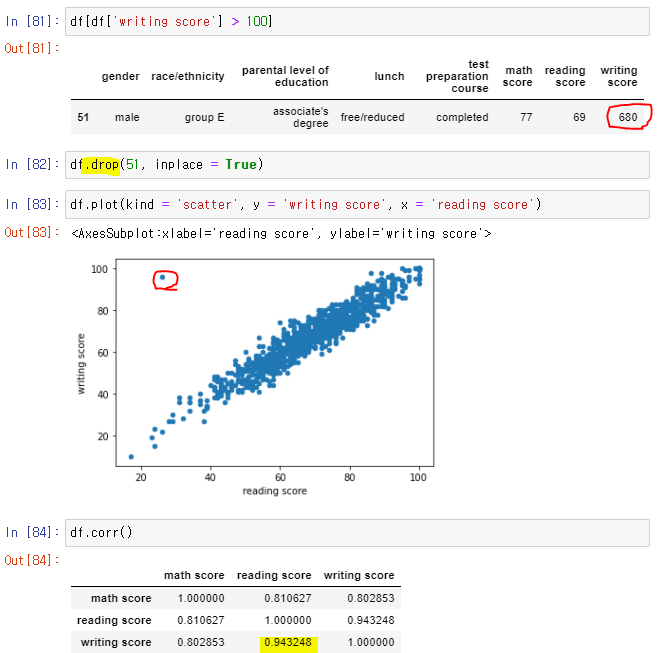
👉 조건 인덱싱 후 삭제, 상관계수도 알맞게 돌아왔고, 또 다른 이상점이 보인다.
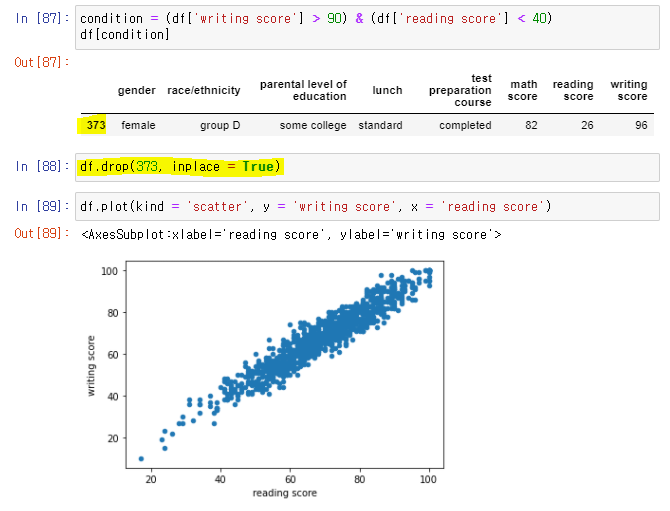
👉 삭제 후 이상점 없는 산점도 출력
.png)