
🙄 새로운 값 계산하기
➡ 전체 TV채널 시청률
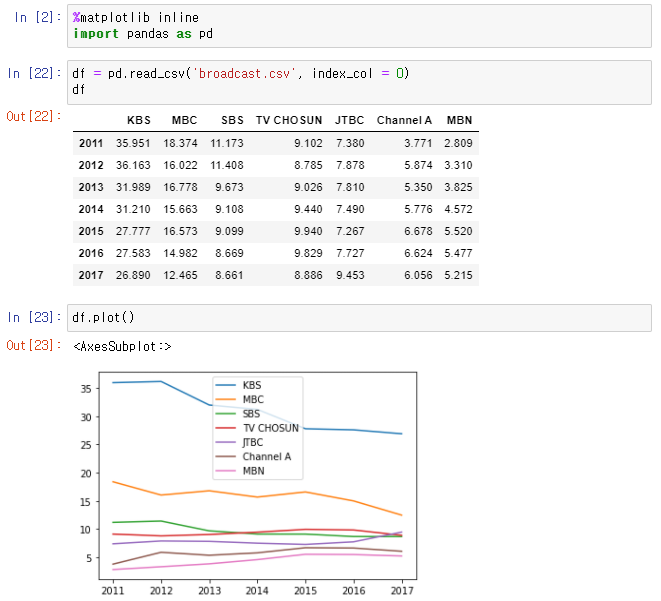
👉 기존 DataFrame, 새로운 Column을 추가함으로써 새로운 인사이트를 얻을 수 있다.
👉 갈수록 사람들이 TV를 적게 본다는 것을 알 수 있다.
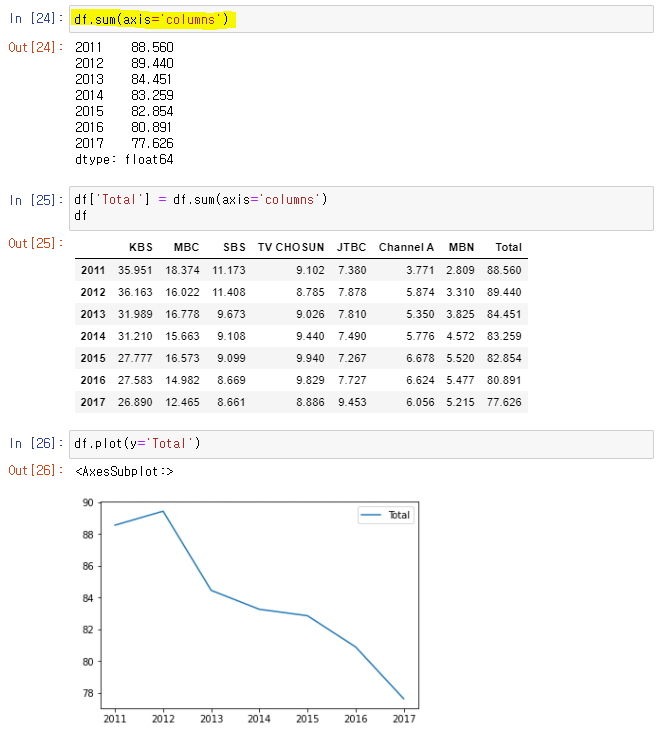
➡ 지상파 vs 종편

👉 지상파 인기는 줄고 종편의 인기가 높아짐을 알 수 있다.
🙄 문자열 필터링
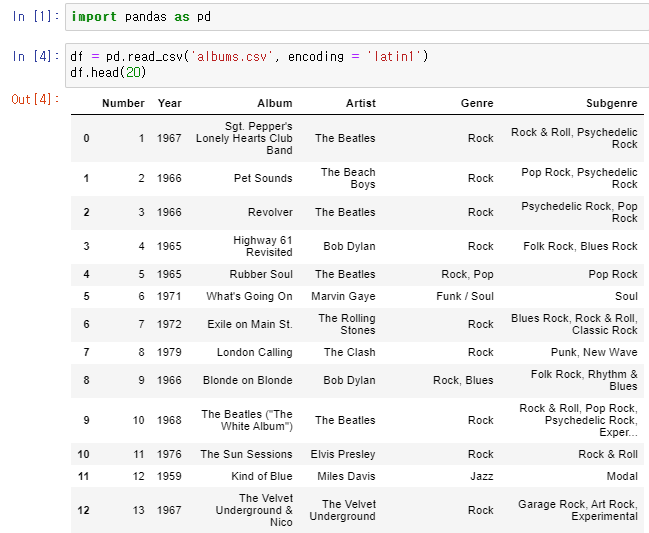
👉 위 DataFrame에서 Genre가 Blues인 Data 필터링 해보자

👉
df['Genre'].str.contains('Blues'): Genre에 Blues를 포함한 Data 필터링
👉df['Genre'].str.startswith('Blues'): Blues로 시작하는 Data 필터링

👉 필터링 한 것을 새로운 Column으로 추가 가능
🙄 문자열 분리
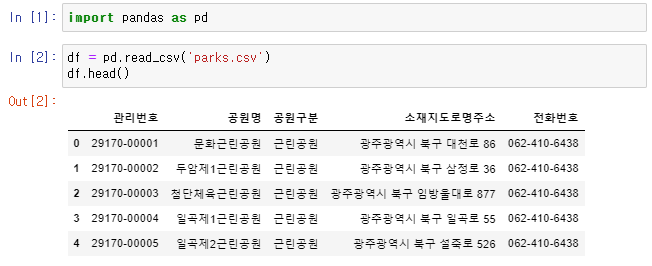
👉 위 DataFrame에서 소재지도로명주소 Data를 분리해 관할구역 Column을 만들어보자.

👉
df[].str.split(): 문자열 분리
👉n = 1,: n번째 분리까지만 적용
👉expand = True: 분할된 리스트를 바로 DataFrame으로 만듦

👉 성공 ❗❗
🙄 카테고리로 분류
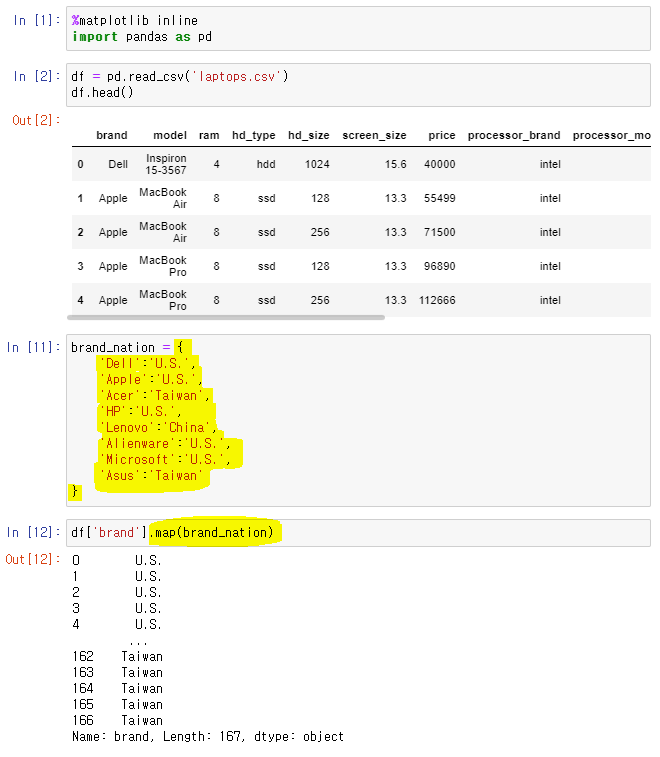
👉
df[].map(): dict 왼쪽 값을 오른쪽 값으로 변경
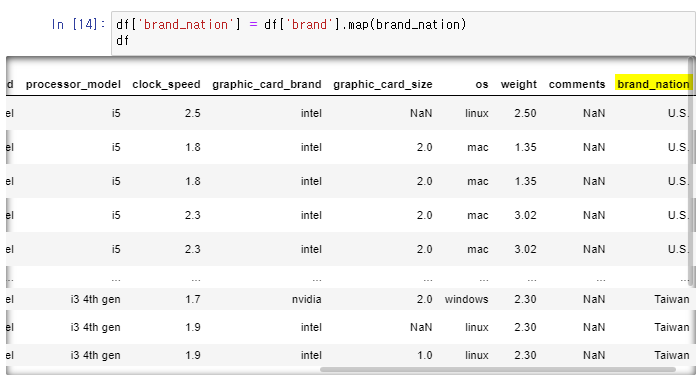
👉 변경된 값을 새로운 column으로 생성
🙄 groupby
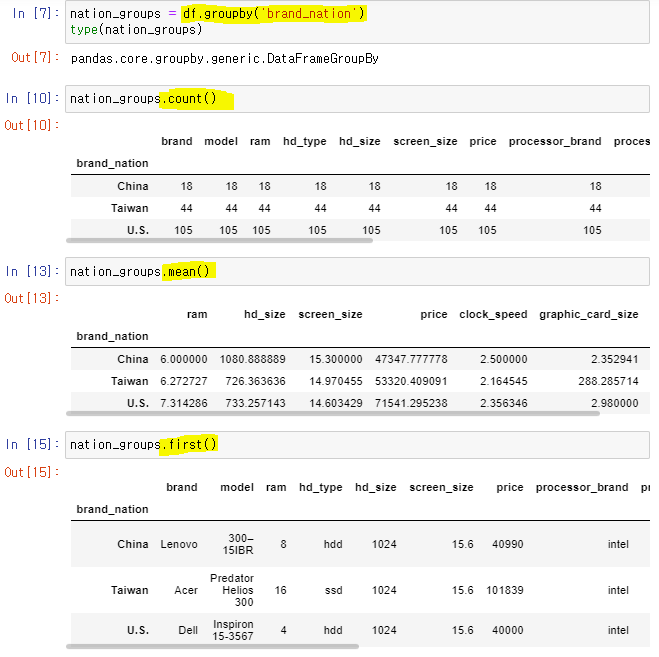
👉
df.groupby()를 이용해 그룹별 Data를 얻을 수 있다.
👉df.groupby().count()
👉df.groupby().mean()
👉df.groupby().first()

👉 그룹별 그래프도 그릴 수 있다.
🙄 데이터 합치기
합치기 의 4가지 방법
- inner join : 두 DataFrame의 교집합만 합침
- left outer join : 왼쪽 DataFrame 기준으로 합침
- right outer join : 오른쪽 DataFrame 기준으로 합침
- full outer join : 모든 데이터를 합침

👉 다음 두 DataFrame을 합쳐보자
➡ inner join & left outer join

👉
pd.merge(df_1, df_2, on = 'Product'): how 기본값 = inner join
👉pd.merge(df_1, df_2, on = 'Product', how = 'left'): left outer join
➡ right outer join & full outer join
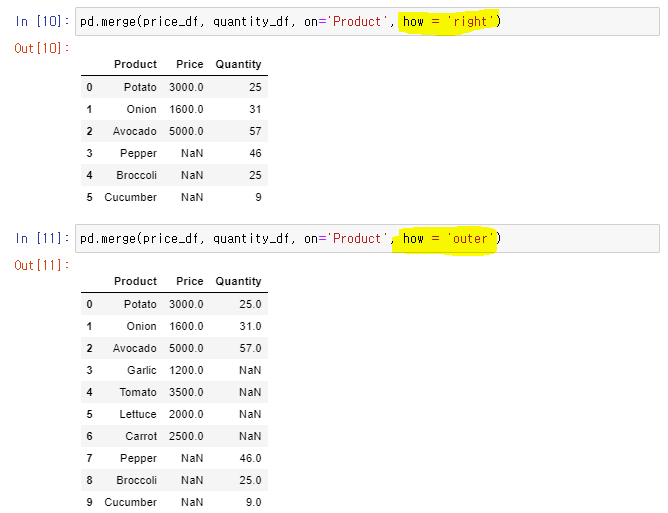
👉
pd.merge(df_1, df_2, on = 'Product', how = 'right'): right outer join
👉pd.merge(df_1, df_2, on = 'Product', how = 'outer'): full outer join
.png)